Một xu hướng mới về trí tuệ nhân tạo (AI) đã được phát hiện: Chinchilla (70B) vượt xa GPT-3 (175B) và Gopher (280B) về hiệu suất
Bài đăng này đã không được cập nhật trong 2 năm
Một xu hướng mới về trí tuệ nhân tạo (AI) đã được phát hiện: Chinchilla (70B) vượt xa GPT-3 (175B) và Gopher (280B) về hiệu suất
DeepMind đã tìm ra cách để tăng kích thước các mô hình ngôn ngữ lớn một cách rẻ tiền. Bài báo mới nhất của DeepMind phá vỡ xu hướng của việc xây dựng các mô hình ngôn ngữ ngày càng lớn để cải thiện hiệu suất. Công ty đã tìm ra một khía cạnh quan trọng của việc tăng kích thước các mô hình ngôn ngữ lớn mà chưa ai áp dụng trước đó. Các công ty công nghệ lớn như OpenAI, Google, Microsoft, Nvidia, Facebook và thậm chí cả DeepMind, tất cả đều đã thực hiện sai: Tăng kích thước mô hình không phải là cách tiếp cận tốt nhất hay hiệu quả nhất.
Nghiên cứu của DeepMind đã chỉ ra rằng tăng số lượng mã thông báo đào tạo (tức là lượng dữ liệu văn bản mà mô hình được cung cấp) cũng quan trọng như tăng kích thước mô hình. Điều này có nghĩa là một mô hình nhỏ có thể vượt trội hơn so với một mô hình lớn - nhưng không tối ưu - nếu được đào tạo trên một số lượng mã thông báo đào tạo đáng kể cao hơn.
DeepMind đã chứng minh điều này bằng mô hình Chinchilla - một mô hình với 70 tỷ tham số, nhỏ hơn 4 lần so với Gopher (cũng được xây dựng bởi DeepMind), nhưng được đào tạo trên 4 lần số lượng dữ liệu. Chinchilla đã "đồng đều và đáng kể" vượt qua Gopher, GPT-3, Jurassic-1 và Megatron-Turing NLG trên một loạt các bài kiểm tra ngôn ngữ.
Kết luận là rõ ràng: Các mô hình ngôn ngữ lớn hiện tại đang được "đào tạo thiếu sự tối ưu", điều này là hậu quả của việc mù quáng theo đuổi giả thiết tăng kích thước - làm cho các mô hình lớn không phải là cách duy nhất để cải thiện hiệu suất. Và không chỉ vậy, vì Chinchilla nhỏ hơn, chi phí phân tích và điều chỉnh cũng rẻ hơn, giúp việc sử dụng các mô hình này đến các công ty nhỏ hoặc các trường đại học có thể không có ngân sách hoặc phần cứng thế hệ trước để chạy các mô hình lớn hơn. "Các lợi ích của một mô hình nhỏ tối ưu hơn, do đó, vượt xa các lợi ích ngay lập tức của hiệu suất được cải thiện."
Bài báo của DeepMind cũng chỉ ra rằng để đạt được mô hình ngôn ngữ lớn tối ưu về tính toán, các nhà nghiên cứu nên phân bổ ngân sách tính toán một cách tương tự cho cả việc tăng kích thước mô hình và số lượng mã thông báo đào tạo. "Đối với mỗi lần gấp đôi kích thước mô hình, số lượng mã thông báo đào tạo cũng nên được gấp đôi." Điều này áp dụng cho các công ty với ngân sách tính toán cố định và muốn tạo ra các mô hình tối ưu về hiệu suất.
Như vậy, việc tăng kích thước mô hình không còn là cách duy nhất để cải thiện hiệu suất của các mô hình ngôn ngữ lớn. Việc tăng số lượng mã thông báo đào tạo cũng rất quan trọng. Các nhà nghiên cứu có thể sử dụng kết quả của DeepMind để tạo ra các mô hình ngôn ngữ lớn tối ưu hơn với chi phí tính toán thấp hơn và tăng cường hiệu suất của chúng.
Tóm lại, DeepMind đã tìm ra một cách mới để tăng cường hiệu suất của các mô hình ngôn ngữ lớn bằng cách tăng số lượng mã thông báo đào tạo. Điều này có thể giúp tạo ra các mô hình ngôn ngữ lớn tối ưu hơn với chi phí tính toán thấp hơn, đồng thời giúp các công ty nhỏ hoặc các trường đại học có thể sử dụng các mô hình này một cách dễ dàng hơn. Đây là một bước tiến quan trọng trong lĩnh vực trí tuệ nhân tạo và có thể mở ra cơ hội cho các ứng dụng mới và cải thiện hiệu suất của các ứng dụng hiện có.
Compute-optimal large language models Trong bài báo, DeepMind cũng đã nghiên cứu cách các yếu tố khác nhau ảnh hưởng đến hiệu suất của các mô hình ngôn ngữ lớn. Ngân sách tính toán thường là yếu tố giới hạn và độc lập. Kích thước mô hình và số lượng mã thông báo đào tạo được xác định bởi số tiền mà công ty có thể chi để nâng cấp phần cứng tốt hơn. Để nghiên cứu cách các biến số này ảnh hưởng đến hiệu suất, các nhà nghiên cứu của DeepMind đã đặt câu hỏi: "Với một ngân sách FLOPs cố định, làm thế nào để phân bổ kích thước mô hình và số lượng mã thông báo đào tạo?"
Các mô hình như GPT-3, Gopher và MT-NLG theo luật tỉ lệ của Kaplan (Bảng 1). Ví dụ cụ thể, nếu ngân sách tính toán tăng lên 10 lần, luật của Kaplan dự đoán hiệu suất tối ưu khi kích thước mô hình tăng lên 5,5 lần và số lượng mã thông báo đào tạo tăng lên 1,8 lần.
Các kết quả này cho thấy rằng cách tối ưu hóa mô hình ngôn ngữ lớn không chỉ là tăng kích thước mô hình, mà còn phải tăng số lượng mã thông báo đào tạo. Nghiên cứu này cung cấp một cách tiếp cận mới cho việc tạo ra các mô hình ngôn ngữ lớn tối ưu hơn, tiết kiệm chi phí tính toán và mở ra nhiều tiềm năng cho các ứng dụng trí tuệ nhân tạo.
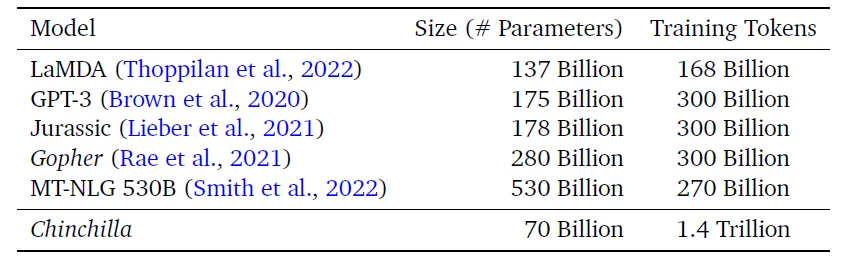
Trong bài báo của mình, DeepMind cũng chỉ ra rằng nghiên cứu của Kaplan và đồng nghiệp đã đưa ra kết luận sai lầm khi giả định số lượng mã thông báo đào tạo là cố định trong phân tích của họ. Điều này đã ngăn họ tìm ra câu trả lời của DeepMind, rằng cả kích thước mô hình và số lượng mã thông báo đào tạo nên tăng đồng thời, ước tính tăng gần 3,16 lần (hoặc căn bậc hai của 10 lần).
Để nghiên cứu mối quan hệ giữa ngân sách tính toán, kích thước mô hình và số lượng mã thông báo đào tạo, các nhà nghiên cứu đã sử dụng ba phương pháp (xem phần 3 của bài báo để biết thêm chi tiết).
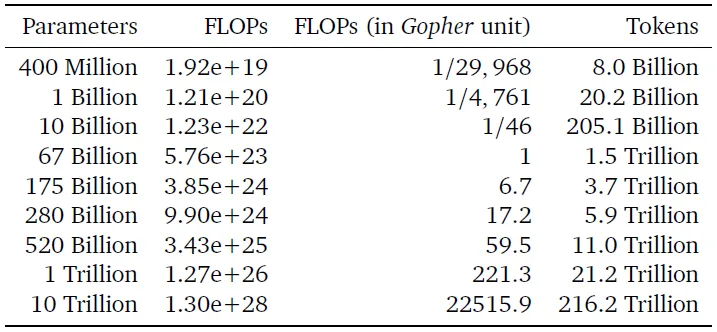
- Kích thước mô hình cố định: Họ xác định một loạt các kích thước mô hình (từ 70 triệu đến 16 tỷ) và thay đổi số lượng mã thông báo đào tạo (4 biến thể) cho mỗi mô hình. Sau đó, họ xác định sự kết hợp tối ưu cho mỗi ngân sách tính toán. Sử dụng phương pháp này, một mô hình tối ưu về tính toán được đào tạo với cùng lượng tính toán như Gopher sẽ có 67 tỷ thông số và 1,5 nghìn tỷ mã thông báo.
- Đường cong IsoFLOP: Họ cố định ngân sách tính toán (9 biến thể trong khoảng từ 6x10¹⁸ đến 3x10²¹) và khám phá kích thước mô hình (xác định tự động số lượng mã thông báo). Sử dụng phương pháp này, một mô hình tối ưu về tính toán được đào tạo với cùng lượng tính toán như Gopher sẽ có 63 tỷ thông số và 1,4 nghìn tỷ mã thông báo.
- Phù hợp với hàm mất số học: Sử dụng kết quả từ phương pháp 1 và 2, họ mô hình hóa các mất số học dưới dạng hàm phụ thuộc vào kích thước mô hình và số lượng mã thông báo đào tạo. Sử dụng phương pháp này, một mô hình tối ưu về tính toán được đào tạo với cùng lượng tính toán như Gopher sẽ có 40 tỷ thông số.
Tổng cộng, họ đã đánh giá hơn 400 mô hình, từ 70 triệu đến 16 tỷ thông số và từ 5 tỷ đến 500 tỷ mã thông báo đào tạo. Ba phương pháp này đưa ra những dự đoán tương tự cho kích thước mô hình và số lượng mã thông báo đào tạo tối ưu - đáng kể khác biệt so với kết quả từ nghiên cứu của Kaplan.
Những kết quả này cho thấy rằng các mô hình hiện tại đã quá lớn so với ngân sách tính toán của chúng (hình 1). Các phát hiện này có thể giúp các nhà khoa học và công ty tạo ra các mô hình ngôn ngữ lớn hơn và tối ưu hơn với chi phí tính toán thấp hơn, đồng thời cung cấp cơ hội để cải thiện hiệu suất và độ chính xác của các ứng dụng trí tuệ nhân tạo.
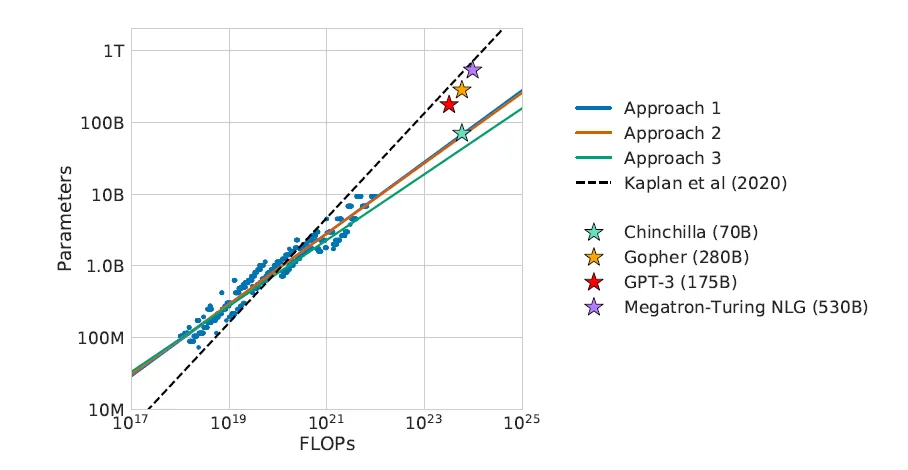
Như được thể hiện trong bảng 3 (phương pháp đầu tiên), một mô hình 175 tỷ thông số (tương tự như GPT-3) nên được đào tạo với ngân sách tính toán là 3,85x10²⁴ FLOPs và được đào tạo trên 3,7 nghìn tỷ mã thông báo (hơn 10 lần so với OpenAI sử dụng cho mô hình GPT-3 175 tỷ thông số của họ). Một mô hình 280 tỷ thông số (tương tự như Gopher) nên được đào tạo với ngân sách tính toán là 9,90x10²⁴ FLOPs và trên 5,9 nghìn tỷ mã thông báo đào tạo (tức là gấp 20 lần số lượng mã thông báo mà DeepMind đã sử dụng cho mô hình Gopher).
Các kết quả này cho thấy tầm quan trọng của việc xem xét cả kích thước mô hình và số lượng mã thông báo đào tạo để tối ưu hóa hiệu suất của các mô hình ngôn ngữ lớn.
Nhóm nghiên cứu DeepMind đã sử dụng các ước tính thận trọng (phương pháp 1 và 2) để xác định kích thước và số lượng mã thông báo đào tạo của một mô hình tối ưu về tính toán được đào tạo trên ngân sách họ sử dụng cho Gopher. Kết quả là mô hình Chinchilla với 70 tỷ thông số được đào tạo trên 1,4 nghìn tỷ mã thông báo (nhỏ hơn 4 lần và sử dụng nhiều dữ liệu hơn 4 lần so với Gopher). Chinchilla vượt trội hơn Gopher - và tất cả các mô hình ngôn ngữ trước đó - "thống nhất và đáng kể".
Động lực của họ đã được chứng minh: Tăng số lượng mã thông báo đào tạo cùng với kích thước mô hình với tốc độ tương tự sẽ mang lại kết quả tốt nhất, giả thiết được chứng minh bởi Chinchilla.
So sánh kết quả: Chinchilla so với Gopher và các mô hình khác Nói rằng Chinchilla vượt trội hơn Gopher là quá nhẹ nhàng khi chúng ta xem xét kết quả cho từng bài kiểm tra. Để không quá tải bài viết với các biểu đồ, dưới đây tôi chỉ sẽ hiển thị kết quả cho hai bài kiểm tra quan trọng nhất là Massive Multitask Language Understanding (MMLU) và Big-bench (chiếm 80% các bài kiểm tra) và các bài kiểm tra liên quan đến đạo đức - luôn xứng đáng được xem xét kỹ lưỡng hơn. (Xem phần 4 của bài báo cho một phân tích chi tiết bao gồm các bài kiểm tra đọc, hiểu biết thông thường và câu hỏi và trả lời.)
MMLU & BIG-bench Chinchilla đạt được điểm SOTA mới cho cả hai bài kiểm tra này. Trung bình đạt được 67,6% độ chính xác trên MMLU và 65,1% độ chính xác trên Big-bench, trong khi Gopher lần lượt đạt được 60% và 54,4% (hình 2, 3). Đối với MMLU, Chinchilla vượt qua thậm chí cả mốc 63,4% được chuyên gia dự đoán sẽ là SOTA cho tháng 6 năm 2023. Không ai mong đợi được cải tiến đáng kể như vậy sớm như vậy.
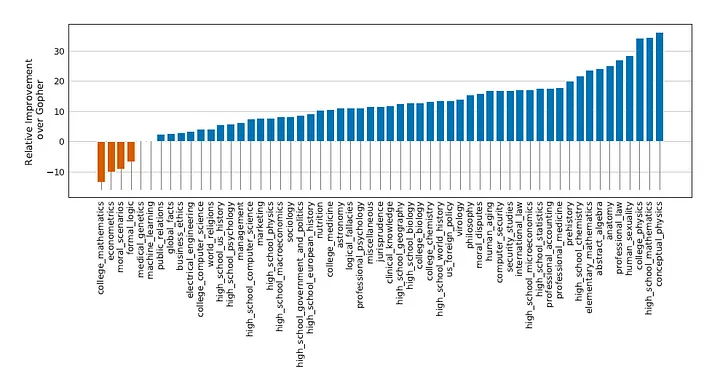
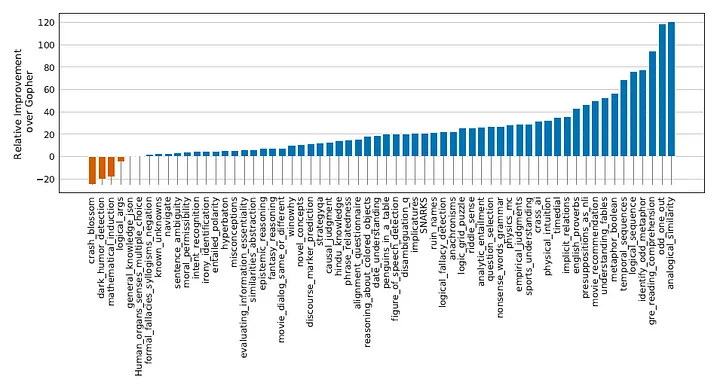
Chinchilla thống nhất vượt trội hơn các mô hình ngôn ngữ trước đó trên các bài kiểm tra khác như suy luận thông thường và hiểu biết đọc, chắc chắn chiếm ngôi vị vương giả của trí tuệ nhân tạo ngôn ngữ.
Tuy nhiên, sự ưu thế của Chinchilla chỉ kéo dài trong thời gian ngắn. Chỉ một tuần sau khi ra mắt, nó đã bị vượt qua bởi mô hình mới nhất của Google, PaLM (với 540 tỷ thông số, nó trở thành mô hình ngôn ngữ lớn nhất và hiệu quả nhất hiện tại). Chuỗi liên tiếp các mô hình mới từ các công ty khác nhau minh họa cho tốc độ nhanh chóng của lĩnh vực này. Tuy nhiên, Google không hoàn toàn lấy ý tưởng từ những phát hiện của DeepMind để xây dựng PaLM vì họ đang thử nghiệm một phương pháp khác. (Mong đợi sẽ có một bài viết mới sớm về PaLM!)
Giới tính và độc hại Dự kiến rằng Chinchilla, có cùng bộ dữ liệu và kiến trúc với Gopher, sẽ cho thấy hành vi tương tự đối với độ chệch giới tính và tính độc hại. Nó cho thấy một số cải tiến so với Gopher trên bộ dữ liệu Winogender của độ chệch giới tính và nghề nghiệp (bảng 7), nhưng không đồng đều trên tất cả các nhóm.

Đối với DeepMind, họ đã tìm thấy một mối quan hệ mới giữa ngân sách tính toán, kích thước mô hình và số lượng mã thông báo đào tạo. Tuy nhiên, đó không phải là các tham số duy nhất ảnh hưởng đến hiệu suất và hiệu quả.
Một vấn đề chính khi đào tạo các mô hình lớn là tìm các siêu tham số (HP) tối ưu. Các mô hình ngôn ngữ hiện tại quá lớn đến mức các công ty chỉ có thể đào tạo chúng một lần: Tìm kiếm bộ siêu tham số tốt nhất là không khả thi. Các nhà nghiên cứu thường phải đưa ra các giả định khó khăn - thường là sai - để thiết lập chúng.
Gần đây, Microsoft và OpenAI đã nghiên cứu một loại tham số hóa mới (μP) có khả năng tỷ lệ tốt trên các mô hình khác kích thước của cùng một họ. Các HP tối ưu cho một mô hình nhỏ có thể được chuyển sang mô hình lớn hơn, mang lại kết quả đáng kể cải thiện.
Bài báo của DeepMind đề cập đến công việc trước đây về việc điều chỉnh siêu tham số nhưng không đề cập đến bài báo cụ thể này được xuất bản cách đó vài tuần. Kết hợp mô hình tối ưu tính toán với μP có thể mang lại kết quả tốt hơn cho bất kỳ mô hình ngôn ngữ lớn nào.
Một cải tiến khác có thể là cơ chế truy xuất. RETRO đạt được hiệu suất tương đương với GPT-3 dù nhỏ hơn 25 lần. Khả năng truy xuất của nó cho phép mô hình truy cập vào một cơ sở dữ liệu lớn (3T mã thông báo) trong thời gian thực (tương tự như cách chúng ta thực hiện tìm kiếm trên internet).
Cuối cùng, nếu chúng ta muốn đi đến cuối cùng, một kỹ thuật cân chỉnh có thể cải thiện kết quả không chỉ trong các chỉ số ngôn ngữ mà còn trong các tình huống thực tế. OpenAI đã sử dụng một phương pháp để cải thiện GPT-3 thành InstructGPT với kết quả hiệu suất tuyệt vời. Tuy nhiên, cân chỉnh trí tuệ nhân tạo là rất phức tạp và InstructGPT không có vẻ cải thiện hơn so với các mô hình trước đó về mặt an toàn hoặc độ độc hại.
Nếu một công ty kết hợp tất cả các tính năng này vào một mô hình, họ sẽ tạo ra mô hình tổng thể tốt nhất có thể với những gì chúng ta biết hiện nay về các mô hình ngôn ngữ lớn. Một xu hướng mới Thành tích của Chinchilla không chỉ ấn tượng về mức độ cải tiến mà còn vì mô hình này nhỏ hơn tất cả các mô hình ngôn ngữ lớn được phát triển trong hai năm qua và cho kết quả tốt nhất trong các bài kiểm tra. Thay vì tập trung vào việc làm cho các mô hình lớn hơn, như nhiều chuyên gia trí tuệ nhân tạo đã chỉ trích, các công ty và nhà nghiên cứu nên tập trung vào tối ưu hóa các nguồn tài nguyên và thông số kỹ thuật hiện có của họ - nếu không, họ đang lãng phí tiền của mình.
Về hiệu suất và hiệu quả, Chinchilla là một bước đột phá.
Hiệu suất của Chinchilla không còn là tốt nhất trong lĩnh vực này, khi mô hình PaLM của Google đã đạt được kết quả tốt nhất trong nhiều bài kiểm tra. Tuy nhiên, ảnh hưởng chính của Chinchilla không nằm ở việc nó là mô hình tốt nhất hiện có, mà là ở việc nó rất tốt trong khi phá vỡ xu hướng làm cho các mô hình ngày càng lớn hơn.
Hậu quả của điều này sẽ định hình tương lai của lĩnh vực này. Đầu tiên, các công ty nên nhận ra rằng kích thước mô hình không phải là duy nhất biến số quan trọng cho hiệu suất, mà chỉ là một trong nhiều biến số. Thứ hai, nó có thể làm dịu sự hào hứng của công chúng nói chung với việc thấy các mô hình ngày càng lớn hơn trong tương lai - như là một dấu hiệu rằng chúng ta đang tiến gần hơn đến AGI nhanh hơn so với thực tế. Cuối cùng, nó có thể giúp giảm các tác động về môi trường của các mô hình lớn và các rào cản đối với các công ty nhỏ hơn không thể theo kịp với các công ty công nghệ lớn.
Điểm này đưa tôi đến sự phản ánh thứ hai. Bốn suy nghĩ quan trọng từ Chinchilla Giới hạn khả tái sản Mặc dù nhỏ hơn các mô hình khác, nhưng vẫn không thể thực hiện được với hầu hết các công ty và trường đại học để huấn luyện hoặc nghiên cứu Hiện nay, đối với đa số các công ty và trường đại học, việc huấn luyện hoặc nghiên cứu các mô hình như Chinchilla là không khả thi. Việc gọi một mô hình có kích thước 70 tỷ tham số là "nhỏ" đã cho thấy điều này là vấn đề khó khăn. Hầu hết các đơn vị không có nguồn lực đủ để tiến hành các thí nghiệm cần thiết. Do đó, AI hiện tại đang được xây dựng trên nền tảng mong manh và do một vài công ty lớn quyết định hướng đi của khoa học.
Tuy nhiên, vấn đề này không chỉ liên quan đến tiền bạc. Các công ty như DeepMind, Google và OpenAI không có kế hoạch phát hành các mô hình của họ, như Chinchilla, PaLM và DALL·E, cho mục đích nghiên cứu của người khác. Các mô hình này thường chỉ được xuất bản như một cách để chỉ ra ai đang tiến bộ nhất trong lĩnh vực. Mặc dù DeepMind là một trong những công ty AI đã nỗ lực nhiều nhất để tiến bộ trong khoa học và nghiên cứu bằng cách cho phép người khác xây dựng trên những khám phá của họ (họ đã đưa ra các dự đoán AlphaFold miễn phí), nhưng xu hướng chỉ để khoe khoang vẫn chiếm ưu thế trong lĩnh vực này.
DeepMind đang cố gắng đảo ngược xu hướng gây tổn hại bằng cách xây dựng một mô hình tốt hơn và nhỏ hơn cùng một lúc. Nhưng với việc Chinchilla vẫn là một mô hình lớn, chúng ta cần nhận ra chúng ta đã đi xa đến mức nào về khả năng phổ cập một công nghệ sẽ định nghĩa lại tương lai của chúng ta. Nếu chúng ta tiếp tục theo hướng mà chỉ có một vài công ty kiểm soát nguồn lực cho nghiên cứu khoa học, hướng đi của nghiên cứu và những đột phá kết quả sẽ không đáng giá để tạo ra AGI.
Ngoài ra, để xây dựng các mô hình tốt hơn trong khi vẫn nhỏ hơn, các công ty cần sử dụng các bộ dữ liệu lớn hơn so với những gì họ có thể sử dụng hiện nay. Bộ dữ liệu văn bản chất lượng cao kích thước lớn sẽ rất cần thiết trong tương lai gần.
Emily M. Bender, giáo sư ngôn ngữ học tại Đại học Washington, đã chỉ trích phương pháp của Google để xây dựng PaLM vì 780 tỷ token (số lượng dữ liệu được sử dụng để huấn luyện mô hình) quá lớn để được tài liệu hóa tốt, điều này làm cho mô hình "quá lớn để triển khai an toàn". Chinchilla đã được huấn luyện trên gấp đôi số lượng token. Nếu chúng ta suy luận theo những chỉ trích của Bender (những chỉ trích này phụ thuộc vào quá trình DeepMind đã thực hiện để huấn luyện mô hình), chúng ta có thể kết luận rằng Chinchilla cũng không đủ an toàn để triển khai.
Để làm cho các mô hình tốt hơn trong khi vẫn nhỏ hơn, họ cần nhiều dữ liệu hơn. Nhưng sử dụng nhiều dữ liệu hơn sẽ làm cho các mô hình ít an toàn hơn. Chúng ta phải đối mặt với một lựa chọn khó khăn giữa việc làm cho các mô hình trở nên lớn hơn (tức là chúng trở nên ngày càng khó tiếp cận với hầu hết các nhà nghiên cứu trong lĩnh vực và đồng thời tác động đến môi trường) hoặc huấn luyện chúng trên nhiều token hơn (tức là làm cho kiểm tra dữ liệu khó hơn và các mô hình ít an toàn hơn). Nói rằng Chinchilla tốt hơn vì nó nhỏ hơn dường như là một tuyên bố xa vời ngày nay.
Sự lựa chọn khác luôn có thể là tập trung vào các dòng nghiên cứu khác không bao gồm việc huấn luyện các mô hình lớn với các bộ dữ liệu lớn. Tuy nhiên, do Big Tech có tiền để tài trợ cho các dòng nghiên cứu họ muốn, chỉ có những dòng nghiên cứu đó cung cấp kết quả - không phải vì những dòng nghiên cứu khác không sẽ hoạt động, mà là bởi vì chúng không được khai thác tốt.
Không có dấu hiệu rằng việc tối ưu các mô hình ngôn ngữ sẽ giải quyết được các vấn đề đạo đức của chúng. Các mô hình ngôn ngữ dựa trên Transformer có thể mắc phải các vấn đề liên quan đến đạo đức, như phân biệt đối xử giới tính, sự thiên vị chủng tộc hoặc sự độc hại, mặc dù kích thước mô hình, kích thước tập dữ liệu, chất lượng hyperparameter, ngân sách tính toán, v.v. Các nhà nghiên cứu và các nhà phát triển công nghệ thông tin sẽ phải tiếp tục đưa ra các giải pháp mới để giải quyết các vấn đề này và đảm bảo rằng các mô hình ngôn ngữ được xây dựng với các chuẩn đạo đức cao.
Nguồn: https://congdongchatgpt.com/d/46-research-mot-xu-huong-moi-ve-tri-tue-nhan-tao-ai-da-duoc-phat-hien Inspire ChatGPT Translate
All rights reserved
