
Một ứng dụng nho nhỏ của giải thuật di truyền trong Reinforcement Learning - Sinh chuỗi tương tự
Bài đăng này đã không được cập nhật trong 4 năm
Lời mở đầu
Xin chào các bạn. Chắc hẳn chúng ta đã không còn xa lạ gì với những thuật toán Reinforcement Learning sử dụng Deep Learning rồi phải không. Có bao giờ bạn đặt ra câu hỏi rằng thay vì chúng ta cố gắng đi tìm những kiến trúc mạng khổng lồ rồi cố gắng tối ưu nó thì chúng ta sẽ thử một trong những phương pháp khác không cần dùng đến mạng nơ ron chưa? Nếu bạn cũng đang có những băn khoăn như vậy thì bài viết này sẽ dành cho bạn.
Trong quá trình tiến hóa tự nhiên, các đặc điểm sinh học thay đổi và các đặc điểm mới được tạo ra chỉ đơn giản là do một số đặc điểm mang lại lợi thế sinh tồn và sinh sản. Kết quả là những sinh vật đó có thể tạo ra nhiều bản sao về di truyền học của chúng hơn trong những thế hệ tiếp theo. Khả năng tồn tại của một gen phụ thuộc hoàn toàn vào môi trường, môi trường này thường không thể đoán trước và liên tục thay đổi. Trong trường hợp áp dụng trong khoa học máy tính, quá trình tiến hóa mô phỏng đơn giản hơn nhiều, vì chúng ta thường muốn tối đa hóa hoặc giảm thiểu một số duy nhất, chẳng hạn như giá trị của hàm mất mát khi huấn luyện một mạng nơ-ron.
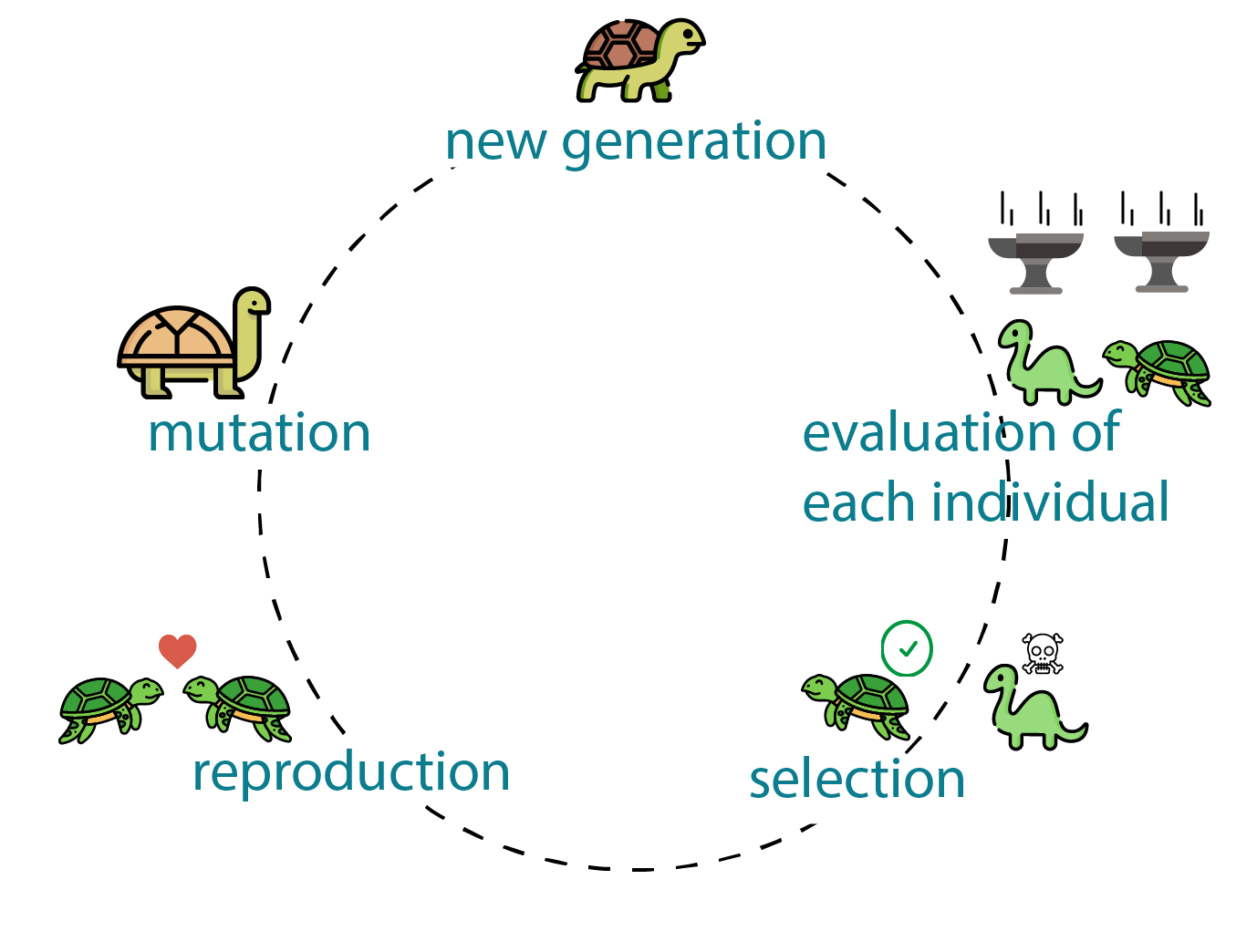
Trong bài này chúng ta sẽ tìm hiểu một hướng tiếp cận mới của RF khi không dùng đến Deep Learning mà sử dụng Genertic Algorithms. Để minh hoạ cho hoạt động của bài toán, mình sẽ sử dụng một ứng dụng rất đơn giản nhưng thú vị đó chính là Sinh chuỗi tương tự với một chuỗi đầu vào bất kì. OK chúng ta bắt đầu thôi
Nhìn lại về học tăng cường sử dụng DL
Học tăng cường sử dụng DL
Cùng nhìn lại một chút về học tăng cường. Tại sao chúng ta thậm chí sẽ nghĩ đến việc loại bỏ backpropagation. Trong khi cả DQN và policy gradient approach, chúng ta đều tạo ra một agent có policy của nó phụ thuộc vào tham số của mạng nơ ron để xấp xỉ Q function hay policy function. Như trong hình dưới đây, agent sẽ tương tác với môi trường, thu thập các kinh nghiệm và sau đó sử dụng lan truyền ngược để cải thiện độ chính xác của mạng nơ-ron. Đó là policy của nó. Chúng ta cần phải điều chỉnh cẩn thận một số siêu tham số khác nhau, từ việc chọn hàm tối ưu phù hợp, kích thước của mini-batch và tốc độ học để quá trình huấn luyện diễn ra ổn định và thành công. Nhưng có một vấn đề là dù đã chọn lựa rất kĩ các siêu tham số đó thì cũng không có gì khẳng định thuật toán sẽ học thành công nếu như các kĩ thuật sử dụng đạo hàm đưa chúng ta để một giải pháp tối ưu cục bộ thay vì tối ưu toàn cục.
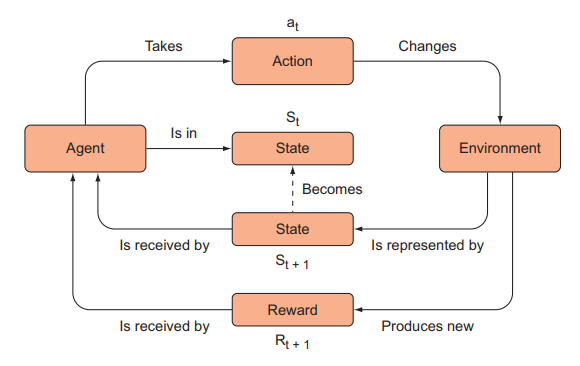
Đối với các thuật toán dựa trên các mạng nơ ron, các agent của chúng ta đã tương tác với môi trường, thu thập kinh nghiệm và sau đó học hỏi từ những kinh nghiệm đó. Chúng ta lặp đi lặp lại quy trình tương tự cho mỗi epoch cho đến khi kết thúc quá trình học.
Tùy thuộc vào môi trường và độ phức tạp của mạng, việc tạo một agent với các siêu tham số phù hợp có thể cực kỳ khó khăn. Hơn nữa, để có thể sử dụng được gradient descent và backpropagation, chúng ta cần một mô hình khả vi. Chắc chắn có những mô hình thú vị và hữu ích mà bạn có thể xây dựng nhưng lại không thể huấn luyện được với gradient descent do nó không khả vi.
Điều này dẫn đến một hướng mới chúng ta có thể tiếp cận đó chính là thuật toán tiến hoá
Quá trình học dựa trên thuật toán tiến hoá
Vậy thay vì tạo ra một agent và cải thiện nó, thay vào đó chúng ta có thể học hỏi từ Charles Darwin và sử dụng quá trình tiến hóa bằng chọn lọc tự nhiên. Chúng ta có thể sinh ra nhiều agent khác nhau với các bộ tham số (weights) khác nhau, quan sát tác nhân nào làm tốt nhất và “lai tạo” tác nhân tốt nhất để con cháu có thể thừa hưởng những đặc điểm mong muốn của cha mẹ chúng — giống như trong chọn lọc tự nhiên. Chúng ta có thể mô phỏng sự tiến hóa sinh học bằng các thuật toán. Chúng ta sẽ không cần phải vật lộn để điều chỉnh các siêu tham số và đợi mô hình được huấn luyện qua rất nhiều epoch để xem liệu agent có đang học “chính xác” hay không. Thay vào đó, chúng ta chỉ cần chọn các agent đã hoạt động tốt hơn. Chúng ta có thẻ mô tả hoạt động của quá trình này trong hình sau
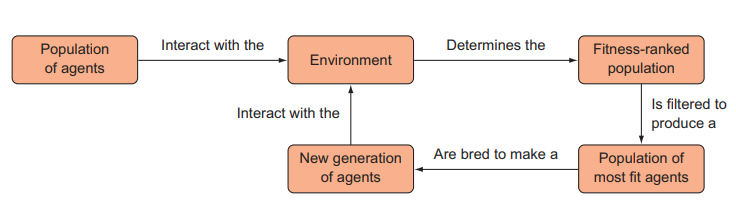
Loại thuật toán này không yêu cầu chúng ta huấn luyện một agent riêng lẻ. Nó không dựa vào gradient và được gọi một cách khác là gradient-free algorithm.
Học tăng cường với thuật toán tiến hoá
Trong phần này chúng ta sẽ nói về cách làm thế nào để tận dụng chiến lược tiến hoá, và chúng ta sẽ trình bày ngắn gọn cách để định nghĩa agent tốt nhất. Tiếp theo chúng ta sẽ nói đến cách thức tổ hợp để sinh ra một agent mới từ một agent sẵn có. Sự phát triển này là một quá trình nhiều thế hệ, vì vậy chúng ta sẽ thảo luận về điều đó và tóm tắt lại toàn bộ các quá trình huấn luyện.
Lý thuyết tiến hoá trong sinh học
Nếu bạn còn nhớ các kiến thức trong môn sinh học từ hồi học phổ thông, thì chọn lọc tự nhiên sẽ chọn ra những cá thể “phù hợp nhất” từ mỗi thế hệ. Trong sinh học, điều này đại diện cho những cá thể có tỉ lệ sống sót thành công lớn nhất và do đó đã truyền thông tin di truyền của họ cho các thế hệ tiếp theo. Những con chim có hình dạng mỏ thích hợp hơn trong việc lấy hạt từ cây sẽ có nhiều thức ăn hơn và do đó có nhiều khả năng sống sót hơn để truyền gen chứa hình dạng mỏ đó cho con cháu của chúng. Nhưng hãy nhớ rằng, khái niệm "phù hợp nhất" ở đây phải liên quan đến môi trường. Một con gấu Bắc Cực thích nghi tốt với các chỏm băng ở vùng cực nhưng sẽ rất không thích hợp trong các khu rừng nhiệt đới Amazon hay sa mạc Sahara.
Trong sinh học, mỗi đột biến thay đổi rất nhỏ các đặc điểm của sinh vật, do đó khó có thể phân biệt thế hệ này với thế hệ khác. Tuy nhiên, việc cho phép những đột biến và biến thể này tích lũy qua nhiều thế hệ sẽ cho phép những thay đổi có thể nhận thấy được. Trong quá trình tiến hóa của mỏ chim, ví dụ, một quần thể ban đầu các loài chim sẽ có hình dạng mỏ gần giống nhau. Nhưng theo thời gian, các đột biến ngẫu nhiên đã được đưa vào quần thể. Hầu hết các đột biến này có thể không ảnh hưởng đến chim hoặc thậm chí có tác động có hại, nhưng với một quần thể đủ lớn và đủ thế hệ, các đột biến ngẫu nhiên xảy ra ảnh hưởng có lợi đến hình dạng mỏ. Những con chim có chiếc mỏ phù hợp hơn sẽ có lợi thế kiếm thức ăn hơn những con chim khác và do đó chúng có khả năng di truyền gen cao hơn. Do đó, thế hệ tiếp theo sẽ có tần số tăng lên của gen mỏ có hình dạng thuận lợi.
Lý thuyết tiến hoá trong khoa học máy tính
Trong học tăng cường sử dụng thuật toán tiến hóa, chúng ta đang chọn các đặc điểm mang lại cho agent của chúng ta phần thưởng cao nhất trong một môi trường nhất định và theo đặc điểm. Các đặc điểm ở đây có nghĩa là các thông số mô hình (ví dụ: trọng số của mạng nơ-ron) hoặc toàn bộ cấu trúc mô hình. Thể trạng của một agent trong RL có thể được xác định bằng phần thưởng dự kiến mà agent sẽ nhận được nếu hoạt động trong môi trường.
Mục tiêu trong học tăng cường tiến hóa hoàn toàn giống như trong đào tạo dựa trên backpropagation và đào tạo dựa trên gradient. Sự khác biệt duy nhất là chúng ta sử dụng quá trình tiến hóa này, thường được gọi là thuật toán di truyền, để tối ưu hóa các tham số của một mô hình chẳng hạn như mạng nơ-ron.
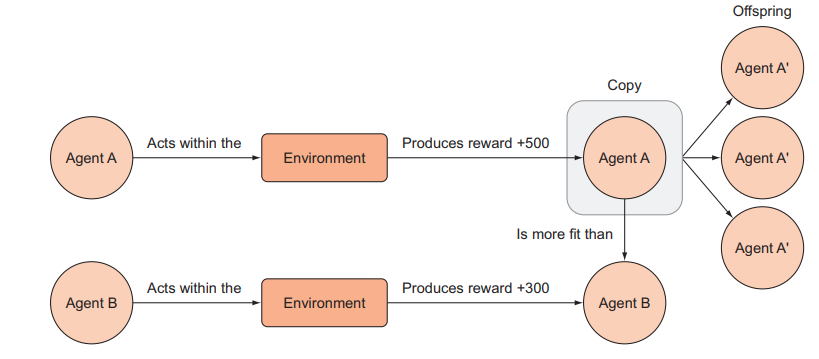
Trong cách tiếp cận thuật toán tiến hóa để học tăng cường, các agent cạnh tranh trong một môi trường và các agent phù hợp hơn (tạo ra nhiều phần thưởng hơn) được ưu tiên sao chép để tạo ra thế hệ tương lai. Sau nhiều lần lặp lại quy trình này, chỉ còn lại những agent phù hợp nhất.
Các bước thực hiện của giải thuật di truyền trong RF
Chúng ta hãy xem xét các bước của thuật toán di truyền một cách chi tiết hơn. Giả sử chúng ta có một mạng nơ-ron mà chúng ta muốn sử dụng làm tác nhân để chơi Gridworld và chúng ta muốn đào tạo nó bằng cách sử dụng một thuật toán di truyền. Hãy nhớ rằng, đào tạo mạng nơ-ron chỉ có nghĩa là cập nhật lặp đi lặp lại các tham số của nó để hiệu suất của nó được cải thiện. Cũng nhớ lại rằng với một kiến trúc mạng nơ-ron cố định, các tham số hoàn toàn xác định hành vi của nó, vì vậy để sao chép một mạng nơ-ron, chúng ta chỉ cần sao chép các tham số của nó.
Sau đây là các khái niệm để có thể huấn luyện được một mạng nơ ron như vậy:
- Khởi tạo quần thể: tạo ra một tập hợp ban đầu của các vectơ trọng số ngẫu nhiên. Mỗi voector này được đại diện cho một cá thể (agent), tập hợp ban đầu này được gọi là quần thể (population). Giả sử quần thể ban đầu này có 100 cá thể.
- Đưa quần thể vào môi trường: đưa quần thể này vào cùng chơi trò chơi Gridworld của chúng ta sau đó tiến hành ghi lại reward của mỗi cá thể. Mỗi cá thể được chỉ định một điểm chất lượng - fitness score dựa trên phần thưởng mà chúng kiếm được. Vì quần thể ban đầu là ngẫu nhiên, tất cả chúng có khả năng sẽ hoạt động rất kém, nhưng sẽ có một số ít, chỉ do ngẫu nhiên, sẽ hoạt động tốt hơn những cá thể khác.
- Lựa chọn cá thể để lai tạo: Tiến hành lấy mẫu ngẫu nhiên một cặp cá thể (“bố mẹ”) từ quần thể, được tính trọng số theo điểm chất lượng tương đối của chúng (những cá thể có chất lượng cao hơn có xác suất được chọn cao hơn) để tạo ra “quần thể giống lai tạo”.
- Lai tạo sinh ra quần thể mới: Các cá thể trong quần thể sinh sản sau đó sẽ “lai tạo” để tạo ra “thế hệ kế cận” sẽ tạo thành một quần thể mới, đầy đủ gồm 100 cá thể. Nếu các cá thể chỉ đơn giản là vectơ tham số của số thực, việc lai ghép vectơ 1 với vectơ 2 bao gồm việc lấy một tập con từ vectơ 1 và kết hợp nó với một tập hợp con bổ sung của vectơ 2 để tạo ra một vectơ con mới có cùng kích thước. Ví dụ, giả sử bạn có vectơ 1: [1 2 3] và vectơ 2: [4 5 6]. Vectơ 1 lai ghép với vectơ 2 để tạo ra [1 5 6] và [4 2 3]. Chúng tôi chỉ đơn giản là bắt cặp ngẫu nhiên các cá thể từ các quần thể sinh sản và tái tổ hợp chúng để tạo ra hai con mới cho đến khi chúng ta tạo thành một quần thể mới. Điều này tạo ra sự đa dạng "di truyền" mới với những cá thể hoạt động tốt nhất.
- Đột biến: Giờ đây, chúng ta có một quần thể mới với các cá thể hàng đầu từ thế hệ trước, cùng với các các cá thể trong thế hệ mới. Tại thời điểm này, chúng ta sẽ lặp lại các giải pháp của mình và đột biến ngẫu nhiên một số trong số chúng để đảm bảo rằng chúng ta đưa sự đa dạng di truyền mới vào mọi thế hệ để ngăn chặn sự hội tụ sớm về mức tối ưu cục bộ. Sự đột biến chỉ đơn giản có nghĩa là thêm một chút nhiễu ngẫu nhiên vào các vectơ tham số. Nếu đây là các vectơ nhị phân, đột biến có nghĩa là lật ngẫu nhiên một vài bit; nếu không, chúng ta có thể thêm một số nhiễu Gaussian. Tỷ lệ đột biến cần phải khá thấp, nếu không chúng ta sẽ có nguy cơ phá hỏng các giải pháp tốt hiện có.
- Lặp lại quá trình tiến hoá: Bây giờ chúng ta có một quần thể mới gồm các cá thể bị đột biến từ thế hệ trước. Chúng ta lặp lại quá trình này với quần thể mới trong N số thế hệ hoặc cho đến khi chúng ta đạt đến sự hội tụ (đó là khi điểm chất lượng của quần thể trung bình đã không còn có sự cải thiện đáng kể).
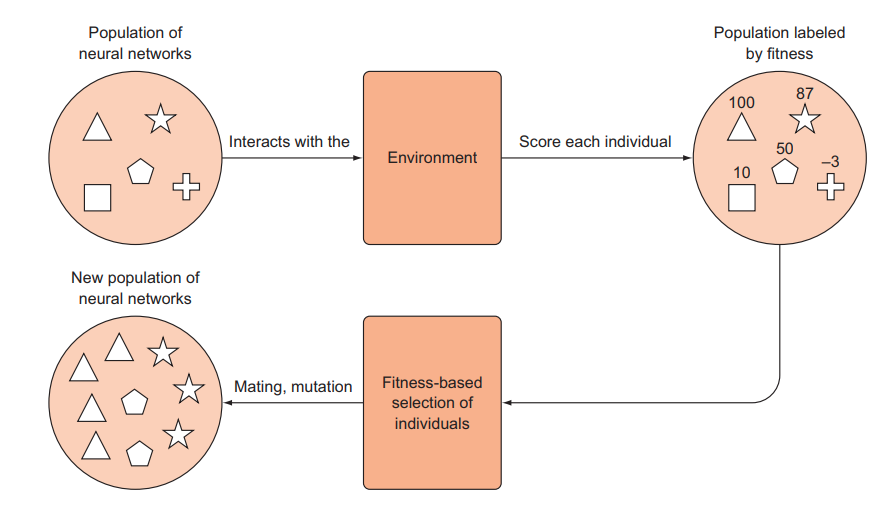
** LƯU Ý**: Có nhiều phương pháp khác nhau để chọn “bố mẹ” cho thế hệ tiếp theo. Một cách đơn giản là gắn một xác suất lựa chọn vào từng cá thể dựa trên điểm chất lượng tương đối của chúng và sau đó lấy mẫu từ phân phối này. Bằng cách này, những cá thể phù hợp nhất sẽ được chọn thường xuyên nhất, nhưng vẫn có một cơ hội nhỏ là cho những cá thể hoạt động kém được chọn. Điều này có thể giúp duy trì sự đa dạng trong quần thể. Một cách khác là chỉ cần xếp hạng tất cả các cá thể và lấy N cá thể hàng đầu, và sử dụng chúng để lai tạo để tạo ra thế hệ tiếp theo. Đối với bất kỳ phương pháp nào thì việc ưu tiên chọn những cá thể tốt nhất để tiến hành việc lai tạo sẽ có hiệu quả tốt hơn. Có một sự đánh đổi giữa việc lựa chọn những ứng cử viên tốt nhất và giảm sự đa dạng trong quần thể — điều này rất giống với sự đánh đổi giữa exploration và exploitation trong học tăng cường.
Bài toán sinh chuối tương đồng
Mô tả bài toán
Chúng ta sẽ tạo một tập hợp các chuỗi ngẫu nhiên và cố gắng phát triển chúng thành một chuỗi mục tiêu do chúng ta lựa chọn, chẳng hạn như “Hello World!”. Tập hợp các chuỗi ngẫu nhiên ban đầu của chúng ta sẽ giống như “gMIgSkybXZyP” và “adlBOMXIrBH”. Chúng ta sẽ sử dụng một hàm có thể cho chúng ta biết các chuỗi này tương tự như thế nào với chuỗi mục tiêu để cung cấp cho chúng ta điểm chất lượng. Sau đó, chúng ta sẽ lấy mẫu các cặp cha mẹ từ quần thể được tính theo fitness score tương đối của chúng, sao cho những cá thể có fitness score cao hơn có nhiều khả năng được chọn để trở thành cha mẹ hơn (tức cá thể có fitness score cao sẽ có tỉ lệ được chọn làm parents lớn hơn các cá thể có fitness score thấp).
Tiếp theo, chúng ta sẽ lai ghép những cặp bố mẹ này (còn được gọi là lai hoặc tái tổ hợp) để tạo ra hai chuỗi con và thêm chúng vào thế hệ tiếp theo. Ngoài ra chúng ta có thể thực hiện đốt biến bằng cách biến đổi các cá thể con cái bằng cách lật ngẫu nhiên một vài ký tự trong chuỗi. Chúng ta sẽ lặp lại quá trình này và hy vọng rằng quần thể mới sẽ trở nên phong phú hơn với các chuỗi rất gần với mục tiêu của chúng ta; có thể ít nhất một mục tiêu sẽ đạt được chính xác mục tiêu của chúng ta (tại thời điểm đó, chúng ta sẽ dừng thuật toán).
Quá trình tiến hóa này của chuỗi được mô tả trong hình dưới đây
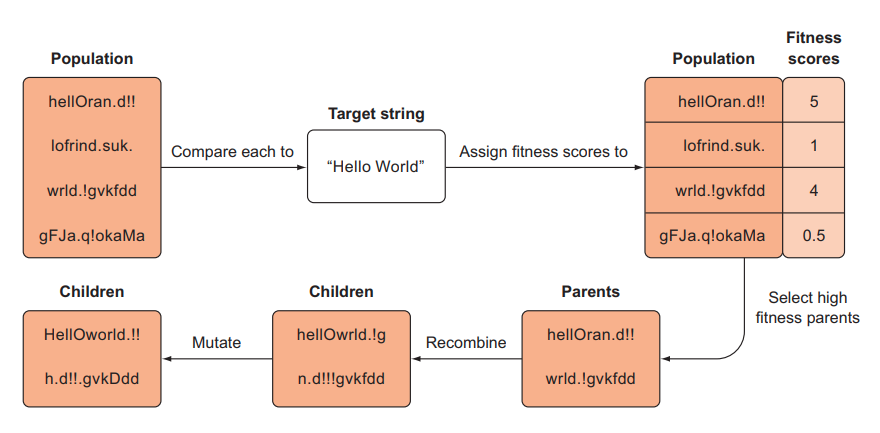
Đây có lẽ là một ví dụ ngớ ngẩn, nhưng đó là một trong những minh chứng đơn giản nhất về thuật toán di truyền và các khái niệm sẽ chuyển trực tiếp sang các nhiệm vụ học tăng cường của chúng ta. Bây giờ chúng ta sẽ tiến hành đi sâu vào code ngay thôi
Code thôi nào
Định nghĩa target string
Đầu tiên chúng ta tiến hành import các thư viên cần thiết và định nghĩa target string. Ở đây chúng ta đang mong muốn các agent sẽ sinh ra các chuối giống với "Hello World" nhất
import random
from matplotlib import pyplot as plt
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,.! "
target = "Hello World!"
Định nghĩa agent
Agent của chúng ta rất đơn giản. Nó sẽ bao gồm hai thuộc tính là string để chứa giá trị của chuỗi mà nó đang biểu diễn và fitness nhằm biểu diễn điểm chất lượng. Điểm nầy có thể đo bằng khoảng cách edit-distance từ string mà agent đang biểu diễn đến chuỗi target. Chúng ta sẽ định nghĩa sau
class Individual:
def __init__(self, string, fitness=0):
self.string = string
self.fitness = fitness
Định nghĩa fitness_score
Như đã trình bày ở phần trên thì chúng ta có thể thực hiện một hàm similar đơn giản giữa hai string để biểu diễn fitness score của agent
from difflib import SequenceMatcher
def similar(a, b):
return SequenceMatcher(None, a, b).ratio()
Khởi tạo quần thể
Chúng ta có thể khởi tạo quần thể bằng cách sinh ra các agent chứa các string ngẫu nhiên. Giả sử quần thể của chúng ta có 100 agents
def spawn_population(length=26,size=100):
pop = []
for i in range(size):
string = ''.join(random.choices(alphabet,k=length))
individual = Individual(string)
pop.append(individual)
return pop
Đột biến
Đây là một bước đã trình bày trong phần lý thuyết. Về cơ bản chúng ta sẽ thay đổi ngẫu nhiên một vài kí tự trong string mà agent đang biểu diễn bởi một xác suất nào đó. Giá sử là 0.01. Tỉ lệ đột biến này phải đủ nhỏ để không bị phá vỡ tính chất tiến hoá của quần thể.
def mutate(x, mut_rate=0.01):
new_x_ = []
for char in x.string:
if random.random() < mut_rate:
new_x_.extend(random.choices(alphabet,k=1))
else:
new_x_.append(char)
new_x = Individual(''.join(new_x_))
return new_x
Tái tổ hợp
Tái tổ hợp là một trong những phép toán quan trọng trong giải thuật di truyền. Nó giúp cho qúa trình tiến hoá tạo ra được các cá thể mới. Ở đây chúng ta thực hiện việc tái tổ hợp đơn giản bằng cánh chọn một điểm chia ngẫu nhiên cross_pt sau đó hoán vị thành phần của hai vector đầu vào tại vị trí điểm chia để tạo thành hai vector mới. Tái tổ hợp là yếu tố then chốt trong quá trình lai tạo.
def recombine(p1_, p2_): #produces two children from two parents
p1 = p1_.string
p2 = p2_.string
child1 = []
child2 = []
cross_pt = random.randint(0,len(p1))
child1.extend(p1[0:cross_pt])
child1.extend(p2[cross_pt:])
child2.extend(p2[0:cross_pt])
child2.extend(p1[cross_pt:])
c1 = Individual(''.join(child1))
c2 = Individual(''.join(child2))
return c1, c2
Đánh giá quần thể
Việc đánh giá quần thể giúp cho chúng ta biết được giải thuật của chúng ta đang hội tụ như thế nào. Việc này đơn giản là lấy fitness_score trung bình của các cá thể trong quần thể
def evaluate_population(pop, target):
avg_fit = 0
for i in range(len(pop)):
fit = similar(pop[i].string, target)
pop[i].fitness = fit
avg_fit += fit
avg_fit /= len(pop)
return pop, avg_fit
Tạo thế hệ tiếp theo
def next_generation(pop, size=100, length=26, mut_rate=0.01):
new_pop = []
while len(new_pop) < size:
parents = random.choices(pop,k=2, weights=[x.fitness for x in pop])
offspring_ = recombine(parents[0],parents[1])
offspring = [mutate(offspring_[0], mut_rate=mut_rate), mutate(offspring_[1], mut_rate=mut_rate)]
new_pop.extend(offspring) #add offspring to next generation
return new_pop
Đây là bước tạo ra thế hệ tiếp theo từ thế hệ có sẵn của chúng ta. Chúng ta có một điểm cần lưu ý trong việc chọn lựa parents.
parents = random.choices(pop,k=2, weights=[x.fitness for x in pop])
Chúng ta để ý rằng ở đây chúng ta lựa chọn ngẫu nhiên có trọng số 2 agent để làm parents cho tiếp hệ tiếp theo. Tại sao mình lại in đậm phần ngẫu nhiên có trọng số bởi lẽ chúng ta sẽ lựa chọn ưu tiên những cá thể nào có fitness_score cao hơn để làm bố mẹ. Nhưng vẫn dành một xác suất nhỏ hơn để những cá thể có finesss nhỏ hơn ở thế hệ hiện tại vẫn có khả năng được lai ghép. Điều này giúp cho quần thể giữ được tính đa dạng trong những thế hệ tiếp theo.
Tiến hành huấn luyện thôi
pop = spawn_population(length=len(target))
num_generations = 400
population_size = 5000
str_len = len(target)
mutation_rate = 0.001 # 0.1% mutation rate per character
pop_fit = []
pop = spawn_population(size=population_size, length=str_len) #initial population
for gen in range(num_generations):
# trainning
pop, avg_fit = evaluate_population(pop, target)
pop_fit.append(avg_fit) #record population average fitness
new_pop = next_generation(pop, size=population_size, length=str_len, mut_rate=mutation_rate)
pop = new_pop
Tiến hành vẽ biểu đồ fitness
Chúng ta có thể vẽ lại biểu đồ thể hiện sự thay đổi của fitness qua từng thế hệ
plt.figure(figsize=(10,5))
plt.xlabel("Generations")
plt.ylabel("Fitness")
plt.plot(pop_fit)
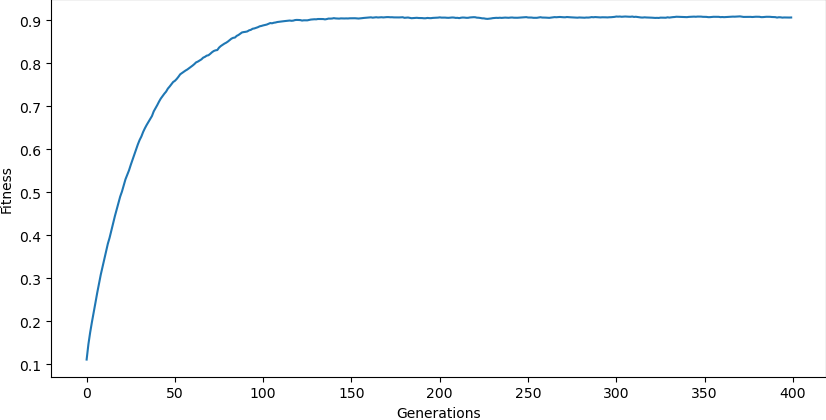
Chúng ta có thể thấy càng về những generations cuối thì điểm fitness trung bình các ít thay đổi và ở mức cao. Điều này chúng tỏ quần thể chúng ta đã chứa những cá thể có fitness tốt nhất với target string
Kiểm tra kết quả
chúng ta tiến hành kiếm tra những cá thể có fitness score cao nhất
pop.sort(key=lambda x: x.fitness, reverse=True) #sort in place, highest fitness first
print(pop[0].string)
>>> 'HelloWorld!!'
Chúng ta thấy rằng từ những chuỗi ngâu nhiên ban đầu nhưng qua quá trình tiến hoá bằng giải thuật di truyền, bản thân quần thể của chúng ta có thể sinh ra được các chuỗi giống như chuỗi target lúc đầu mà không cần phải tối ưu những mạng nơ ron phức tạp.
Kết luận
Giải thuật di truyền là một trong những thuật toán có tư tưởng gần gũi với qua trình tiến hoá nhất. Chúng ta có thể áp dụng linh hoạt nó trong nhiều bài toán khác nhau. Việc áp dụng nó cho Reinforcement Learning giúp chúng ta có thể thay thế các mạng nơ ron phức tạp. Xin chào các bạn và hẹn gặp lại trong những bài tiếp theo .
All rights reserved
