
MLP-Mixer - Hướng giải quyết các bài toán Computer Vision mới bên cạnh CNN và Transformer
Bài đăng này đã không được cập nhật trong 5 năm
Có thể nói rằng Convolutional Neural Network hay CNN đã và đang được cho là mô hình vô cùng phù hợp cho thị giác máy tính. Bên cạnh đó các mạng dựa trên cơ chế attention, chẳng hạn như Vision Transformer, cũng dần được quan tâm và sử dụng nhiều hơn. Tuy vậy trong paper mới được publish của mình với tên gọi MLP-Mixer: An all-MLP Architecture for Vision, nhóm Google Brain ở Zurich và Berlin đã tuyên bố rằng năm 2021 rồi ai cùng dùng mấy cái đấy nữa mặc dù các kiến trúc trên đều mang lại hiệu xuất cũng như độ chính xác cao, việc sử dụng chúng đôi khi là không cần thiết. Vậy nên trong bài viết này, chúng ta sẽ cùng tìm hiểu cách thức hoạt động của kiến trúc này cũng như sự khác biệt của nó với các kiến trúc mạng khác.
Tổng quan kiến trúc của MLP-Mixer
Như có thể dễ dàng nhận thấy, sự xuất hiện của các bộ dữ liệu với kích thước ngày càng lớn và cùng với đó là khả năng tính toán của máy móc càng ngày càng được cải thiện dẫn đến nhiều kiến trúc mô hình được ra đời cũng như dần được cải tiến. Trong khi Convolutional Neural Network đã và đang là tiêu chuẩn thực tế cho thị giác máy tính, gần đây Vision Transformers (ViT), một giải pháp thay thế dựa trên các lớp self-attention đã đạt được hiệu suất của các mô hình hiện đại được công bố trước đó. ViT tiếp tục xu hướng lâu dài là loại bỏ các đặc trưng "hand-crafted" và "inductive biases" khỏi các mô hình và dựa vào việc học hỏi nhiều hơn từ dữ liệu thô.
Tiếp nối truyền thống tre chưa già mà măng đã mọc, kiến trúc MLP-Mixer được nhóm tác giả đề xuất và được cho là đơn giản hơn các mô hình trước đây nhưng không hề thua kém về hiệu xuất khi không sử dụng đến các lớp convolution hay cơ chế self-attention. Thay vào đó kiến trúc của Mixer hoàn toàn dựa trên perceptron nhiều lớp, thứ được áp dụng nhiều lần trên thông tin không gian cũng như các đặc trưng theo channel.
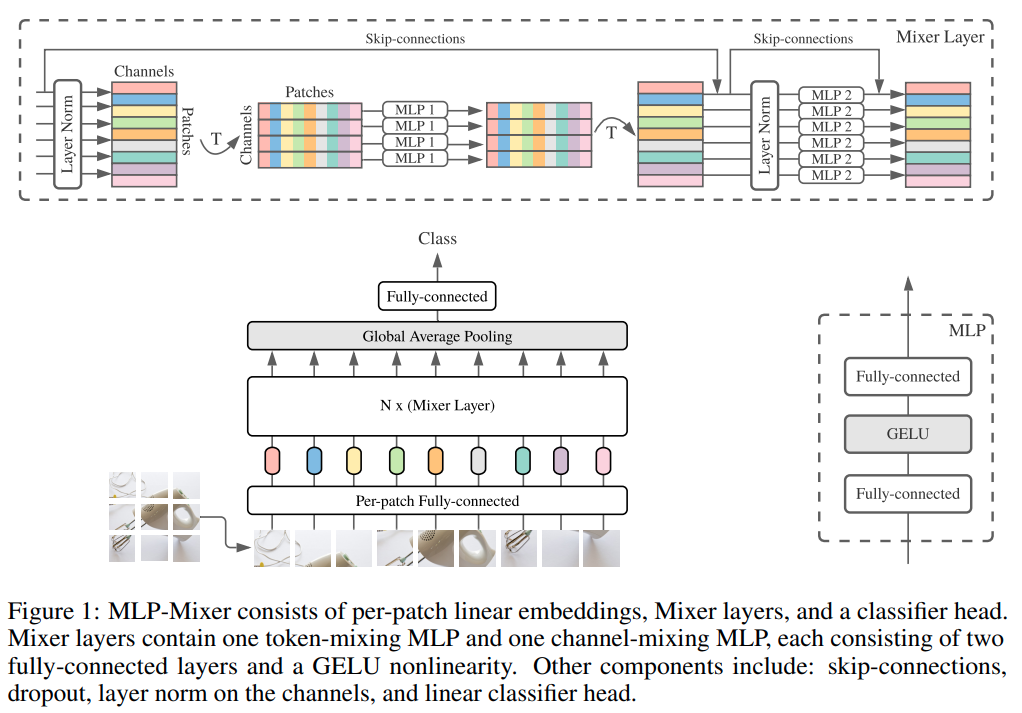
Dữ liệu đầu vào
Hình minh họa trên được trích từ paper mô tả tổng quan kiến trúc của Mixer. Kiến trúc này nhận đầu vào là một chuỗi các phần của hình ảnh được chiếu tuyến tính (được đề cập trong paper với khái niệm token) như một bảng có kích thước là . Như trong hình minh họa trên đang thể hiện kiến trúc của một mô hình phân lớp, hình ảnh đầu vào được chia thành 9 phần tương ứng với 9 token là đầu vào cho mạng. Để hình dung rõ hơn, ta hãy cùng quan sát phần mã Pytorch được cài đặt cho phần PatchEmbed ở repo pytorch-image-models được thể hiện ở hình dưới đây.
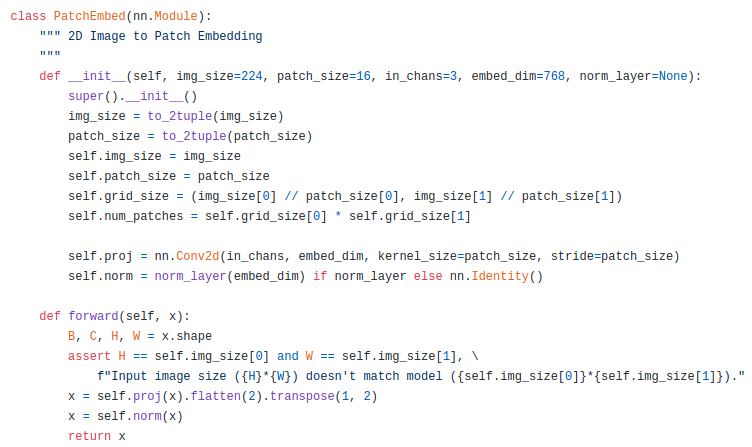
Có thể thấy rằng qua module này, ảnh đầu vào với kích thước được chia thành từng phần với kích thước sau đó được từng phần nhỏ kia được chuyển đổi thành một vector có kích thước do ảnh đầu vào có 3 channel lần lượt là R, G, B như thông thường. Khi đó bảng giá trị đầu vào sẽ có kích thước là do ta có tổng cộng token tương ứng với từng đó phần của ảnh đầu vào.
Cấu trúc của MixerLayer
Mixer lấy ý tưởng từ việc sử dụng convolution với các kernel nhỏ đến cực điểm: bằng cách giảm kích thước kernel xuống 1 × 1 và việc này biến các phép convolution thành phép nhân ma trận dense tiêu chuẩn được áp dụng độc lập cho từng vị trí không gian. Tuy vậy chỉ riêng sửa đổi này không cho phép tổng hợp thông tin không gian và để bù lại, nhóm tác giả áp dụng phép nhân ma trận dense được áp dụng cho mọi đối tượng trên tất cả các vị trí không gian.
Điểm này khiến cho MLP-Mixer khác với các loại kiến trúc mạng khác khi thay vì dùng các thành phần convolution hay cơ chế self-attention, Mixer sử dụng MixerLayer được tạo nên bằng cách sử dụng hai loại MLP như sau:
- Channel-mixing MLP: cho phép giao tiếp giữa các channel khác nhau; chúng hoạt động trên từng token một cách độc lập và lấy các hàng riêng lẻ của bảng làm đầu vào. T
- Token-mixing MLP: cho phép giao tiếp giữa các vị trí không gian khác nhau (token); chúng hoạt động trên từng channel độc lập và lấy các cột riêng lẻ của bảng làm đầu vào.
Hai loại lớp này được xen kẽ để cho phép tương tác của cả hai thứ nguyên đầu vào là theo từng token và theo từng channel và tạo nên một MixerLayer.
Quay trở lại với hình minh họa, ta có thể thấy rằng trong mỗi MixerLayer, bảng dữ liệu đầu vào sau khi qua một LayerNorm sẽ được chuyển vị và truyền qua các token-mixing MLP với theo từng channel sau đó tiếp tục được chuyển vị về kích thước cũ và truyền qua các channel-mixing MLP sau khi đã truyền qua một LayerNorm thứ hai. Bên cạnh đó, trước mỗi LayerNorm luôn có skip-connections, là một kĩ thuật được đã giới thiệu tại paper Deep Residual Learning for Image Recognition, cho phép đào tạo các mạng thần kinh rất sâu với hàng trăm lớp và được cải thiện hơn nữa hiệu suất.
Phần mã dưới đây thể hiện cách thức cài đặt của MixerLayer. Có thể thấy rằng cấu trúc của MixerLayer được cài đặt đầy đủ trong class MixerBlock (không giống như repo nào đấy của Yolov4 treo đầu dê bán thịt chó, trong paper có PAN mà tìm không thấy đâu) khi mà mỗi MixerBlock có hai LayerNorm trước mỗi lớp MLP cũng như cài đặt mã phục vụ cho quá trình skip-connections .

Cuối cùng, thành phần nhỏ nhấn được thể hiện trong hình minh họa là các khối MLP. Chúng được cấu tạo bởi hai lớp fully-connected và một hàm kích hoạt phi tuyến tính được áp dụng độc lập cho mỗi hàng của tensor dữ liệu đầu vào cụ thể là hàm GELU có công thức là . Mã cài đặt của chúng được thể hiện trong hình dưới đây:

So sánh với các kiến trúc khác
Do ý tưởng thiết kế được bắt nguồn từ ý tưởng từ các tài liệu trên Convolutional Neural Network và Transformers, MLP-Mixer có một số điểm tương đồng cũng như khác biệt với hai kiểu kiến trúc trên.
Đầu tiên, các token-mixing MLP hoạt động trên từng channel độc lập và lấy các cột riêng lẻ của bảng làm đầu vào. Ràng buộc các tham số của channel-mixing MLP (trong mỗi lớp) là một lựa chọn tự nhiên — nó cung cấp bất biến vị trí (nguyên văn là positional invariance, thể hiện việc ta có thể phát hiện và phân lớp các đối tượng kể cả khi vị trí chúng được thay đổi) vốn là một tính năng nổi bật của việc sử dụng convolution.
Tuy vậy, việc ràng buộc các thông số trên các channel ít được sử dụng hơn. Ví dụ như việc lấy separable convolution, được sử dụng trong một số kiến trúc CNN, thường được thực hiện bằng cách áp dụng áp dụng convolution cho từng channel độc lập, sử dụng một kernel khác nhau để áp dụng cho mỗi channel. Điều này không giống như các token-mixing MLP trong Mixer khi chúng chia sẻ cùng một kernel (của receptive fied) cho tất cả các channel. Do đó như được trình bày trong paper, điều này dẫn đến việc ràng buộc tham số đã ngăn không cho kiến trúc không phát triển quá nhanh khi tăng kích thước bảng dữ liệu và giúp đến tiết kiệm bộ nhớ đáng kể.
Cuối cùng, mỗi lớp trong Mixer (ngoại trừ lớp chiếu các phần ảnh đầu vào ban đầu) nhận một đầu vào có cùng kích thước. Thiết kế "đẳng hướng" này gần giống với Transformer hoặc các kiến trúc RNN sâu khác. Điều này không giống như hầu hết các kiến trúc mạng tích chập khi các kiến trúc mạng này có cấu trúc hình chóp: các lớp sâu hơn có đầu vào độ phân giải thấp hơn, nhưng nhiều channel hơn. Và hơn nữa, không giống như kiến trúc ViT, Mixer không sử dụng embedding cho thông tin vị trí bởi các token-mixing MLP có thông tin về thứ tự các token đầu vào và do đó nó có thể học thể hiện thông tin vị trí.
Kết quả thực nghiệm
Để chứng minh hiệu năng của kiến trúc mô hình này, nhóm tác giả đã thực nghiệm trên các một số bộ dữ liệu lớn. Kết quả thu được như sau được thể hiện ở hình được trích từ paper dưới đây thể hiện các thông tin về độ chính xác và tài nguyên được sử dụng khi so sánh Mixer với các mô hình hiện đại khác. Các cột “ImNet” và “ReaL” đề cập đến các nhãn xác thực ImageNet ban đầu và các nhãn ReaL đã được làm sạch trong khi đó “Avg 5 ”là viết tắt của hiệu suất trung bình trên tất cả năm tác vụ ImageNet, CIFAR-10, CIFAR-100, Pets, Flowers.
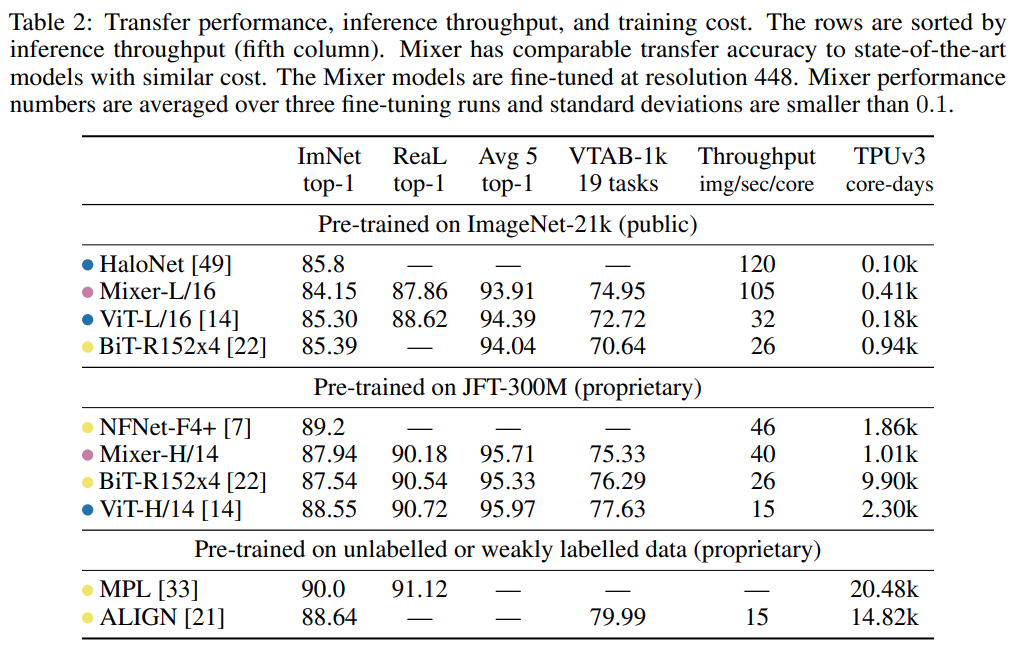
Mặc dù hoạt động không tốt khi train từ đầu trên mageNet-1k, Mixer đạt được hiệu suất tổng thể khá cao (84,15% top-1 trên ImageNet) khi được pre-trained trên ImageNet-21k với Regularization bổ sung, mặc dù hơi kém so với các mô hình khác. Regularization trong trường hợp này là cần thiết và Mixer sẽ bị overfit nếu không sử dụng nó, và theo nhóm tác giả, điều này phù hợp với các quan sát tương tự đối với ViT.
Khi kích thước của tập dữ liệu tăng lên, hiệu suất của Mixer sẽ cải thiện đáng kể. Đặc biệt, Mixer-H/14 đạt độ chính xác top-1 là 87,94% trên ImageNet, tốt hơn 0,5% so với BiTResNet152x4 và chỉ thấp hơn 0,5% so với ViT-H/14. Đáng chú ý, Mixer-H/14 chạy nhanh hơn 2,5 lần so với ViT-H/14 và gần như gấp đôi BiT.
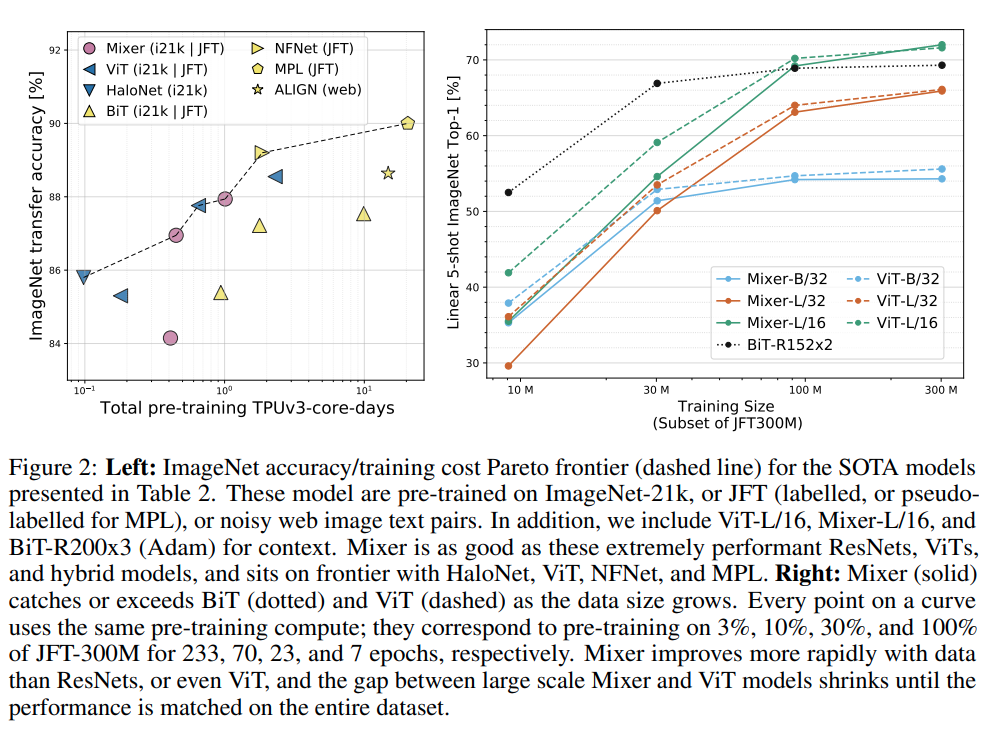
Tuy được tuyên bố như vậy trong paper, có một số ý kiến khác được đưa ra khi thảo luận về về MLP-Mixer. BeatLeJuce trên Reddit cho rằng MLP-Mixer sẽ không hoạt động hiệu quả trên các tập dữ liệu với kích thước nhỏ hơn. Thậm chí, kardeng trên Reddit cho rằng việc sử dụng MLP trong MLP-Mixer không phải quá độc đáo và kiến trúc này không có tiềm năng đáng kể vì các lớp được kết nối đầy đủ đã là một phần của kiến trúc CNN ngay từ đầu (LeNet) nhưng đã dần bị loại bỏ theo thời gian. Bằng cách giới hạn các tương tác đến "chỉ giữa các vị trí không gian", các bậc tự do được giảm xuống mức mà bây giờ MLP-Mixer chỉ cần 100 triệu hình ảnh tiền đào tạo hoặc 1 triệu hình ảnh tiền đào tạo và Regularization để đạt được kết quả gần như SOTA. Một số khác cũng cho rằng bên cạnh việc đòi hỏi quá nhiều dữ liệu, đi kèm với độ lớn của model và dữ liệu là đòi hỏi năng lực tính toán rất lớn.
Kết luận
Do là miếng gạch đầu tiên đặt vào một hướng đi mới nhằm giải quyết các bài toán thị giác máy, MLP-Mixer có kiến trúc khá đơn giản và bên cạnh đó còn khá nhiều vấn đề cần được giải quyết như việc cần quá nhiều dữ liệu để huấn luyện cũng như cần có khả năng tính toán tương xứng với kích thước của mô hình, vốn được cho rằng khá lớn so với các kiến trúc mạng khác. Trên hết, theo nhóm tác giả đề cập trong paper, họ hy vọng rằng kết quả nghiên cứu này sẽ thúc đẩy các nghiên cứu sâu hơn, vượt ra ngoài lĩnh vực của các mô hình đã được thiết lập dựa trên convolution và self-attention và sẽ đặc biệt thú vị khi xem liệu một thiết kế như vậy có hoạt động trong NLP hay các miền khác hay không. Bài viết đến đây là kết thúc cảm ơn mọi người đã giành thời gian đọc.
Tài liệu tham khảo
All rights reserved
