MiroFish — Phân tích kiến trúc Swarm Intelligence Engine "dự đoán vạn vật"
MiroFish — Phân tích kiến trúc Swarm Intelligence Engine "dự đoán vạn vật"
Repo: https://github.com/666ghj/MiroFish | Đang trending trên GitHub
TL;DR
MiroFish là một swarm intelligence engine — upload tài liệu thực tế (tin tức, báo cáo, tiểu thuyết), AI tự xây dựng một thế giới ảo với hàng nghìn agent có nhân cách riêng, cho chúng "sống" trên mạng xã hội giả lập, rồi rút ra dự đoán về xu hướng, dư luận, hoặc kết cục câu chuyện.
Demo ấn tượng nhất của team: dự đoán phần kết thất truyền của Hồng Lâu Mộng chỉ từ 80 chương đầu.
Kiến trúc tổng thể
[Vue.js Frontend] ←→ [Flask Backend] ←→ [Zep GraphRAG]
Step 1-5 Services (Memory)
↕
[OASIS Simulator] (Twitter + Reddit giả)
↕
[LangChain ReACT] (Report Agent)
Stack:
- Frontend: Vue 3 + Vite, wizard UI 5 bước
- Backend: Python Flask + UV
- LLM: OpenAI-compatible — gọi được GPT, Claude, Qwen, MiniMax...
- Memory/Graph: Zep — knowledge graph + long-term memory
- Simulator: OASIS — framework mô phỏng mạng xã hội đa agent
Pipeline 5 bước
Bước 1 — Graph Build | Bước 2 — Env Setup | Bước 3 — Simulation | Bước 4 — Report | Bước 5 — Interaction
(Xem phần phân tích kỹ thuật bên dưới để hiểu rõ từng bước)
Những điểm kỹ thuật đáng học
1. LLM Tự Sinh Ontology
Thay vì developer phải định nghĩa schema cứng, MiroFish để LLM đọc tài liệu và tự quyết định cần những loại entity và relationship gì. Không hardcode gì cả.
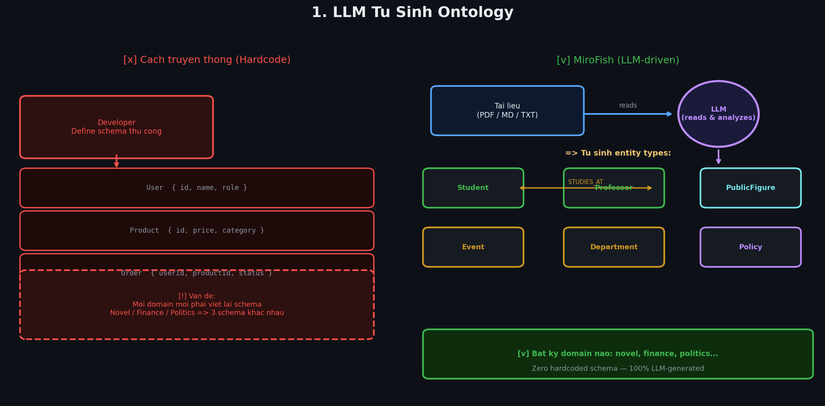
Cách hoạt động:
Khi bạn upload tài liệu về một trường đại học, LLM đọc và tự sinh ra:
{
"entity_types": ["Student", "Professor", "Department", "Event", "Policy"],
"edge_types": [
{"name": "STUDIES_AT", "source": "Student", "target": "Department"},
{"name": "SUPERVISED_BY", "source": "Student", "target": "Professor"},
{"name": "HEAD_OF", "source": "Professor", "target": "Department"}
]
}
Upload tài liệu về thị trường tài chính? LLM sẽ tự sinh Investor, Asset, Market, Regulation... Không cần thay đổi một dòng code nào. Đây là điểm flexible nhất của toàn bộ system.
# backend/app/services/ontology_generator.py
class OntologyGenerator:
def generate(self, document_texts, simulation_requirement, additional_context=None):
# LLM đọc tài liệu và trả về ontology hoàn chỉnh
# Zero hardcoded schema
2. GraphRAG làm Memory Tầng Nền
Không phải vector search đơn thuần. Zep build knowledge graph với ontology tùy biến — agent có "ký ức" dưới dạng graph, phản ánh quan hệ xã hội thực tế.
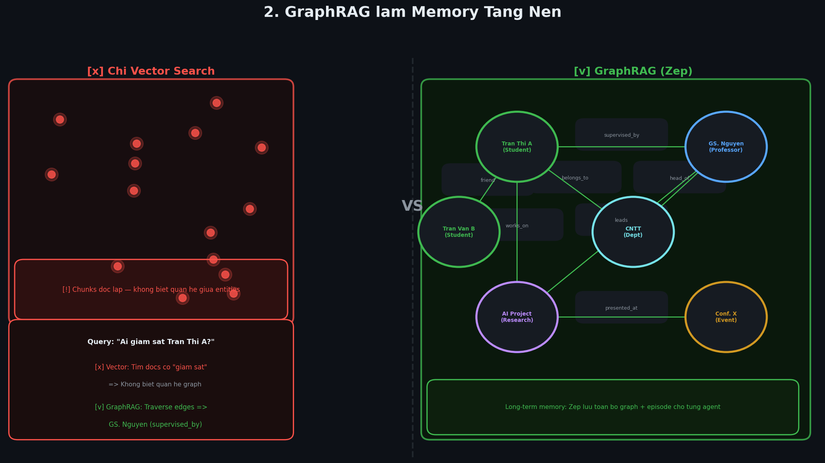
Tại sao GraphRAG tốt hơn pure vector search?
Khi query "Ai giám sát Trần Thị A?":
- Vector search: tìm các chunk văn bản có chứa từ "giám sát" — không biết quan hệ giữa các entity
- GraphRAG: traverse edges
supervised_by→ ngay lập tức tìm raGS. Nguyễn
Quan trọng hơn, agent được build từ đây không chỉ biết facts mà còn hiểu mạng lưới quan hệ xã hội — ai là bạn bè, ai là đối thủ, ai ảnh hưởng ai. Điều này tạo ra hành vi simulation thực tế hơn nhiều.
# Zep build graph với custom ontology
builder.set_ontology(graph_id, ontology)
# Agent sau đó được tạo ra từ graph entities này
# => Mỗi agent có long-term memory dưới dạng subgraph
3. Smart Caching Tránh Lãng Phí LLM
Trước khi generate lại, system kiểm tra is_prepared — nếu đã có profiles và config rồi thì skip, không gọi LLM lại.
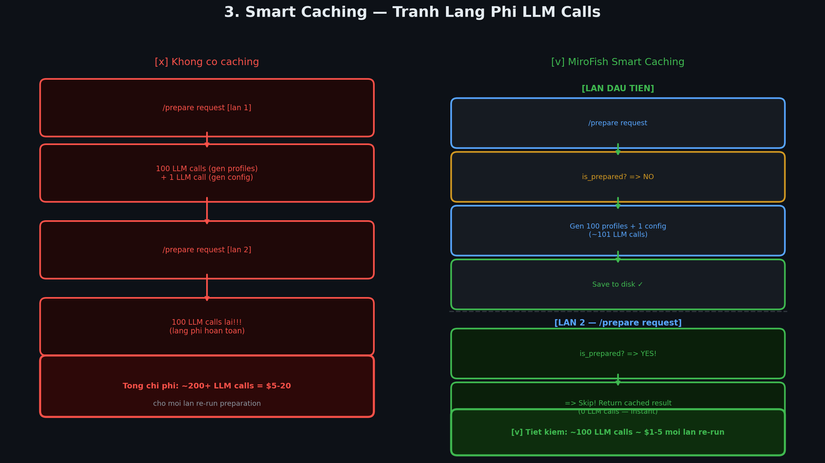
Tại sao điều này quan trọng về mặt kinh tế?
Với 100 agents:
- Mỗi profile generation = ~1 LLM call
- 1 simulation config generation = ~1 LLM call
- Tổng: ~101 LLM calls / lần prepare
Nếu không có caching, mỗi lần restart server hay re-run sẽ tốn thêm ~101 calls. Với GPT-4o, con số này có thể là $1-5 mỗi lần — cộng lại rất nhanh.
# backend/app/api/simulation.py
def _check_simulation_prepared(simulation_id: str) -> tuple:
"""
Kiểm tra: state.json tồn tại + status in ["ready","running","completed"]
+ config_generated = True
+ reddit_profiles.json và twitter_profiles.csv tồn tại
Nếu đủ điều kiện => skip toàn bộ LLM generation
"""
required_files = [
"state.json",
"simulation_config.json",
"reddit_profiles.json",
"twitter_profiles.csv"
]
# ... kiểm tra từng file
if all files exist and config_generated:
return True, prepare_info # => Không gọi LLM nào cả
4. IPC qua File System
Cách giao tiếp giữa Flask và OASIS process: Flask ghi file lệnh vào commands/, OASIS poll và ghi response vào responses/.
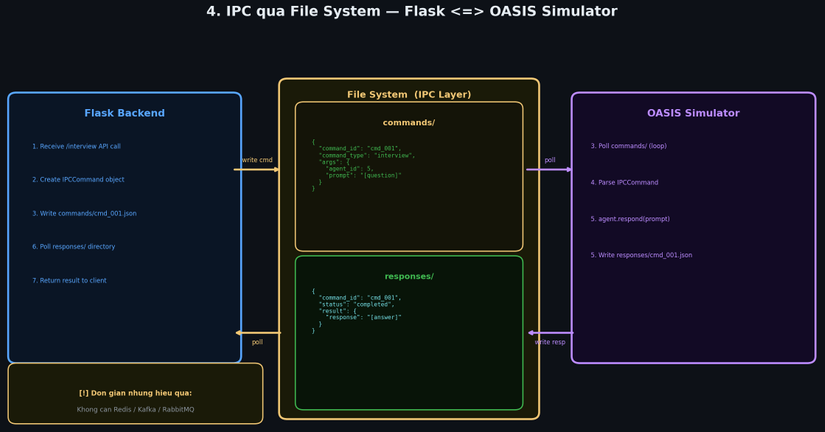
Tại sao dùng file thay vì message queue?
Flask chạy như một web server bình thường. OASIS simulator là một Python subprocess nặng, có vòng lặp simulation riêng. Hai process này cần giao tiếp để implement tính năng Interview (hỏi chuyện agent real-time).
Thay vì dựng Redis/RabbitMQ/Kafka — phức tạp và overkill cho một research project — họ dùng file system:
# Flask side: ghi command
command = IPCCommand(
command_id="cmd_001",
command_type=CommandType.INTERVIEW,
args={"agent_id": 5, "prompt": "..."}
)
# Write to: uploads/simulations/{sim_id}/commands/cmd_001.json
# OASIS side: poll & execute
while True:
commands = scan_commands_dir()
for cmd in commands:
result = execute(cmd)
write_response(result) # responses/cmd_001.json
time.sleep(0.1)
Thô nhưng không có single point of failure, không cần infra thêm, dễ debug (chỉ cần cat file là thấy toàn bộ state).
Hạn chế thực tế: Race condition nếu nhiều simulation chạy song song, và scale kém nếu lên production — nhưng với research prototype, đây là tradeoff hợp lý.
5. Post-Simulation Interview
Sau khi sim xong, agent vẫn còn "sống" trong graph memory. Có thể hỏi chuyện riêng từng agent — họ trả lời dựa trên toàn bộ lịch sử hành động và ký ức của mình.
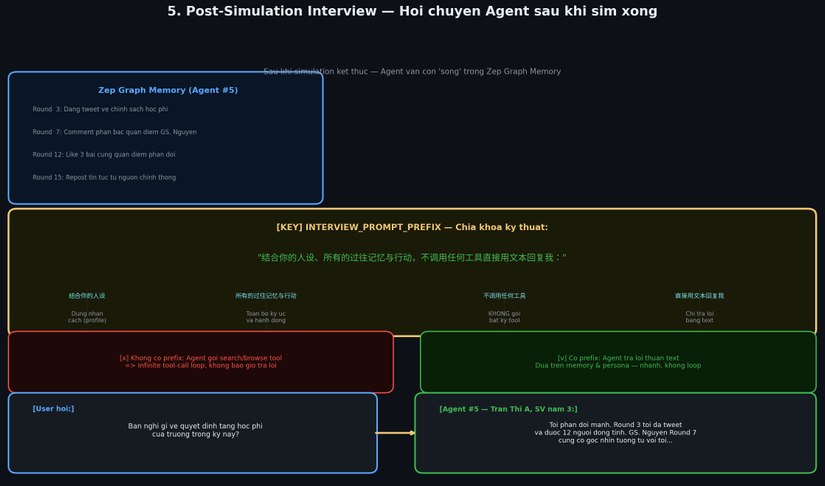
Kỹ thuật then chốt — Interview Prompt Prefix:
INTERVIEW_PROMPT_PREFIX = "结合你的人设、所有的过往记忆与行动,不调用任何工具直接用文本回复我:"
Tạm dịch: "Dựa trên nhân cách, toàn bộ ký ức và hành động của bạn, KHÔNG gọi bất kỳ tool nào, hãy trả lời thẳng bằng text:"
Tại sao cần prefix này?
Trong OASIS, mỗi agent được implement như một LLM agent có tool-calling capability (search, post, comment...). Khi nhận câu hỏi thông thường, agent sẽ mặc định gọi tool để "tìm kiếm thêm thông tin" trước khi trả lời — tạo ra infinite loop không bao giờ kết thúc.
Prefix này làm hai việc:
- Nhắc nhở context: "Dùng memory của mình, không cần search thêm"
- Chặn tool call: "Không gọi tool" — câu lệnh tường minh ngăn agent invoke bất kỳ function nào
def optimize_interview_prompt(prompt: str) -> str:
if prompt.startswith(INTERVIEW_PROMPT_PREFIX):
return prompt # tránh thêm prefix hai lần
return f"{INTERVIEW_PROMPT_PREFIX}{prompt}"
Một trick nhỏ nhưng critical — thiếu nó thì tính năng Interview hoàn toàn không hoạt động.
Điểm mạnh / Điểm yếu tổng kết
Mạnh:
- Pipeline modular rõ ràng, dễ extend
- Async task management đàng hoàng với progress callback
- OpenAI-compatible → không lock-in vào bất kỳ LLM provider nào
- Smart caching tiết kiệm chi phí đáng kể
- Retry mechanism cho profile generation
Yếu / Rủi ro:
- IPC qua file — scale kém, race condition tiềm ẩn
- Chi phí LLM cao khi số agent lớn (100 agents = 100+ LLM calls chỉ để setup)
- Zep dependency nặng — nếu Zep API down là toàn bộ pipeline bị block
- Thiếu authentication trên API endpoints — không thể deploy raw ra production
Kết luận
Đây là research prototype chất lượng cao. Concept "digital twin of society" là một hướng đi có market thực sự. Bottleneck chính là cost per simulation và latency. Nếu giải quyết được hai điều này (batching, cheaper models cho profile gen, local graph), đây là sản phẩm có thể đi xa.
Repo đáng star và theo dõi nếu bạn quan tâm đến multi-agent simulation, social computing, hoặc AI prediction systems.
All rights reserved
