Mặt tối của Bộ nhớ Cache: những "cái bẫy" chết người
Hãy tưởng tượng: Đồng hồ điểm đúng 12:00 đêm. Cổng bán vé concert của BlackPink chính thức mở. Hàng triệu người hâm mộ cùng lúc nhấn F5 (tải lại trang) với hy vọng giành được 1 trong 50.000 tấm vé hiếm hoi. Chỉ trong một phần nghìn giây, một cơn sóng thần "request" (yêu cầu) khổng lồ đổ sập xuống hệ thống.
Nếu toàn bộ lượng truy cập này đập thẳng vào Database (Cơ sở dữ liệu gốc), máy chủ của bạn sẽ sụp đổ ngay lập tức 💥. Đó là lúc Caching (Bộ nhớ đệm)—điển hình là Redis—xuất hiện như một vị cứu tinh. Bằng cách lưu trữ dữ liệu trên RAM để đọc và ghi với tốc độ siêu tốc, Caching đóng vai trò như một tấm khiên vững chắc, gánh vác hàng triệu lượt truy cập thay cho Database.
Thế nhưng, kiến trúc Caching lại là một con dao hai lưỡi 🗡️. Nếu thiết kế vòng đời dữ liệu không khéo léo, chính tấm khiên này lại tạo ra những "cái bẫy" chí mạng. Chỉ một khoảnh khắc mất đồng bộ, hệ thống phòng thủ sẽ vỡ vụn, Database bị đánh gục và dữ liệu thanh toán của người dùng có thể sai lệch hoàn toàn.
Trong bài viết này, chúng ta sẽ cùng mổ xẻ 4 cạm bẫy cốt lõi của nghệ thuật Caching—từ những trận tuyết lở dữ liệu đến sự bất nhất quán thầm lặng—và giải mã cách kiến trúc hệ thống thực chiến được xây dựng để sống sót qua những "cơn bão" Flash Sale cường độ cao.
"Cái bẫy" số 1: Cache Avalanche (Tuyết lở bộ nhớ đệm)
1. Cơ chế của Cache Avalanche
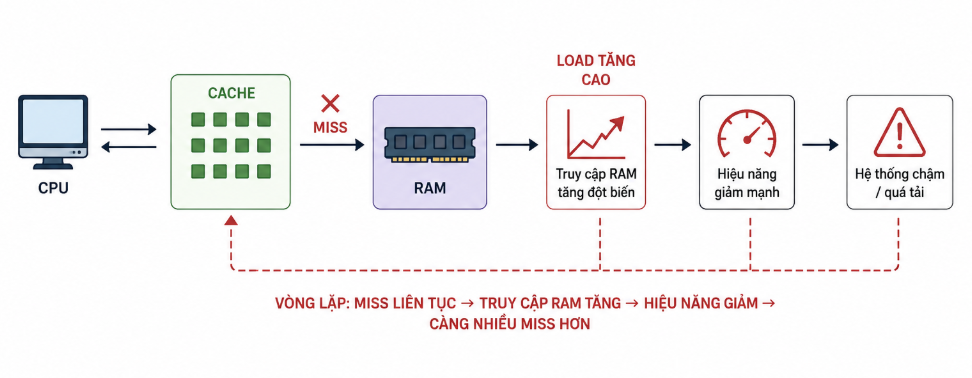
Hiện tượng "tuyết lở" xảy ra khi một lượng lớn các khóa (key) trong cache hết hạn (TTL - Time to Live) vào cùng một thời điểm. Hãy hình dung một hệ thống thương mại điện tử vào ngày Flash Sale. Bạn tải trước hàng ngàn sản phẩm lên Redis lúc 00:00 và đặt thời gian sống (TTL) cho tất cả là đúng 2 giờ. Điều gì sẽ xảy ra vào đúng lúc 02:00?
- Toàn bộ dữ liệu của các sản phẩm đó bốc hơi khỏi cache cùng một microsecond.
- Hàng vạn yêu cầu truy cập mới từ người dùng đổ vào hệ thống, nhưng không tìm thấy dữ liệu trong cache (Cache Miss).
- Tất cả các truy vấn này buộc phải chạy thẳng xuống Database để tìm dữ liệu. Database không chịu nổi lượng tải đột biến này và sụp đổ 💥.
2. Giải pháp: Sử dụng Jitter (Thêm giá trị ngẫu nhiên)
Để tránh việc các key "nắm tay nhau" hết hạn cùng lúc, chúng ta phải phá vỡ sự đồng bộ đó. Thay vì dùng một mức TTL cố định, ta sẽ cộng (hoặc trừ) thêm một khoảng thời gian ngẫu nhiên (Jitter) vào TTL mặc định của từng key.
Ví dụ: Thay vì đặt toàn bộ TTL = 120 phút, chúng ta thiết lập cơ chế: TTL = 120 phút + random(1, 15) phút.
Lúc này, các key sẽ "rụng" rải rác từ phút 121 đến phút 135. Những key hết hạn trước sẽ được truy vấn Database và nạp lại vào cache, giúp phân tán áp lực lên Database theo thời gian.
Bây giờ, giả sử bạn quản lý hai loại dữ liệu: một loại rất ít khi thay đổi (như danh sách các tỉnh thành) và một loại thay đổi liên tục (như giá cổ phiếu theo giây). Theo bạn, khi thiết lập khoảng thời gian ngẫu nhiên (Jitter) lớn hay nhỏ, chúng ta cần căn cứ vào đặc tính nào của hai loại dữ liệu này?
Khi thiết lập khoảng thời gian ngẫu nhiên (Jitter), chúng ta cần căn cứ vào tần suất thay đổi dữ liệu và yêu cầu về độ trễ (thời gian thực) của hệ thống.
Dưới đây là chi tiết cách áp dụng cho hai loại dữ liệu bạn vừa phân tích:
1. Đối với dữ liệu tĩnh (Ít thay đổi)
-
Ví dụ: Danh sách tỉnh thành, danh mục sản phẩm, cấu hình hệ thống cơ bản.
-
Đặc tính: Dữ liệu này có thể tồn tại nhiều ngày hoặc nhiều tháng mà không bị sai lệch. Người dùng xem dữ liệu chậm hơn vài giờ cũng không gây ra hậu quả gì.
-
Chiến thuật Jitter: Khung thời gian ngẫu nhiên có thể được đặt rất lớn.
-
Ví dụ: TTL = 7 ngày + random(1 đến 24) giờ.
-
Việc rải rác thời gian hết hạn trong hẳn một ngày giúp loại bỏ hoàn toàn nguy cơ tuyết lở mà không làm ảnh hưởng đến tính chính xác của ứng dụng.
-
2. Đối với dữ liệu động (Thay đổi liên tục)
-
Ví dụ: Giá cổ phiếu, tỷ giá tiền tệ, số lượng hàng tồn kho trong sự kiện Flash Sale.
-
Đặc tính: Tính thời gian thực là sống còn. Nếu hiển thị giá cổ phiếu chậm vài phút, người dùng có thể mất tiền.
-
Chiến thuật Jitter: Khung thời gian ngẫu nhiên phải thật nhỏ.
-
Ví dụ: TTL = 10 giây + random(100 đến 1000) mili-giây.
-
Khoảng ngẫu nhiên chỉ tính bằng mili-giây đủ để các key không rụng cùng đúng một phần nghìn giây, nhưng vẫn đảm bảo dữ liệu luôn được làm mới liên tục để phục vụ người dùng.
-
"Cái bẫy" số 2: Cache Breakdown (Xuyên phá điểm nghẽn / Hot Key)
1. Cơ chế của Cache Breakdown
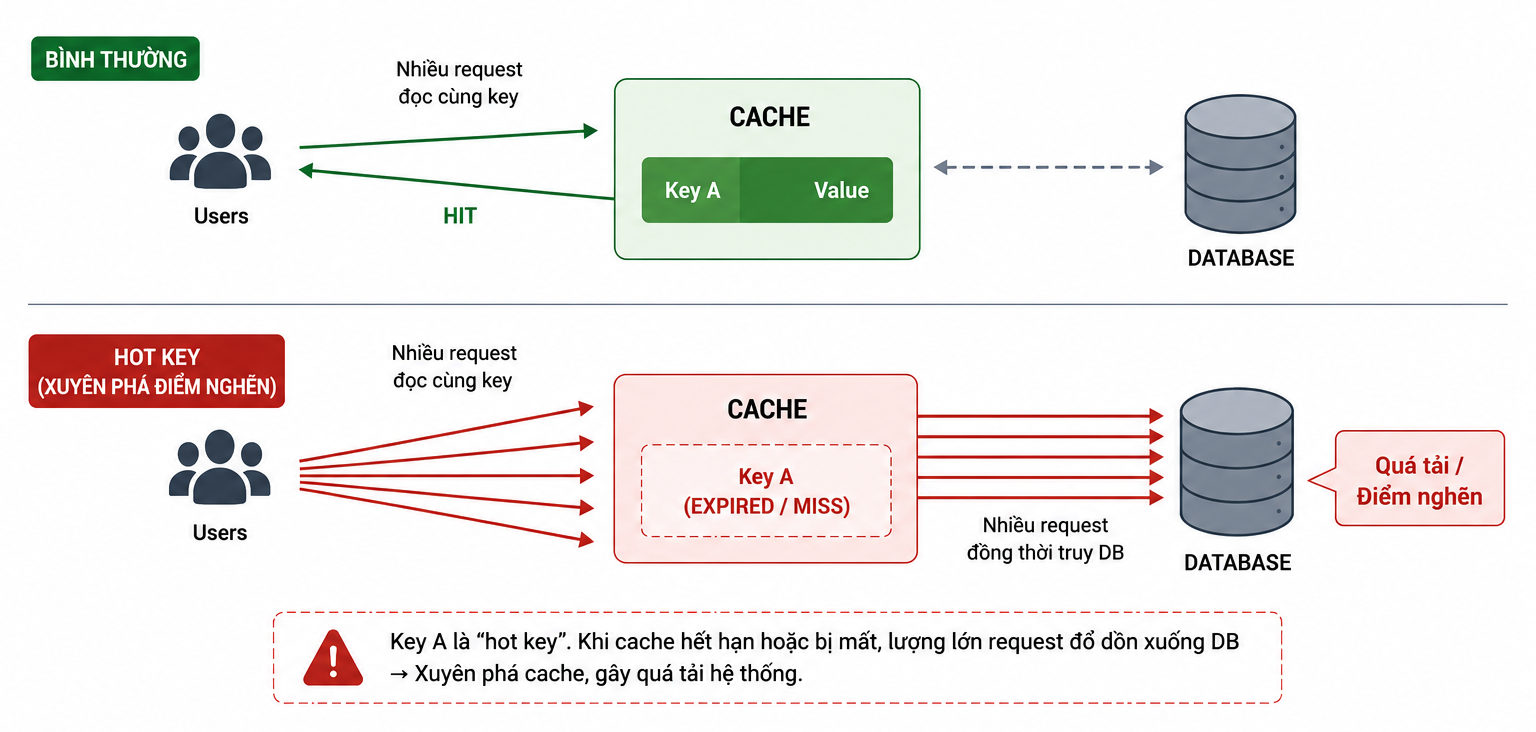
Nếu Cache Avalanche là thảm họa do hàng loạt key hết hạn, thì Cache Breakdown lại là "nhát dao chí mạng" đến từ một key duy nhất (Hot Key).
Hãy tưởng tượng chiếc iPhone 15 Pro Max đang được giảm giá 50%. Có 100,000 người đang liên tục F5 (tải lại) trang web để xem số lượng tồn kho. Vào đúng khoảnh khắc dữ liệu tồn kho (Hot Key) này hết hạn trong Redis:
-
100,000 request cùng lao vào Redis và nhận được kết quả: Không tìm thấy dữ liệu (Cache Miss).
-
Vì không thấy trong cache, cả 100,000 luồng (thread) này đồng loạt quay sang truy vấn thẳng vào Database để lấy số tồn kho mới nhất nhằm ghi ngược lại vào Redis.
-
Database bị quá tải lập tức chỉ vì xử lý 100,000 câu lệnh giống hệt nhau cùng một lúc.
Để giải quyết vấn đề này, thay vì để cả 100,000 luồng cùng chạy xuống Database, chúng ta cần một cơ chế "chặn cửa" để chỉ cho phép một luồng duy nhất được đi tiếp, các luồng còn lại phải chờ. Trong thiết kế hệ thống, bạn có biết kỹ thuật nào thường được dùng để khóa các luồng xử lý đồng thời như thế này không?
Chắc chắn rồi, chúng ta sẽ đi thẳng vào giải pháp. Kỹ thuật "chặn cửa" kinh điển nhất trong trường hợp này chính là Mutex Lock (Khóa tương hỗ), hoặc trong hệ thống lớn gồm nhiều server, người ta sẽ dùng Distributed Lock (Khóa phân tán) thông qua chính Redis (như lệnh SETNX).
2. Cách Mutex Lock cứu sống Database
Thay vì để 100.000 luồng (thread) tự do chạy xuống Database khi không tìm thấy "Hot Key" trong bộ nhớ đệm, chúng ta ép chúng phải xếp hàng qua một cánh cửa chỉ cho phép một người lọt qua. Quá trình diễn ra như sau:
-
Luồng đầu tiên: Phát hiện cache trống (Cache Miss). Nó lập tức yêu cầu hệ thống cấp một cái "khóa" (Lock). Vì khóa đang rảnh, nó lấy được khóa và ung dung đi tiếp xuống Database để truy vấn số lượng iPhone.
-
Các luồng đến sau: 99.999 luồng còn lại cũng phát hiện cache trống và xin cấp khóa. Tuy nhiên, khóa đã bị luồng đầu tiên cầm mất. Lập trình viên sẽ viết code ép các luồng này phải ngủ (sleep) một khoảng thời gian cực ngắn, ví dụ 50 mili-giây, rồi thử lại.
-
Quá trình làm mới: Luồng đầu tiên lấy xong dữ liệu từ Database, ghi ngược kết quả vào Redis, sau đó trả lại khóa (Release Lock).
-
Đọc lại từ Cache: 99.999 luồng kia thức dậy, kiểm tra lại Redis. Lần này, dữ liệu đã nằm chễm chệ trong cache! Tất cả đọc dữ liệu từ cache và trả về cho người dùng.
Chỉ với một chiếc "ổ khóa", Database của bạn từ việc phải gánh 100.000 truy vấn nặng nề cùng một phần nghìn giây, giờ chỉ phải xử lý đúng 1 truy vấn duy nhất.
"Cái bẫy" số 3: Cache Penetration (Xuyên thủng bộ nhớ)
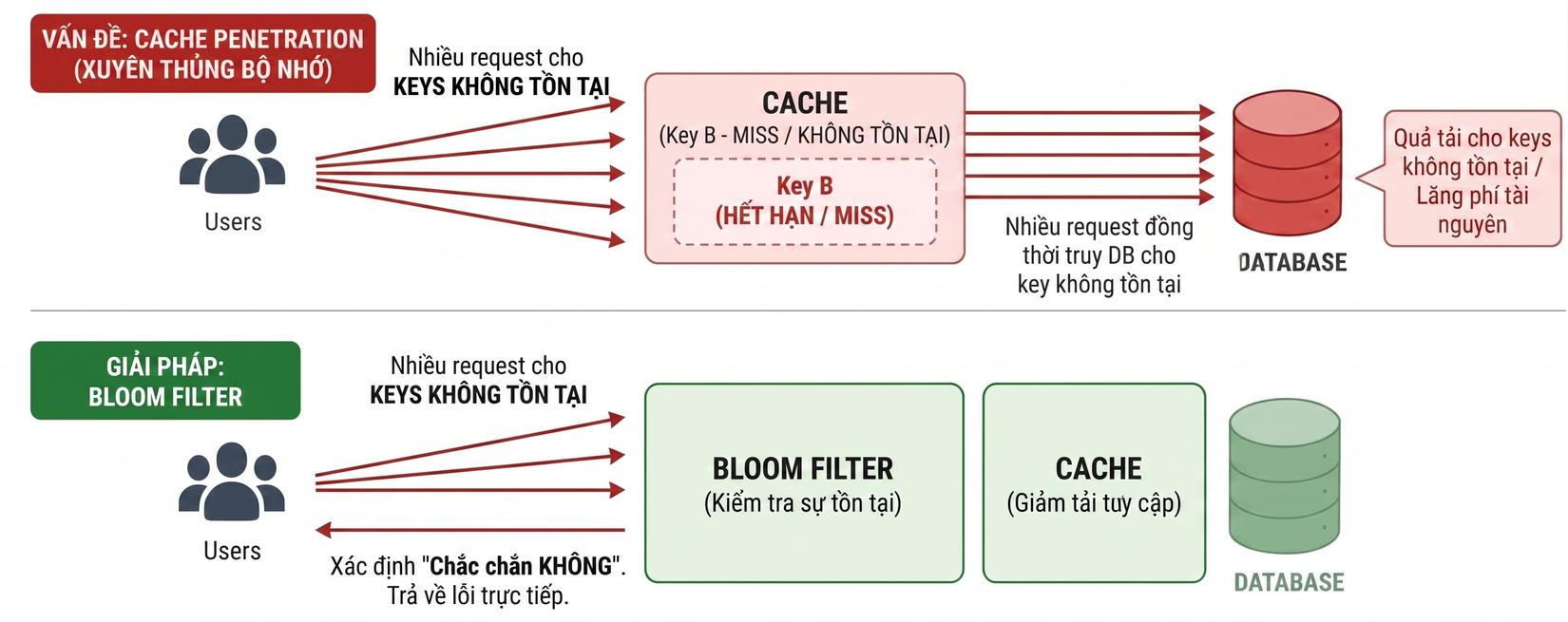
Bây giờ chúng ta đã bảo vệ được Database khỏi những dữ liệu có thật (nhưng bị hết hạn). Nhưng kẻ tấn công thì tinh vi hơn, chúng sử dụng Cache Penetration (Xuyên thủng bộ nhớ cache).
Hacker sẽ liên tục gửi hàng triệu request tìm kiếm các sản phẩm có ID = -1 hoặc những mã ID không bao giờ tồn tại.
-
Redis tìm không thấy dữ liệu.
-
Request đi thẳng xuống Database. Database quét xong cũng báo không có, và vì không có dữ liệu thật nên không có gì để ghi ngược lại vào Redis.
-
Request tiếp theo với
ID = -1lại lặp lại chu kỳ đó: Xuyên qua Redis ➡️ Đập thẳng vào Database. Hệ thống sẽ gục ngã vì kiệt sức.
Như đã đề cập ở đầu, giải pháp tối ưu là Bloom Filter. Cấu trúc dữ liệu này cực kỳ kỳ diệu: nó không cần lưu trữ thông tin chi tiết của dữ liệu, tốn cực kỳ ít RAM, nhưng lại có thể "phán" chính xác 100% rằng một ID chắc chắn không tồn tại để chặn ngay request từ vòng gửi xe.
Vậy nên, chúng ta hãy cùng mổ xẻ xem thuật toán bên trong Bloom Filter hoạt động thế nào mà nó lại đạt được phép màu tối ưu RAM như vậy không?
1. Vấn đề cốt lõi của Cache Penetration
Khi hacker liên tục gửi các ID = -1 (dữ liệu rác không tồn tại):
-
Redis không có ➡️ Trượt xuống Database.
-
Database không có ➡️ Không có gì để lưu ngược lên Redis.
-
Request tiếp theo với
ID = -1lại tiếp tục đập vào Database.
Chúng ta cần một người "bảo vệ" đứng trước Redis. Người này không cần nhớ chi tiết từng ID hợp lệ, mà chỉ cần có khả năng phán đoán nhanh chóng: "ID này CHẮC CHẮN KHÔNG TỒN TẠI, cấm đi tiếp!"
2. Bloom Filter hoạt động như thế nào?
Bloom Filter không lưu trữ dữ liệu thật (như tên hay giá sản phẩm). Nó chỉ sử dụng hai thành phần cốt lõi:
- Một mảng Bit (Bit Array): Một chuỗi dài gồm các số 0 và 1 (ban đầu tất cả đều là 0).
- Các Hàm băm (Hash Functions): Các thuật toán toán học giúp biến một chuỗi (ví dụ: ID = 100) thành các con số vị trí cụ thể trên mảng Bit.
Quá trình ghi nhận dữ liệu hợp lệ (Khi sản phẩm mới được tạo):
- Giả sử ta thêm
ID = 100vào hệ thống. ID = 100đi qua 3 hàm băm khác nhau, cho ra 3 vị trí (ví dụ: vị trí số 2, số 5 và số 9).- Hệ thống sẽ đánh dấu các vị trí 2, 5, 9 trên mảng Bit thành
1.
Quá trình chặn đứng Hacker (Khi có truy vấn tới):
Hacker gửi ID = -1.
-
ID = -1cũng bị đưa qua 3 hàm băm đó. Giả sử nó cho ra các vị trí: 2, 7, và 11. -
Hệ thống kiểm tra mảng Bit. Nó thấy vị trí số 2 là 1, nhưng vị trí số 7 và 11 lại là 0.
-
Kết luận đanh thép: Vì có ít nhất một vị trí là 0, Bloom Filter khẳng định 100% rằng ID = -1 chưa bao giờ được thêm vào hệ thống. Request bị chặn ngay lập tức, Database được an toàn! 🛡️
3. Sự đánh đổi: Dương tính giả (False Positive)
Điều kỳ diệu là một mảng bit vài Megabyte có thể lưu "dấu vân tay" của hàng tỷ bản ghi. Tuy nhiên, Bloom Filter có một đặc điểm: Nó có thể phán đúng 100% một thứ không tồn tại, nhưng nó chỉ có thể đoán "có khả năng tồn tại" đối với dữ liệu hợp lệ (vì các bit 1 có thể vô tình bị trùng lặp do các ID khác tạo ra - gọi là Dương tính giả).
Hãy thử suy luận: Nếu hacker vô tình tìm ra được một "ID rác" tạo ra hiện tượng Dương tính giả (tức là Bloom Filter nhầm tưởng ID đó có thật và cho đi qua), thì điều tồi tệ nhất gì sẽ xảy ra với Database của chúng ta lúc đó?
Hậu quả của "Dương tính giả" (False Positive) 🚨
Dương tính giả xảy ra khi hacker gửi một ID rác (ví dụ: ID = -999), nhưng vô tình sau khi chạy qua các hàm băm, nó lại chỉ đúng vào các vị trí bit đã được bật thành 1 từ trước bởi các ID hợp lệ khác.
Lúc này, Bloom Filter bị đánh lừa và phán: "Có vẻ ID = -999 có tồn tại, cho phép đi qua!".
Hành trình của request lọt lưới này sẽ diễn ra như sau:
-
Lọt qua Bloom Filter: Request tiến vào hệ thống.
-
Kiểm tra Redis: Redis tìm
ID = -999nhưng chắc chắn không có (Cache Miss). -
Đập vào Database: Hệ thống buộc phải chạy một câu lệnh query xuống Database để tìm ID = -999.
-
Kết quả: Database quét xong, báo về là không tìm thấy dữ liệu. Mọi thứ kết thúc.
👉 Điều tồi tệ nhất xảy ra là: Database của bạn bị lãng phí tài nguyên để xử lý một vài truy vấn vô ích.
Tại sao đây là một sự đánh đổi hoàn hảo? ⚖️
Trong thiết kế hệ thống, chúng ta luôn phải đánh đổi (Trade-off). Giả sử hacker gửi 1.000.000 request chứa ID rác cùng lúc. Nếu tỷ lệ dương tính giả của Bloom Filter là 1%:
- Chiếc lưới ma thuật này sẽ chặn đứng ngay lập tức 990.000 request.
- Chỉ có 10.000 request lọt lưới và chạy xuống Database.
Database hoàn toàn có thể chịu đựng được 10.000 truy vấn rác, nhưng chắc chắn sẽ sụp đổ nếu phải gánh trọn 1.000.000 truy vấn. Chúng ta chấp nhận một tỷ lệ lọt lưới rất nhỏ để đổi lấy việc tiết kiệm hàng chục Gigabyte RAM (vì không phải lưu chi tiết toàn bộ dữ liệu) và bảo vệ được sinh mạng của Database.
"Cái bẫy" số 4 - Bất nhất quán dữ liệu (Data Inconsistency)
Chúng ta đã xây dựng thành công những tấm khiên vững chắc để bảo vệ Database khỏi nguy cơ sụp đổ. Tuy nhiên, một hệ thống "chạy nhanh, không sập" chưa chắc đã là một hệ thống "trả về kết quả đúng". Chào mừng bạn đến với cạm bẫy thầm lặng nhưng nguy hiểm không kém mang tên: Bất nhất quán dữ liệu. Đây là lúc chúng ta phải chuyển sự tập trung từ việc bảo vệ sinh mạng của hệ thống sang việc đảm bảo tính chính xác tuyệt đối cho trải nghiệm của người dùng.
1. Tình huống tiến thoái lưỡng nan
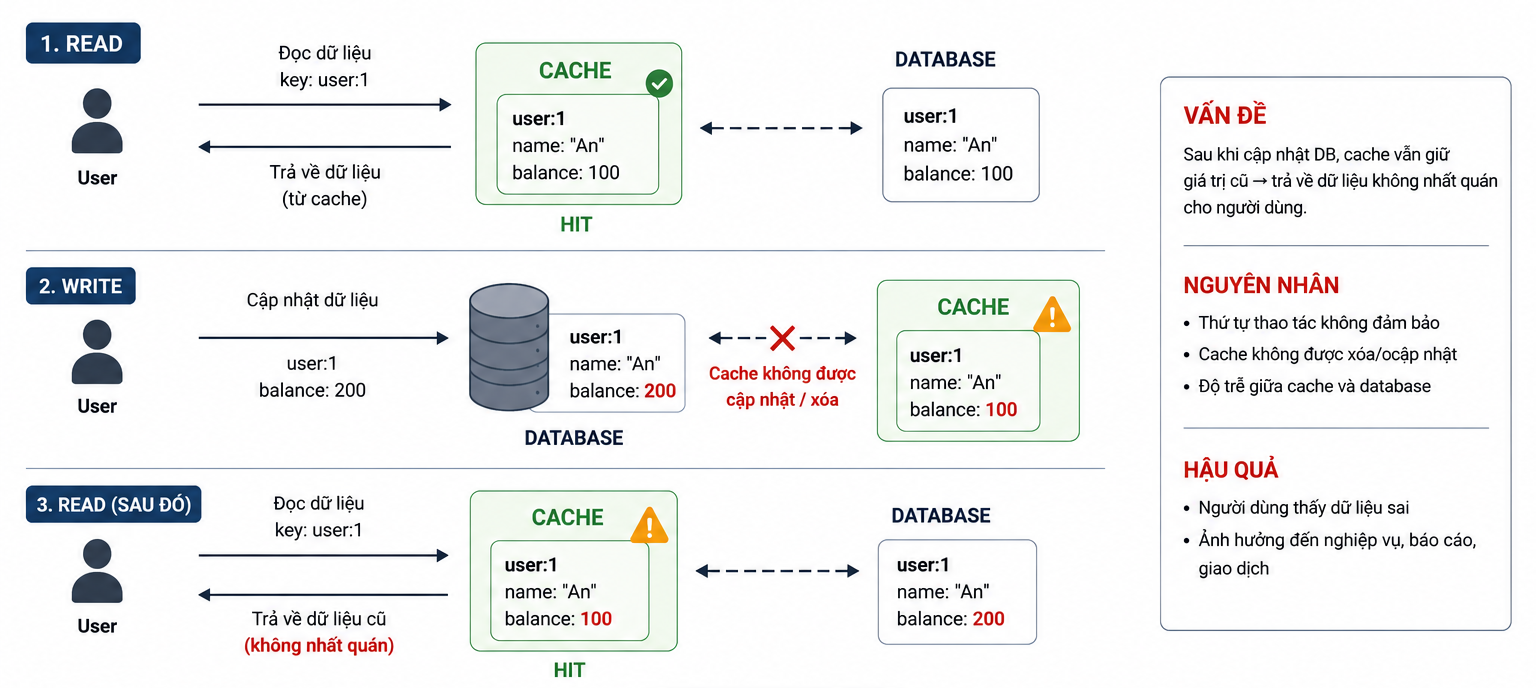
Để giải quyết cạm bẫy này, chúng ta có các chiến lược gọi là Caching Patterns (Các mẫu thiết kế bộ nhớ đệm). Vấn đề thường xảy ra nhất không phải lúc Đọc (Read), mà là lúc Ghi (Write/Update) dữ liệu.
Giả sử người dùng vừa cập nhật số điện thoại mới trên ứng dụng. Lúc này, chúng ta có hai nơi cần thay đổi: Database (nơi lưu trữ gốc) và Redis Cache (nơi đọc nhanh).
Theo bạn, để giảm thiểu rủi ro dữ liệu bị sai lệch, chúng ta nên:
-
Cập nhật Database trước, sau đó mới tiến hành cập nhật/xóa dữ liệu trong Cache?
-
Hay Xóa/cập nhật Cache trước, sau đó mới ghi dữ liệu mới xuống Database?
Hãy thử hình dung kịch bản tồi tệ: Nếu bước 1 thành công nhưng bước 2 bị lỗi (crash mạng, sập server giữa chừng), thì lựa chọn nào sẽ gây ra hậu quả nghiêm trọng hơn cho người dùng?
2. Giải mã thứ tự thao tác (Bẫy Concurrency)
Hãy cùng phân tích kịch bản sập mạng (crash) giữa chừng để xem rủi ro của từng lựa chọn. Giả sử số điện thoại cũ của người dùng là 0911 (đang nằm trong cả Cache và DB), số muốn đổi là 0999.
Kịch bản 1: Cập nhật Database trước ➡️ Xóa Cache sau
-
Bước 1: Cập nhật DB thành
0999(Thành công). -
Sự cố: Mất kết nối mạng trước khi kịp xóa Cache.
-
Hậu quả: Cache vẫn giữ số cũ
0911. Người dùng f5 app sẽ thấy số cũ. Đây là bất nhất quán tạm thời. Khi Cache hết hạn (TTL), hệ thống sẽ tự động lấy số mới từ DB lên và mọi thứ lại đồng bộ.
Kịch bản 2: Xóa Cache trước ➡️ Cập nhật Database sau
-
Bước 1: Xóa Cache chứa số 0911 (Thành công).
-
Sự cố: Sập server trước khi kịp ghi DB.
-
Hậu quả: Cache trống, DB giữ số cũ 0911. Lần tới người dùng tải trang, hệ thống không thấy trong Cache sẽ đọc lại DB và nạp số 0911 lên Cache. Trạng thái quay về như chưa có gì xảy ra, dữ liệu không bị hỏng.
Nhìn qua thì Kịch bản 2 có vẻ an toàn hơn khi có lỗi sập mạng. Nhưng cái bẫy thực sự của nó nằm ở Tính đồng thời (Concurrency) khi hệ thống hoạt động bình thường!
Hãy hình dung Luồng A (Ghi số 0999) và Luồng B (Đọc dữ liệu) chạy song song trong cùng 1 mili-giây:
-
✍️ Luồng A: Xóa Cache thành công (để chuẩn bị ghi DB).
-
👁️ Luồng B: Nhảy vào đọc dữ liệu. Thấy Cache trống, luồng B chạy thẳng xuống DB đọc số cũ
0911(vì Luồng A chưa kịp ghi DB). -
✍️ Luồng A: Ghi số mới
0999xuống DB thành công. -
👁️ Luồng B: Hồn nhiên mang số cũ
0911vừa đọc được nạp ngược trở lại Cache. 🚨 Hậu quả: Database là0999, nhưng Cache lại lưu0911. Sự sai lệch này sẽ tồn tại vĩnh viễn (hoặc phải chờ rất lâu cho đến khi hết TTL)!
Vì bẫy đồng thời này rất dễ xảy ra, tiêu chuẩn của thiết kế hệ thống là sử dụng Kịch bản 1 (Cache-Aside Pattern): Luôn ghi vào Database trước, sau đó Xóa Cache.
3. Tại sao là "Xóa" mà không phải "Cập nhật"?
Bạn có để ý trong toàn bộ quá trình, chúng ta chỉ nhắc đến việc "Xóa Cache" (Invalidate) thay vì "Cập nhật giá trị mới cho Cache" (Update) không? Theo bạn, tại sao khi DB thay đổi, hệ thống thà xóa hẳn dữ liệu trong Cache đi để người sau tự tải lại, chứ ít khi ghi đè trực tiếp giá trị mới vào Cache?
Việc chọn "Xóa" (Invalidate) thay vì "Cập nhật" (Update) Cache thực chất nhằm giải quyết hai vấn đề cốt lõi về kiến trúc:
- Ngăn chặn Bẫy tranh chấp đồng thời (Race Condition) 🚧
Hãy hình dung hai luồng dữ liệu (Luồng A và Luồng B) cùng thao tác thay đổi một thông tin gần như cùng một lúc: Luồng A muốn đổi dữ liệu thành , Luồng B muốn đổi thành .
Nếu chúng ta áp dụng quy trình: Ghi DB ➡️ Cập nhật Cache:
- Ở Database: Luồng A chạy nhanh hơn nên ghi trước, Luồng B ghi sau. Kết quả cuối cùng (và chuẩn xác nhất) ở DB là .
- Ở Cache: Do độ trễ mạng ngẫu nhiên, Luồng B lại đẩy lệnh cập nhật Cache lên trước (thành ). Sau đó Luồng A đến chậm hơn nên ghi đè Cache thành .
- 🚨 Kết quả: Database lưu , nhưng Cache lại lưu . Bất nhất quán xảy ra!
Việc Xóa Cache an toàn hơn rất nhiều. Bất kể Luồng A xóa trước hay Luồng B xóa trước, kết quả cuối cùng vẫn là Cache bị trống. Người tiếp theo truy cập sẽ gặp "Cache Miss" và buộc hệ thống phải lấy dữ liệu nguyên bản, chuẩn xác nhất từ Database nạp lên lại.
- Tránh lãng phí tài nguyên tính toán (Lazy Loading) ⚡
Nhiều dữ liệu trong bộ nhớ đệm không chỉ đơn thuần là sao chép 1:1 từ Database, mà đòi hỏi hệ thống phải truy vấn (join) từ nhiều bảng, hoặc thực hiện các phép tính phức tạp (ví dụ: Báo cáo thống kê doanh thu).
Giả sử một bản ghi trong Database được thay đổi liên tục 100 lần/giờ, nhưng người dùng chỉ mở ứng dụng ra xem đúng 1 lần/giờ.
- Nếu chọn Cập nhật Cache, server sẽ phải tốn CPU để tính toán lại toàn bộ dữ liệu đó 100 lần vô ích.
- Nếu chọn Xóa Cache, dữ liệu cũ bị hủy bỏ lập tức. Hệ thống sẽ bỏ qua mọi lần thay đổi ở DB, và chỉ thực sự tiêu tốn CPU để tính toán lại dữ liệu 1 lần duy nhất vào đúng lúc có người dùng yêu cầu đọc.
Tình huống thực chiến
Chúng ta đã cùng nhau mổ xẻ tường tận cả 4 cạm bẫy lớn nhất của Caching: Tuyết lở (Avalanche), Xuyên phá 1 điểm (Breakdown), Xuyên thủng (Penetration) và Bất nhất quán dữ liệu (Data Inconsistency).
Bây giờ, chúng ta sẽ mang những nguyên lý này ra "thực chiến". Hãy thử thiết kế kiến trúc hệ thống cho ứng dụng bán vé sự kiện âm nhạc (ví dụ: Concert của BlackPink hoặc Taylor Swift). Với bài toán này, hàng triệu người sẽ cùng lúc nhấn F5 để giành giật 50.000 chiếc vé.
Khi một khách hàng bấm "Mua vé", theo bạn, chúng ta nên trừ số lượng vé trực tiếp trong Database trước, hay trừ số lượng vé ngay trên bộ nhớ đệm (Redis Cache) trước để đảm bảo hệ thống vừa không sập, vừa không bán lố số lượng vé thật?
Bài toán bán vé sự kiện âm nhạc (Flash Sale / Seckill) là thử thách cực đại về độ chịu tải và tính nhất quán. Các bạn hãy thử cùng mình mổ xẻ hai lựa chọn này dưới áp lực của 1 triệu lượt nhấn "Mua vé" cùng lúc nhé.
Lựa chọn 1: Trừ vé trong Database trước
-
Cơ chế: Khi có request, hệ thống chạy lệnh cập nhật thẳng vào Database để trừ vé, đồng thời kiểm tra điều kiện còn vé (Ví dụ: UPDATE tickets SET count = count - 1 WHERE count > 0).
-
Hậu quả: Để tránh bán lố, Database phải sử dụng cơ chế khóa (Row-level lock) trên dòng dữ liệu chứa số lượng vé. Cùng một lúc có 1 triệu request tranh nhau mở khóa và khóa lại một dòng dữ liệu duy nhất.
-
Kết quả: Tình trạng thắt cổ chai trầm trọng xảy ra. CPU của Database tăng vọt lên 100% và hệ thống sập ngay trong giây đầu tiên.
Lựa chọn 2: Trừ vé trong Redis Cache trước (Giải pháp tiêu chuẩn)
-
Cơ chế: Số lượng 50.000 vé được nạp sẵn vào Redis từ trước khi sự kiện bắt đầu. Khi người dùng bấm mua, ta sử dụng lệnh giảm trừ nguyên tử của Redis (ví dụ: DECR).
-
Lợi thế tốc độ: Redis lưu trữ trên RAM. Nó có thể xử lý hơn 100.000 thao tác mỗi giây một cách nhẹ nhàng.
-
Chống bán lố (Overselling): Bản chất Redis xử lý các lệnh theo dạng đơn luồng (Single-threaded). 1 triệu người dùng lao vào cùng lúc, nhưng Redis sẽ ép tất cả phải xếp hàng và xử lý lần lượt từng lệnh một ở tốc độ siêu cao. Người thứ 50.000 sẽ làm số vé tụt về 0. Từ người thứ 50.001 trở đi, lệnh trả về sẽ là số âm, hệ thống lập tức chặn lại và báo hết vé.
-
Kết quả: Hệ thống sống sót qua đợt bão truy cập, người dùng nhận được phản hồi ngay lập tức và số lượng vé được bán chính xác 100%.
Mảnh ghép còn thiếu
Lựa chọn 2 giải quyết được bài toán sập hệ thống và bán lố, nhưng lại sinh ra một vấn đề mới: Dữ liệu chưa được lưu vào Database gốc.
Nếu 50.000 người đã giành được vé trên Redis, nhưng trước khi hệ thống kịp tạo hóa đơn và lưu xuống Database thì máy chủ Redis bị cúp điện, toàn bộ kết quả mua vé sẽ bốc hơi. Chúng ta không thể bắt Redis gọi trực tiếp xuống Database để ghi hóa đơn ngay lập tức, vì lượng kết nối ồ ạt vẫn sẽ làm Database quá tải.
Để giải quyết, kiến trúc hệ thống bắt buộc phải có một thành phần "trung gian" đứng giữa Redis và Database. Thành phần này hoạt động như một hệ thống máng trượt hoặc băng chuyền: nó hứng lấy danh sách 50.000 người vừa giành vé thành công từ Redis một cách cực nhanh, lưu tạm lại cho an toàn, sau đó từ từ đưa từng hóa đơn một xuống Database với tốc độ mà Database có thể chịu đựng được (ví dụ 1000 hóa đơn/giây).
Trong thiết kế hệ thống lớn, bạn có biết tên gọi chung của cấu trúc "băng chuyền" chuyên dùng để xếp hàng và xử lý bất đồng bộ các luồng dữ liệu khổng lồ này là gì không?
Cấu trúc "băng chuyền" trung gian đó chính là Message Queue (Hàng đợi tin nhắn). Những hệ thống phổ biến nhất thường được dùng cho vị trí này là Apache Kafka, RabbitMQ hoặc Amazon SQS.
Trong bài toán bán vé sự kiện âm nhạc, Message Queue đóng vai trò như một bộ giảm xóc (buffer) hoàn hảo giữa Redis siêu tốc và Database chậm chạp. Quá trình này diễn ra qua 3 bước cốt lõi:
-
Sản xuất tin nhắn (Producer): Ngay khi Redis trừ vé thành công, máy chủ ứng dụng sẽ không gọi thẳng xuống Database. Thay vào đó, nó đóng gói thông tin (Ví dụ: User_123 mua Vé_VIP_BlackPink) thành một "tin nhắn" và ném lên Message Queue. Việc ném dữ liệu lên băng chuyền này chỉ tốn 1-2 mili-giây.
-
Xếp hàng an toàn (Queue): Message Queue có nhiệm vụ giữ lại và xếp hàng 50.000 tin nhắn này. Đa số các Message Queue đều lưu trữ trên ổ cứng (Persistent), nghĩa là nếu hệ thống sập nguồn lúc này, 50.000 tin nhắn mua vé vẫn nằm an toàn trên băng chuyền và không bị mất.
-
Tiêu thụ tin nhắn (Consumer): Một nhóm các luồng xử lý ngầm (Worker) sẽ đứng ở cuối băng chuyền, từ từ nhón lấy từng tin nhắn và thực hiện thao tác tạo hóa đơn lưu xuống Database. Thay vì Database phải gồng gánh 50.000 lệnh ghi cùng một giây gây sập hệ thống, giờ đây nó được cung cấp dữ liệu một cách nhịp nhàng với tốc độ an toàn (ví dụ: 500 hóa đơn/giây).
Kỹ thuật này trong System Design được gọi là Xử lý bất đồng bộ (Asynchronous Processing) và Gọt tải (Traffic Shaping / Peak Clipping).
Tuy nhiên, cơ chế bất đồng bộ này lại sinh ra một độ trễ nghiệp vụ. Bởi vì việc ghi Database diễn ra chậm hơn, nên tại khoảnh khắc người dùng được Redis xác nhận là "Đã giành được vé", hóa đơn chính thức của họ có thể vẫn đang nằm trên băng chuyền và chưa hề tồn tại trong Database.
Nếu khách hàng lập tức chuyển sang trang "Lịch sử mua hàng" (nơi truy vấn dữ liệu từ Database) ngay giây tiếp theo, họ sẽ không thấy hóa đơn đâu và có thể hoảng sợ nghĩ rằng mình đã bị mất vé.
Theo bạn, để giải quyết trải nghiệm người dùng trong tình huống "độ trễ bất đồng bộ" này, giao diện ứng dụng (Frontend) nên hiển thị thông điệp hoặc trạng thái gì ngay sau khi họ bấm mua thành công?
Xử lý UX trong Kiến trúc Bất đồng bộ
Khi hệ thống sử dụng Message Queue, vé đã được chốt ở Redis nhưng hóa đơn thực tế vẫn đang nằm trên "băng chuyền". Lúc này, giao diện (Frontend) tuyệt đối không được hiển thị là "Mua vé thành công" ngay lập tức, mà phải áp dụng chiến thuật Trạng thái trung gian (Intermediate State):
-
⏳ Hiển thị "Đang xử lý" (Processing / In Queue): Ngay khi Redis trừ vé và đẩy tin nhắn lên Queue, Frontend sẽ chuyển sang màn hình chờ với thông báo: "Bạn đã giữ được vé! Hệ thống đang khởi tạo hóa đơn, vui lòng không làm mới trang...".
-
🔄 Cơ chế Polling hoặc WebSockets: Trong lúc người dùng nhìn màn hình chờ, Frontend không hề đứng im. Nó sẽ ngầm liên tục gửi yêu cầu (mỗi 1-2 giây) hoặc dùng kết nối WebSocket tới Backend để hỏi: "Hóa đơn của User_123 đã được Database xử lý xong chưa?".
-
✅ Xác nhận trạng thái cuối cùng: Khi các luồng xử lý (Worker) ở cuối Message Queue ghi thành công hóa đơn xuống Database, Backend sẽ cập nhật trạng thái đơn hàng. Ngay khi Frontend nhận được tín hiệu "Hoàn tất" này, giao diện mới chính thức chuyển sang màn hình "Mua vé thành công" kèm theo mã hóa đơn chi tiết.
Chiến thuật này giúp che lấp hoàn toàn độ trễ của việc ghi Database, giữ chân người dùng trong 3-5 giây chờ đợi mà không gây ra cảm giác hoang mang hay lỗi dữ liệu ảo.
Chúng ta đã đi qua một vòng trọn vẹn của nghệ thuật Caching trong System Design: Từ việc nhận diện 3 cạm bẫy (Avalanche, Breakdown, Penetration), đến việc xử lý Bất nhất quán dữ liệu, và cuối cùng là kết hợp Redis - Message Queue - Database để giải quyết bài toán chịu tải khổng lồ của Flash Sale.
Lời Kết: Nghệ Thuật Của Sự Đánh Đổi
Thiết kế hệ thống (System Design) chưa bao giờ là một bài toán có đáp án hoàn hảo tuyệt đối; bản chất của nó là nghệ thuật của sự đánh đổi (Trade-off). Để 50.000 tấm vé đến đúng tay người hâm mộ trong một cơn bão truy cập mà không làm sập máy chủ, chúng ta đã phải liên tục đưa ra những lựa chọn khắt khe:
Chúng ta đánh đổi bộ nhớ RAM đắt đỏ lấy tốc độ xử lý siêu tốc của Redis. Chúng ta chấp nhận một tỷ lệ "dương tính giả" lọt lưới cực nhỏ của Bloom Filter để tiết kiệm hàng chục Gigabyte tài nguyên. Và cuối cùng, chúng ta chủ động hy sinh một vài giây trải nghiệm thời gian thực (real-time) của người dùng bằng Message Queue, đổi lấy sự sống còn và tính toàn vẹn dữ liệu cho Database.
Làm chủ được nghệ thuật Caching và những cạm bẫy của nó không chỉ giúp bạn xây dựng được những ứng dụng chịu tải hàng triệu lượt truy cập, mà còn đánh dấu bước chuyển mình vững chắc từ một người viết code thông thường trở thành một kiến trúc sư hệ thống (System Architect) thực thụ.
Còn bạn thì sao? Giả sử ngày mai, ứng dụng bạn đang phát triển đột nhiên nhận được lượng truy cập gấp 100 lần bình thường, bạn nghĩ hệ thống của mình sẽ "gục ngã" ở điểm nghẽn (bottleneck) nào đầu tiên?
All rights reserved
