Lưu trữ dữ liệu time series với InfluxDB cùng bài toán về dữ liệu chứng khoán
Bài đăng này đã không được cập nhật trong 7 năm
Mở đầu
Như các bạn đã biết thì phân tích dữ liệu hiện là một bài toán được nghiên cứu rất nhiều từ những ngành nghề đầu tư, kĩ thuật cho đến marketing. Những vị trí data engineering không ngừng được săn đón, trong đó phân tích dữ liệu chuỗi thời gian (time series) là một trong số những bài toán đó. Có thể kể một số ví dụ để các bạn dễ hình dung về những ứng dụng của phân tích dữ liệu chuỗi thời gian như phân tích dữ liệu sử dụng băng thông nhà mạng của user trong ngày để phân phối hợp lý , phân tích số lượng request của user đến server để có các biện pháp cân bằng tài, phân tích dữ liệu từ các sensor phục vụ việc bảo trì kịp thời cho các loại máy móc, hay những thứ fancy hơn như phân tích giá của chứng khoán, forex..(why not) Trong bài viết lần này mình sẽ giới thiệu và demo về một cơ sở dữ liệu để lưu trữ dữ liệu chuỗi thời gian, có thể nói đây là nền móng cho việc phân tích dữ liệu. Cơ sở dữ liệu mình lựa chọn sẽ là Influx
Giới thiệu
Phần này mình sẽ giới thiệu tổng quan về influxdb cũng như những chức năng chính của nó
Influxdb thường được lựa chọn trong các trường hợp khi phải lưu trữ, tổ chức những dữ liệu lớn được đánh dầu bằng các nhãn thời gian ( DevOps monitoring, IoT sensor data ,...)
Những tính năng chính mà Influxdb hỗ trợ có thể kể đến như :
- Có các API đọc ghi dễ hiểu, hiệu suất cao
- Plugin hỗ trợ cho các giao thức nhập dữ liệu khác như Graphite, collectd và OpenTSDB (Phần này trong khuôn khổ bài viết mình chưa thể thực nghiệm)
- Câu query tương đồng với SQL do đó rất dễ để những người đã có base về SQL ứng dụng
- Đánh index theo các trường tags giúp truy vấn tốc độ.
- Các truy vấn liên tục tự động tính toán dữ liệu tổng hợp để làm cho các truy vấn thường xuyên hiệu quả hơn. Và cuối cùng thì Influxdb có cả mã nguồn mở và phiên bản cho enterprise
Cài đặt
Trong bài viết lần này mình sẽ hướng dẫn cài đặt trên máy chủ linux, còn trên window thì cũng sẽ có những gói cài đặt đơn giản. Đây là tài liệu cài đặt chính thử của Influxdb
Inflluxdb có thể sẽ cần yêu cầu quyền root hoặc quản trị để có thể cài đặt hoàn thiện.
Port
Đầu tiên hãy kiểm tra chắc chắn rằng các port 8086 và 8088 chưa được sử dụng bởi tiến trình nào. Các bạn có thể kiểm tra bằng câu lệnh :
lsof -i :8086
Đầu tiên hãy thêm InfluxData repository bằng câu lệnh :
wget -qO- https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
hoặc
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
Sau đó chỉ cần cài gói Influx và chạy service influxdb thôi
sudo apt-get update && sudo apt-get install influxdb
sudo service influxdb start
Với OS sử dụng là dạng systemd :
sudo apt-get update && sudo apt-get install influxdb
sudo systemctl unmask influxdb.service
sudo systemctl start influxdb
Gọi lại câu lệnh
lsof -i :8086
sẽ thầy cổng này đang chạy service của influx:

Tương tác với Influx
Cấu trúc dữ liệu
Việc đầu tiên của chúng ta sẽ là mở command line lên và gõ
influx
Khi đó command line sẽ xuất hiện màn hình console để có thể thao tác trực tiếp với influx:
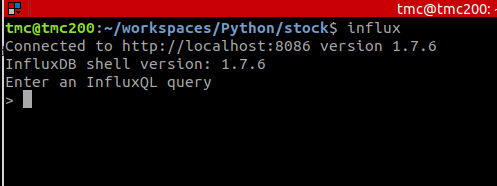
Trong khuôn khổ bài viết, mình sẽ nói về những câu lệnh chính, các bạn có thể tham khảo thêm ở đây
#Hiển thị các cơ sở dữ liệu hiện có
SHOW DATABASES
#Tạo một cơ sở dữ liệu mới
CREATE DATABASE example
#Lựa chọn csdl để tương tác (Luôn phải gọi trước khi viết câu query cho csdl tương ứng)
USE example
Trước khi vào phần viết query thì chúng ta cần phải hiểu qua một số thành phần chính của 1 csdl Influx:
measurement : Trường này thì các bạn có thể hiểu đơn giản nhất là nó tương tự với table trong SQL, chỉ có điều khác là nó có các primary index là trường thời gian , còn nếu chưa biết SQL thì cá nhân mình nghĩ nên tìm hiểu về nó trước khi tìm hiểu về những csdl khác
tags : Tương tư như một collumn của table trong SQL. Tuy nhiên đây là collumn được đánh index để hộ trợ biệc GROUP trong các câu query
value: Cũng tương tự là một collumn của table trong SQL. Đây sẽ là các giá trị quan trọng cho việc phân tích dữ liệu sau này
Một ví dụ đơn giản :
[
{
"measurement": "server_request",
"tags": {
"host": "server01",
"region": "us-west"
},
"time": "2009-11-10T23:00:00Z",
"fields": {
"value": 1997
}
}
]
Với ví dụ trên phân tích lưu lượng request gọi đến server, khi đó
- measurement là server_request
- Hai trường tags host và region để sau này có thể query select số lượng request theo vùng (region) hoặc theo loại server (host)
- value chính là số lượng request đến trong một trường thời gian nhất định (time - primary index của measurement)
Truy vấn
Như vậy với ví dụ về lưu lượng server như trên thì những câu lệnh cơ bản sẽ có dạng
Insert
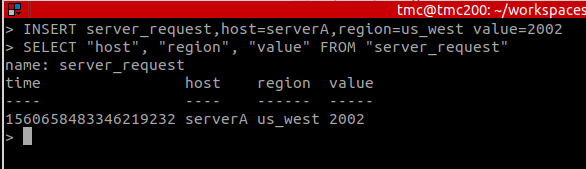
Câu lệnh khá tương tự như SQL
INSERT server_request,host=serverA,region=us_west value=2002
Select
SELECT "host", "region", "value" FROM "server_request"
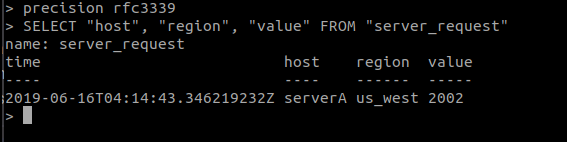
Trong đây trường time được format dưới dạng nano seconds, có thể hiển thị time dưới dạng datatime với câu lệnh precision rfc3339
Thu thập và lưu trữ dữ liệu chứng khoán
Đây là một ví dụ nho nhỏ để các bạn hình dung một flow theo mình là tương đối hoàn thiện từ việc crawl dữ liệu và thiết kế csdl cho chuỗi thời gian. Trong ví dụ này mình sẽ thu thập dữ liệu chứng khoán của Microsoft Corporation (MSFT):
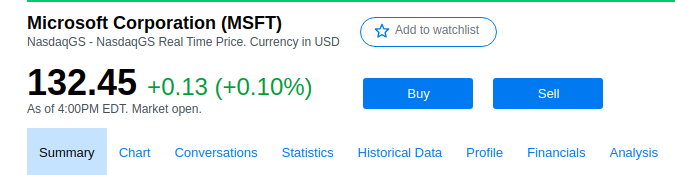
Các bạn có thể có các chiến thuật khác như lấy trực tiếp API của bên cung cấp hay dùng các framework test cũng có thể lấy được dữ liệu này. Phương pháp ở đây là mình sẽ lấy trực tiếp dữ liệu từ thẻ HTML :

Dữ liệu giá trị của chứng khoán của Microsoft sẽ được mình cập nhật từng phút, và để crawl mình sẽ sử dụng một framework Scrapy của python, với framework này các bạn có thể tham khảo qua các bài viết khác của mình tại đây
Để tương tác với service Influx thì mình sẽ sử dụng package InfluxDBClient của python (Các bạn có thể sử dụng Go để tương tác vì Influxdb được xây dựng hoàn toàn trên Golang, but cho dễ tiếp cận thì Python vẫn hợp lý hơn nhứ nhỉ  )
)
Đây là file scrapy của mình, các bạn có thể tham khảo cách mình lấy giá trị từ trang chứng khoán kia :
import scrapy
from influxdb import InfluxDBClient
from time import time
import pdb
import random
class StockSpider(scrapy.Spider):
name = "stock"
start_urls = {
'https://finance.yahoo.com/quote/MSFT/'
}
def parse(self, response):
db = InfluxDBClient("localhost", 8086)
db.switch_database("stock")
price = response.xpath('//div[@id="quote-header-info"]/div[@class="My(6px) Pos(r) smartphone_Mt(6px)"]/div/span/text()').extract()[0]
json = [{
"measurement": "MSFT",
"time": int(time()) * 1000000000,
"fields": {
"price": str(float(price)
}
}]
db.write_points(json)
Đầu tiên là kết nối đến service Influx để chọn csdl stock sau đó lấy dữ liệu từ trang web và insert vào measurement MSFT (viết tắt của cổ phiếu Microsoft)
Tiếp theo sẽ là hàng phút các bạn gọi con crawl này chạy 1 lần, trong lần này mình vẫn sử dụng với crontab như trong bài chia sẻ về crawl tự động:
crontab -e
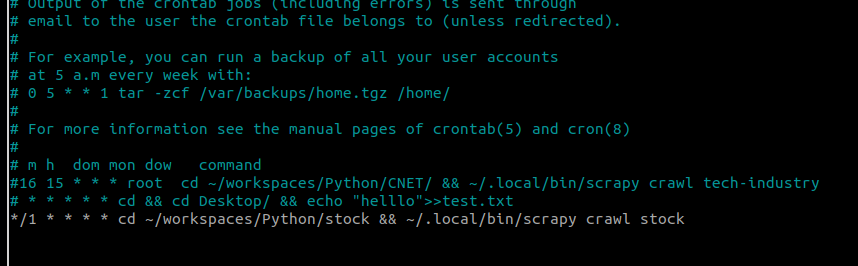
Như vậy cứ 1 phút thì dữ liệu về giá trị chứng khoán Microsoft sẽ được lấy một lần. Do bài viết được viết vào những ngày đóng phiên của chứng khoán nên giá trị không thể có biến động, do đó mình có can thiệp để fake một chút giúp các bạn có thể dễ hình dung hơn =))
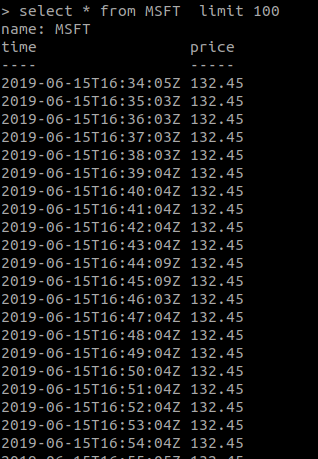
Dữ liệu crawl sau một khoảng thời gian :
Có thể query để lấy được nhuững dữ liệu theo khoảng thời gian như giá trị chứng khoán trong khoàng 30ph hay một tiếng một cách dễ dàng :
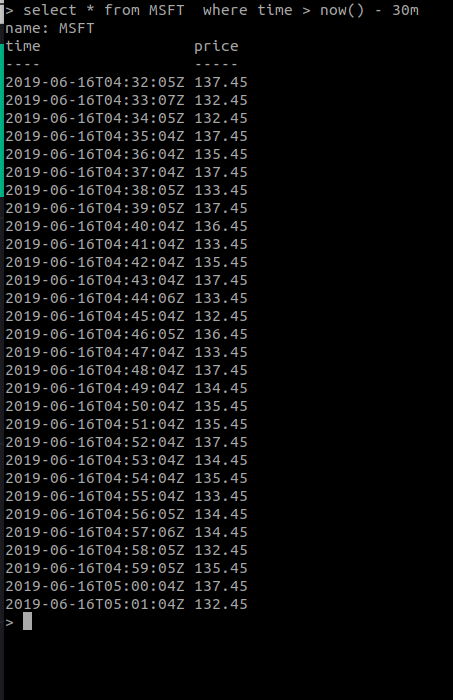
Các bạn có thể sẽ thấy hơi confused khi thấy chỉ có một 2 trường time và price mà không thấy trường tags đâu thì cũng không nên bất ngờ, mình có thể giải thích mà :
InfluxDB là cơ sở dữ liệu rất linh hoạt, đơn giản vì mình muốn tăng tốc độ truy xuất hơn mà mình cho mỗi một loại cổ phiết là một measurement thôi, hơi khác sách giáo khoa một xíu nhưng kệ thôi, phục vụ tốt mục đích của dev là vui mà =)
Kết luận
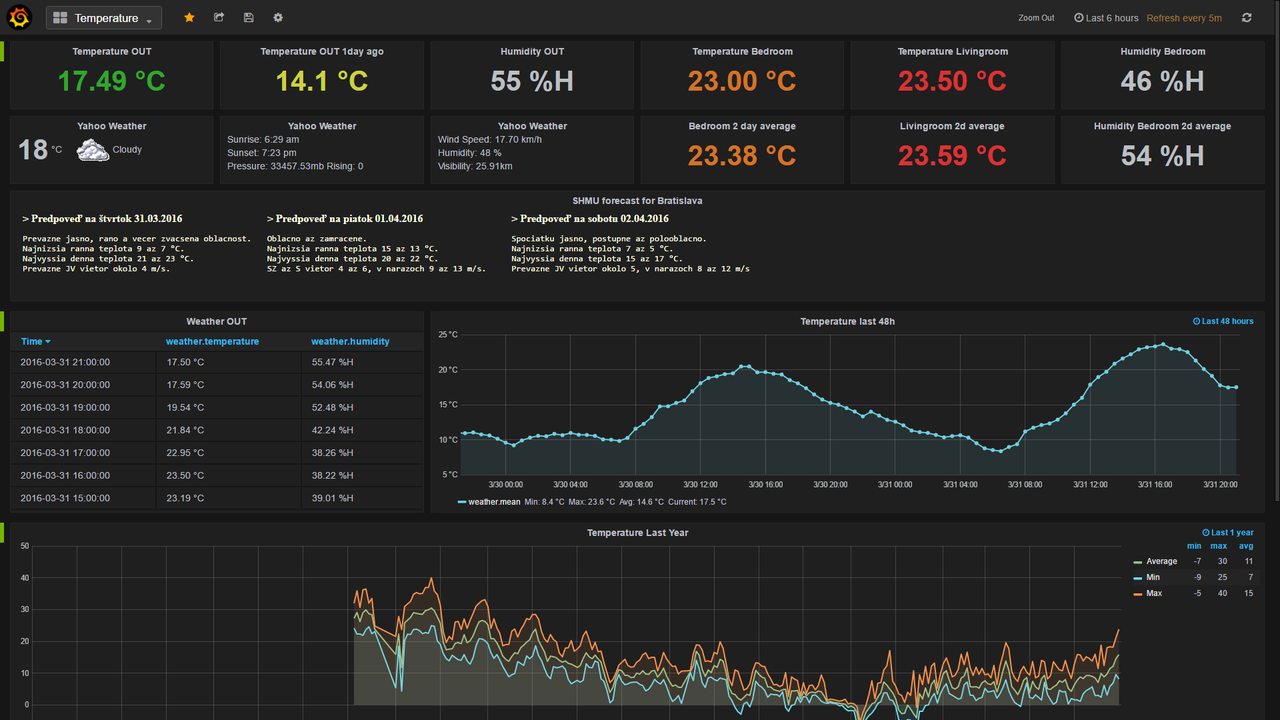
Trên đây là bài viết của mình về cơ sở dữ liệu Influx, các bạn có thể thắc mắc về bức ảnh intro ban đầu - đó chính là một chút nhá hàng về việc vusualize dữ liệu dựa trên cơ sở dữ liệu Influxdb sẽ được mình thực hiện trong những bài viết tiếp theo. Bên cạnh đó, InfluxDB cũng tương tác hoàn toàn tốt với các framework phân tích dữ liệu lớn nổi tiếng như spark hay hadoop. Cảm ơn các bạn đã đọc bài viết của mình )
All rights reserved
