[LLM - Paper reading] Self-Rewarding Language Models - Tìm hiểu cách LLM tự nâng cấp chính nó
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Các bạn tìm hiểu về LLM chắc không còn lạ gì với RLHF (Reinforcement learning with Human Feedback). Đây là kĩ thuật giúp bạn căn chỉnh (align) LLM sử dụng human preference data, giúp tăng chất lượng của pretrained model. Cách tiếp cận của RLHF khá cơ bản như sau:
- Train 1 reward model từ human preference. Human preference ở đây các bạn có thể hiểu là nhãn feedback của con người. Ví dụ như thích phản hồi nào hơn, hoặc gán điểm cho phản hồi.
- Sau đó, reward model này sẽ được đóng băng (frozen) và được sử dụng để train LLM sử dụng thuật toán RL, ví dụ như PPO, DPO chẳng hạn.
Dễ thấy, cách tiếp cận này có bottleneck nằm ở số lượng và chất lượng của human preference data. Vì dữ liệu này ảnh hưởng trực tiếp tới chất lượng reward model mà reward model lại ảnh hưởng tới LLM. Nói chung, data is the king 
Trong bài báo này, nhóm tác giả đề xuất một cách tiếp cận mới, đó là xây dựng một pipeline sao cho reward model được cập nhật liên tục mà không phải bị frozen như RLHF truyền thống. Từ đó, model LLM cũng sẽ được cập nhật liên tục luôn. Nói 1 cách khác, ta sẽ có 1 pipeline thống nhất chứ không phải chia reward model và LLM riêng nữa.
Cách tiếp cận này có tên là Self-Rewarding Language Models. Về cơ bản, nó sẽ có 2 khả năng sau:
- Hoạt động hệt như một instruction following model, có thể generate response từ 1 prompt cho trước.
- Có thể generate và evaluate các instruction following example để thêm vào tập training.
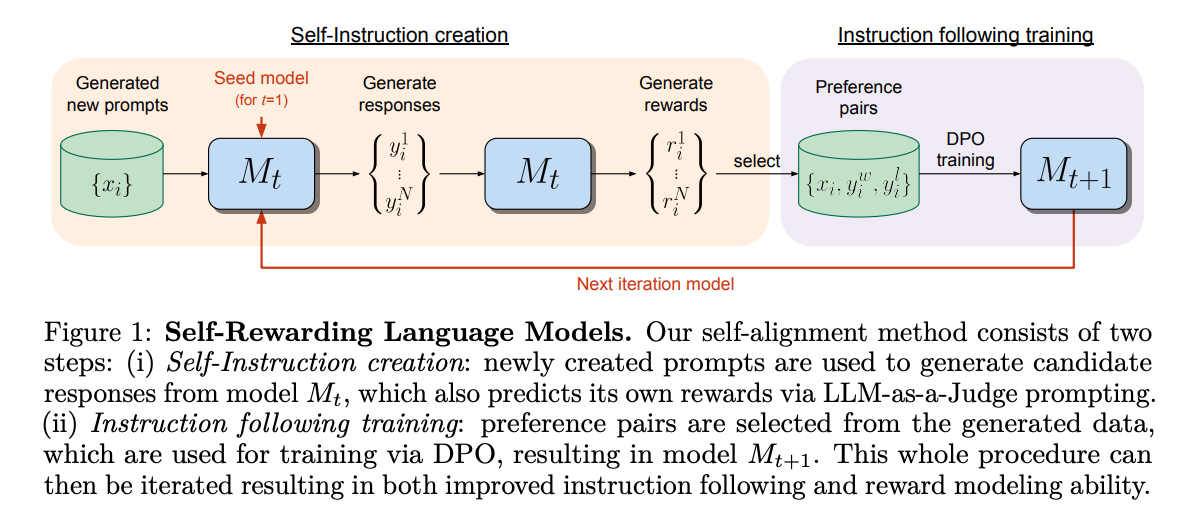
Các model này sẽ được training sử dụng Iterative DPO framework. Nó sẽ có 2 bước như sau:
- Đầu tiên, từ một seed model, trong mỗi vòng lặp (iteration) sẽ có 1 quá trình gọi là Self-Instruction creation. Một prompt được sử dụng để generate candidate responses từ model . Sau đó, ta sẽ sử dụng chính model này để predict reward sử dụng 1 prompt khác (được gọi là LLM-as-a-Judge prompting).
- Sau bước trên, ta sẽ có các preference pairs. Ta sẽ sử dụng các preferences pair này để training model với DPO. Cuối cùng, ta thu được model mới. Quá trình này được lặp liên tục với mục tiêu cải thiện khả năng instruction following và reward modeling của model LLM .
Self-Rewarding Language Models
Mình đã trình bày tổng quan phương pháp ở phần trước, bây giờ hãy đi vào chi tiết từng thành phần .
Đầu tiên, context ở đây là ta đã có một based pretrained language model và một lượng nhỏ dữ liệu được gán nhãn bởi con người. Mục tiêu hiện tại là ta sẽ build một model sao cho có 2 kỹ năng sau đây:
- Instruction following: Từ 1 prompt được mô tả bởi người dùng, model phải có khả năng generate các response chuẩn chỉnh, có chất lượng cao.
- Self-Instruction creation: Model phải có khả năng generate và evaluate các instruction-following examples. Mục tiêu là thêm chính những example này vào training set.
Nói 1 cách ngắn gọn và dễ hiểu là: Model tự đưa ra phản hồi, Model tự đánh giá chính những phản hồi của nó, và cuối cùng model sẽ tự cải thiện chính nó thông qua việc đánh giá ở bước trước.
Khởi tạo
Seed instruction following data. Đầu tiên, ta cần có bộ dữ liệu này để thực supervised fine-tuning (SFT) cho based model ban đầu. Bộ dữ liệu này (Instruction Fine-Tuning data - IFT data) gọi là sẽ được tạo bởi con người, mỗi sample bao gồm 1 cặp (instruction prompt, response).
Seed LLM-as-a-Judge instruction following data. Tiếp theo, nhóm tác giả giả định rằng đã được cung cấp một tập các example (evaluation instruction prompt, evaluation result response) được sử dụng cho quá trình training. Theo tác giả, bộ data này không thật sự cần thiết vì bản thân model sử dụng IFT data đã có khả năng LLM-as-a-Judge rồi. Tuy nhiên, thêm bộ data này vào thì sẽ cải thiện được performance hơn. Bộ dữ liệu này được gọi là Evaluation Fine-Tuning (EFT) data. Trong bộ data này, input prompt sẽ yêu cầu model đánh giá chất lượng của các response cho trước. Bạn có thể tham khảo prompt mẫu trong hình dưới:

Self-Instruction
Okay! Sau khi cho model training qua các bộ data trên, ta sẽ đến bước để cho model tự thẩm trên data do chính nó tạo ra. Quá trình như sau:
-
Tạo prompt mới: Nhóm tác giả tạo một prompt mới bằng cách sử dụng few-shot prompting. Các prompt được sampling từ dữ liệu IFT ban đầu.
-
Tạo ra các candidate responses: Sau đó, ta sẽ tạo ra response khác nhau từ prompt .
-
Đánh giá các candidate responses: Cuối cùng, nhóm tác giả sử dụng khả năng LLM-as-a-Judge của cùng một model để đánh giá các candidate repsonse với điểm số .
Instruction Following Training
Tiếp theo ta sẽ tới quá trình gọi là AI Feedback Training. Sau khi thực hiện quá trình self-instruction creation. Chúng ta có thể augment các data ban đầu thành nhiều example hơn để thực hiện training. Đây chính là các AI Feedback Training (AIFT) data.
Để thực hiện điều này, ta sẽ tạo các preference pairs, data này sẽ có dạng (instruction prompt , winning response , losing response ). Để lựa chọn đâu là winning, đâu là losing, ta sẽ chọn repsonse có điểm số cao nhất và thấp nhất tương ứng trong 1 bộ các response được tạo. Chú ý rằng, ta sẽ bỏ đi những cặp mà có điểm số bằng nhau. Sau đó, các preference pair này được sử dụng cho quá trình DPO.
Tổng quan thuật toán Self-Alignment
Iterative Training. Ta sẽ thực hiện train một loạt các mô hình trong đó mỗi mô hình kế tiếp sử dụng augmented training data được tạo ra bởi mô hình trước đó. Nhóm tác giả định nghĩa AIFT() là dữ liệu huấn luyện AI Feedback được tạo ra bằng cách sử dụng mô hình .
Model Sequence
Cụ thể, nhóm tác giả định nghĩa các mô hình và dữ liệu được sử dụng tại từng step như sau:
-
: Model base pretrained LLM ban đầu, chưa được thực hiện finetune.
-
: Được khởi tạo từ , sau đó finetune trên dữ liệu IFT+EFT sử dụng SFT.
-
: Được khởi tạo từ , sau đó training với dữ liệu AIFT() sử dụng DPO.
-
: Được khởi tạo từ , sau đó training với dữ liệu AIFT() sử dụng DPO.
Quá trình huấn luyện lặp đi lặp lại này tương tự với quy trình được sử dụng trong Pairwise Cringe Optimization và được gọi là Iterative DPO.
Một số kết quả
Một số kết quả của phương pháp được thể hiện trong các bảng dữ liệu và sơ đồ dưới:
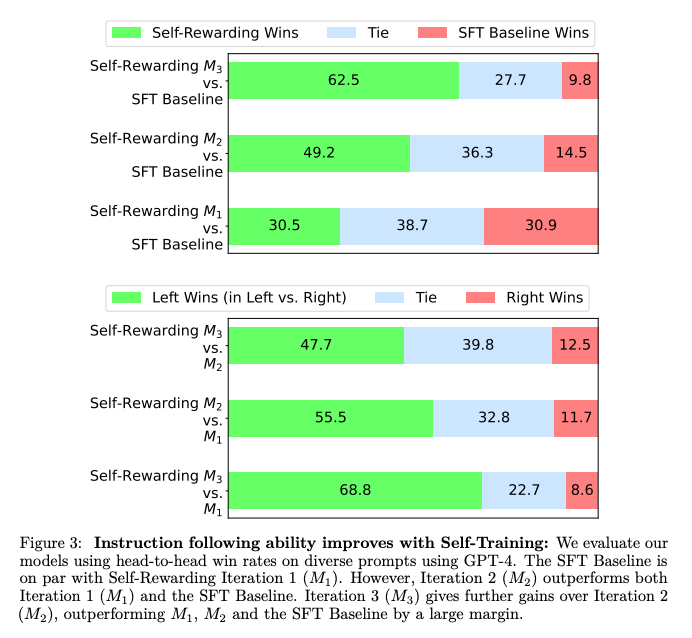
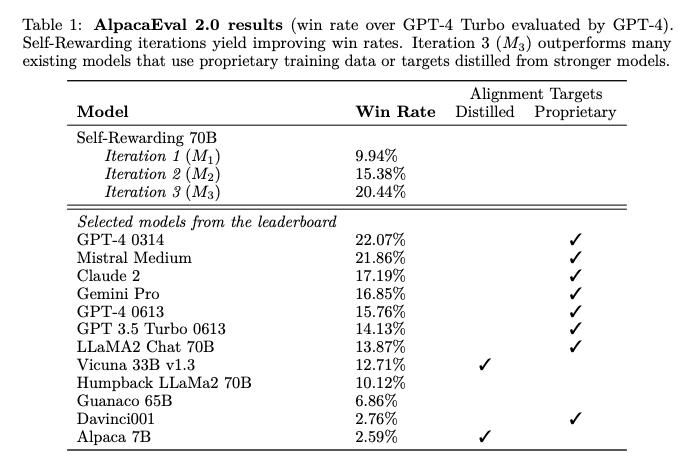
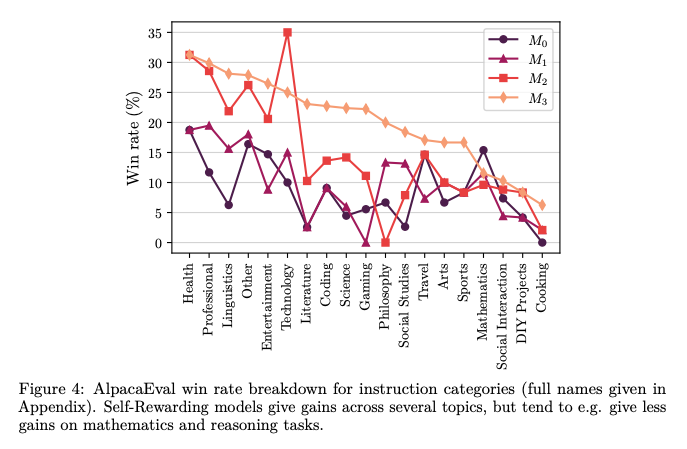
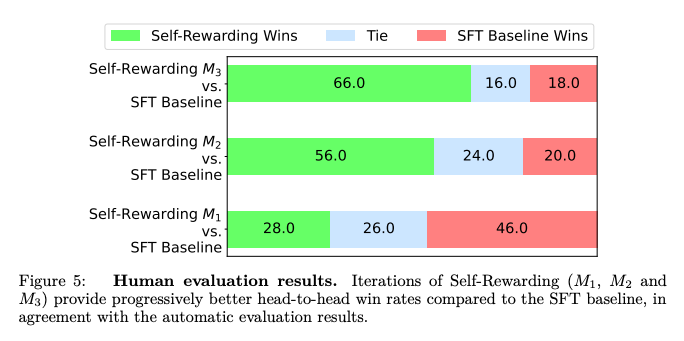
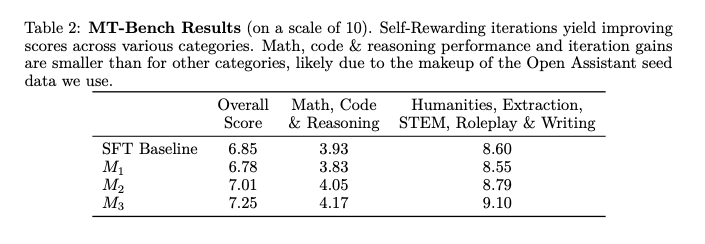
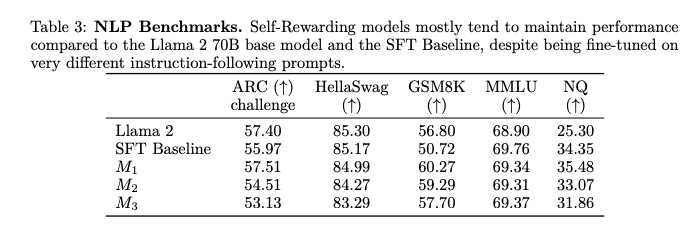
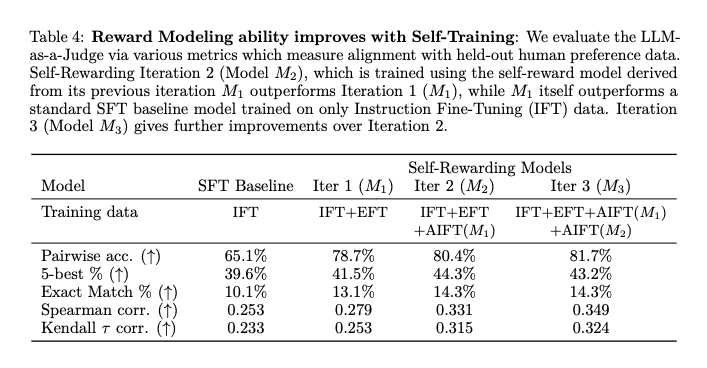
Tạm kết
Trong bài báo, nhóm tác giả đã giới thiệu phương pháp Self-Rewarding Language Models, đây là những mô hình có khả năng tự nâng cấp thông qua việc đánh giá và training trên các phiên bản của chính mình Phương pháp này học theo cách lặp lại, trong đó mỗi lượt lặp mô hình tạo ra dữ liệu training dựa trên preference của chính mô hình. Điều này được thực hiện bằng cách gán reward score thông qua LLM-as-a-Judge prompting và sử dụng Iterative DPO để training dựa trên các preference đó. Kết quả cho thấy rằng phương pháp này không chỉ cải thiện khả năng follow instruction mà còn nâng cao khả năng reward modeling qua các lần lặp.
Tuy nhiên, nhóm tác gỉa nhận định rằng cải thiện này có thể bị bão hòa trong các trường hợp thực tế. Các kết quả thí nghiệm ban đầu rất hứa hẹn nhưng cần phải nghiên cứu thêm để hiểu rõ hơn các giới hạn của training lặp lại và các "scaling law" của hiệu ứng này.
All rights reserved
