[LLM 101] Thử cài đặt Decomposed Low-Rank Adaptation (DoRA)
Giới thiệu
Low-rank adaptation (LoRA) là một phương pháp trong học máy được sử dụng để finetune một mô hình pretrain (ví dụ, một Large Language Model hoặc mô hình Vision Transformer) nhằm align nó với một tập dữ liệu cụ thể, thường là tập dữ liệu nhỏ hơn. Để đạt được này ta chỉ cần điều chỉnh chỉ một phần nhỏ lượng tham số của mô hình. Cách tiếp cận này quan trọng vì nó cho phép finetune hiệu quả các mô hình lớn trên dữ liệu đặc thù của nhiệm vụ, giảm đáng kể chi phí tính toán và thời gian cần thiết cho việc finetune.
Gần đây, các nhà nghiên cứu đã đề xuất một phương pháp mới gọi là DoRA: Weight-Decomposed Low-Rank Adaptation, đây là một phương pháp thay thế và có thể vượt trội hơn LoRA. Dưới đây là một hình ảnh được chú thích từ bài báo DoRA (https://arxiv.org/abs/2402.09353) minh họa hiệu suất của DoRA so với LoRA trên mô hình LLAMA-7B theo từng .
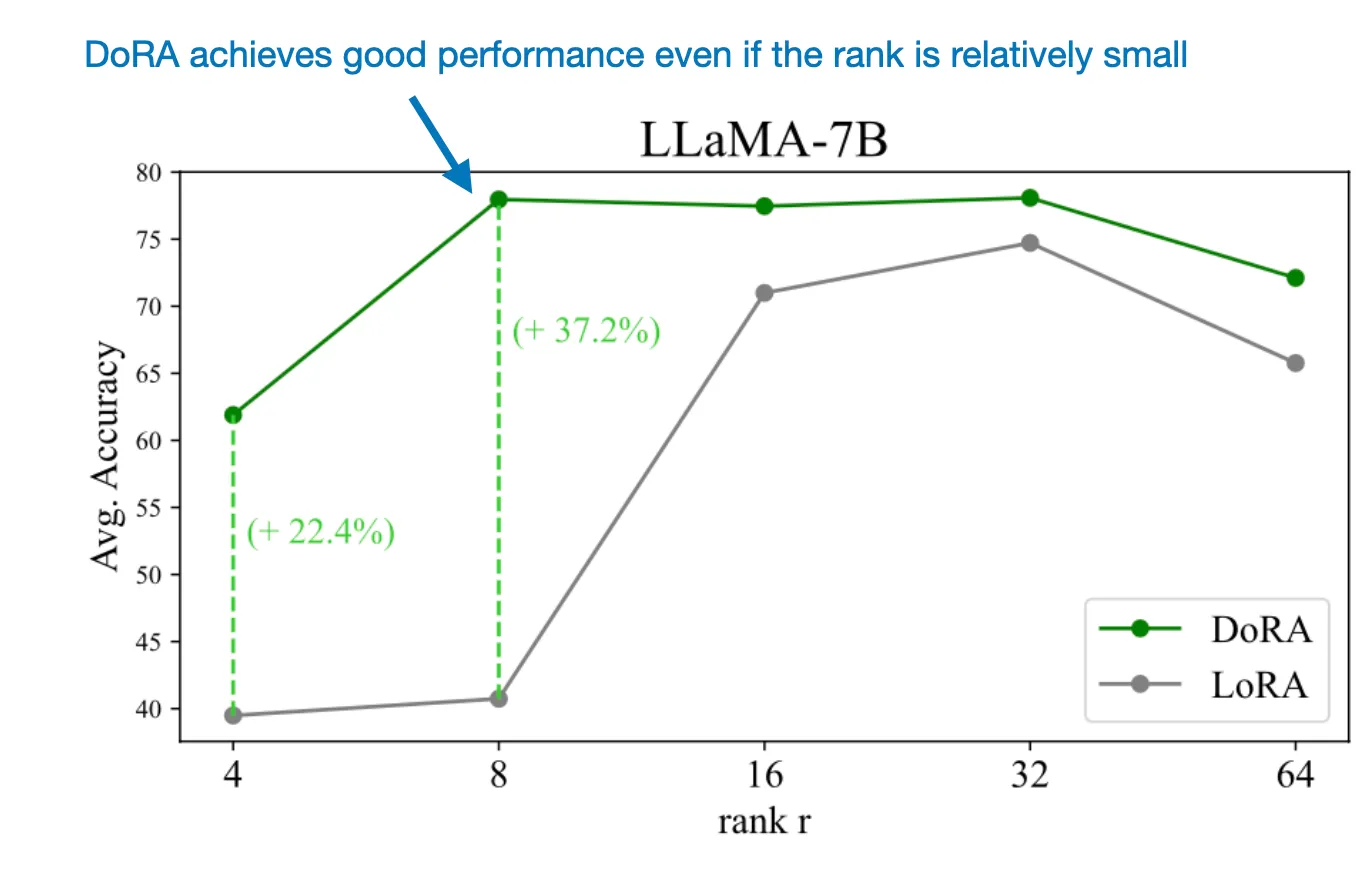
Như hình minh họa, DoRA đạt được hiệu suất tốt ngay cả khi tương đối nhỏ. Điều này cho thấy DoRA là một phương pháp thay thế đầy hứa hẹn cho LoRA.
Để hiểu rõ hơn về cách các phương pháp này hoạt động, chúng ta sẽ thử cài đặt cả LoRA và DoRA trong PyTorch trong bài viết này.
Nhắc lại kiến thức về LoRA
Trước khi đi sâu vào DoRA, hãy tóm tắt nhanh về cách LoRA hoạt động.
Vì các mô hình ngôn ngữ lớn (LLM) có kích thước rất lớn, việc cập nhật tất cả các trọng số mô hình trong quá trình huấn luyện có thể rất tốn kém do hạn chế về bộ nhớ GPU. Giả sử chúng ta có một ma trận trọng số lớn cho một layer nhất định. Trong quá trình backpropagation, chúng ta học một ma trận , chứa thông tin về mức độ chúng ta muốn cập nhật các trọng số ban đầu để giảm thiểu hàm mất mát (loss function) trong quá trình huấn luyện.
Trong quá trình huấn luyện và finetuning thông thường, cập nhật trọng số được định nghĩa như sau:
Phương pháp LoRA mang lại một cách tiếp cận hiệu quả hơn trong việc tính toán các cập nhật trọng số bằng cách học một sự xấp xỉ của nó, . Nói cách khác, trong LoRA, ta có:
Trong đó và là hai ma trận trọng số nhỏ.
Dưới đây là hình ảnh minh hoạ cho 2 cách làm trên 
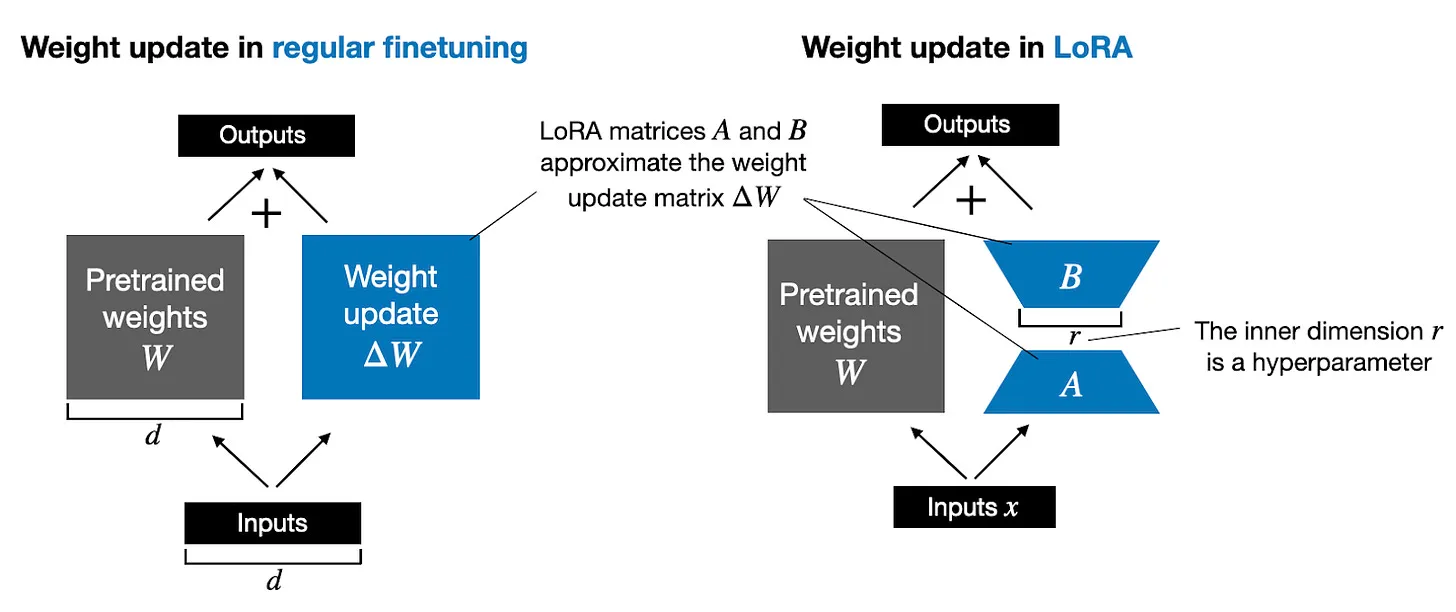
Trên hình, có thể thấy trong training thông thường (trái), toàn bộ ma trận trọng số được cập nhật trực tiếp bằng cách thêm . Trong khi đó, với LoRA (phải), trọng số được cập nhật gián tiếp qua hai ma trận nhỏ hơn và với một tham số hạng đã cho.
LoRA giúp tiết kiệm bộ nhớ GPU? Nếu một ma trận trọng số có kích thước 1,000 × 1,000 thì ma trận cập nhật trọng số trong quá trình finetuning tiêu chuẩn cũng có kích thước tương đương. Trong một trường hợp như vậy, có 1,000,000 tham số. Với LoRA nếu chọn hạng là 2, ma trận sẽ có kích thước 1,000 × 2 và ma trận sẽ là 2 × 1,000, số lượng tham số cần cập nhật chỉ là 2 × 2 × 1,000 = 4,000 tham số, tức là ít hơn 250 lần so với .
Rõ ràng, và không thể chứa hết thông tin như , nhưng đó là mục đích của thiết kế này. Khi sử dụng LoRA, chúng ta giả định rằng mô hình cần là một ma trận lớn với đầy đủ hạng (rank) để nắm bắt tất cả kiến thức trong tập dữ liệu tiền huấn luyện. Tuy nhiên, khi finetune một LLM, chúng ta không cần phải cập nhật tất cả các trọng số, mà có thể nắm bắt các thông tin cốt lõi cần thiết cho việc thích ứng bằng một lượng nhỏ các trọng số so với . Vì vậy, chỉ cần cập nhật hạng thấp qua là đủ.
Nếu bạn để ý kỹ, các hình minh họa về việc finetuning đầy đủ và LoRA trong hình trên trông hơi khác so với các công thức đã trình bày trước đó. Điều này là do tính chất phân phối của phép nhân ma trận: chúng ta không cần phải cộng các trọng số với các trọng số đã được cập nhật mà có thể giữ chúng riêng biệt. Ví dụ, nếu là dữ liệu đầu vào, chúng ta có thể viết công thức cho finetuning thông thường như sau:
Tương tự, chúng ta có thể viết công thức cho LoRA như sau:
Việc chúng ta có thể giữ các ma trận trọng số của LoRA riêng biệt là 1 điều rất thú vị Trên thực tế, điều này có nghĩa là chúng ta không cần phải chỉnh sửa các trọng số của mô hình đã pretrained. Ta có thể áp dụng các ma trận LoRA ngay khi lúc nào cần Điều này đặc biệt hữu ích nếu bạn đang xem xét việc lưu trữ một mô hình cho nhiều khách hàng. Thay vì phải lưu trữ các mô hình lớn đã được cập nhật cho từng khách hàng, bạn chỉ cần lưu trữ một tập hợp nhỏ các trọng số LoRA cùng với mô hình pretrained gốc
Để làm cho ý tưởng này bớt trừu tượng và cung cấp thêm trực quan, ta sẽ triển khai LoRA bằng code trong phần tiếp theo.
Cài đặt LoRA Layer
Chúng ta bắt đầu bằng cách khởi tạo một class có tên LoRALayer, class này sẽ tạo ra các ma trận và , cùng với các hyperparameter alpha và rank. Class này có thể nhận một đầu vào và tính toán đầu ra tương ứng, như minh họa trong hình dưới đây.
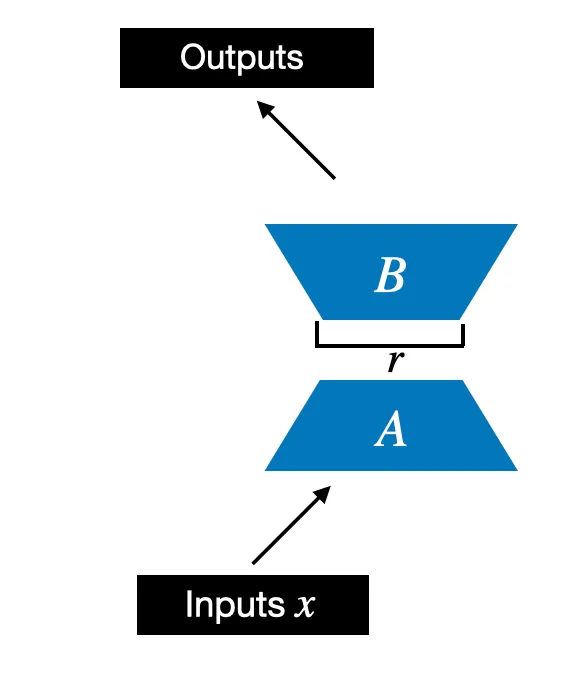
Trong đoạn code dưới đây, class LoRA được minh họa như sau:
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.A = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x
Trong đoạn code trên, rank là một hyperparameter điều khiển chiều trong (inner dim) của các ma trận và . Nói cách khác, tham số này kiểm soát số lượng tham số bổ sung được giới thiệu bởi LoRA và là yếu tố chính xác định sự cân bằng giữa khả năng thích ứng của mô hình và hiệu quả của tham số.
Hyperparameter thứ hai, alpha, là một tham số tỷ lệ được áp dụng cho đầu ra của adaptation low-rank. Nó về cơ bản điều khiển mức độ ảnh hưởng của đầu ra của layer LoRA lên các layer khác. Điều này có thể được hiểu như là một cách để điều chỉnh ảnh hưởng của adaptation hạng thấp lên đầu ra của layer.
Class LoRALayer mà chúng ta đã triển khai ở trên cho phép biến đổi các đầu vào của lớp . Tuy nhiên, trong LoRA, chúng ta thường quan tâm đến việc thay thế các lớp Linear hiện có để cập nhật trọng số được áp dụng cho các trọng số pretrained hiện có, như được minh họa trong hình dưới đây:
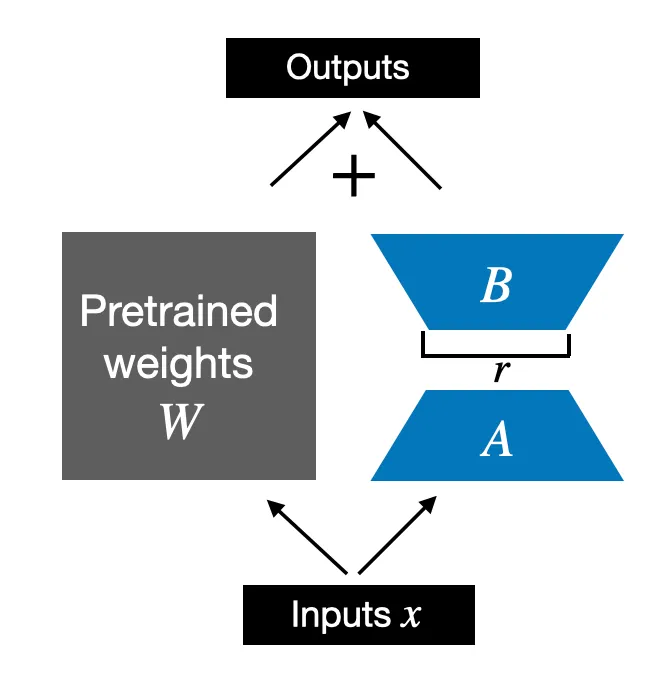
Để tích hợp các trọng số từ layer Linear gốc như minh họa trong hình trên, chúng ta sẽ triển khai class LinearWithLoRA sử dụng class LoRALayer đã được triển khai trước đó. Class LinearWithLoRA này có thể được sử dụng để thay thế các layer Linear hiện có trong một mạng neural, ví dụ như module self-attention hoặc các module feed forward trong một mô hình ngôn ngữ lớn (LLM):
import torch
import torch.nn as nn
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)
Lưu ý rằng vì chúng ta khởi tạo ma trận trọng số (self.B trong LoRALayer) với các giá trị bằng 0 trong lớp LoRA, phép nhân ma trận giữa và sẽ cho ra một ma trận chứa toàn bộ các giá trị bằng 0 và không làm ảnh hưởng đến các trọng số gốc (vì khi cộng 0 vào các trọng số gốc thì không làm thay đổi chúng).
Hãy thử áp dụng LoRA vào một layer neural nhỏ được biểu diễn bằng một layer Linear đơn:
import torch
torch.manual_seed(123)
layer = nn.Linear(10, 2)
x = torch.randn((1, 10))
print("Original output:", layer(x))
Đầu ra sẽ là:
Original output: tensor([[0.6639, 0.4487]], grad_fn=<AddmmBackward0>)
Bây giờ, áp dụng LoRA cho layer Linear, chúng ta sẽ thấy kết quả như cũ vì chúng ta chưa huấn luyện các trọng số LoRA. Nói cách khác, mọi thứ đều hoạt động như mong đợi
layer_lora_1 = LinearWithLoRA(layer, rank=2, alpha=4)
print("LoRA output:", layer_lora_1(x))
Đầu ra sẽ là:
LoRA output: tensor([[0.6639, 0.4487]], grad_fn=<AddmmBackward0>)
Như đã đề cập trước đó, theo tính chất phân phối của phép nhân ma trận:
Điều này có nghĩa là chúng ta cũng có thể kết hợp hoặc hợp nhất các ma trận LoRA và trọng số gốc, dẫn đến một triển khai tương đương. Trong code, triển khai thay thế cho lớp LinearWithLoRA sẽ như sau:
import torch.nn.functional as F
class LinearWithLoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
lora = self.lora.A @ self.lora.B # Kết hợp các ma trận LoRA
# Sau đó kết hợp LoRA với trọng số gốc
combined_weight = self.linear.weight + self.lora.alpha * lora.T
return F.linear(x, combined_weight, self.linear.bias)
Tóm lại, LinearWithLoRAMerged tính toán bên trái của phương trình $x \cdot (W + A \cdot B) = x \cdot W + x \cdot A \cdot B $ trong khi LinearWithLoRA tính toán bên phải của phương trình -- cả hai đều tương đương.
Chúng ta có thể xác minh rằng điều này cho ra kết quả tương tự như trước qua đoạn code sau:
layer_lora_2 = LinearWithLoRAMerged(layer, rank=2, alpha=4)
print("LoRA output:", layer_lora_2(x))
Đầu ra sẽ là:
LoRA output: tensor([[0.6639, 0.4487]], grad_fn=<AddmmBackward0>)
Bây giờ chúng ta đã có một triển khai LoRA hoạt động, hãy xem cách chúng ta có thể áp dụng nó vào một mạng neural ở phần tiếp theo.
Sử dụng LoRA Layer
Chúng ta đã triển khai và sử dụng LoRA theo cách được mô tả ở trên bằng PyTorch nhằm thay thế dễ dàng các lớp Linear trong các mô hình neural hiện có (ví dụ như các module self-attention hoặc feed forward trong Large Language Model - LLM) bằng các class LinearWithLoRA (hoặc LinearWithLoRAMerged).
Để đơn giản hóa, hãy tập trung vào một multilayer perceptron 3 layer thay vì một LLM, như minh họa trong hình dưới đây:
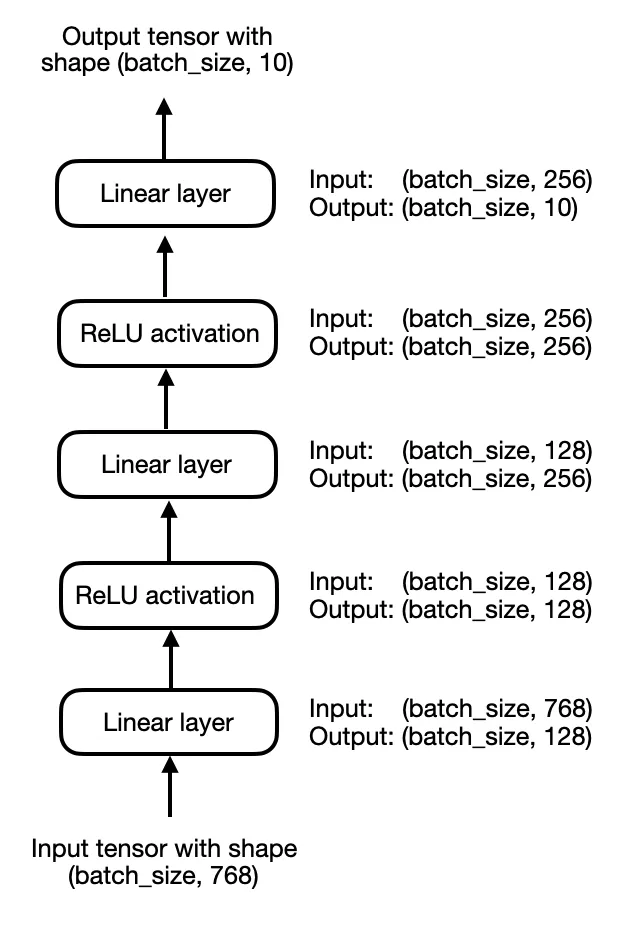
Trong code, chúng ta có thể triển khai multilayer perceptron như sau:
import torch.nn as nn
class MultilayerPerceptron(nn.Module):
def __init__(self, num_features, num_hidden_1, num_hidden_2, num_classes):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(num_features, num_hidden_1),
nn.ReLU(),
nn.Linear(num_hidden_1, num_hidden_2),
nn.ReLU(),
nn.Linear(num_hidden_2, num_classes)
)
def forward(self, x):
x = self.layers(x)
return x
# Khởi tạo mô hình với các tham số cụ thể
num_features = 768
num_hidden_1 = 128
num_hidden_2 = 256
num_classes = 10
model = MultilayerPerceptron(
num_features=num_features,
num_hidden_1=num_hidden_1,
num_hidden_2=num_hidden_2,
num_classes=num_classes
)
print(model)
Đầu ra sẽ là:
MultilayerPerceptron(
(layers): Sequential(
(0): Linear(in_features=768, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=10, bias=True)
)
)
Sử dụng LinearWithLoRA, chúng ta có thể thêm các lớp LoRA bằng cách thay thế các lớp Linear gốc trong mô hình multilayer perceptron:
model.layers[0] = LinearWithLoRA(model.layers[0], rank=4, alpha=8)
model.layers[2] = LinearWithLoRA(model.layers[2], rank=4, alpha=8)
model.layers[4] = LinearWithLoRA(model.layers[4], rank=4, alpha=8)
print(model)
Đầu ra sẽ là:
MultilayerPerceptron(
(layers): Sequential(
(0): LinearWithLoRA(
(linear): Linear(in_features=768, out_features=128, bias=True)
(lora): LoRALayer()
)
(1): ReLU()
(2): LinearWithLoRA(
(linear): Linear(in_features=128, out_features=256, bias=True)
(lora): LoRALayer()
)
(3): ReLU()
(4): LinearWithLoRA(
(linear): Linear(in_features=256, out_features=10, bias=True)
(lora): LoRALayer()
)
)
)
Sau đó, chúng ta có thể "đóng băng" các layer Linear gốc và chỉ làm cho các lớp LoRALayer có thể trainable như sau:
def freeze_linear_layers(model):
for child in model.children():
if isinstance(child, nn.Linear):
for param in child.parameters():
param.requires_grad = False
else:
# Recursively freeze linear layers in children modules
freeze_linear_layers(child)
freeze_linear_layers(model)
for name, param in model.named_parameters():
print(f"{name}: {param.requires_grad}")
Đầu ra sẽ là:
layers.0.linear.weight: False
layers.0.linear.bias: False
layers.0.lora.A: True
layers.0.lora.B: True
layers.2.linear.weight: False
layers.2.linear.bias: False
layers.2.lora.A: True
layers.2.lora.B: True
layers.4.linear.weight: False
layers.4.linear.bias: False
layers.4.lora.A: True
layers.4.lora.B: True
Dựa vào các giá trị True và False ở trên, chúng ta có thể xác nhận rằng chỉ các layer LoRA là có thể huấn luyện bây giờ (True nghĩa là có thể huấn luyện, False nghĩa là bị đóng băng). Trên thực tế, chúng ta sẽ huấn luyện mô hình với cấu hình LoRA trên một tập dữ liệu hoặc nhiệm vụ mới.
Weight-Decomposed Low-Rank Adaptation (DoRA)
DoRA (Weight-Decomposed Low-Rank Adaptation) hiện được xem như một cải tiến hoặc mở rộng của LoRA, nhờ vào việc xây dựng trên nền tảng của nó. Quá trình này có thể được diễn tả qua hai bước chính:
- Phân rã ma trận trọng số pretrain thành vector độ lớn () và ma trận hướng ().
- Áp dụng LoRA vào ma trận hướng và training riêng biệt vector độ lớn .
Phân rã thành các thành phần độ lớn và hướng được lấy cảm hứng từ nguyên lý toán học: bất kỳ vector nào cũng có thể được biểu diễn bằng tích của độ lớn của nó (giá trị vô hướng biểu thị độ dài) và hướng của nó (một vector đơn vị biểu thị phương hướng trong không gian).
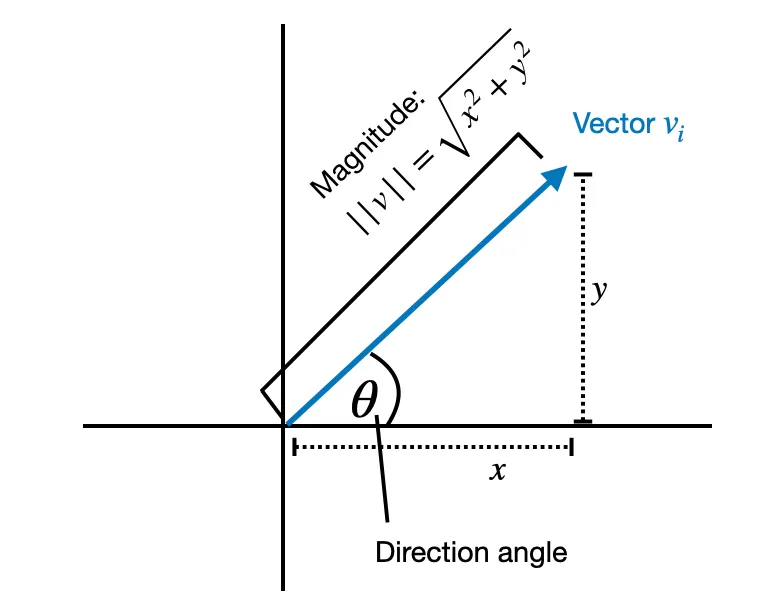
Ví dụ, với vector 2D , ta có thể phân rã vector này thành một độ lớn là 2.24 và một vector hướng là . Khi đó:
Trong DoRA, quá trình phân rã này được áp dụng cho ma trận trọng số pretrained (), thay vì chỉ áp dụng cho một vector. Mỗi cột của ma trận trọng số tương ứng với các trọng số kết nối tất cả đầu vào với một neuron đầu ra cụ thể.
Kết quả của việc phân rã ma trận là một vector độ lớn và một ma trận hướng , trong đó mỗi cột của chứa một vector hướng .
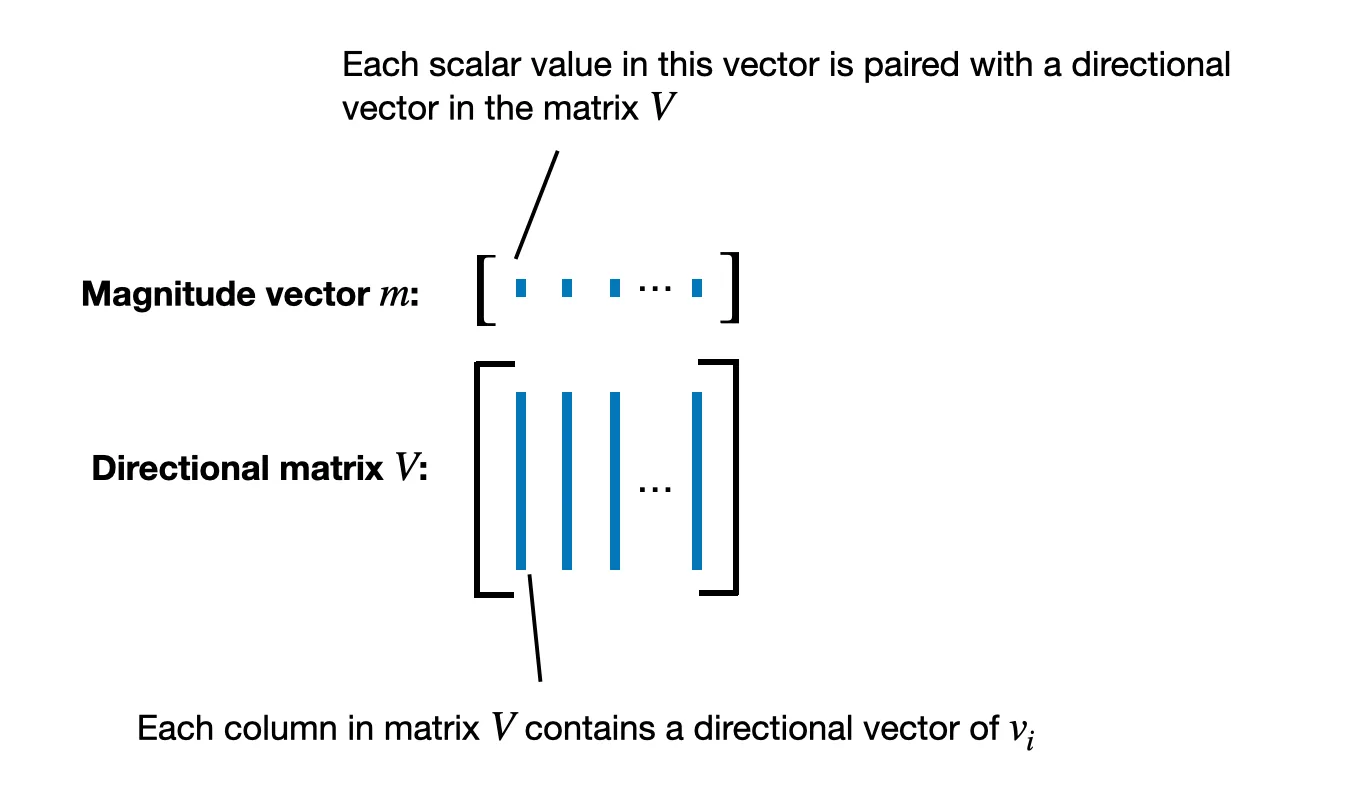
Khi đã có ma trận hướng , DoRA áp dụng LoRA tiêu chuẩn bằng cách:
Trong đó "norm" đại diện cho quá trình chuẩn hóa trọng số.
Phương pháp DoRA (Decomposed Representation Learning using LoRA) được thiết kế nhằm cải thiện một số hạn chế của LoRA (Low-Rank Adaptation) trong quá trình training model. Quy trình hai bước của DoRA bao gồm phân rã ma trận trọng số (weight matrix) đã được pretrained và áp dụng LoRA cho ma trận định hướng (directional matrix), như được minh họa trong hình ảnh từ bài báo về DoRA.
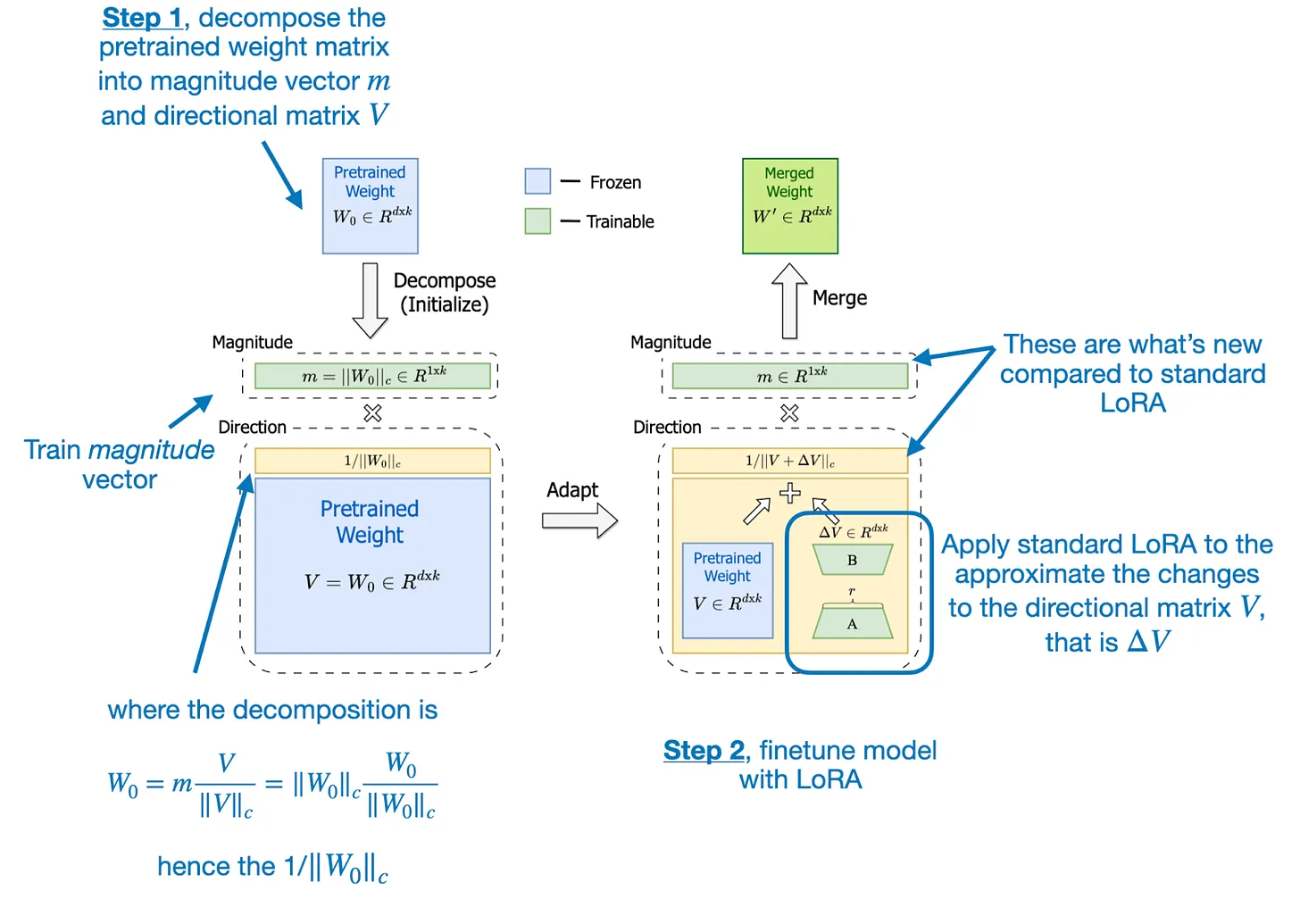
Trong bước đầu tiên, ma trận trọng số pretrained được phân rã thành vector độ lớn và ma trận định hướng .
- Vector độ lớn: .
- Ma trận định hướng: .
Cả hai thành phần này được khởi tạo từ ma trận trọng số , trong đó:
Trong biểu thức trên, là hệ số chuẩn hóa để điều chỉnh độ phức tạp của mô hình.
Sau khi đã phân rã xong xuôi ma trận trọng số, bước tiếp theo là áp dụng phương pháp LoRA tiêu chuẩn để biểu diễn các thay đổi đối với ma trận định hướng , tức là .
- Huấn luyện vector độ lớn độc lập với ma trận định hướng.
- Áp dụng LoRA để tạo ra thông qua các ma trận và .
Những thay đổi này sau đó được cộng vào ma trận định hướng ban đầu và nhân với vector độ lớn để tạo ra ma trận trọng số mới:
Nghiên cứu cho thấy rằng việc áp dụng DoRA có thể cải thiện hiệu suất so với LoRA, mặc dù chi phí tính toán thêm không nhiều. Điều này được thể hiện rõ qua các bảng so sánh và biểu đồ hiệu suất trong hình ảnh. Mặc dù DoRA chỉ thêm vào mô hình 0.01% số tham số so với LoRA, nhưng trên các bộ dữ liệu benchmark của LLM và Vision Transformer, DoRA vẫn vượt trội hơn khi sử dụng chỉ bằng một nửa số tham số của LoRA.
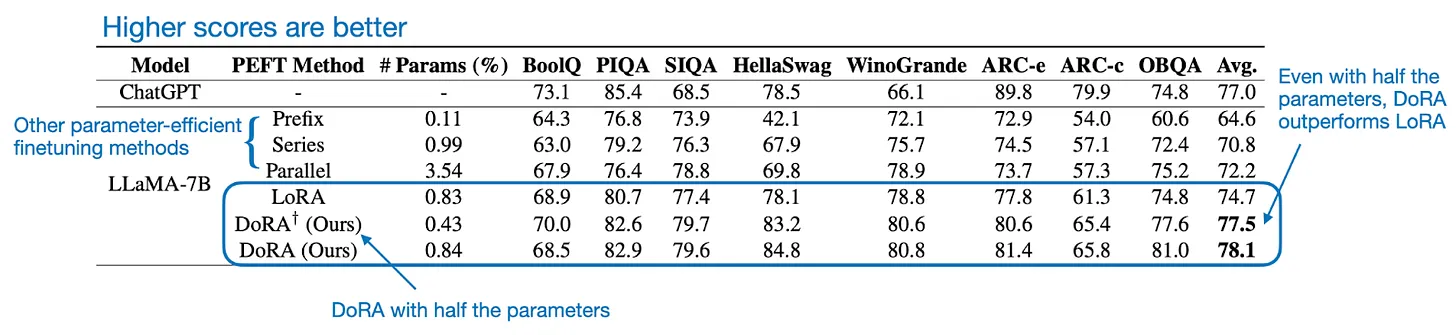
Một khía cạnh quan trọng khác của DoRA là tính ổn định với các thay đổi trong hạng (rank) của mô hình. Như biểu đồ so sánh cho thấy, DoRA đạt hiệu suất tốt ngay cả khi hạng tương đối nhỏ, khiến cho phương pháp này trở thành lựa chọn tối ưu hơn về số lượng tham số cần thiết so với LoRA.
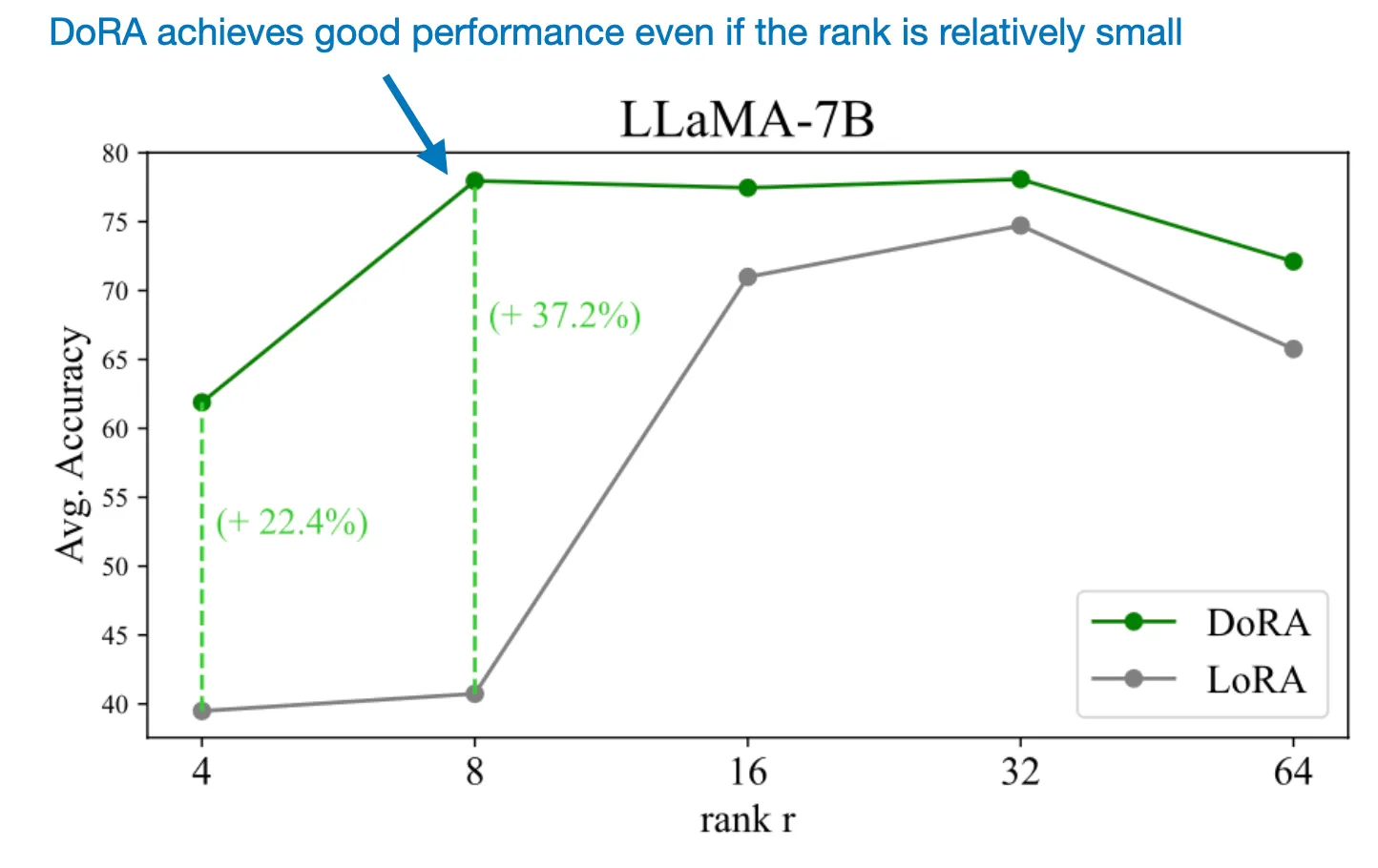
Như vậy, DoRA không chỉ cải thiện hiệu suất mà còn tối ưu hóa về tài nguyên tính toán.
Cài đặt DoRA Layer
Trong phần này, chúng ta sẽ xem cách triển khai DoRA. Trước đó, chúng ta đã nói rằng có thể khởi tạo trọng số đã được pretrained với độ lớn và thành phần hướng . Ví dụ, ta có phương trình sau:
trong đó là chuẩn vector của . Sau đó, chúng ta có thể viết DoRA bao gồm cả cập nhật trọng số của LoRA như dưới đây:
Trong bài báo về DoRA, các tác giả đã đưa ra công thức cho DoRA như sau, trong đó họ sử dụng trọng số pretrained ban đầu trực tiếp như thành phần hướng và học vector độ lớn trong quá trình huấn luyện:
Ở đây, là cập nhật cho thành phần hướng, ma trận .
Dưới đây là đoạn code minh hoạ:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LinearWithDoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(linear.in_features, linear.out_features, rank, alpha)
self.m = nn.Parameter(self.linear.weight.norm(p=2, dim=0, keepdim=True))
def forward(self, x):
lora = self.lora.A @ self.lora.B
numerator = self.linear.weight + self.lora.alpha * lora.T
denominator = numerator.norm(p=2, dim=0, keepdim=True)
directional_component = numerator / denominator
new_weight = self.m * directional_component
return F.linear(x, new_weight, self.linear.bias)
Class LinearWithDoRAMerged khác với class LinearWithLoRAMerged trước đó ở một số khía cạnh chủ yếu, đặc biệt ở cách nó thay đổi và áp dụng các trọng số của layer Linear. Tuy nhiên, cả hai lớp đều tích hợp một LoRALayer để bổ sung trọng số của lớp linear ban đầu, nhưng DoRA còn thêm vào bước chuẩn hóa và điều chỉnh trọng số.
Trong mô hình LinearWithDoRAMerged, sau khi kết hợp các trọng số gốc với các trọng số đã được điều chỉnh bởi LoRA (self.linear.weight + self.lora.alpha*lora.T), mô hình sẽ tính toán chuẩn của các trọng số kết hợp này theo cột (column_norm). Sau đó, các trọng số kết hợp sẽ được chuẩn hóa bằng cách chia cho các chuẩn cột này (). Bước này đảm bảo rằng mỗi cột của ma trận trọng số kết hợp có chuẩn đơn vị, giúp duy trì thang đo của các cập nhật trọng số và ổn định quá trình học.
DoRA còn giới thiệu một vector có thể trainable self.m, đại diện cho độ lớn của mỗi cột trong ma trận trọng số đã được chuẩn hóa. Tham số này cho phép mô hình điều chỉnh động thang đo của mỗi vector trọng số trong ma trận trọng số kết hợp trong quá trình huấn luyện. Sự thêm vào linh hoạt này giúp mô hình nắm bắt tốt hơn tầm quan trọng của các đặc trưng khác nhau.
Tóm lại, LinearWithDoRAMerged là phiên bản mở rộng của LinearWithLoRAMerged bằng cách kết hợp chuẩn hóa trọng số động và thay đổi tỉ lệ để cải thiện hiệu suất huấn luyện.
Trong thực tế, xét đến multilayer perceptron)từ trước đó, chúng ta có thể thay thế các lớp Linear hiện có bằng các lớp LinearWithDoRAMerged như sau:
In:
model.layers[0] = LinearWithDoRAMerged(model.layers[0], rank=4, alpha=8)
model.layers[2] = LinearWithDoRAMerged(model.layers[2], rank=4, alpha=8)
model.layers[4] = LinearWithDoRAMerged(model.layers[4], rank=4, alpha=8)
print(model)
Đầu ra sẽ như sau:
Out:
MultilayerPerceptron(
(layers): Sequential(
(0): LinearWithDoRAMerged(
(linear): Linear(in_features=784, out_features=128, bias=True)
(lora): LoRALayer()
)
(1): ReLU()
(2): LinearWithDoRAMerged(
(linear): Linear(in_features=128, out_features=256, bias=True)
(lora): LoRALayer()
)
(3): ReLU()
(4): LinearWithDoRAMerged(
(linear): Linear(in_features=256, out_features=10, bias=True)
(lora): LoRALayer()
)
)
)
Trước khi finetuning mô hình, chúng ta có thể sử dụng lại hàm freeze_linear_layers đã được triển khai trước đó để làm cho các trọng số LoRA và các vector độ lớn có thể train được:
In:
freeze_linear_layers(model)
for name, param in model.named_parameters():
print(f"{name}: {param.requires_grad}")
Đầu ra sẽ như sau:
Out:
layers.0.m: True
layers.0.linear.weight: False
layers.0.linear.bias: False
layers.0.lora.A: True
layers.0.lora.B: True
layers.2.m: True
layers.2.linear.weight: False
layers.2.linear.bias: False
layers.2.lora.A: True
layers.2.lora.B: True
layers.4.m: True
layers.4.linear.weight: False
layers.4.linear.bias: False
layers.4.lora.A: True
layers.4.lora.B: True
Các trọng số linear truyền thống được đóng băng (không train được), và chỉ các trọng số LoRA cùng với vector độ lớn được cập nhật trong quá trình huấn luyện.
All rights reserved
