[LLM 101] Thảo luận các vấn đề về Finetune Large Language Models
Giới thiệu
Như các bạn đã biết, lĩnh vực trí tuệ nhân tạo đang phát triển nhanh chóng và việc sử dụng hiệu quả các mô hình ngôn ngữ lớn (large language models - LLMs) trở nên ngày càng quan trọng. Tuy nhiên, có nhiều cách sử dụng khác nhau đối với LLMs, điều này có thể khiến người mới bắt đầu cảm thấy hơi ngợp 
Về cơ bản, có hai cách chính để sử dụng pretraining LLMs cho các tác vụ mới: Học trong ngữ cảnh (in-context learning) và tinh chỉnh (finetuning). Bài viết này sẽ giải thích ngắn gọn về In-context learning và sau đó là các cách khác nhau để finetune LLMs.
In-Context Learning và Indexing
Kể từ khi GPT-2 và GPT-3 ra đời, chúng ta thấy rằng các mô hình pretrained generative LLMs trên dữ liệu văn bản chung có khả năng In-Context Learning. Điều này tức là chúng ta không cần phải training hoặc finetuning thêm các LLMs để thực hiện các tác vụ mới hoặc cụ thể mà mô hình chưa được huấn luyện. Thay vào đó, chúng ta có thể cung cấp trực tiếp một vài ví dụ của tác vụ thông qua văn bản đầu vào, hay nói một cách khác là chúng ta nhập prompt. Cụ thể như sau:
Minh họa ví dụ về In-Context Learning:
Translate the following German sentences into Vietnam:
Example 1:
German: "Ich liebe Eis."
English: "Tôi rất thích kem"
Example 2:
German: "Draußen ist es stürmisch und regnerisch"
English: "Ngoài trời đang có bão và mưa."
Translate this sentence:
German: "Wo ist die nächste Supermarkt?"
In-Context learning rất hữu ích vì chúng ta không cần can thiệp trực tiếp vào mô hình. Việc đơn giản cần làm là ta sẽ sử dụng mô hình thông qua API Liên quan đến In-context learning ta có khái niệm hard prompt tuning, nơi ta thay đổi đầu vào để cải thiện đầu ra, như minh họa dưới đây.
Minh họa về hard prompt tuning:
1) "Translate the English sentence '{english_sentence}' into German: {german_translation}"
2) "English: '{english_sentence}' | German: {german_translation}"
3) "From English to German: '{english_sentence}' -> {german_translation}"
Chúng ta gọi đây là hard prompt tuning vì ta thay đổi trực tiếp các từ hay token đầu vào.
Hard prompt tuning như trên là một cách tiếp cận tiết kiệm tài nguyên hơn so với parameter finetuning. Tuy nhiên, hiệu quả của nó thường không bằng finetuning, vì nó không cập nhật các tham số của mô hình cho một tác vụ cụ thể, điều này có thể hạn chế khả năng đáp ứng yêu cầu của mô hình với yêu cầu cụ thể nào đó. Hơn nữa, prompt tuning cũng có thể tốn nhiều công sức, vì thường yêu cầu con người tham gia so sánh chất lượng của các prompt khác nhau.
Trước khi thảo luận chi tiết về finetuning, một phương pháp khác thường được sử dụng để thay thế cho in-context learning là lập chỉ mục (indexing). Trong LLMs, indexing được coi là một giải pháp thay thế cho in-context learning, cho phép chuyển đổi LLMs trở thành các hệ thống truy xuất thông tin để trích xuất dữ liệu từ các nguồn tài liệu bên ngoài và trang web. Trong quá trình này, module indexing chia nhỏ tài liệu hoặc nội dung trang web thành các đoạn nhỏ hơn gọi là chunk, biến đổi chúng thành vector và lưu trữ trong vector database.
Sau đó, khi người dùng gửi một truy vấn, module indexing sẽ tính toán độ tương đồng vector giữa truy vấn và từng vector trong vector database để cuối cùng tìm kiếm được các vector tương tự nhất để tạo ra phản hồi.
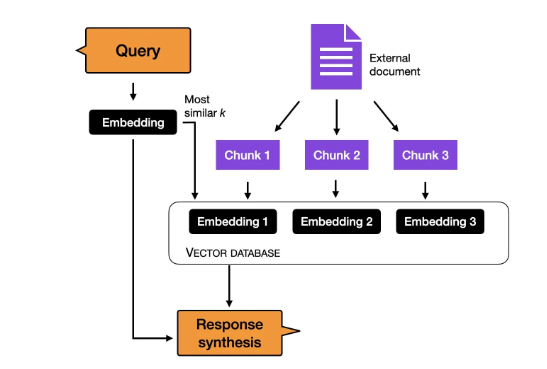
Các cách finetuning phổ biến
In-Context Learning là một phương pháp khá ổn và dễ sử dụng khi truy cập trực tiếp vào LLM bị hạn chế, ví dụ khi tương tác thông qua API hoặc giao diện người dùng
Tuy nhiên, nếu có quyền truy cập trực tiếp vào LLM, việc finetune mô hình cho một tác vụ cụ thể thường cho kết quả tốt hơn. Vậy làm thế nào để finetune một mô hình cho một tác vụ cụ thể? Có ba phương pháp truyền thống như minh họa dưới đây:
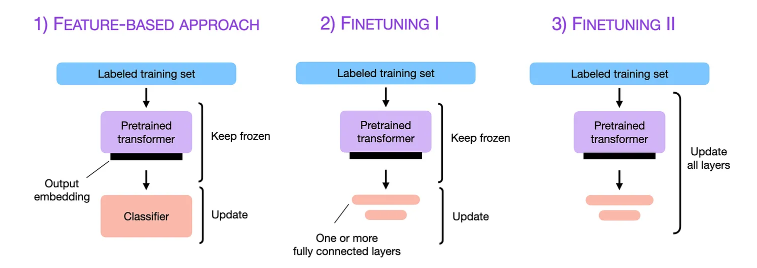
Ý tưởng chính của các phương pháp này như sau:
-
Feature-Based: Trong phương pháp này, chúng ta sử dụng tập huấn luyện có nhãn để tải mô hình transformer đã được huấn luyện sẵn và giữ nguyên các trọng số (weight) của nó. Chúng ta chỉ cần trích xuất các embeddings đầu ra và sử dụng chúng làm đặc trưng (feature) đầu vào cho mô hình phân loại, và chỉ cập nhật các tham số của bộ phân loại. Rất dễ hiểu phải không
-
Finetuning I: Cũng sử dụng tập huấn luyện có nhãn, chúng ta tải mô hình transformer đã được huấn luyện sẵn, giữ nguyên các trọng số của nó và chỉ cập nhật các trọng số của các fully connected layers ở cuối mô hình. Trong quá trình huấn luyện, chỉ các layer này được cập nhật trọng số.
-
Finetuning II: Với tập huấn luyện có nhãn, chúng ta tải mô hình transformer đã được huấn luyện sẵn và cập nhật tham số của tất cả các layer trong mô hình, trong đó bao gồm cả các lớp bổ sung.
Cách tiếp cận Feature-Based
Trong cách tiếp cận dựa trên đặc trưng (feature-based), chúng ta sẽ tải một mô hình pretrained LLM và sử dụng nó cho tập data mục tiêu của mình. Đặc biệt, chúng ta quan tâm đến việc tạo các đầu ra embeddings cho training set, đây sẽ là các feature đầu vào để huấn luyện một mô hình phân loại
Mặc dù cách tiếp cận này thường sử dụng với các mô hình embeddings như BERT, chúng ta cũng có thể trích xuất embeddings từ các generative model như GPT.
Mô hình phân loại sau đó có thể là một mô hình hồi quy logistic, random forest hoặc XGBoost,...
Đoạn code ví dụ minh hoạ cho cách tiếp cận này như sau:
from transformers import AutoModel
import torch
import numpy as np
from sklearn.linear_model import LogisticRegression
# Tải mô hình pretrained
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ... tokenize dataset ...
# Hàm tạo embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
# Tạo các features cho tập dữ liệu
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10
)
# Chuyển đổi dữ liệu thành mảng numpy
X_train = np.array(imdb_features["train"]["features"])
y_train = np.array(imdb_features["train"]["label"])
X_val = np.array(imdb_features["validation"]["features"])
y_val = np.array(imdb_features["validation"]["label"])
X_test = np.array(imdb_features["test"]["features"])
y_test = np.array(imdb_features["test"]["label"])
# Huấn luyện bộ phân loại hồi quy logistic
clf = LogisticRegression()
clf.fit(X_train, y_train)
# In độ chính xác của các tập dữ liệu
print("Training accuracy", clf.score(X_train, y_train))
print("Validation accuracy", clf.score(X_val, y_val))
print("Test accuracy", clf.score(X_test, y_test))
Finetuning I
Như mình đã đề cập trong phần trên, đây là phương pháp mà ta chỉ cập nhật các Fully connected layers cuối cùng trong model. Chúng ta sẽ giữ nguyên các trọng số của các LLM pretrained và chỉ huấn luyện các layer đầu ra mới thêm vào.
Dưới đây là đoạn code minh họa:
from transformers import AutoModelForSequenceClassification
import torch
# Tải mô hình pretrain với hai nhãn (positive, negative)
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
# Đóng băng tất cả các layer của mô hình
for param in model.parameters():
param.requires_grad = False
# Mở khóa hai layer cuối cùng (các layer đầu ra)
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
# Finetune model
lightning_model = CustomLightningModule(model)
trainer = L.Trainer(
max_epochs=3,
# ... các cấu hình khác ...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader
)
# Đánh giá mô hình
trainer.test(
model=lightning_model,
dataloaders=test_loader
)
Finetuning II
Mặc dù bài báo gốc về BERT đã chỉ ra rằng rằng việc finetune các layer cuối có thể mang lại hiệu suất mô hình tương đương với việc finetune tất cả các layer, nhưng finetune tất cả các layer lại tốn kém hơn đáng kể do phải tính toán nhiều trọng số hơn.
Ví dụ, một mô hình BERT base có khoảng 110 triệu tham số. Tuy nhiên, layer cuối của mô hình BERT base cho phân loại nhị phân chỉ có khoảng 1,500 tham số. Trong khi đó, hai layer cuối của mô hình BERT base có khoảng 60,000 tham số, chiếm khoảng 0.6% tổng kích thước mô hình.
Hiệu quả của việc finetune sẽ thay đổi dựa trên mức độ giống nhau giữa tác vụ mục tiêu và miền mục tiêu với tập dữ liệu mà mô hình đã được pretrain. Trong thực tế, việc finetune tất cả các layer gần như luôn mang lại hiệu suất mô hình vượt trội.
Vì vậy, khi tối ưu hóa hiệu suất mô hình, tiêu chuẩn vàng (gold standard) để sử dụng các LLMs đã pretrain là cập nhật tất cả các layer của mô hình. Các bạn có thể thấy finetuning II rất giống với finetuning I, sự khác biệt duy nhất là chúng ta không đóng băng trọng số của LLM đã huấn luyện sẵn mà sẽ finetune tất cả.
Dưới đây là đoạn code minh hoạ
from transformers import AutoModelForSequenceClassification
import torch
from pytorch_lightning import Trainer
# Tải mô hình đã huấn luyện sẵn với hai nhãn
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
# Không đóng băng bất kỳ lớp nào
# Tinh chỉnh mô hình
lightning_model = CustomLightningModule(model)
trainer = Trainer(
max_epochs=3,
# ... các cấu hình khác ...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader
)
# Đánh giá mô hình
trainer.test(
model=lightning_model,
dataloaders=test_loader
)
Dưới đây là kết quả thực tế khi huấn luyện mô hình phân loại đánh giá phim sử dụng base model pretrained DistilBERT:
- Phương Pháp Feature-based kết hợp với Hồi quy Logistic: Độ chính xác đạt 83%.
- Finetuning I, cập nhật 2 layer cuối cùng: Độ chính xác đạt 87%.
- Finetuning II, cập nhật tất cả các layer: Độ chính xác đạt 92%.
Tất nhiên, hiệu suất của chúng sẽ thay đổi tùy thuộc vào mô hình và tập data, nhưng việc khám phá các lựa chọn finetuning và xem xem cách nào hiệu quả cũng khá là thú vị .
Ví dụ, chúng ta có thể đạt hiệu suất tương tự bằng cách chỉ training một nửa số layers của mô hình. Biểu đồ dưới đây cho thấy hiệu suất dự đoán và thời gian training khi finetuning các layers khác nhau của mô hình DistilBERT trên tập 20k sample training từ tập data đánh giá phim IMDB.
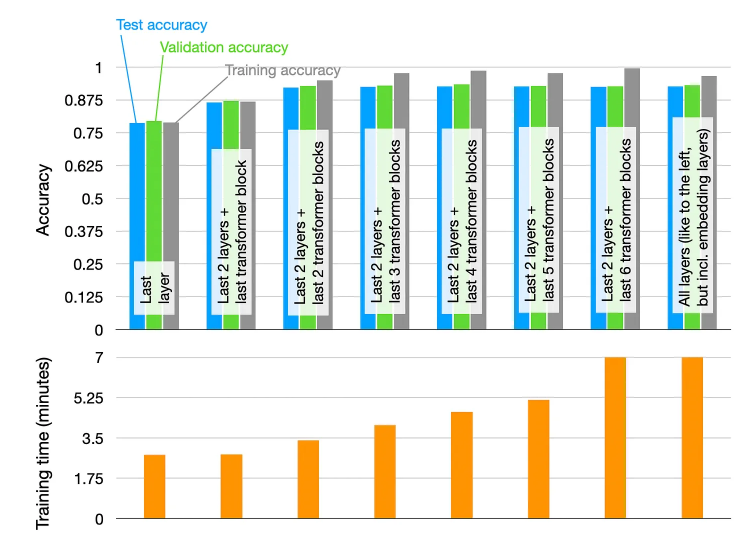
Các kết quả như sau:
-
Training layer cuối:
- Thời gian training nhanh nhất.
- Hiệu suất mô hình kém nhất.
-
Training các layers cuối và một số block transformer:
- Việc training kết hợp hai layers fully connected cuối và các khối transformer cuối cùng cải thiện hiệu suất mô hình.
- Tuy nhiên, khi tăng số layer training, thời gian training cũng tăng lên.
-
Sự bão hòa hiệu suất:
- Hiệu suất dự đoán đạt mức tối đa khi training hai layer đầu ra fully connected và hai khối transformer cuối cùng.
Ta có thể đưa ra các kết luận sau:
- Tối ưu hóa giữa hiệu suất và chi phí: Khi phải cân bằng giữa hiệu suất mô hình và chi phí tính toán, việc lựa chọn số layer phù hợp để finetuning là rất quan trọng.
- Finetuning có chọn lọc: Tùy theo mô hình và tập data mục tiêu, việc chỉ finetuning một phần của mô hình có thể đạt được hiệu suất tương đương với việc finetuning toàn bộ mô hình nhưng với chi phí thấp hơn đáng kể.
- Khám phá nhiều tùy chọn finetuning: Thử nghiệm với các phương pháp khác nhau có thể mang lại hiệu suất tốt nhất mà không lãng phí tài nguyên.
Parameter-Efficient Finetuning
Parameter-Efficient Finetuning cho phép chúng ta tái sử dụng các mô hình đã huấn luyện sẵn trong khi giảm thiểu chi phí về tính toán và tài nguyên. Tóm lại, Parameter-Efficient Finetuning mạng lại những lợi ích sau:
- Giảm chi phí tính toán (cần ít GPU và thời gian GPU hơn);
- Thời gian training nhanh hơn (hoàn thành training nhanh hơn);
- Yêu cầu phần cứng thấp hơn (Yêu cầu tính toán trên GPU ít hơn và sử dụng ít bộ nhớ hơn);
- Hiệu suất mô hình tốt hơn (giảm overfitting);
- Tiết kiệm dung lượng lưu trữ (đa số trọng số có thể được chia sẻ qua các tác vụ khác nhau).
Trong các phần trước, chúng ta đã biết rằng finetuning nhiều layers thường dẫn đến kết quả tốt hơn. Các thí nghiệm trên đều dựa trên mô hình DistilBERT, vốn tương đối nhỏ. Nhưng nếu chúng ta muốn finetuning các mô hình lớn hơn mà chỉ vừa vặn trong bộ nhớ GPU, ví dụ như các mô hình LLM mới nhất? Chúng ta có thể dùng phương pháp feature-based hoặc Finetuning I. Nhưng nếu muốn đạt được chất lượng mô hình tương tự như Finetuning II thì sao?
Các nhà nghiên cứu đã phát triển một số kỹ thuật để finetuning các LLM với hiệu suất mô hình cao nhưng chỉ cần training một số lượng nhỏ trọng số. Những phương pháp này thường được gọi là các kỹ thuật finetuning hiệu quả về tham số (Parameter-Efficient Finetuning Techniques - PEFT). Một số kỹ thuật PEFT được tóm tắt trong hình dưới đây.
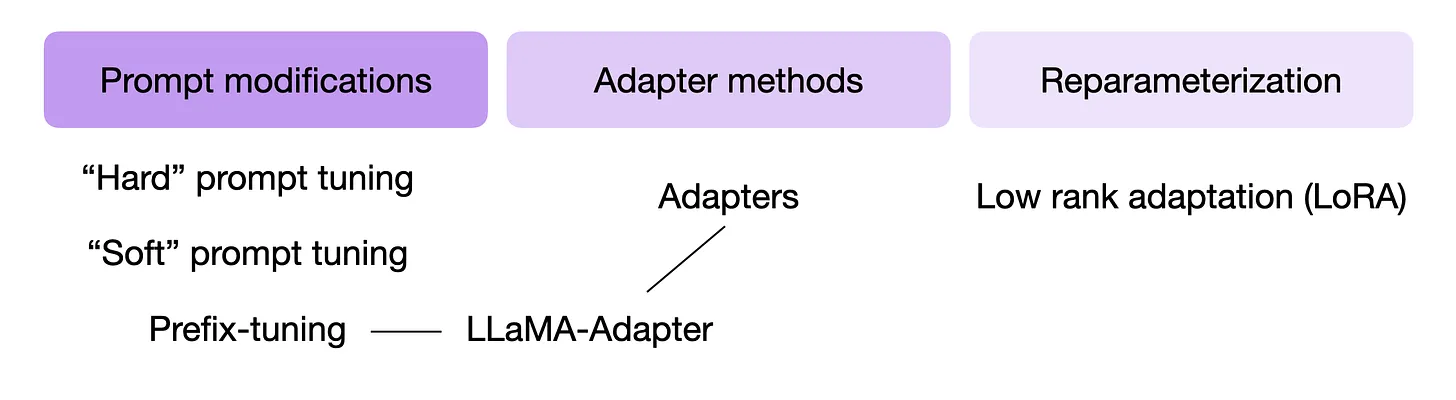
Vậy các kỹ thuật này hoạt động như thế nào? Nói một cách ngắn gọn, tất cả các kỹ thuật này đều sử dụng một số lượng nhỏ các tham số bổ sung để finetuning (khác với việc finetuning tất cả các layers như đã làm ở phương pháp Finetuning II ở trên). Theo một cách nào đó, Finetuning I (chỉ finetuning layer cuối) cũng có thể được coi là một kỹ thuật Parameter-Efficient Finetuning. Tuy nhiên, các kỹ thuật như prefix tuning, adapters, và low-rank adaptation, tất cả đều “thay đổi” nhiều layers, thường đạt được hiệu suất dự đoán tốt hơn (với chi phí thấp).
Reinforcement Learning with Human Feedback
Trong Reinforcement Learning with Human Feedback (RLHF), một mô hình pretrained được finetuning sử dụng kết hợp giữa học giám sát (supervised learning) và học tăng cường (reinforcement learning). Quy trình sẽ như sau:
-
Thu thập dữ liệu minh họa và training mô hình supervised policy:
- Một prompt được lấy mẫu từ tập dữ liệu prompt.
- Người gán nhãn (labeler) minh họa hành vi đầu ra mong muốn.
- Dữ liệu này được sử dụng để finetuning GPT-3 với học supervised learning.
-
Thu thập dữ liệu so sánh và training mô hình phần thưởng (reward model):
- Một prompt và nhiều đầu ra mô hình được lấy mẫu.
- Người gán nhãn xếp hạng các đầu ra từ tốt nhất đến tệ nhất.
- Dữ liệu này được sử dụng để training mô hình reward model.
-
Tối ưu hóa policy so với reward model sử dụng học tăng cường:
- Một prompt mới được lấy mẫu từ tập dữ liệu.
- Policy tạo ra 1 output.
- Reward model tính toán phần thưởng cho đầu ra.
- Phần thưởng này được sử dụng để cập nhật policy sử dụng PPO (proximal policy optimization).
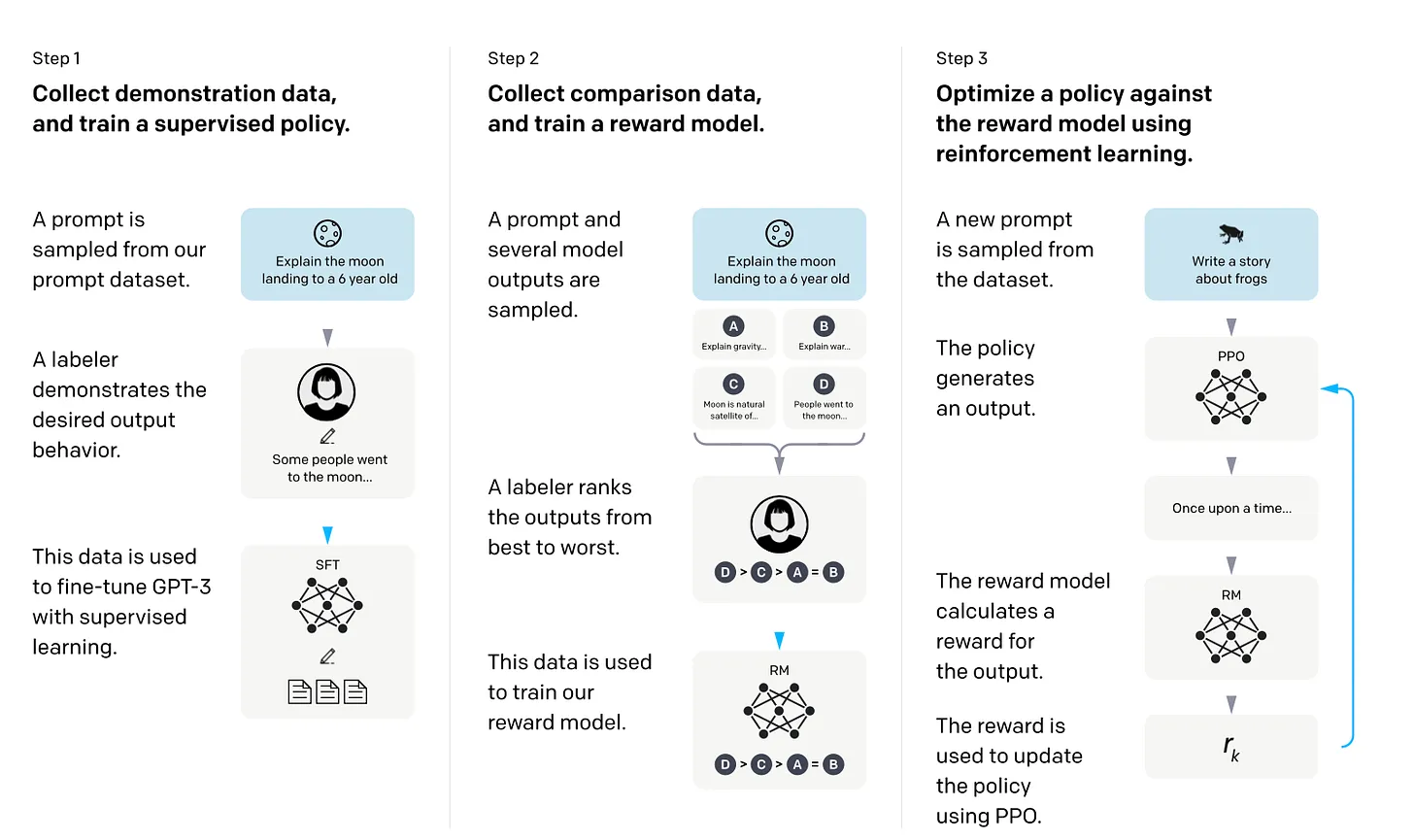
Câu hỏi đặt ra là sử dụng mô hình phần thưởng thay vì training trực tiếp trên phản hồi con người? Lý do là vì việc liên quan đến con người trong quá trình học sẽ tạo ra một điểm nghẽn, bởi chúng ta không thể nhận được phản hồi từ con người theo thời gian thực.
Kết Luận
Việc finetuning tất cả các layers của một LLM đã huấn luyện sẵn vẫn là 1 best practice để đáp ứng với các tác vụ mục tiêu mới, nhưng cũng có nhiều phương pháp thay thế hiệu quả để sử dụng các transformers đã được pretrain:
- Phương pháp feature-based,
- In-context learning,
- Các kỹ thuật finetuning hiệu quả về tham số (PEFT).
Các phương pháp này cho phép ứng dụng LLMs vào các tác vụ mới trong khi giảm thiểu chi phí tính toán và tài nguyên.
Ngoài ra, RLHF là một phương pháp thay thế cho supervised finetuning, có thể cải thiện hiệu suất của mô hình.
All rights reserved
