[LLM 101 - Paper reading] Tìm hiểu Corrective Retrieval Augmented Generation (CRAG)
Giới thiệu
Hãy tưởng tượng bạn đang trong giờ kiểm tra và thầy của bạn cho mở sách  Chúng ta sẽ có 3 chiến lược để làm bài kiểm tra như sau:
Chúng ta sẽ có 3 chiến lược để làm bài kiểm tra như sau:
-
Chiến lược 1: Trả lời nhanh các câu mà bạn đã ôn tập. Đối với những câu mà bạn chưa học, mở sách ra và tham khảo thôi
. Khi này bạn phải nhanh chóng tìm trong sách các kiến thức liên quan đến câu hỏi, tổ chức lại và tóm tắt chúng trong đầu, sau đó viết câu trả lời của bạn ra giấy thi. -
Chiến lược 2: Đối với mỗi câu hỏi mở sách ra tìm luôn. Xác định các phần liên quan, tóm tắt chúng trong đầu, rồi viết câu trả lời của bạn ra giấy thi.
-
Chiến lược 3: Đối với mỗi câu hỏi, tham khảo sách và xác định các phần liên quan. Sau đó, phân loại thông tin thu thập được thành ba nhóm: Đúng, Sai và Mơ hồ. Xử lý từng loại thông tin một cách riêng biệt. Sau đó, dựa trên thông tin đã xử lý này, tổng hợp và tóm tắt trong đầu. Cuối cùng ghi ra câu trả lời.
Chiến lược 1 liên quan đến quy trình tự đánh giá, sửa đổi và tạo ra câu trả lời (self-RAG), trong khi chiến lược 2 chính là quy trình RAG cổ điển.
Cuối cùng, chiến lược 3 được gọi là Corrective Retrieval Augmented Generation (CRAG) mà mình sẽ trình bày trong bài viết này.
Động lực của bài báo
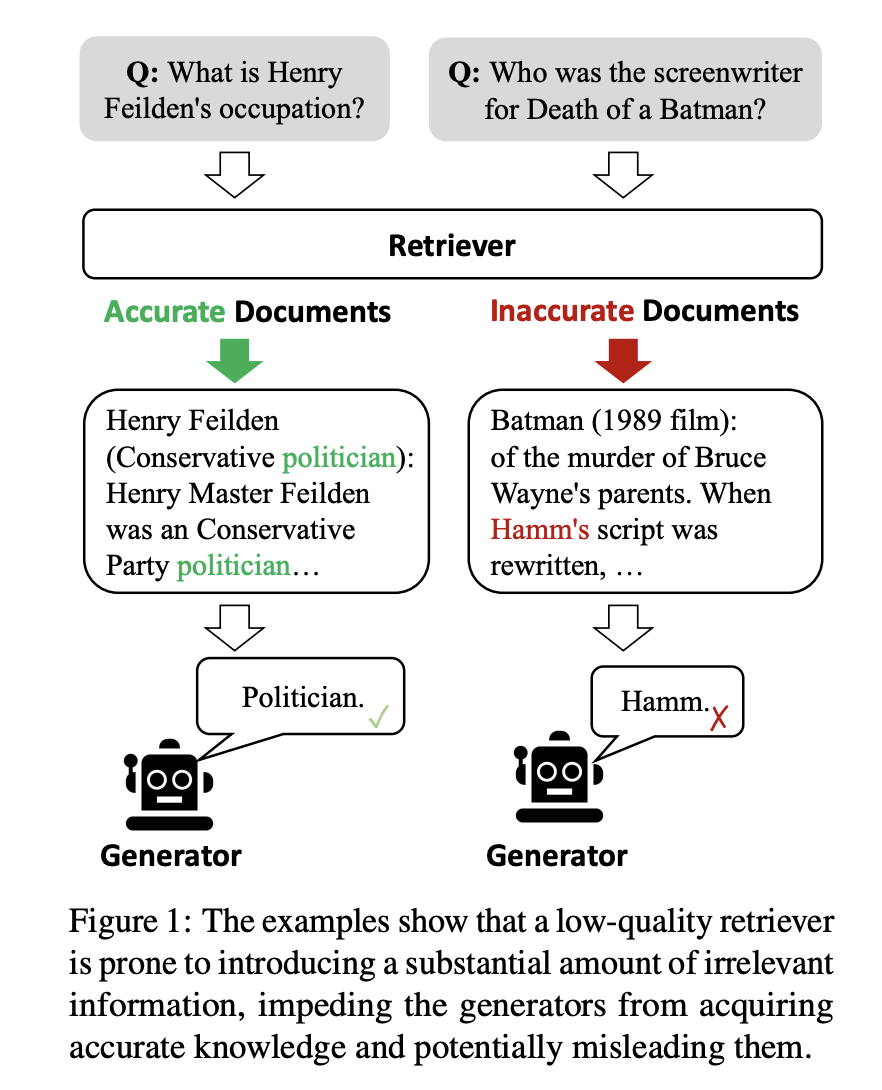
Hình trên cho thấy rằng hầu hết các phương pháp RAG (Retrieval Augmented Generation) truyền thống không xem xét đến tính liên quan của tài liệu với câu hỏi mà chỉ đơn giản là kết hợp các tài liệu đã tìm kiếm. Điều này có thể đưa vào thông tin không liên quan, làm cản trở mô hình từ việc thu thập thông tin chính xác và có thể dẫn đến hiện tượng hallucination.
Ngoài ra, hầu hết các phương pháp RAG truyền thống lấy toàn bộ tài liệu đã tìm kiếm làm đầu vào. Tuy nhiên, một phần đáng kể của văn bản trong những tài liệu này thường không cần thiết cho quá trình đưa ra câu trả lời (generation).
Ý tưởng chính của CRAG
CRAG (Corrective Retrieval Augmented Generation) được thiết kế với một bộ đánh giá tìm kiếm gọn nhẹ để đánh giá chất lượng tổng thể của các tài liệu được truy xuất cho các truy vấn cụ thể. Nó cũng sử dụng web search như một công cụ bổ sung để cải thiện kết quả truy xuất.
CRAG có thể tích hợp một cách linh hoạt, cho phép kết nối liền mạch với nhiều phương pháp dựa trên RAG. Kiến trúc tổng thể được mô tả trong hình dưới.
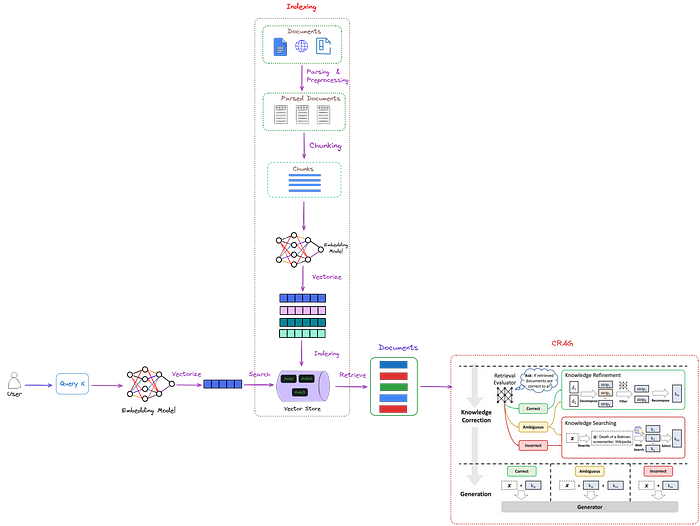
Hình trên minh họa vị trí của CRAG (khung đứt đoạn màu đỏ) trong RAG. Một bộ đánh giá tìm kiếm (Retrieval Evaluator) được thiết kế để đánh giá mức độ liên quan của các tài liệu truy xuất đối với user query. Nó cũng ước tính một mức độ tin cậy, có thể kích hoạt các hành động truy xuất kiến thức khác nhau, cụ thể là {Đúng, Sai, Mơ hồ}. Tại đây, "x" đại diện cho truy vấn.
CRAG cải tiến RAG truyền thống bằng cách sử dụng một bộ đánh giá tìm kiếm để đánh giá mối quan hệ giữa các tài liệu được truy xuất và truy vấn.
Có 3 kết quả đánh giá có thể xảy ra:
- Nếu đúng, điều này có nghĩa là các tài liệu được truy xuất chứa nội dung cần thiết theo yêu cầu của truy vấn, sau đó sử dụng một thuật toán tinh chỉnh kiến thức để viết lại các tài liệu được truy xuất.
- Nếu các tài liệu truy xuất là sai, điều này có nghĩa là truy vấn và các tài liệu truy xuất không liên quan. Do đó, chúng ta không thể gửi tài liệu đến LLM (Large Language Model). Trong CRAG, một công cụ tìm kiếm web được sử dụng để truy xuất kiến thức bên ngoài.
- Đối với các trường hợp mơ hồ, điều này có nghĩa là các tài liệu truy xuất có thể gần nhưng không đủ để cung cấp một câu trả lời. Trong trường hợp này, thông tin bổ sung cần được lấy thông qua tìm kiếm web. Vì vậy, cả thuật toán tinh chỉnh kiến thức và công cụ tìm kiếm được sử dụng.
Cuối cùng, thông tin đã được xử lý được chuyển tiếp đến LLM để tạo phản hồi. Hình dưới mô tả chính xác thuật toán mà chúng ta sẽ sử dụng.

Lưu ý rằng web search không sử dụng trực tiếp truy vấn đầu vào của người dùng để tìm kiếm. Thay vào đó, nó xây dựng một prompt và truyền vào GPT-3.5 Turbo theo few-shot để thu được truy vấn tìm kiếm.
Okay! Đó là tổng quan về phương pháp Bây giờ, chúng ta sẽ tìm hiểu hai thành phần chính của CRAG: bộ đánh giá tìm kiếm và thuật toán tinh chỉnh kiến thức.
Như được minh họa trong dưới bộ đánh giá tìm kiếm có ảnh hưởng đáng kể đến kết quả của các quy trình tiếp theo và là yếu tố quan trọng trong việc xác định hiệu suất tổng thể của hệ thống.
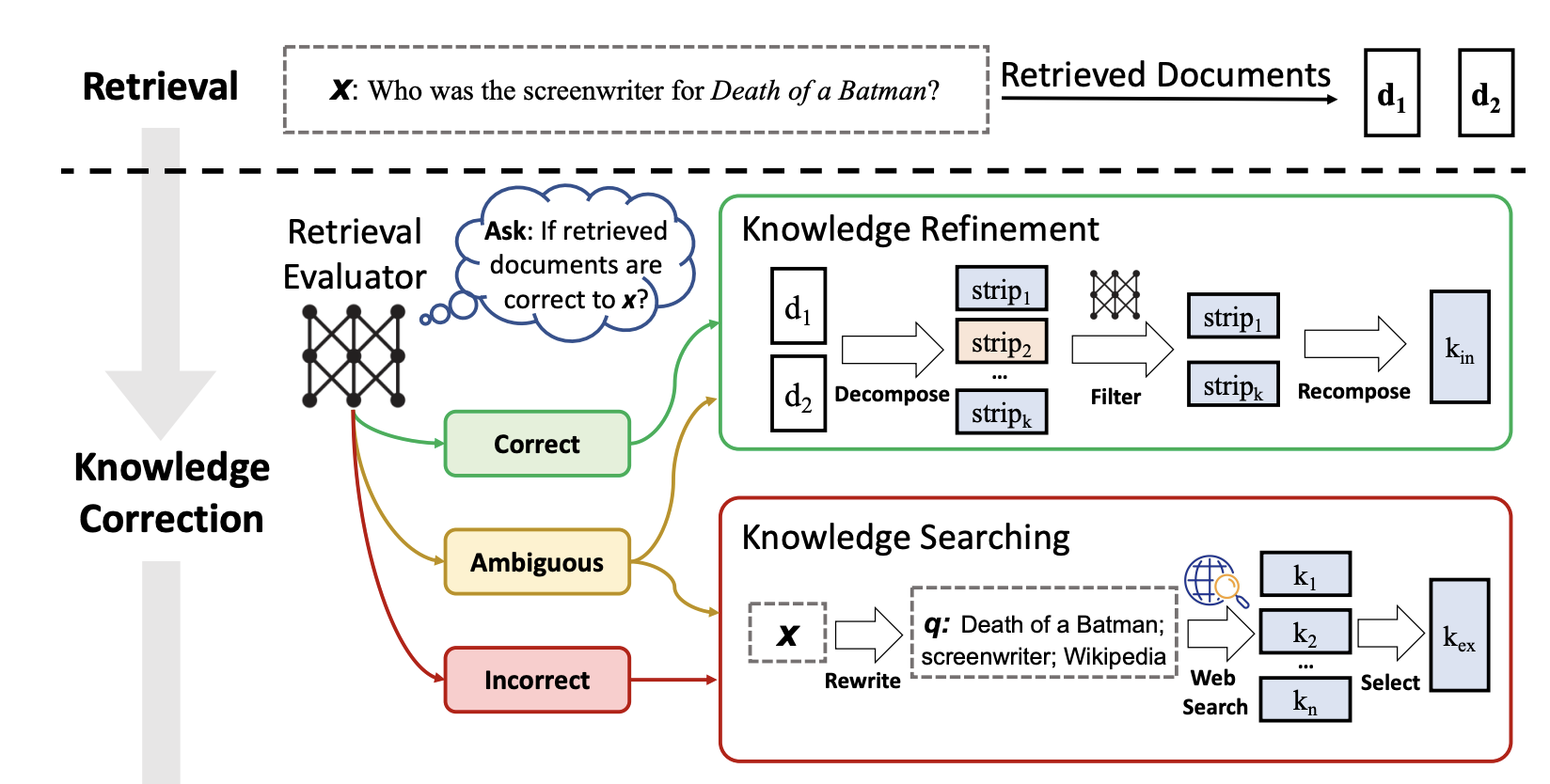
CRAG sử dụng một mô hình T5-large làm bộ đánh giá tìm kiếm. Đối với mỗi truy vấn, thông thường 10 tài liệu được truy xuất. Sau đó, truy vấn được nối tiếp với mỗi tài liệu một cách riêng biệt để làm đầu vào dự đoán mức độ liên quan của chúng. Trong quá trình tinh chỉnh, gán nhãn 1 cho các mẫu tích cực và -1 cho các mẫu tiêu cực. Trong quá trình suy luận, bộ đánh giá gán điểm liên quan cho mỗi tài liệu, dao động từ -1 đến 1.
Những điểm số này sẽ được phân loại thành 3 mức dựa trên các ngưỡng. Trong CRAG, các thiết lập ngưỡng có thể thay đổi tùy thuộc vào dữ liệu thí nghiệm:
Hai ngưỡng tin cậy để kích hoạt một trong ba hành động được thiết lập dựa trên kinh nghiệm. Cụ thể, chúng được thiết lập là (0.59, -0.99) trong PopQA, (0.5, -0.91) trong PubQA và ArcChallenge, và (0.95, -0.91) trong Biography.
CRAG đã phát triển một phương pháp "phân rã rồi tái cấu trúc" (decompose-then-recompose) để trích xuất kiến thức từ các tài liệu có liên quan. Quy trình này nhằm mục đích rút ra những kiến thức quan trọng nhất từ tài liệu.
Đầu tiên, các quy tắc heuristic được áp dụng để phân tách từng tài liệu thành các dải kiến thức, với mục tiêu thu được kết quả chi tiết. Nếu tài liệu được truy xuất chỉ gồm một hoặc hai câu, nó được xem là một đơn vị độc lập. Nếu không, tài liệu được chia thành các đơn vị nhỏ hơn, thường bao gồm vài câu, tùy thuộc vào tổng độ dài của tài liệu. Mỗi đơn vị được kỳ vọng chứa một phần thông tin độc lập.
Tiếp theo, bộ đánh giá tìm kiếm được sử dụng để tính toán similarity score cho mỗi dải kiến thức. Những dải có điểm liên quan thấp sẽ được lọc bỏ. Các dải kiến thức còn lại có liên quan sau đó được tái tổ hợp nhằm hình thành kiến thức nội bộ.
Ta có thể thấy sự khác biệt giữa CRAG và self-RAG như sau:
- Từ góc độ quy trình, self-RAG có thể cho phản hồi trực tiếp sử dụng LLM mà không cần truy xuất (retrieve), trong khi CRAG phải thực hiện truy xuất trước khi thêm một lớp đánh giá.
- Từ góc độ cấu trúc, self-RAG phức tạp hơn CRAG, nó đòi hỏi quy trình training phức tạp hơn, nhiều hoạt động label generation và đánh giá trong giai đoạn generate, làm tăng chi phí inference. Do đó, CRAG nhẹ hơn so với self-RAG.
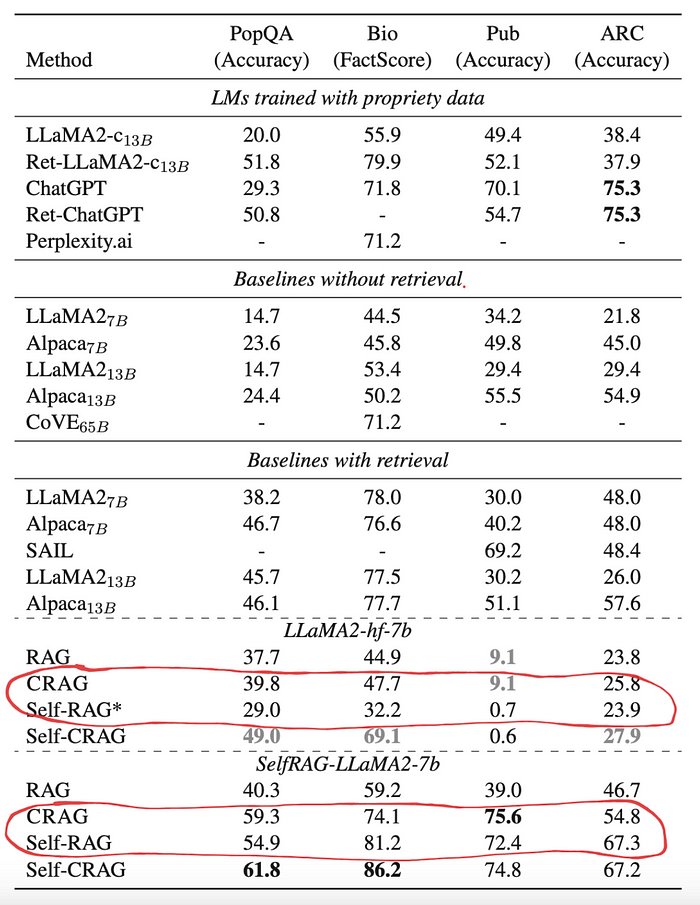
- Về hiệu suất, như được minh họa trong hình dưới, CRAG thường vượt trội hơn self-RAG trong hầu hết các trường hợp.
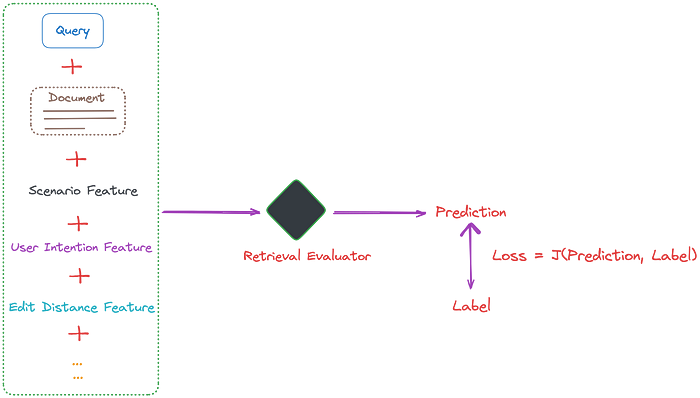
Cải tiến Bộ đánh giá truy xuất:
- Bộ đánh giá truy xuất có thể được xem như một mô hình phân loại điểm số. Mô hình này được sử dụng để xác định mức độ liên quan của truy vấn và tài liệu, tương tự như mô hình reranking trong RAG.
- Các mô hình đánh giá liên quan này có thể được cải tiến bằng cách tích hợp thêm nhiều đặc điểm phù hợp với các tình huống thực tế.
- Bằng cách thêm các scenario feature vào dữ liệu đào tạo của bộ đánh giá truy xuất, nó có thể đánh giá tốt hơn mức độ liên quan của các tài liệu được truy xuất. Các đặc điểm khác, như ý định người dùng (user intention) và khoảng cách chỉnh sửa (edit distance) cũng có thể được tích hợp.
Điểm số và Ngưỡng (threshold) của Bộ đánh giá truy xuất:
- Ngưỡng là khác nhau cho các loại dữ liệu khác nhau. Ngoài ra, ta thấy rằng các ngưỡng cho các trường hợp mơ hồ và không chính xác thường xung quanh -0.9, cho thấy hầu hết kiến thức được truy xuất liên quan đến truy vấn. Có thể không nên loại bỏ hoàn toàn kiến thức này và chỉ dựa vào tìm kiếm web.
- Trong các ứng dụng thực tế, chúng ta cần điều chỉnh các tham số trên theo bài toán cụ thể và nhu cầu thực tế.
Tổng kết
Bài viết này bắt đầu bằng một ví dụ trực quan và trình bày quy trình cơ bản của CRAG. Tóm lại, CRAG hoạt động như một plugin plug-and-play, có thể nâng cao đáng kể hiệu suất của RAG. Nó cung cấp một giải pháp khá gọn nhẹ để cải thiện RAG.
Tài liệu tham khảo
All rights reserved
