[LLM 101 - Paper reading] MemGPT: Towards LLMs as Operating Systems
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Hãy tưởng tượng bạn đang cố gắng đọc một cuốn sách rất dài mà chỉ có thể nhớ được một số trang gần nhất bạn vừa đọc. Điều này giống như vấn đề của các mô hình ngôn ngữ lớn (LLM), các mô hình này khó có thể "nhớ" hoặc xử lý thông tin từ những cuộc trò chuyện hoặc tài liệu dài vì chúng chỉ có khả năng xem xét một lượng thông tin giới hạn tại một thời điểm. Đây chính là vấn đề về độ dài context trong LLM.
Nếu tăng độ dài context một cách trực tiếp thì sẽ làm tăng độ phức tạp tính toán và bộ nhớ theo cấp số nhân do kiến trúc self-attention của Transformer. Các nhà nghiên cứu đang cố gắng tìm ra cách để giải quyết vấn đề này, nhưng ngay cả khi họ tìm ra cách để các mô hình này "nhớ" được nhiều hơn mà không tốn quá nhiều thời gian và tiền bạc, thì việc sử dụng hiệu quả thông tin đó vẫn là một thách thức.
Để giải quyết vấn đề này, nhóm tác giả đề xuất MemGPT, giống như một kỹ thuật cho phép "cuốn sách" (hay dữ liệu) của chúng ta di chuyển giữa bàn làm việc và một kệ sách lớn (bộ nhớ ngoài), từ đó ta có thể tiếp cận nhiều thông tin hơn mà không cần phải giữ chúng trên bàn cùng một lúc.
Cách làm này bắt nguồn từ ý tưởng về bộ nhớ ảo mà máy tính sử dụng để xử lý dữ liệu lớn hơn bộ nhớ có sẵn của nó. MemGPT cho phép LLM đọc và ghi thông tin vào một nơi lưu trữ ngoài, giống như lấy sách từ kệ sách và sau đó đặt chúng trở lại khi không cần nữa. Điều này giúp LLM xử lý thông tin dễ dàng hơn mà không bị giới hạn bởi "kích thước bàn" của chúng  .
.
MemGPT hoạt động giống như một hệ điều hành (OS) dành cho LLM, cho phép LLM quản lý nội dung trong context của mình - tương tự như cách quản lý bộ nhớ vật lý trong máy tính. Nó giúp LLM truy cập dữ liệu lịch sử cần thiết bị thiếu trong ngữ cảnh hiện tại và loại bỏ dữ liệu ít (hoặc không) liên quan ra khỏi context, chuyển nó vào hệ thống lưu trữ bên ngoài.
Nhóm tác giả đã thử nghiệm MemGPT trong hai bài toán lớn của LLM: Phân tích tài liệu dài và duy trì cuộc hội thoại có ý nghĩa. Kết quả cho thấy MemGPT không chỉ giải quyết được vấn đề giới hạn về context mà còn cải thiện đáng kể hiệu suất so với các phương pháp trước đây.
Phương pháp
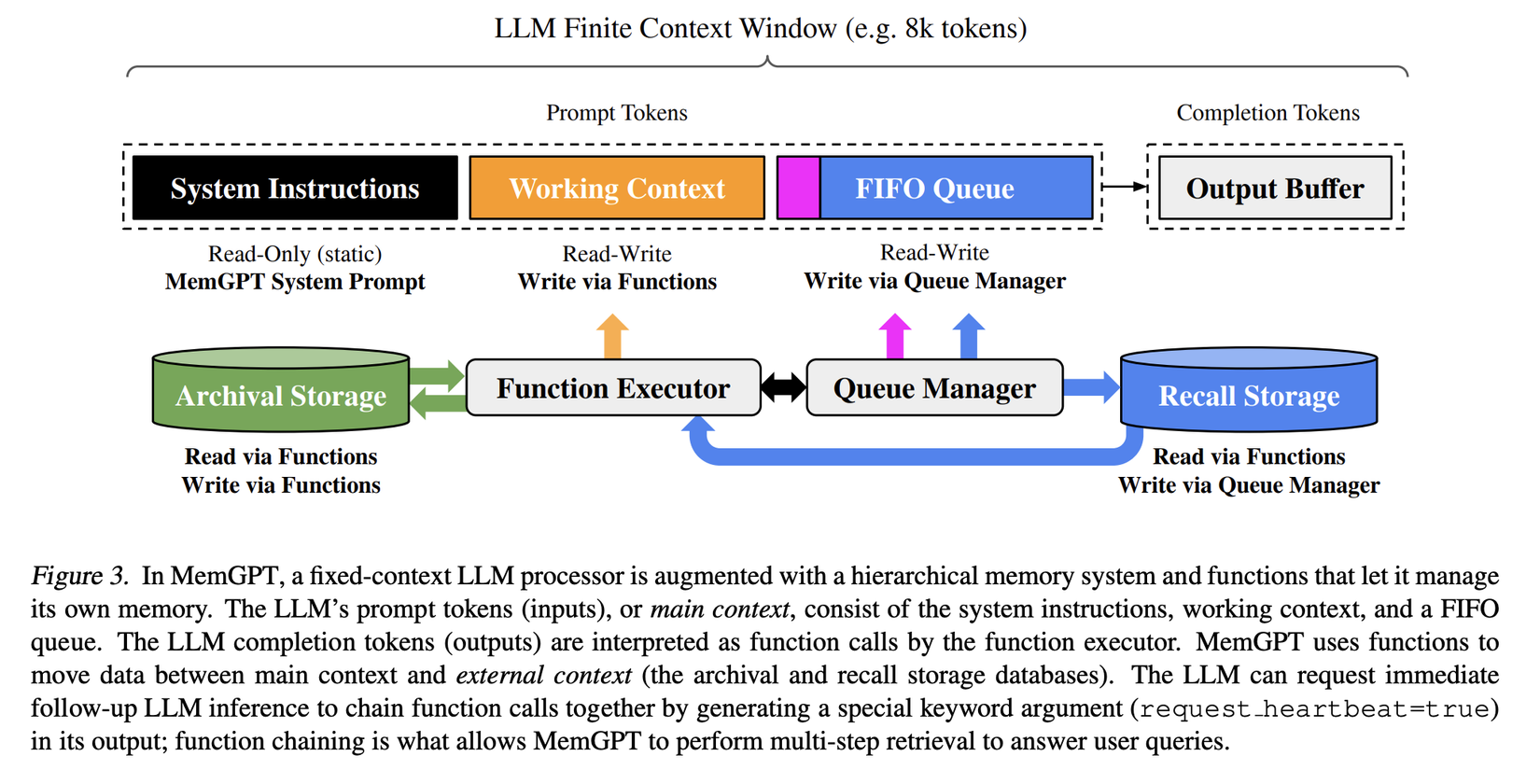
Trong kiến trúc của MemGPT có 2 thành phần chính là: Main context và External context. "Main context" chứa các token prompt của LLM, và mọi thứ trong đó được coi là in context, có thể truy cập bởi LLM processor khi thực hiện inference. "External context" bao gồm thông tin nằm ngoài window context cố định của LLM. Dữ liệu out-of-context cần được chuyển một cách cụ thể vào "main context" để có thể được xử lý bởi LLM khi thực hiện inference. MemGPT cho phép bộ xử lý LLM quản lý bộ nhớ của mình thông qua các cuộc gọi hàm mà không cần sự can thiệp của người dùng, ví dụ như: thêm, thay đổi hoặc tìm kiếm thông tin liên quan để đưa vào context hiện tại.
Main context (prompt tokens)
Trong MemGPT, các prompt token được chia thành 3 phần liên tục: "system instructions," "working context," và "FIFO Queue".
System instructions là phần chỉ đọc (không được sửa phần này) và chứa thông tin sau:
- Control flow của MemGPT
- Cách sử dụng các cấp bộ nhớ khác nhau
- Hướng dẫn cách dùng các functions của MemGPT, ví dụ như cách truy xuất dữ liệu out-of-context
Working context là một khối văn bản không cấu trúc, có kích thước cố định và chỉ có thể được viết thông qua các lần gọi hàm của MemGPT. Trong các tình huống hội thoại, "working context" dùng để lưu trữ các thông tin quan trọng, sở thích, và các thông tin khác về người dùng và nhân vật, từ đó giúp agent trò chuyện một cách mạch lạc với người dùng.
FIFO Queue có nhiệm vụ lưu trữ lịch sử tin nhắn, bao gồm tin nhắn giữa agent và người dùng, cũng như tin nhắn hệ thống (ví dụ, cảnh báo bộ nhớ) và input, output của các lần gọi hàm. Vị trí đầu tiên trong "FIFO Queue" chứa một tin nhắn hệ thống với tóm tắt đệ quy (recursive summary) của các tin nhắn đã bị loại bỏ khỏi hàng đợi.
Queue Manager
Queue manager có nhiệm vụ quản lý tin nhắn trong recall storage và FIFO queue. Khi hệ thống nhận một tin nhắn mới, queue manager thêm tin nhắn vào FIFO queue, concat các prompt token và kích hoạt inference của LLM để tạo ra output của LLM (completion tokens).
Queue manager ghi cả tin nhắn đến và output được tạo bởi LLM vào recall storage (cơ sở dữ liệu tin nhắn của MemGPT). Khi tin nhắn từ recall storage được query thông qua một cuộc gọi hàm MemGPT, queue manager thêm chúng vào cuối queue để tái chèn chúng vào context window của LLM.
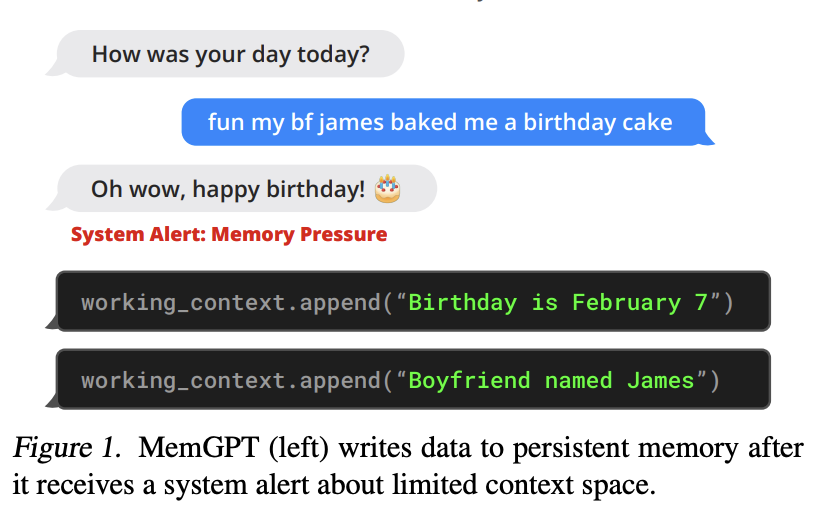
Queue manager cũng chịu trách nhiệm kiểm soát tràn context thông qua một chính sách loại bỏ từ queue (queue eviction policy). Khi số lượng prompt token vượt qua một ngưỡng được set trước của window context LLM (ví dụ, 70% window context), queue manager chèn một tin nhắn hệ thống vào queue, cảnh báo LLM về việc sắp xảy ra loại bỏ queue (cảnh báo áp lực bộ nhớ - memory pressure) để LLM có thể gọi các hàm MemGPT để lưu trữ thông tin quan trọng từ FIFO queue vào working context hoặc archival storage (cơ sở dữ liệu đọc/ghi lưu trữ các đối tượng văn bản có độ dài tùy ý).
Khi số lượng prompt token vượt qua 'số lượng token xóa' (ví dụ, 100% window context), queue manager làm sạch queue để giải phóng không gian trong window context: loại bỏ một số lượng cụ thể tin nhắn (ví dụ, 50% window context), tạo ra một tóm tắt đệ quy mới từ tóm tắt hiện có và các tin nhắn đã loại bỏ. Sau khi queue được "làm sạch", các tin nhắn loại bỏ không còn trong context và không thể xem trực tiếp bởi LLM. Tuy nhiên, các tin nhắn này được lưu trữ vĩnh viễn trong recall storage và có thể đọc qua các lần gọi hàm MemGPT.
Function executor (handling of completion tokens)
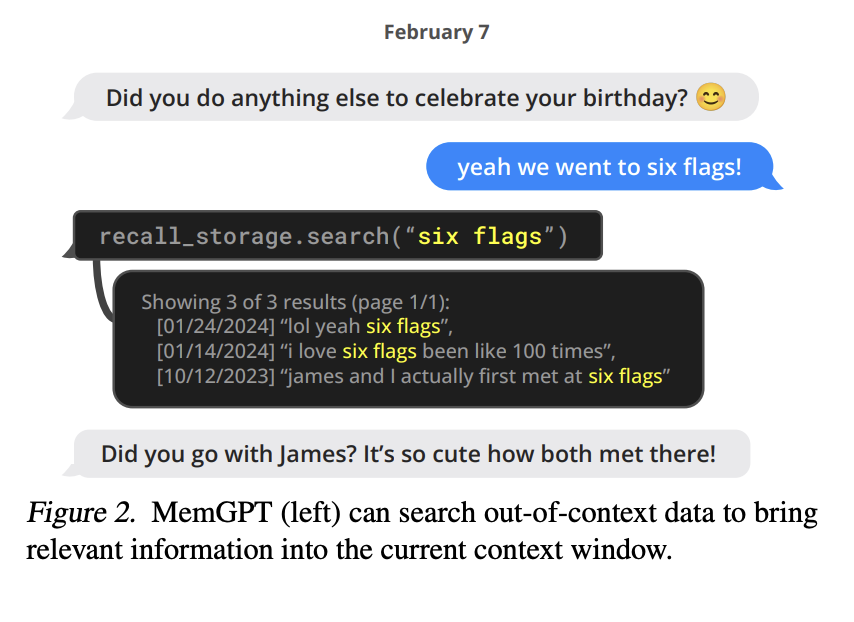
MemGPT điều phối việc di chuyển dữ liệu giữa main context và external context thông qua các cuộc gọi hàm được tạo bởi bộ xử lý LLM. MemGPT tự động cập nhật và tìm kiếm thông tin trong bộ nhớ của mình dựa trên context hiện tại (xem hình dưới).

Ví dụ, nếu lịch sử cuộc trò chuyện trở nên quá dài, MemGPT có thể quyết định loại bỏ một số thông tin ra khỏi main context hoặc thêm thông tin mới vào để giữ cho cuộc trò chuyện trở nên rõ ràng và đúng đắn hơn, dựa trên những gì nó hiểu về đoạn hội thoại hiện tại. Mọi hành động này đều dựa trên các lệnh mà bộ xử lý LLM tạo ra, giúp MemGPT tự chủ trong việc chỉnh sửa và truy xuất bộ nhớ của mình (xem hình dưới).
Việc chỉnh sửa và truy xuất thông tin được thực hiện bằng cách cung cấp hướng dẫn cụ thể trong các system prompt, cụ thể là hướng dẫn LLM cách tương tác với hệ thống bộ nhớ MemGPT. Các hướng dẫn này bao gồm 2 thành phần chính:
- Một mô tả chi tiết về hệ thống phân cấp bộ nhớ và công dụng của chúng
- Một lược đồ chức năng (được mô tả bằng ngôn ngữ tự nhiên) mà hệ thống có thể gọi để truy cập hoặc sửa đổi bộ nhớ của mình.
Trong mỗi chu kỳ inference, bộ xử lý LLM lấy main context làm input (dạng string) và tạo ra một output. Output này được MemGPT phân tích để đảm bảo tính chính xác, và nếu bộ phân tích xác thực các tham số hàm thì hàm được thực thi.
Sau khi một function được MemGPT thực hiện, nếu có lỗi runtime - chẳng hạn, khi cố gắng thêm thông tin vào main context khi nó đã đầy - lỗi đó được báo lại cho bộ xử lý. Điều này tạo nên một vòng phản hồi, giúp MemGPT học hỏi từ các hành động của mình và điều chỉnh hành vi của mình cho phù hợp. Việc nhận biết về giới hạn của context là rất quan trọng để làm cho cơ chế tự chỉnh sửa này hoạt động hiệu quả. Vì vậy, MemGPT sẽ cảnh báo bộ xử lý về các giới hạn token để hướng dẫn quyết định quản lý bộ nhớ của nó. Hơn nữa, cơ chế truy xuất bộ nhớ của MemGPT được thiết kế để ý thức về các ràng buộc token và sử dụng phân trang để ngăn chặn việc các cuộc gọi truy xuất làm tràn context window.
Control flow và function chaining
Trong MemGPT, các event trigger inference LLM như:
- Thông báo tin nhắn từ người dùng (trong ứng dụng chat)
- Cảnh báo từ hệ thống (như cảnh báo về dung lượng main context)
- Tương tác từ người dùng (như thông báo người dùng vừa đăng nhập hoặc hoàn thành tải lên tài liệu)
- Event được thiết lập định kỳ (ví dụ như MemGPT tự động hoạt động mà không cần sự can thiệp của người dùng)
MemGPT sử dụng một parser để xử lý các event này, chuyển chúng thành tin nhắn văn bản thuần túy có thể được thêm vào main context và cuối cùng là input cho bộ xử lý LLM.
Nhiều tác vụ thực tế đòi hỏi việc gọi nhiều function một cách tuần tự, chẳng hạn như điều hướng qua nhiều kết quả từ một truy vấn duy nhất hoặc tổng hợp dữ liệu từ các tài liệu khác nhau trong main context từ các truy vấn riêng biệt. Chaining function cho phép MemGPT thực hiện nhiều cuộc gọi function một cách liên tiếp trước khi trả lại quyền kiểm soát cho người dùng.
Trong MemGPT, function có thể được gọi với một flag đặc biệt yêu cầu quyền kiểm soát được trả lại ngay lập tức cho bộ xử lý sau khi function yêu cầu hoàn thành. Nếu flag được set bằng True, MemGPT sẽ thêm output của function vào main context và tiếp tục hoạt động. Nếu flag bằng False, MemGPT sẽ không chạy bộ xử lý LLM cho đến khi event tiếp theo bên ngoài được trigger (như tin nhắn đến từ người dùng hoặc một event định kì nào đó).
Kết luận
Qua bài báo, các bạn đã có thêm một ý tưởng kiểm soát nội dung context sao cho hiệu quả, từ đó LLM Agent có thể hiểu người dùng hơn và đưa ra những phản hồi chính xác và mạch lạc. Chi tiết hơn, các bạn có thể tham khảo code cài đặt cho ý tưởng bài báo này tại đây https://github.com/cpacker/MemGPT/tree/main/memgpt
Tài liệu tham khảo
All rights reserved
