Linear Regession with One Variable
Bài đăng này đã không được cập nhật trong 7 năm
Linear Regession (Hồi quy tuyến tính) là một trong những thuật toán Machine Learning cơ bản nhất. Đây là một thuật toán Supervised Learning, đôi khi nó còn được gọi là Linear Fitting hoặc Linear Least Square.
Model Representation
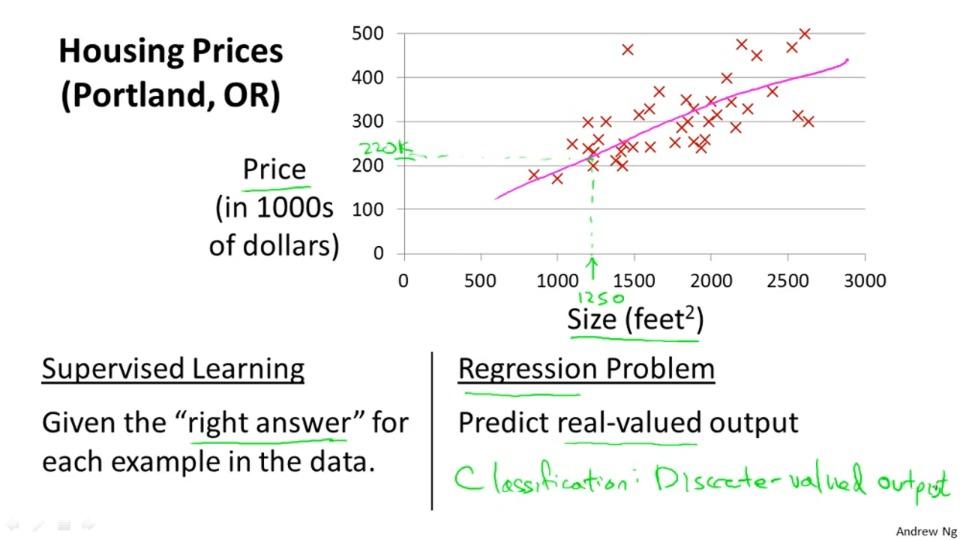
Trong bài này, chúng ta sẽ xét mô hình cơ bản của hồi quy tuyến tính. Cho một căn nhà với bộ dữ liệu training gồm có diện tích và giá trị của căn nhà đấy. Chúng ta sẽ cần dự đoán với một căn nhà có diện tích bất kì thì giá căn nhà đó sẽ là bao nhiêu.
| Diện tích | Giá trị |
|---|---|
| 2104 | 460 |
| 1534 | 315 |
| 1416 | 232 |
| 852 | 178 |
| ... | ... |
Ở đây chúng ta sẽ có:
- là số lượng training example.
- là dữ liệu đầu vào hay đặc điểm, tính chất của căn nhà.
- là dữ liệu đầu ra hay đặc điểm tính chất mà ta cần (giá trị căn nhà).
Để thống nhất ký hiệu về sau, chúng ta sử dụng là biến nhập vào (diện tích căn nhà trong ví dụ này), là biến output (giá trị căn nhà). Với mỗi cặp là một cặp "training example". Lượng dữ liệu data chúng ta dùng để train là một list training examples. là một training set. là không gian vecto trong ví dụ này, là không gian vecto output. Trong ví dụ này
Để thể hiện rõ Supervised Learning, mục tiêu chúng ta là khi được cho bộ training set, tạo một hàm để dự đoán giá trị của . Thuật toán được thể hiện như sau:
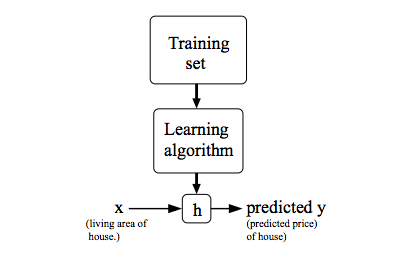
Khi đầu ra là một giá trị liên tục, như diện tích ngôi nhà, chúng ta gọi bài toán đó là hồi quy. Khi đầu ra chỉ nhận một vài giá trị rời rạc (ví dụ khi được cho diện tích một căn nhà hoặc căn hộ chung cư, ta sẽ cần dự đoán xem là nhà riêng hay chung cư) được gọi là bài toán phân loại.
Cost Function
Cost Function hay còn được gọi là Loss Function, là hàm chi phí của hàm . Hàm là một hàm tuyến tính theo , dùng để dự đoán giá trị đầu ra : .
Giá trị dự đoán sẽ có thể có sai số, ta biểu diễn: . Ở đây, là giá trị thực, là giá trị dự đoán.
Mục tiêu của ta là tìm sao cho tổng giá trị với là gần nhất. Ta sẽ có hàm chi phí như sau:
-
Câu hỏi thứ nhất là tại sao lại là mà không phải . Lý do là hàm trị tuyệt đối thì không có đạo hàm ở

-
Câu hỏi thứ hai là giá trị ở đâu ra? Giá trị là để thuận tiện cho việc tính toán, khi đạo hàm bình phương thì sẽ mất
Gradient Descent
Giờ chúng ta đã có hàm ước tính và cách để đánh giá độ chính xác của nó với bộ data được nhận. Công việc tiếp theo là tìm các tham số trong hàm đó. Vì vậy, chúng ta cần đến Gradient Descent.
Mô hình chung
Tưởng tượng rằng chúng ta biểu diễn hàm cần tìm "based on its fields and " (Đoạn này không biết diễn ta bằng tiếng việt như nào  nôm na là dựa trên mặt phẳng tạo bởi và khi chúng chạy trên ).
nôm na là dựa trên mặt phẳng tạo bởi và khi chúng chạy trên ).
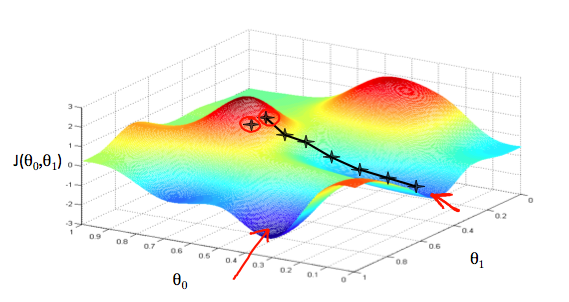
Chúng ta đạt được mục tiêu khi hàm chi phí đạt đến giá trị nhỏ nhất.
Cách thực hiện là đạo hàm hàm chi phí như ở toán cao cấp để tìm cực trị. Ở đây, chúng ta tiếp cận việc tìm nghiệm của đạo hàm theo một hướng mới. Thuật toán Gradient Descent sẽ như sau:
repeat until convergence:
where and
Với nhiều ta phải update đồng thời chúng. Trình tự đúng như sau:

với là "Learning Rate". Learning Rate còn được gọi là Step Size, là một tham số để ta kiểm soát việc xác định giá trị tiếp theo của . Hầu hết lập trình viên dành thời gian để tinh chỉnh Learning Rate. Nếu Learning Rate quá nhỏ, thuật toán sẽ tốn nhiều thời gian, nếu Learning Rate quá lớn, nó có thể sẽ bỏ qua điểm cực trị. Quan sát hình minh họa sau đây:
- Learning Rate quá nhỏ:

- Learning Rate quá lớn:

- Learning Rate hợp lý:

Tham khảo Machine Learning Crash Course
Với việc chọn Learning Rate hợp lý, ta sẽ dùng thuật toán để tìm được điểm cực tiểu:
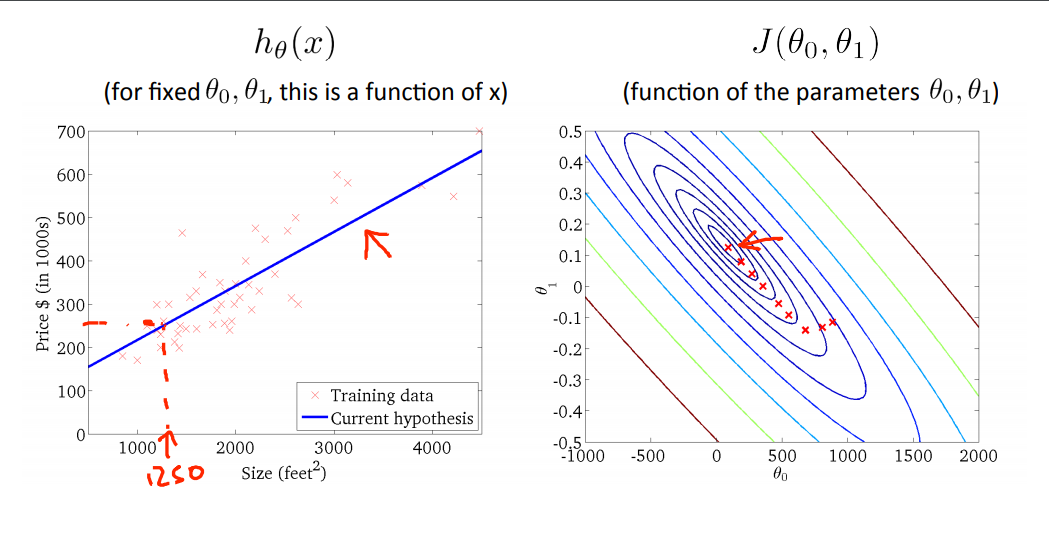
Cụ thể hàm chi phí (Cost Function) của ví dụ trên
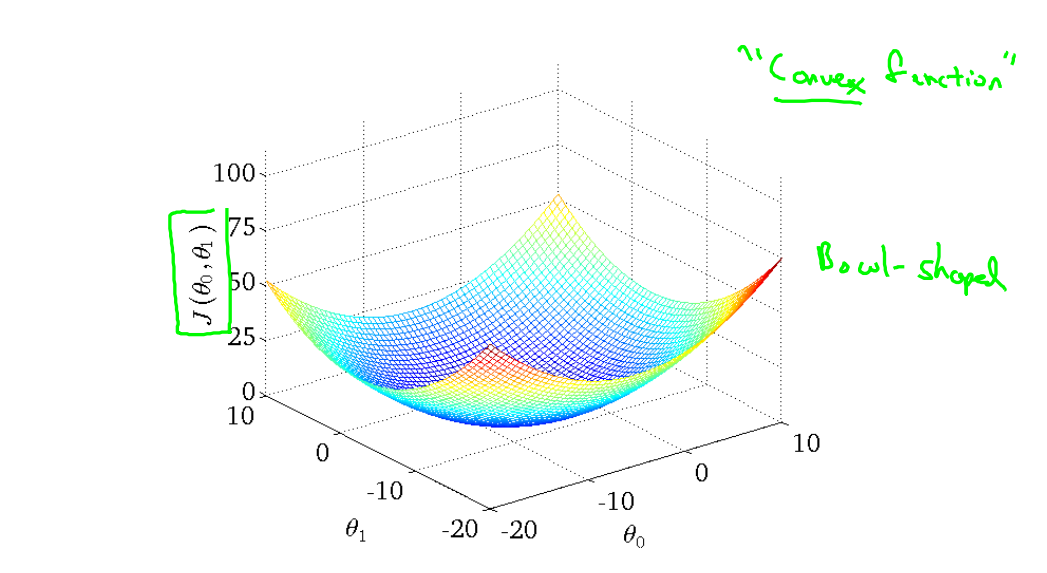
Nhìn vào hàm chi phí, ta thấy nó là tổng của các bình phương của một tổng nên không thể âm được, giá trị nhỏ nhất sẽ gần nhất.
Gradient Descent Algorithm
repeat until convergence:
update and simultaneously
Sau khi tìm được và tối ưu, ta tìm được hàm là một đường tuyến tính để dự đoán giá trị của
(còn tiếp)
Bài viết là quá trình ghi lại khi tham gia khóa học Machine Learning của thầy Andrew Ng và tham khảo tài liệu từ blog Machine Learning cơ bản.
All rights reserved
