Lập Lịch Hằng Ngày Cho Tác Vụ Đẩy Dữ Liệu Từ MongoDB sang Hadoop (HDFS) Với Apache NiFi (Scheduling fetch data same day from MongoDB to Hadoop in Apache NiFi)
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu về Apache NiFi
Apache NiFi là gì ?
Apache NiFi là công cụ mã nguồn mở được xây dựng để tự động hóa luồng dữ liệu giữa các hệ thống.
Tính năng chính:
- Giao diện người dùng dựa trên trình duyệt (Browser-based user interface)
- Theo dõi xuất xứ dữ liệu (Data provenance tracking)
- Cấu hình phong phú (Extensive configuration)
- Thiết kế mở rộng (Extensible design)
- Giao tiếp an toàn (Secure communication)
Kiến trúc NiFi
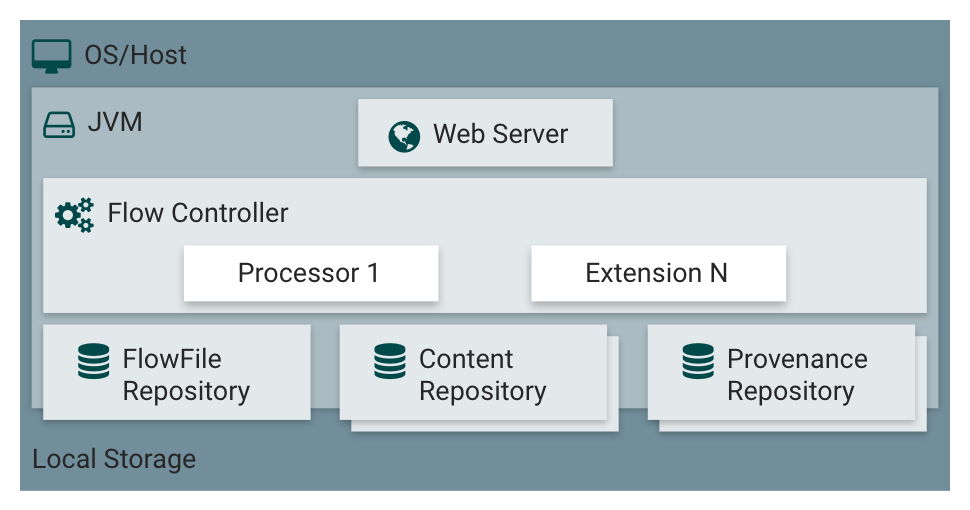
Hình 1: NiFi Standlone
NiFi thực thi trong một JVM trên hệ điều hành máy chủ. Các thành phần chính của NiFi trên JVM như sau:
- Web server: Mục đích của máy chủ web là lưu trữ API điều khiển và lệnh dựa trên HTTP của NiFi.
- Flow controller: Bộ điều khiển lưu lượng là bộ não của hoạt động. Nó cung cấp các luồng để các tiện ích mở rộng chạy trên đó và quản lý lịch trình khi các tiện ích mở rộng nhận tài nguyên để thực thi.
- Extensions: Có nhiều loại tiện ích mở rộng NiFi được mô tả trong các tài liệu khác. Điểm mấu chốt ở đây là các phần mở rộng hoạt động và thực thi bên trong JVM.
- Flow file: Kho lưu trữ FlowFile là nơi NiFi theo dõi trạng thái của những gì nó biết về một FlowFile nhất định hiện đang hoạt động trong luồng. Việc triển khai kho lưu trữ có thể cắm được. Cách tiếp cận mặc định là Nhật ký ghi trước liên tục nằm trên một phân vùng đĩa được chỉ định.
- Content Repository: Kho lưu trữ nội dung là nơi lưu trữ các byte nội dung thực tế của một FlowFile nhất định. Việc triển khai kho lưu trữ có thể cắm được. Cách tiếp cận mặc định là một cơ chế khá đơn giản, lưu trữ các khối dữ liệu trong hệ thống tệp. Có thể chỉ định nhiều hơn một vị trí lưu trữ hệ thống tệp để có được các phân vùng vật lý khác nhau được tham gia để giảm tranh chấp trên bất kỳ ổ đĩa nào.
- Provenance Repository: Kho lưu trữ nguồn gốc là nơi lưu trữ tất cả dữ liệu sự kiện nguồn gốc. Cấu trúc kho lưu trữ có thể cắm được với việc triển khai mặc định là sử dụng một hoặc nhiều ổ đĩa vật lý. Trong mỗi dữ liệu sự kiện vị trí được lập chỉ mục và có thể tìm kiếm được.
NiFi cũng có thể hoạt động theo một cụm:
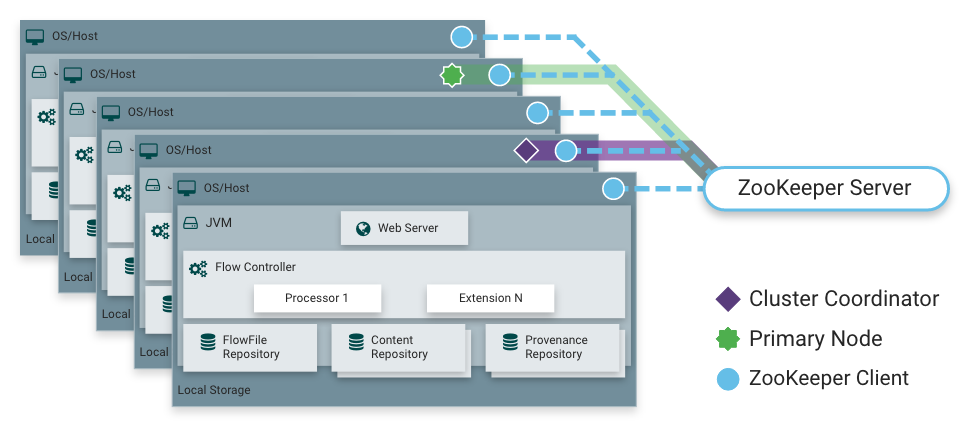
Hình 2: NiFi Cluster
- Mô hình hoạt động: Zero-Master Clustering.
- Cluster Coordinator: là một nút trong cụm NiFi chịu trách nhiệm duy trì thông tin về trạng thái của cụm.
- Primary node: là nút chịu trách nhiệm thực thi tất cả các luồng dữ liệu và quản lý sổ đăng ký luồng cụm.
- Mỗi nút trong cụm NiFi thực hiện các tác vụ giống nhau trên dữ liệu, nhưng mỗi nút hoạt động trên một bộ dữ liệu khác nhau.
Scheduling fetch data same day from MongoDB to Hadoop

Hình 3: Mô tả hướng xử lý vấn đề
Cài đặt môi trường
- Cài đặt Apache Hadoop
- Cài đặt MongoDB, MongoDB Compass
- Cài đặt Apache NiFi
Tiến trình xử lý trong NiFi
Chúng ta sẽ sử dụng 2 processor của NiFi đó là:
- GetMongo
- PutHDFS
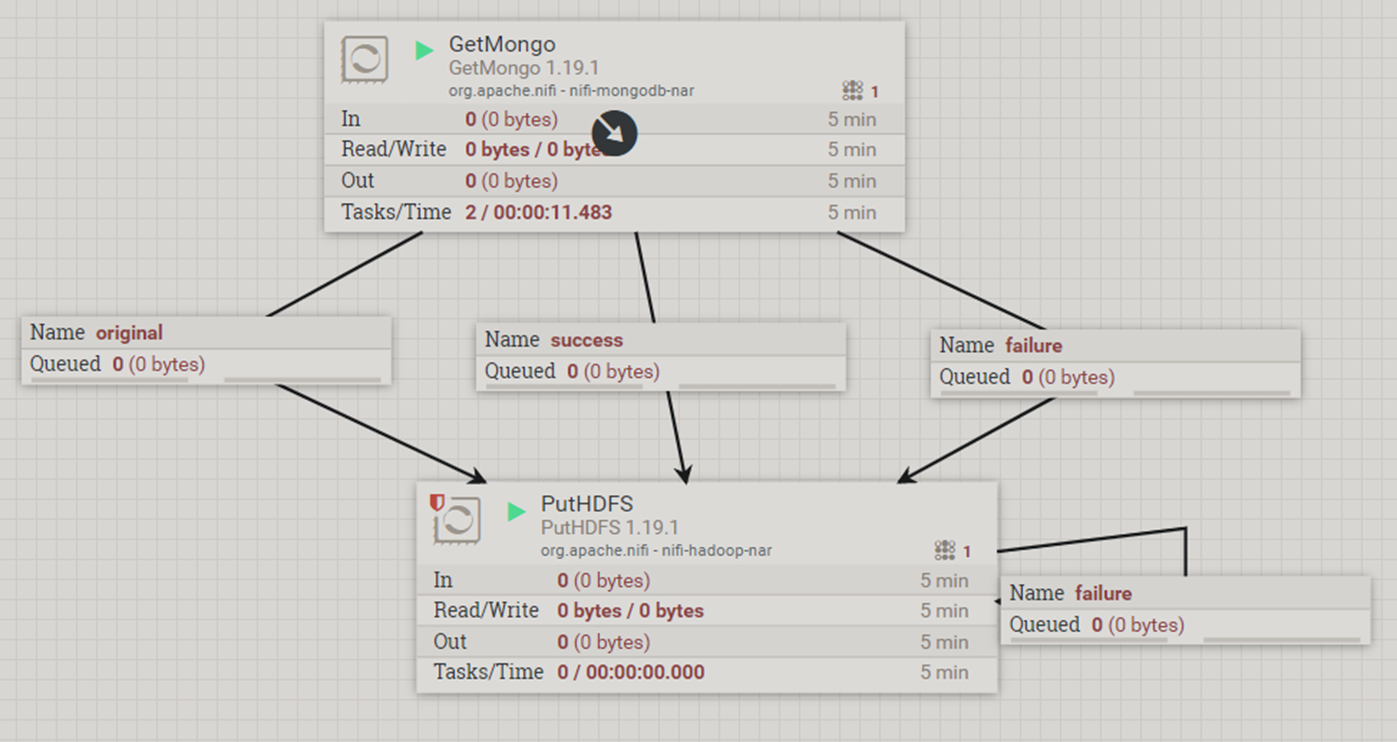
Hình 4: Luồng xử lý các processor trong NiFi
GetMongo processor
Setup Scheduling tab:
- Scheduling Strategy: Sử dụng bộ lập lịch CRON Driven
- Run Schedule:
59 59 23 ? * MON-SUNlà lên lịch để bộ xử lý chạy lúc 23:59:59 từ thứ hai đến chủ nhật hàng tuần
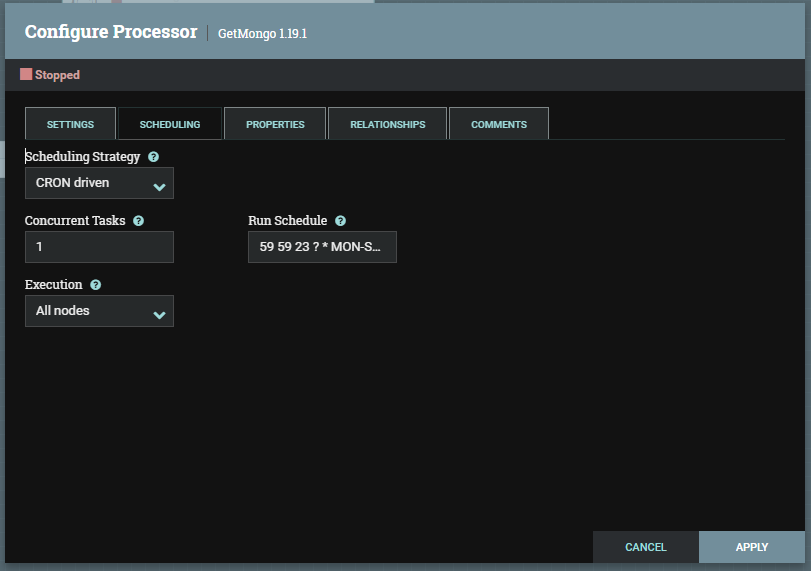
Hình 5: Cấu hình lập lịch mỗi ngày
Setup Properties tab:
- Mongo URL: kết nối với Mongo: mongodb://host1[:port1]
- Mongo Database Name: Tên database
- Mongo Collection Name: Tên Collection
- Query: Truy vấn với Mongodb ở định dạng JSON. Trong trường hợp này chúng ta sẽ giải sử trong Collection ở MongoDb có field là
time_createdđể có thể truy vấn dữ liệu hàng ngày.
{
"$where": "find_data_by_date_range(this.time_created)"
}
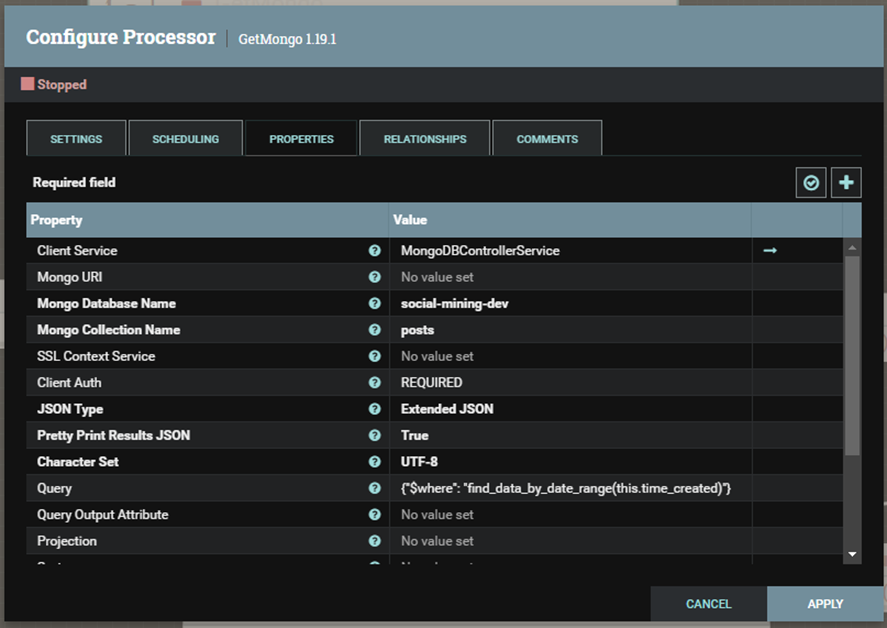
Hình 6: Cấu hình kết nối và truy vấn MongoDB
Tạo hàm thủ tục find_data_by_date_range (function procedure):
db.system.js.insertOne({
_id: "find_data_by_date_range",
value: function (created_time) {
var fromDate = new Date(new Date().setHours(0, 0, 0, 0));
var toDate = new Date(new Date().setHours(23, 59, 59, 999));
if ((created_time >= fromDate) && (created_time <= toDate)) {
return true;
}
return false;
}
});
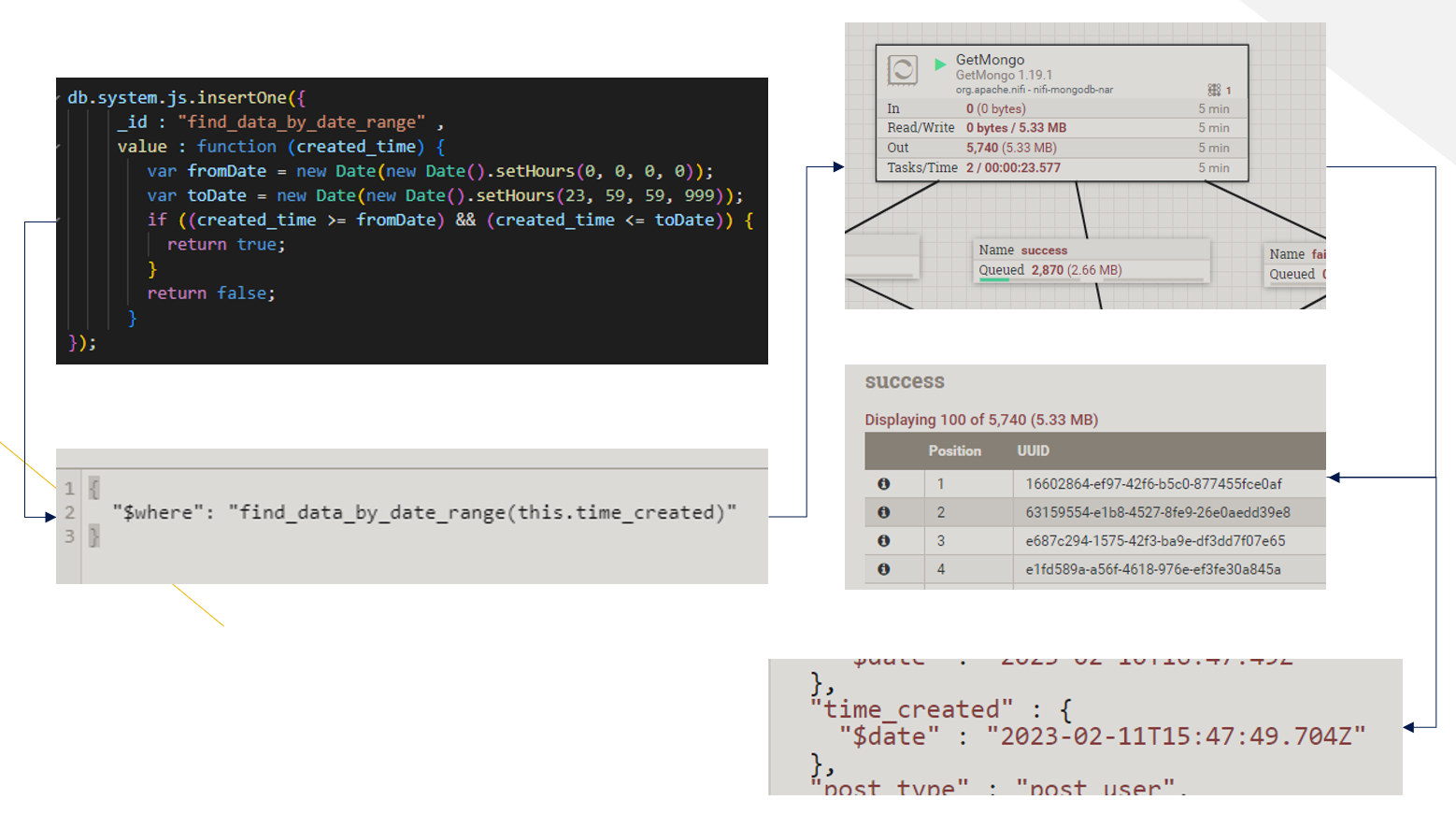
Hình 7: Luồng xử lý truy vấn dữ liệu từ MongoDB
PutHDFS processor
- Hadoop Configuration Resources: Cấu hình Hadoop
- Directory: Thư mục trên HDFS
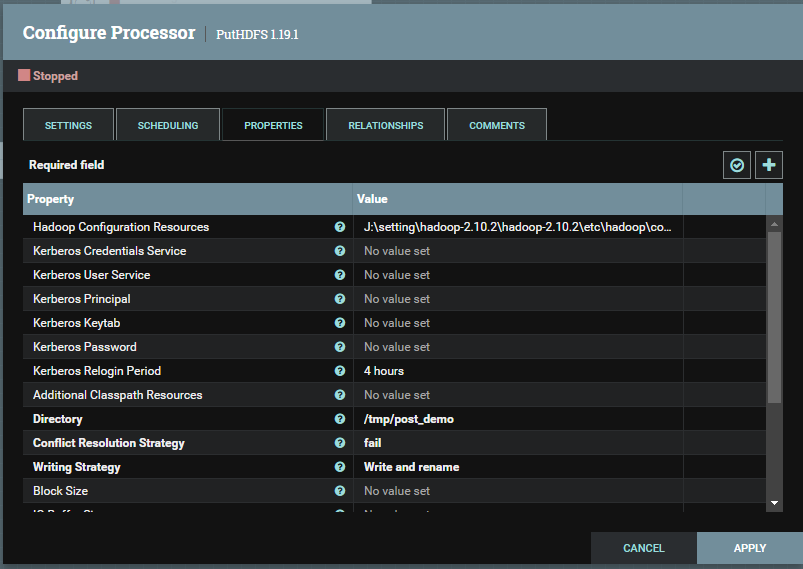
Hình 8: Cấu hình put data lên HDFS
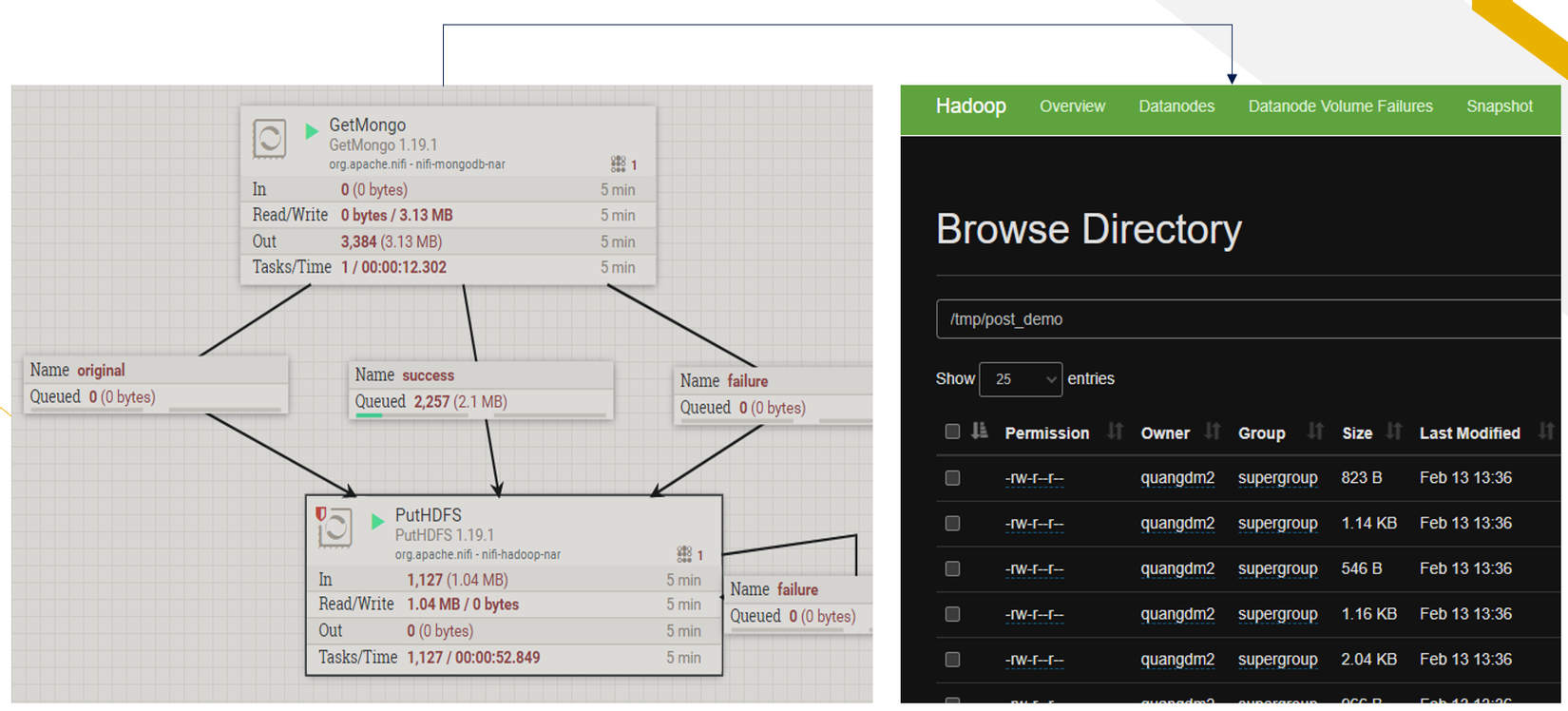
Hình 9: Hoàn thành job
Tổng kết
Bài post này là cách làm của mình trong việc chuyển dữ liệu từ MongoDB lên Hadoop. Hi vọng có thể giúp bạn giải quyết được vấn đề. Nếu có cách giải quyết hay hơn hãy đóng góp ý kiến ở bình luận nhé. Xin cám ơn! 😄
Tài liệu tham khảo
- Apache NiFi : https://nifi.apache.org/docs.html
- Install Hadoop: https://github.com/DoManhQuang/datasciencecoban/tree/master/blog/hadoop/install-hadoop
- GetMongo Processor: https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-mongodb-nar/1.19.1/org.apache.nifi.processors.mongodb.GetMongo/index.html
- PutHDFS Processor: https://nifi.incubator.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-hadoop-nar/1.19.1/org.apache.nifi.processors.hadoop.PutHDFS/index.html
All rights reserved
