Kiểm thử big data - hướng dẫn hoàn chỉnh cho người mới bắt đầu (phần 3)
Bài đăng này đã không được cập nhật trong 8 năm
(Tiếp theo phần 1 và 2)
Tiếp cận kiểm thử hiệu năng
Tiếp cận kiểm thử hiệu năng cho ứng dụng big data được thể hiện ở hình ảnh dưới dây
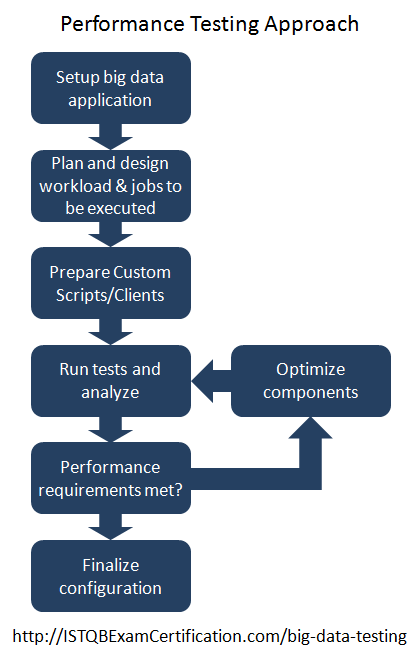
- Để bắt đầu kiểm thử hiệu năng, cần pải thiết lập cụm big data (big data cluster) sẽ được kiểm thử.
- Xác định và lên kế hoạch phần công việc sẽ được thực hiện
- Viết scripts được yêu cầu
- Thực hiện kiểm thử hiệu năng và nghiên cứu kết quả
- Nếu không hài lòng về kết quả và hệ thống không đáp ứng tiêu chuẩn hiệu năng, phải tối ưu hoá lại các thành phần được kiểm thử và kiểm thử lại
- Lặp lại bước 4 cho đến khi các yêu cầu về hiệu năng được đáp ứng
Kiểm thử chức năng của ứng dụng big data
Kiểm thử chức năng của các ứng dụng big data được thực hiện bằng cách kiểm thử giao diện dựa trên giao diện người dùng. Giao diện người dùng có thể là một ứng dụng web có giao diện Hadoo ( hoặc một framework tương thích với back-end)
Kết quả được tạo ra bởi giao diện sẽ được so sánh với kết quả mong đợi.
Kiểm thử chức năng của các ứng dụng gần giống với kiểm thử chức năng thông thường của ứng dụng phần mềm khác.
Vai trò và trách nhiệm của một Tester trong ứng dụng big data
- Tester có thể phải làm việc với dự liệu phi cấu trúc và bán cấu trúc. HỌ cũng có thể làm việc với dữ liệu có cấu trúc trong kho dữ liệu RDBMS nguồn.
- Vì lược đồ (schema) có thể thay đổi trong quá trình phát triển ứng dụng, tester có thể phải làm việc với lược đồ được thay đổi.
- Vì dữ liệu có thể đến từ nhiều nguồn khác nhau và khác nhau về cấu trúc, nên tesster có thể tự phát triển cấu trúc dựa trên kiến thức về nguồn dữ liệu.
- Để làm được điều trên, tester có thể làm việc cùng nhóm phát triển và người dùng hiểu về nghiệp vụ để hiểu hơn về dữ liệu.
- Trong các ứng dụng chung, tester có thể sử dụng chiến lược lấy mẫu khi kiểm thử bằng tay hoặc chiến lược xác minh toàn diện khi sử dụng công cụ tự động hóa. Tuy nhiên trong trường hợp các ứng dụng big data vì tập dữ liệu là rất lớn ngay cả khi trích xuất một mẫu đại diện cho tập dữ liệu một cách chính xác, có thể là một thách thức.
- Tester phải làm việc với nhóm phát triển và kinh doanh và có thể phải nghiên cứu vấn đề nghiệp vụ trước khi đưa ra chiến lược
- Testers sẽ phải đổi mới để đưa ra các kỹ thuật để đảm bảo test coverage trong khi vẫn duy trì năng suất kiểm thử cao.
- Tester nên biết cách làm việc với các hệ thống như Hadoop, HDFS. Trong một số tổ chức, họ cũng có thể được yêu cầu có kiến thức cơ bản về thiết lập hệ thống.
- Tester có thể được yêu cầu có kiến thức về Hive QL và Pig Latin.
Ưu điểm của việc sử dụng big data / Hadoop
- Khả năng mở rộng : Các ứng dụng big data có thể được sử dụng để xử lý khối lượng lớn dữ liệu. Dữ liệu này có thể là từ petabyte trở lên. Hadoop có thể dễ dàng mở rộng từ một nút đến hàng nghìn nút dựa trên các yêu cầu xử lý và dữ liệu.
- Đáng tin cậy : Hệ thống big data được thiết kế để chịu lỗi và tự động xử lý lỗi phần cứng. Hadoop tự động chuyển các tác vụ từ các máy không thành công với các máy khác.
- Kinh tế : Sử dụng phần cứng cùng với khả năng chịu lỗi được cung cấp bởi Hadoop, làm cho nó trở thành một lựa chọn rất kinh tế để xử lý các vấn đề liên quan đến các tập dữ liệu lớn.
- Linh hoạt : Các ứng dụng dữ liệu lớn có thể có các loại dữ liệu không đồng nhất khác nhau như dữ liệu có cấu trúc, dữ liệu bán cấu trúc và dữ liệu phi cấu trúc. Nó có thể xử lý dữ liệu cực kỳ nhanh chóng do xử lý song song dữ liệu.
Khuyết điểm của việc sử dụng big data/ hadoop
- Độ phức tạp kỹ thuật - Độ phức tạp kỹ thuật liên quan đến các dự án big data cao hơn đáng kể so với các dự án thông thường. Mỗi thành phần của hệ thống thuộc về một công nghệ khác nhau. Các chi phí và hỗ trợ liên quan đến việc đảm bảo rằng phần cứng và phần mềm cho các dự án này chạy suôn sẻ, đều cao.
- Thay đổi logistic (logictical changes) - Các tổ chức muốn sử dụng big data có thể phải sửa đổi luồng dữ liệu vào hệ thống của họ.
- Nguồn nhân lực có trình độ - Tester và developer làm việc cho dự án big data cần phải có kỹ thuật và kỹ năng cao khi tự mình chọn công nghệ mới. Tìm kiếm và giữ chân những người có tay nghề cao có thể là một thách thức.
- Đắt tiền - Mặc dù big data hứa hẹn sử dụng máy móc chi phí thấp để giải quyết các thách thức về máy tính, nguồn nhân lực cần thiết trong các dự án như vậy là tốn kém. Các chuyên gia khai thác dữ liệu, các nhà khoa học dữ liệu, developer, tester cần thiết cho các dự án như vậy có chi phí cao hơn các dự án thông thường.
- Độ chính xác của kết quả - Việc trích xuất đúng dữ liệu và kết quả chính xác từ dữ liệu là một thách thức. Ví dụ: Đôi khi Gmail có thể đánh dấu một email hợp pháp là spam. Nếu nhiều người dùng đánh dấu email từ ai đó là spam, gmail sẽ bắt đầu đánh dấu tất cả email từ người gửi đó là spam.
Kiến trúc Hadoop
Hadoop là một trong những framework được sử dụng rộng rãi nhất trong các dự án big data. Ở góc độ của tester, việc tìm hiểu kiến trúc Hadoop mang lại nhiều lợi ích.
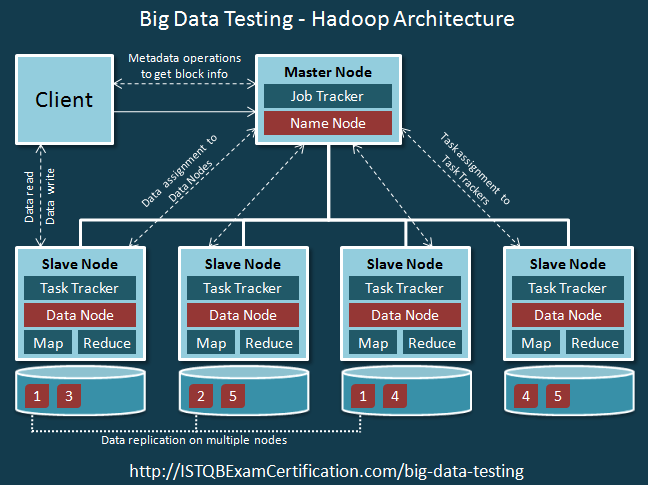
sơ đồ trên cho thấy kiến trúc tầng cao của Hadoop. Mỗi nút (Client, Master Node, Node Slave) đại diện cho một máy.
Hadoop được cài đặt trên các máy khách và họ kiểm soát công việc đang được thực hiện bằng cách tải dữ liệu cụm (cluster data), gửi các công việc MapReduce và cấu hình xử lý dữ liệu. Chúng cũng được sử dụng để xem kết quả. Tất cả các máy này tạo thành một cụm (cluster). Có thể có nhiều cụm trong mạng.
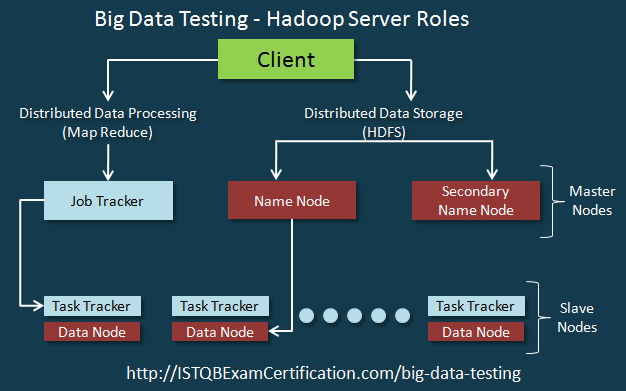
MasterNodes có hai trách nhiệm chính. Đầu tiên, chúng xử lý lưu trữ phân tán dữ liệu bằng cách sử dụng NameNodes. Thứ hai, xử lý song song dữ liệu (MapReduce) được điều phối bởi JobTracker. Secondary NameNode hoạt động như một NameNode backup.
Các Slave node tạo thành số lượng lớn các máy chủ. Chúng lưu trữ và xử lý dữ liệu. Mỗi nút nô lệ có một DataNode và một TaskTracker.
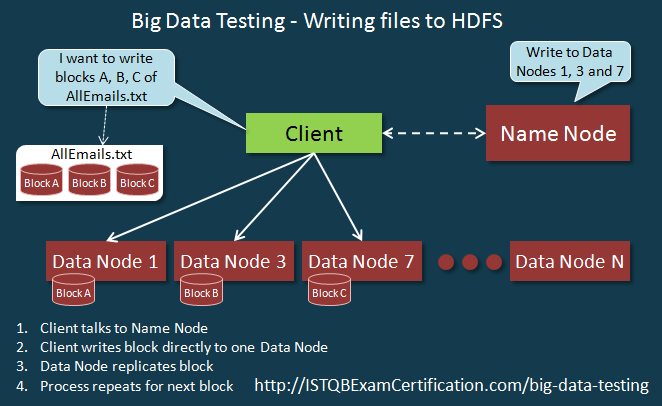
DataNode phụ thuộc và nhận hướng dẫn từ NameNodes và thực hiện lưu trữ dữ liệu như được hiển thị bên dưới.
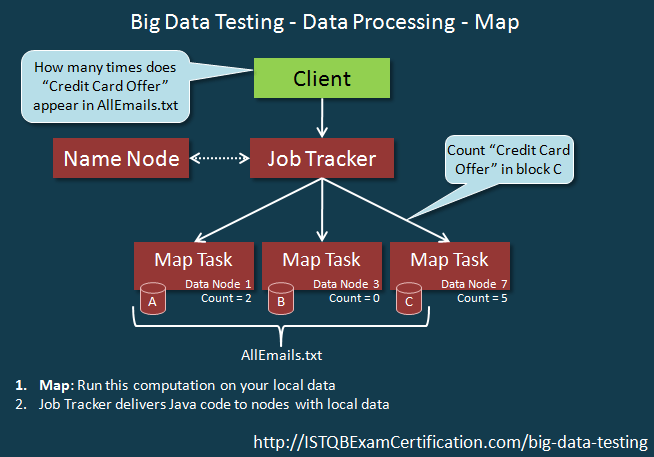
Task Tracker phụ thuộc và nhận hướng dẫn từ Job Tracker. Xử lý dữ liệu sử dụng MapReduce có 2 bước xử lý như hình dưới đây
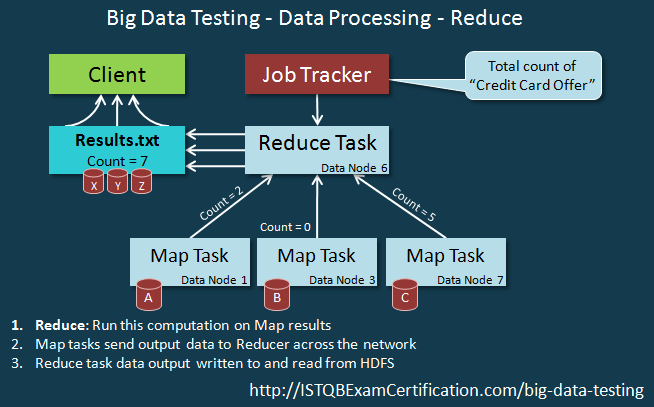
Chuỗi sự kiện của Reduce process như dưới đây:
Công cụ Big data (Big data tool)/ Các thuật ngữ chung
- Hadoop - Hadoop là một framework mã nguồn mở. Nó được sử dụng để xử lý phân tán và lưu trữ các tập dữ liệu lớn bằng cách sử dụng các cụm (cluster) máy. Nó có thể mở rộng từ một máy chủ đến hàng ngàn máy chủ. Nó cung cấp tính sẵn sàng cao bằng cách sử dụng các máy giá rẻ bằng cách xác định các lỗi phần cứng và xử lý chúng ở tầng ứng dụng.
- Hệ thống tệp phân tán Hadoop - Hadoop Distributed File System (HDFS) - HDFS là hệ thống tệp phân tán được sử dụng để lưu trữ dữ liệu trên nhiều máy chi phí thấp.
- MapReduce - MapReduce là mô hình lập trình để xử lý song song các tập dữ liệu lớn
- Hive - Apache Hive là phần mềm kho dữ liệu được sử dụng để làm việc với các tập dữ liệu lớn được lưu trữ trong các hệ thống tệp phân tán
- HiveQL - HiveQL tương tự như SQL và được sử dụng để truy vấn dữ liệu được lưu trữ trong Hive. HiveQL chỉ thích hợp cho cấu trúc dữ liệu phẳng và không thể xử lý cấu trúc dữ liệu lồng nhau phức tạp.
- Pig Latin - Pig Latin là một ngôn ngữ cấp cao được sử dụng với nền tảng Apache Pig. Pig Latin có thể được sử dụng để xử lý các cấu trúc dữ liệu lồng nhau phức tạp. Pig Latin không yêu cầu mã hóa phức tạp.
- Commodity Servers - Khi làm việc với dữ liệu lớn, bạn sẽ gặp phải các thuật ngữ như Commodity Servers. Điều này đề cập đến phần cứng rẻ được sử dụng để xử lý song song dữ liệu. Nếu một Commodity Servers thất bại trong khi xử lý một lệnh, thì nó được phát hiện và xử lý bởi Hadoop. Hadoop sẽ gán nhiệm vụ cho một máy chủ khác. Khả năng chịu lỗi này cho phép chúng tôi sử dụng phần cứng rẻ tiền.
- Nút - Nút đề cập đến từng máy nơi dữ liệu được lưu trữ và xử lý. Các khung dữ liệu lớn như Hadoop cho phép chúng ta làm việc với nhiều nút. Các nút có thể có các tên khác nhau như DataNode, NameNode, v.v.
- DataNodes - Đây là những máy được sử dụng để lưu trữ dữ liệu và xử lý dữ liệu.
- NameNodes - NameNode là thư mục trung tâm của tất cả các nút. Khi một khách hàng muốn định vị một tệp, nó có thể giao tiếp với NameNode, nó sẽ trả về danh sách các máy chủ DataNodes nơi tệp / dữ liệu có thể được định vị.
- Master node - Master node giám sát việc lưu trữ dữ liệu và xử lý song song dữ liệu bằng cách sử dụng MapReduce. Nó sử dụng NameNode để lưu trữ dữ liệu và JobTracker để quản lý việc xử lý song song dữ liệu.
- JobTracker - Nó chấp nhận công việc, gán nhiệm vụ và nhận diện các máy thất bại
- Worker nodes - Chúng là số lượng lớn các máy ảo và được sử dụng để lưu trữ và xử lý dữ liệu. Mỗi work node chạy một DataNode và TaskTracker - được sử dụng để nhắn tin với các nút chính.
- Client nodes - Hadoop được cài đặt trên các nút máy client nodes. Chúng không phải là Master node hay worker node, được sử dụng để thiết lập dữ liệu cụm, gửi các công việc MapReduce, xem kết quả.
- Cụm (cluster) - Cụm là tập hợp các nút hoạt động cùng nhau. Các nút này có thể là Master node, worker node or client nodes.
Công cụ kiểm thử tự động big data
Kiểm thử các ứng dụng big data phức tạp hơn nhiều so với kiểm thử các ứng dụng thông thường. Các công cụ kiểm thử tự động hóa big data giúp tự động hoá các tác vụ lặp đi lặp lại liên quan đến kiểm thử.
Bất kỳ công cụ nào được sử dụng để kiểm thử tự động hóa các ứng dụng dữ liệu lớn đều phải đáp ứng các nhu cầu sau:
- Cho phép tự động hóa quá trình kiểm thử phần mềm hoàn chỉnh
- Vì kiểm thử cơ sở dữ liệu là một phần lớn của việc kiểm thử big data, công cụ kiểm thử tự động nên hỗ trợ theo dõi dữ liệu khi nó được chuyển từ dữ liệu nguồn sang dữ liệu đích sau khi được xử lý thông qua thuật toán MapReduce và các phép biến đổi ETL khác.
- Có khả năng mở rộng nhưng đồng thời, nó phải đủ linh hoạt để kết hợp các thay đổi khi mức độ phức tạp của ứng dụng tăng lên
- Tích hợp với các hệ thống và nền tảng khác nhau như Hadoop, Teredata, MongoDB, AWS, các sản phẩm NoSQL khác, v.v.
- Tích hợp với các giải pháp dev ops để hỗ trợ phân phối liên tục
- Các tính năng báo cáo tốt giúp bạn xác định dữ liệu xấu và các lỗi trong hệ thống
Dịch vụ kiểm thử big data
Tìm kiếm các nguồn lực có kỹ năng để kiểm thử các dự án big data và phát triển nhóm trong khi đáp ứng nhu cầu dự án cùng một lúc là một thách thức và vấn đề này được giải quyết bởi các nhà cung cấp dịch vụ kiểm thử big data.
Các tổ chức cung cấp dịch vụ kiểm thử big data có các thành viên nhóm có kỹ thuật cao. Họ có thể tìm hiểu các công nghệ mới một cách nhanh chóng và khắc phục sự cố một cách độc lập. Họ có kinh nghiệm qua một số lượng lớn các công nghệ, nền tảng và khung công tác, điều này rất quan trọng khi kiểm thử các ứng dụng big data.
Nhà cung cấp dịch vụ kiểm thử big data có một nhóm nguồn lực có kỹ năng có kinh nghiệm trong việc kiểm thử big data. Họ có thể triển khai các nguồn lực cho các dự án một cách nhanh chóng.
Nếu một tổ chức phát triển đội ngũ big data trong nội bộ, sẽ mất một lượng thời gian và chi phí đáng kể để thuê các nguồn lực có tay nghề cao. Điều này có thể ảnh hưởng đến các dự án có thời gian cụ thể. Khác với điều này họ cũng phải giữ lại và quản lý khát vọng nghề nghiệp của các thành viên trong nhóm, những người muốn phát triển trong lĩnh vực này.
Trong các tổ chức truyền thống, dự án big data có thể là một dự án phụ hoặc một trong nhiều dự án. Tuy nhiên, các dự án big data là một lĩnh vực trọng tâm cho các tổ chức cung cấp dịch vụ kiểm thử big data. Kết quả là, các nhà cung cấp dịch vụ kiểm thử big data là một giải pháp tốt cho các tổ chức muốn có chuyên môn nhưng không có thời gian hoặc nguồn lực để phát triển một đội ngũ nội bộ.
Phần 1: https://viblo.asia/p/kiem-thu-big-data-huong-dan-hoan-chinh-cho-nguoi-moi-bat-dau-phan1-QpmleQrMlrd Phần 2: https://viblo.asia/p/kiem-thu-big-data-huong-dan-hoan-chinh-cho-nguoi-moi-bat-dau-phan-2-Do754wyelM6
Bài viết được dịch lại từ nguồn: http://istqbexamcertification.com/big-data-testing/#Big_Data_Hadoop_Performance_Testing
All rights reserved
