Khám phá sức mạnh của cơ chế Self Attention trong Transformers
Bài đăng này đã không được cập nhật trong 3 năm
Lời nói đầu
Transformers đã cách mạng hóa quá trình xử lý ngôn ngữ tự nhiên (NLP) bằng cách đạt được hiệu suất tiên tiến nhất trên nhiều tác vụ như dịch máy, lập mô hình ngôn ngữ và phân tích tình cảm. Một trong những thành phần quan trọng làm cho máy biến áp trở nên mạnh mẽ là việc sử dụng cơ chế self attention của chúng.
Self attention cho phép transformers cân nhắc linh hoạt tầm quan trọng của các phần khác nhau của chuỗi mã thông báo(token) khi đưa ra dự đoán. Điều này cho phép mô hình tập trung vào thông tin phù hợp nhất ở mỗi bước xử lý, giúp mô hình hóa các mối quan hệ ngôn ngữ phức tạp chính xác và hiệu quả hơn.
Trong bài viết này, chúng ta sẽ đi sâu hơn về khái niệm Self attention và vai trò của nó trong transformers. Chúng ta sẽ khám phá cơ chế self attention, bao gồm cách nó khác với cơ chế attention truyền thống và cách nó có thể được sử dụng để nắm bắt các phụ thuộc tầm xa trong chuỗi mã thông báo(token).
Nhìn chung, bài viết này nhằm mục đích cung cấp một cái nhìn tổng quan toàn diện về sự tự chú ý trong máy biến áp, làm nổi bật cả nền tảng lý thuyết của nó trong NLP.
Phần 1 . Forward
1.1 Self Attention
Hãy cùng bắt đầu khám phá cơ chế đặc biệt đằng sau self attention nào . Đầu tiên ta sẽ hiểu đầu vào giữa chúng. Ở đây trog bài viết này chúng ta chỉ khám phá duy nhất cơ chế self attention còn những thứ khác như skip connect ,layer noem hay activation function gelu . Mô hình seuquence to sequence sẽ được bỏ qua . Đều đặc biệt là nằm ở cơ chế này.

Tiếp theo sẽ là hình ản để ta nắm bắt khái quát thế nào là query, keys và value trong self attention . Chúng rất dễ dàng nếu như ta nhìn vào ảnh.
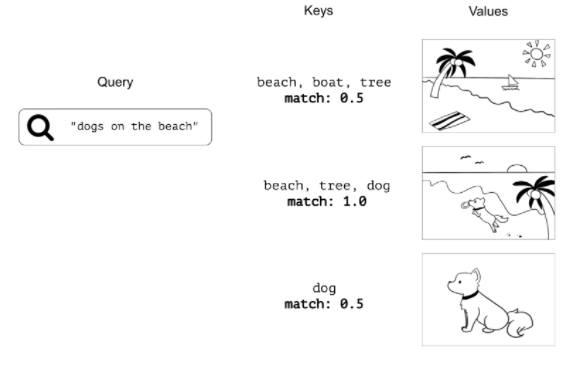
Chúng ta sẽ bắt đầu với việc hiểu các q,k,v theo ngữ cảnh của bài toán . Đây là trực giác còn trong thực tế các q,k,v sẽ là các số đã được token từ đầu vào thông qua các weight tương ứng giữa chúng mà hình thành . Vậy nên các bạn đừng nhầm lẫn q,k,v là text . Chúng thực ra là number

Cơ chế self attention là attention từ quan trọng nhất trong câu nói . Ở đây câu nói "Death is like the wind alway by my side" đang ám chỉ đến điều gì và từ nào ánh xạ chúng quan trọng nhất . Nếu như các bạn đã từng chơi Leage of lengend thì đương nhiên biết câu nói này đang ám chỉ đến một vị tướng và từ ngữ quan trọng mà ta cần chú ý đến đó chính là từ "wind(gió)".
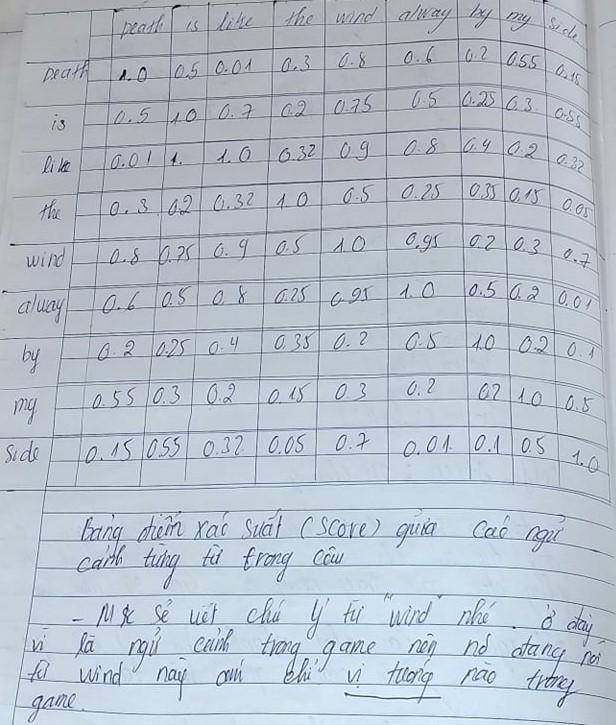
Tuy nhiên đó là theo cảm nhận của chúng ta vì chúng ta đã quen thuộc với chúng , nhưng mạng nơ-ron thì không như vậy chúng ta phải train để cho chúng có thể nắm bắt mối liên hệ giữa các từ trong câu nói. Vậy nên chúng ta sẽ tính toán giá trị như trong bảng trên ( đây chỉ là giả thiết mà mình đưa ra). Các bạn có thể nhìn từ bảng trên và nhận ra rằng các từ có cột và hàng giống nhau có điểm số cao nhất là 1.0 . Những từ nào có điểm số gần bằng 1.0 là những từ ngữ có mối liên hệ cao nhất ví dụ như từ "Death" có mối liên hệ chặt chẽ với từ "Wind" điều đó ám chỉ rằng chúng đang hướng tới mục đích chính là Yasua vị tướng của chúng ta . Ý nghĩa để chúng ta nhận diện ra rằng câu nói này xuất phát từ vị tướng nào.

Hãy ùng mình đi phân tích từ "Death" nhé để hiểu rõ hơn về chúng. Tại sao mình lại đặt điểm số của chúng như vậy , đương nhiên mình không đặt chúng một cách ngẫu nhiên làm gì cả. Tiếp tục với các từ "is","like"...,vv. Tương tự như từ "Death" theo cảm nghĩ của chúng ta.

Tiếp theo sẽ là sơ đồ hay nếu ta dùng Pytorch sẽ có biểu đồ dyamastic . Vâng đây chính là chúng , mặc dù toàn bộ bài viết bằng giấy đều là các bài viết mình đã viết từ 2 năm trước và xin phép được chia sẻ lên trên này. bản thân có sửa chữa chút về chúng
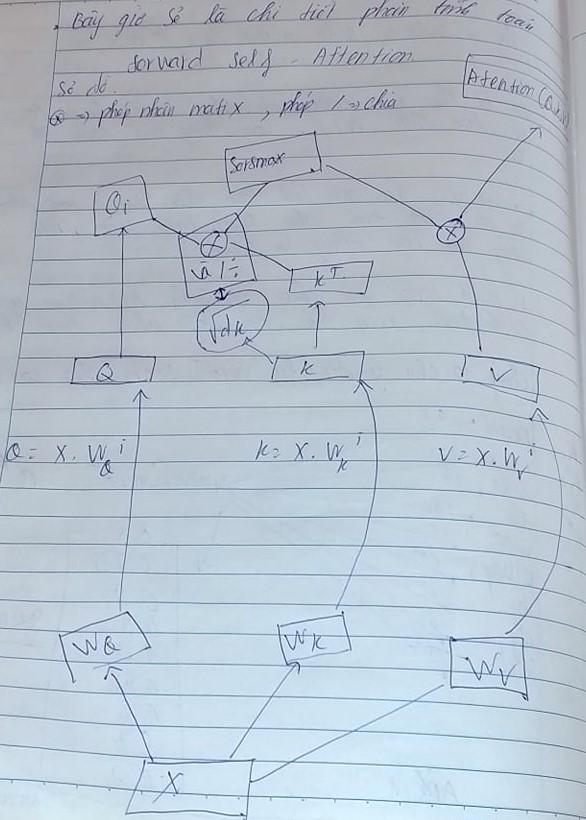
Từ sơ đồ trên ta có thể nhận ra rằng chúng không khác gì một MLP(ANN) cả tuy nhiên ở đây các q,k,v có hình dạng matrix là 2d (không tính batch size) nên nếu tinh ý thì ta nhận ra rằng transformers thật sự giống GNN ( mạng nơ ron đồ thị ).

Chúng ta sẽ thực sự tính các Q,K,V dựa trên đầu vào là x . Tuy nhiên ở đây như đã nói mình sẽ loại bỏ batch size để thuận tiện cho việc tính toán.
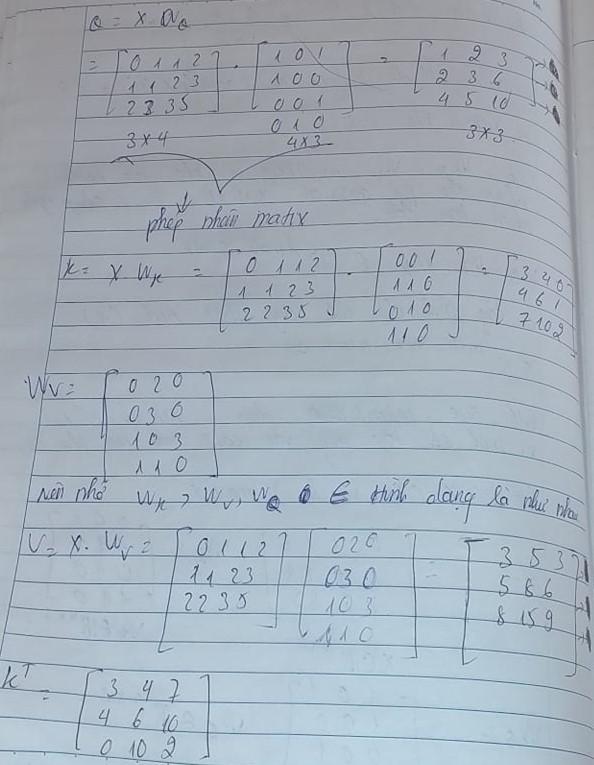
Để cho việc tính toán thật sự dễ dàng thì mình đặt các weight là số 0 hoặc 1 . Thực chất việc khởi tạo weight sẽ quy theo phân phối gaussian đôi khi còn được gọi là (uniform initialization) giá trị trong khoảng từ (-a,a). Hoặc theo Xavier Initialization w ~ U(-sqrt(6 / (n_in + n_out)), sqrt(6 / (n_in + n_out))) trong đó n_in là nodes input n_out là nodes output (Phương pháp này giúp ngăn chặn sự bão hòa của các activation function và cải thiện động lực học tập). He Initialization và LeCun Initialization (thuonhwf được sử dụng trong CNN nhằm vanishing gradients and improve the convergence of CNNs.)

Chúng ta sẽ bắt đầu tính toán giữa Q và K để ra điểm số rồi so sánh với chính V. Đây chính là điểm mấu chốt của cơ chế self attention.
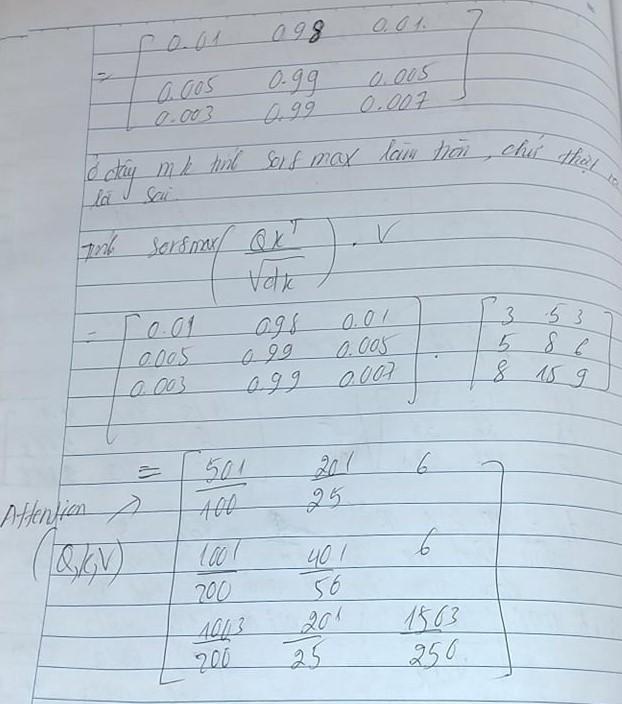
Ở đây mình giải thích chi tiết về hình dạng matrix của paper so với bản thân thực tế tính toán . Chúng khác nhau do tính tay nên các bạn chắc hiểu mình chỉ tính hình dạng matrix rất nhỏ mà thôi

1.2 Multi head attention
Tiếp theo sau khi chúng ta đã có được trực giác đằng sau Self attention , chúng ta sẽ bắt đầu đi phần mở rộng hơn của chúng chính là nhiều self attention kết hợp lại thành và tạo nên multi head attention. Đầu tiên và là từ ta cần để bắt tới và quan trọng nhất chính là từ "wind".Thứ hai từ quan trọng tiếp theo là từ "Death"

Thứ ba và thứ 4 là các từ "like" và từ "the".
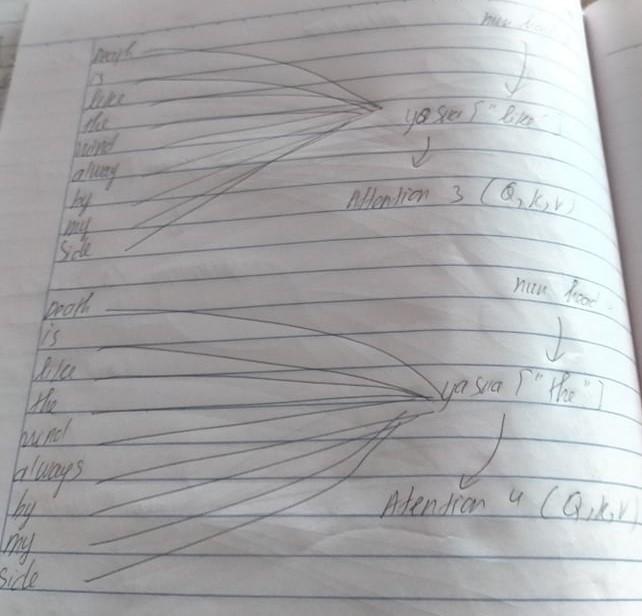
Thứ 5 và thứ 6 là các từ "Alway" và từ "Side"

Và cuối cùng là các từ còn lại trong câu tướng ứng 7 và 8 . Từ "is" và từ "my" ,trong ảnh có từ "like" thực ra là sai sót của bản thân mình chúng phải là từ "my".

Ta có thể nhận ra một điều rằng chúng chú ý( attetion) những từ quan trọng trước rồi lần lượt đến các từ tiếp theo trong câu . Kết hợp tất cả các điều đó lại với nhau ta sẽ được multi head attetion
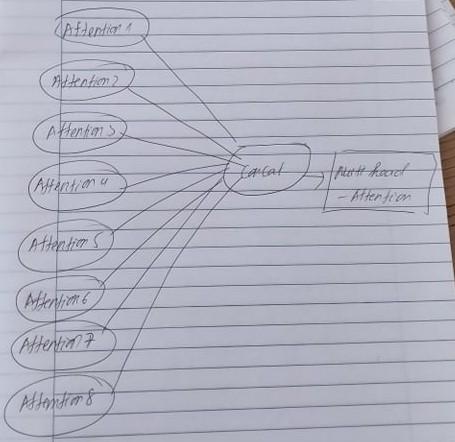
Tuy nhiên trong toàn bộ model Mutihead attetion tác giả có nói đầu ra phải bằng với đầu vào . Vậy nên ta sẽ cần phải kết hợp với một weight để tạo ra hình dạng matrix tương ứng với đầu vào . Cuối cùng ta được multi head attetion như sau . Từ đó ta biết được rằng hình dạng matrix của self attetion tương ứng với hình dạng matrix của multihead attetion.

1.3 Mask multi head attention
Tiếp theo sẽ là phần cuối cùng trong forwrd mà chúng ta tìm hiểu mask multi head attention , thực ra chúng chính là attetion nhưng lược bỏ một số thông tin lặp lại . Các bạn vẫn nhớ cái bảng điểm số chứ , đó chúng là một matrix hình vuông và chúng ta sẽ lược bỏ một nữa số thông tin hình vuông đó ta sẽ được hình tam giác . Mak được sử dụng để ngăn mô hình tham gia vào các vị trí nhất định trong chuỗi đầu vào, điều này đặc biệt hữu ích trong các tác vụ theo trình tự theo trình tự trong đó chuỗi đầu ra được tạo một mã thông báo tại một thời điểm. Mask multi head attetion : Trong một số trường hợp, có thể cần phải áp dụng mask cho chuỗi đầu vào trước khi tính weight attention. Điều này thường được thực hiện trong các tác vụ như mô hình hóa ngôn ngữ, trong đó mục tiêu là dự đoán mã thông báo tiếp theo trong chuỗi. Trong trường hợp này, một mask được áp dụng cho chuỗi đầu vào để ngăn mô hình tham gia vào các vị trí xuất hiện sau vị trí hiện tại.


Bằng cách áp dụng mặt nạ cho hàm softmax tính toán trọng số chú ý, chú ý nhiều đầu với mặt nạ cho phép máy biến áp mô hình hóa dữ liệu tuần tự một cách hiệu quả trong khi vẫn có thể tham gia song song nhiều phần của chuỗi, đồng thời đảm bảo rằng mô hình không tham dự vào các vị trí đã được che đậy. Điều này làm cho nó trở thành một công cụ mạnh mẽ cho nhiều tác vụ xử lý ngôn ngữ tự nhiên, bao gồm dịch máy, lập mô hình ngôn ngữ và phân tích cảm tính.
Phần 2 . Backward self attention
Trong phần 2 này chúng ta sẽ chỉ tính toán duy nhất phần backward self attention mà thôi . Những kế hoạch như tính toán multi head attetion hay mask multi head attetion sẽ bỏ qua . Quan trọng một điều rằng toàn bộ bài viết nhằm giải thích những phần quan trọng trong attetion của transformers chứ không nêu rõ ra model transformers . Đã có rất nhiều bài viết tiếng việt ghi vậy rồi nên sẽ chẳng có gì ngạc nhiên nữa , các bạn có thể tham khảo.
Phần cốt lõi tạo nên self attetion chính là các weight attetion của chúng là weight query , weight value , weight keys . Chúng sẽ được tính toán dựa trên backward mà chúng ta sẽ được học trong bài viết này.

Trước khi tính đến các weight attention ta sẽ phải tính toán từ loss đến các value, query và keys rồi mới có thể tính được weight attention như thế nào. Ảnh tiếp theo sẽ là gradient của value
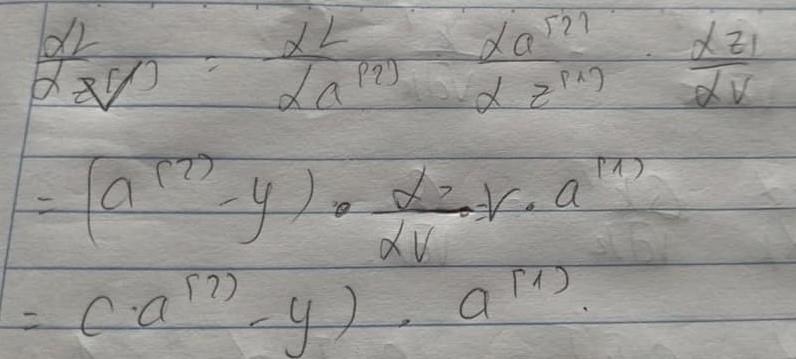
Để hiểu rõ hơn kết quả từ ảnh đầu tiên ta sẽ tính gradient của loss binary crossentropy


Bây giờ hãy cùng chiêm ngưỡng lại toàn bộ sơ đồ dyamastic để tính toán backward trong self attention của chúng ta . Đồng thời chúng ta sẽ tính gradient của query . Lưu ý ký hiệu (*) ở đây ảnh sau chúng ta sẽ dùng chúng.
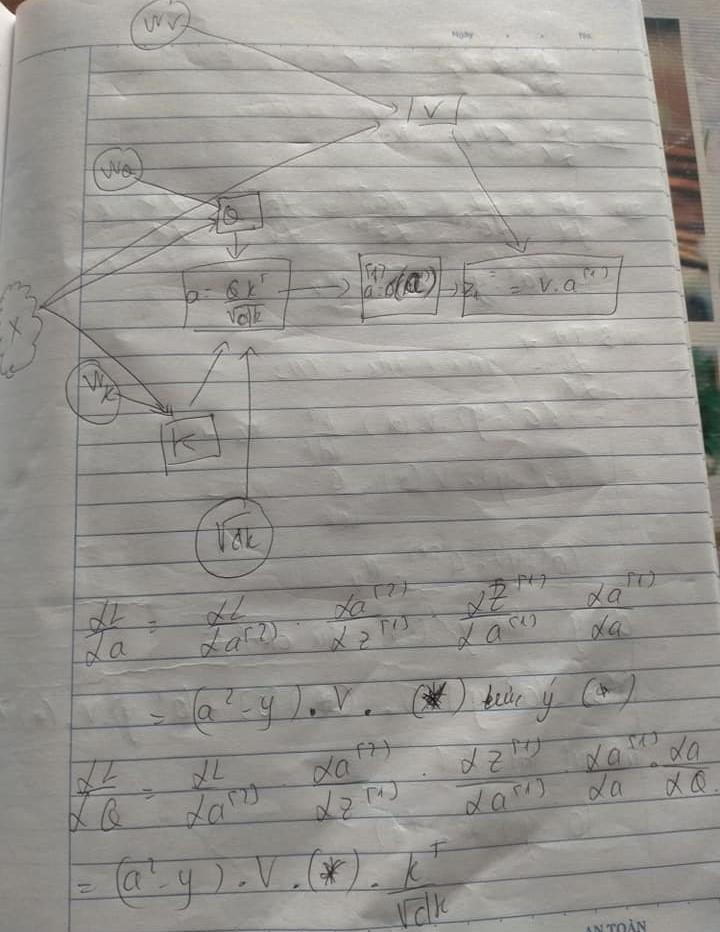
Tiếp theo ta sẽ tính lần lượt các gradient keys và hơn hết là chiều căn bậc 2 dim của keys

Quan trọng nhất dẫn đến việc tính toán backward self attetion khó khăn lại chính nằm ở activation function softmax được tính toán quá phức tạp . Đây chính là nguyên nhân chính gây khó khăn cho việc này
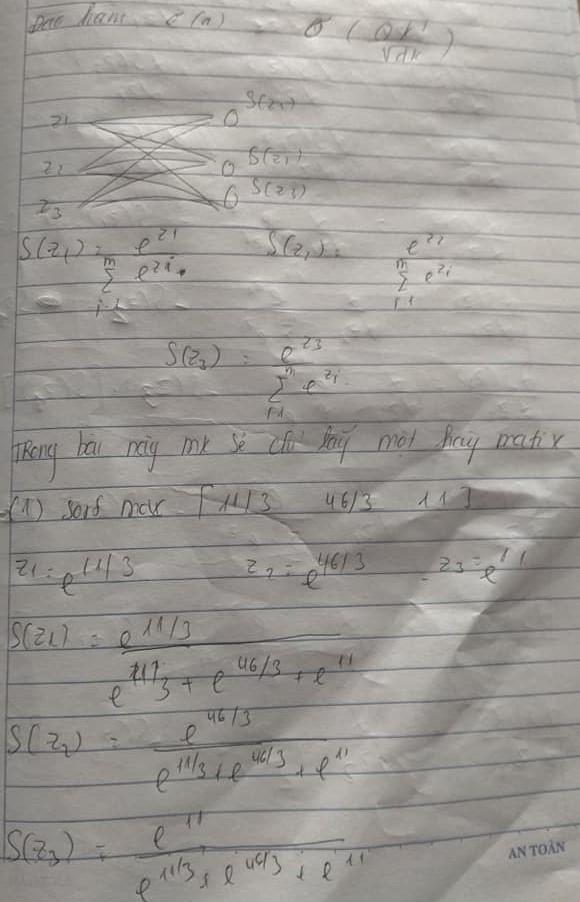
Việc tính toán gradient activation function softmax đã được trình bày trong Introduction backprogation ANN(serries 1) phần 3 đã nêu rất rõ . Chúng ta chỉ việc tính toán chúng lại rồi kết hợp tất cả lại với nhau là được . Khi kết hợp lại với nhau cả 2 trường hợp và ta được ký hiệu (*)


Sau khi chúng ta đã hiểu ký hiệu (*) chỉ là gradient activation function softmax . Chúng ta sẽ lần lượt tính toán các Wq,Wk,Wv .Để có thể tính toán chúng ta sẽ gọi Wq là Th1, Wk là Th2, Wv là Th3. Do activation function softmax chỉ liên kết với q và k nên Wq sẽ là . Tương tự như vậy với Wk sẽ là và cuối cùng Wv do không liên kết với activation function softmax nên việc tính toán chúng rât dễ dàng là

Từ 3 trường hợp ta biết rằng cách tính X đầu vào là sự kết hợp phéo cộng của cả 3 Wq,Wk,Wv hình thành nên . Do vấn đề X nhân với từng loạt Wq,Wk,Wv ra Q,K,V nên khi backward chúng cũng sẽ phải tính ngược lại như vậy.
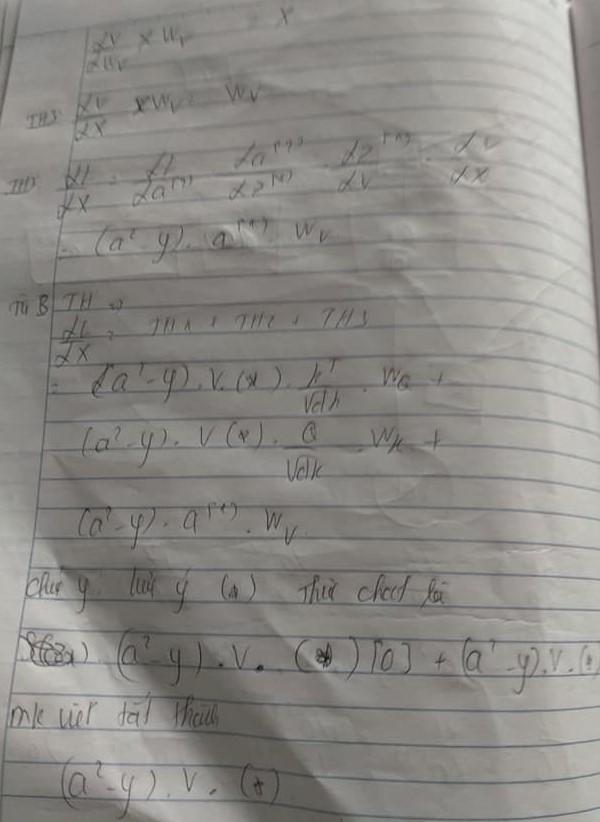
Phần 3. Kết luận
Trên đây là bài viết tổng kết lại về self attention của bản thân được lấy từ trong bài viết bằng tay của bản thân đăng trên Hội anh em thích ăn mỳ AI . mặc dù bài viết này đã được 2 năm kể từ khi ra mắt nhưng mình vẫn muốn cố gắng share lên đây . Bài viết được tổng hợp một cách rất chi tiết về cấu trúc hoạt động của chúng và đây sẽ là bài viết được viết bằn tay cuối cùng . Mọi bài viết blog sau này đều sẽ được viết theo đúng dạng latex để mọi người có thể nắm bắt và theo dõi xuyên suốt chủ đề khác nhau.
Tham khảo
https://www.facebook.com/groups/miaigroup/permalink/1035750953862843/ (Phần 1) https://www.facebook.com/groups/miaigroup/permalink/1035758207195451/(Phần 2)
All rights reserved
