Khái quát về Text-To-Speech
Bài đăng này đã không được cập nhật trong 5 năm
Chắc hẳn ai cũng đã từng dùng hoặc nghe ít nhất 1 lần về Text-To-Speech - 1 thứ giúp chúng ta có thể chuyển từ văn bản trên điện thoại, máy tính sang dạng âm thanh. Hôm nay mình sẽ giới thiệu một cách tổng quan về công nghệ Text-To-Speech và đi sâu hơn vào cách mà một hệ thống có thể chuyển đổi từ văn bản sang giọng nói được.
1. Khái niệm
Hệ thống chuyển đổi văn bản thành lời nói Text-To-Speech là một hệ thống dựa trên máy tính tự động chuyển đổi văn bản thành lời nói nhân tạo của con người. Bộ tổng hợp Text-To-Speech không phát lại lời nói đã ghi mà thay vào đó, chúng tạo ra các câu sử dụng văn bản thuần túy làm đầu vào. Cần phải phân biệt giữa các bộ tổng hợp Text-To-Speech từ Hệ thống phản hồi bằng lời nói. Hệ thống phản hồi bằng lời nói chỉ đơn giản là nối các từ và các phân đoạn của câu và chỉ áp dụng được trong các trường hợp cần có vốn từ vựng hạn chế và các hạn chế về phát âm.
2. Một số hệ thống hiện có
Ngày nay, có rất nhiều hệ thống chuyển đổi văn bản thành lời nói Text-To-Speech được phát triển bới các công ty, các nhà phát triển trên khắp thế giới. Mỗi hệ thống có cách thức phát triển riêng nhưng đều hướng tới mục đích là có thể chuyển đổi văn bản thành lời nói gần giống với tiếng nói thực tế của con người nhất có thể. Phổ biến nhất và chất lượng nhất có thể kể đến các hệ thống Text-To-Speech được phát triển bởi Google.
- Google Text-To-Speech: Một ứng dụng độc màn hình do Google phát triển cho hệ điều hành Android với sự hỗ trợ cho nhiều ngôn ngữ. Tính năng chuyển văn bản thành giọng nói có thể được sử dụng bởi các ứng dụng khác trong cùng bộ ứng dụng Google để có thể đọc sách, cung cấp thông tin chi tiết về cách phát âm của từ.
- Google Tacotion 2: đơn giản hóa các kỹ thuật tổng hợp giọng nói bằng AI, được sử dụng trong mạng nơ-ron, cái có thể tạo ra giọng nói gần giống với giọng nói con người từ văn bản.
Bên cạnh các hệ thống được phát triển bởi Google, có một số hệ thống khác có khả năng chuyển đổi văn bản thành giọng nói rất giống giọng nói thực của con người, trong đó có WaveNet. WaveNet là một mạng nơ-ron sâu để tạo ra âm thanh thô. Nó được tạo ra bởi các nhà nghiên cứu tại công ty trí tuệ nhân tạo DeepMind có trụ sở tại London. Kỹ thuật này, được nêu trong một bài báo vào tháng 9 năm 2016, có thể tạo ra giọng nói tương đối thực tế giống như tiếng người bằng cách mô hình hóa trực tiếp các dạng sóng bằng phương pháp mạng thần kinh được huấn luyện với các bản ghi âm giọng nói thực. Các thử nghiệm với tiếng Anh Mỹ cho thấy hệ thống này hoạt động tốt hơn các hệ thống chuyển văn bản thành giọng nói (TTS) tốt nhất hiện có của Google, mặc dù tính đến năm 2016, tính năng tổng hợp văn bản thành giọng nói của nó vẫn kém thuyết phục hơn so với giọng nói thực tế của con người. Khả năng tạo ra các dạng sóng thô của WaveNet có nghĩa là nó có thể mô hình hóa bất kỳ loại âm thanh nào, bao gồm cả âm nhạc. Các doanh nghiệp công nghệ ở Việt Nam cũng không đứng ngoài cuộc đua phát triển hệ thống Text-To-Speech này. Hai ông lớn trong mảng công nghệ là Viettel và FPT cũng phát triển cho mình những hệ thống Text-To-Speech được xây dựng trên chính ngôn ngữ Tiếng Việt với những đặc trưng riêng của Tiếng Việt, cùng với đó là giọng nói được tạo ra được mô phỏng theo giọng nói của cả ba miền đất nước. Có thể nói, khả năng phát triển của những hệ thống Text-To-Speech của người Việt – do người Việt – cho người Việt tại Việt Nam là rất hứa hẹn.
3. Kiến trúc hệ thống
Quy trình xử lý của hệ thống Text-To-Speech khác biệt đáng kể so với quá trình tạo ra lời nói của con người. Việc tạo ra lời nói của con người phụ thuộc vào cơ chế chất lỏng phức tạp phụ thuộc vào sự thay đổi áp suất phổi và co thắt đường thanh quản. Việc thiết kế các hệ thống để bắt chước các cấu trúc của con người sẽ dẫn đến sự phức tạp nhất định.
Hình dưới đây mô tả sơ đồ kiến trúc hệ thống của một hệ thống Text-To-Speech tổng quát, gồm 2 module:
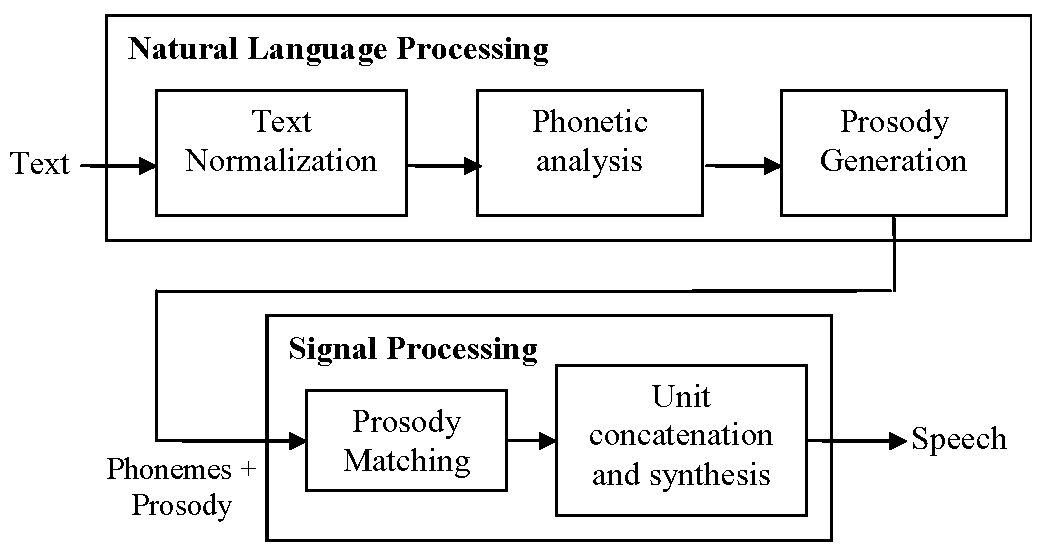
- Natural Language Processing – Xử lý ngôn ngữ tự nhiên: xử lý ngữ âm và ngữ điệu cùng với nhịp điệu và nó xuất ra bản phiên âm của văn bản đầu vào.
- Digital Signal Processing – Xử lý tín hiệu kỹ thuật số: chuyển đổi bản ghi ngữ âm nhận được thành lời nói.
4. Quá trình xử lý
Module Natural Language Processing – Xử lý ngôn ngữ tự nhiên (NLP)
Để có thể dễ hình dung hơn thì hình dưới mô tả sơ đồ của module xử lý ngôn ngữ tự nhiên
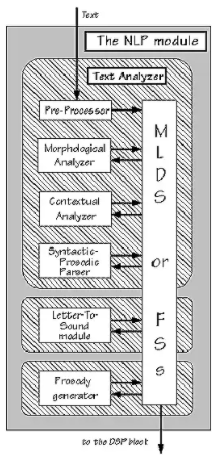
Text Analyzer - Phân tích văn bản
Khối phân tích văn bản bao gồm 4 phần cơ bản:
- Khối tiền xử lý làm nhiệm vụ xử lý sơ bộ văn bản: xóa bỏ những kí tự, những mã điều khiển, những vùng không cần thiết cho hệ thống gồm: tách đoạn/câu/từ, làm sạch, tích hợp, chuyển đổi và giảm số chiều.
- Khối phân tích hình thái học làm nhiệm vụ xác định, phân tích và miêu tả cấu trúc của hình vị và các đơn vị ý nghĩa khác như từ, phụ tố, từ loại, thanh điệu. Phân tích hình thái có thể chia thành 3 khâu xử lý:
- Phân đoạn từ vựng: phân giải câu văn thành các từ có thứ tự
- Phân loại tử: quyết định từ loại của từ vựng
- Phục hồi nguyên dạng của từ: làm trở lại nguyên dạng ban đầu của các từ vựng bị biến đổi thể hoặc được kết hợp
- Khối phân tích ngữ cảnh: chia nhỏ các câu thành các chuỗi từ nối tiếp nhau để trích xuất được ngữ cảnh của các chuỗi từ trong câu, văn bản.
- Khối phân tích cú pháp – ngôn điệu xác định cấu trúc văn bản (thành phần mệnh đề và cụm từ) liên quan chặt chẽ hơn đến việc xác định ngôn điệu.
Letter-To-Sound - Phiên âm
Khối phiên âm được sử dụng để phiên âm văn bản đã được phân tích trong khối phân tích văn bản trước đó. Điều đáng chú ý ở đây là việc phiên âm này không giống như việc tra cứu từ điển vì các từ có phiên âm khác nhau tùy thuộc vào ngữ cảnh. Ngoài ra, cách phát âm theo từ điển không tính đến các biến thể hình thái trong từ. Ngoài ra, cách phát âm của các từ trong câu khác với cách phát âm của cùng những từ đó có trong từ điển phiên âm. Kết quả là, phiên âm có thể được dựa trên từ điển hoặc dựa trên tập hợp các quy tắc phiên âm.
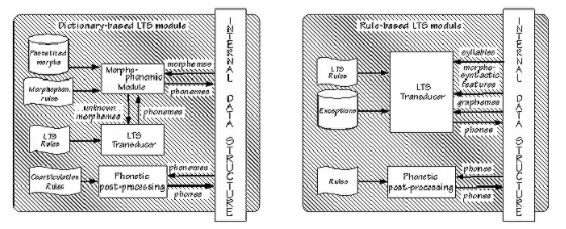
Giải pháp phiên âm dựa trên từ điển bao gồm việc lưu trữ tối đa lượng kiến thức âm vị học vào một từ điển. Sau khi thu được bản phiên âm đầu tiên của mỗi từ, một số quá trình xử lý ngữ âm thường được áp dụng với mục đích tính toán hiện tượng làm mịn. Cách tiếp cận này đã được hệ thống MITTALK tuân theo ngay từ ngày đầu tiên ra đời. Một từ điển lên đến 12.000 hình vị bao phủ khoảng 95% các từ đầu vào. Hệ thống TTS của AT&T BellLaboratories cũng tuân theo nguyên tắc tương tự, với từ điển hình vị tăng lên đến 43.000 hình vị.
Một giải pháp khác là phiên âm dựa trên hệ thống các luật. Khi gặp từ mà chưa biết cách phát âm thì cần áp dụng các luật khác nhau để tìm ra cách phát âm. Sự chuyển đổi thường được thực hiện theo từng ký tự một, từ trái qua phải. Có thể sử dụng quy tắc ngữ cảnh A[B]C - D nghĩa là nếu ký hiệu B ở sau A, trước C thì có phát âm D, hoặc là A|T B nghĩa là ký hiệu A với luật T thì được phát âm là B.
Prosody Generator - Tạo ngôn điệu
Ngôn điệu đề cập đến nhịp điệu, trọng âm và ngữ điệu của lời nói. Ngôn điệu hướng sự tập trung vào các phần cụ thể của câu, chẳng hạn như sự nhấn mạnh được đặt vào một âm tiết cụ thể, do đó gán tầm quan trọng đặc biệt hoặc tương phản với phần đó của câu. Các chức năng ngôn điệu cũng giúp phân đoạn câu thành các đoạn bao gồm các nhóm từ và âm tiết và cũng để xác định mối quan hệ giữa các đoạn đó. Khối tạo ngôn điệu chịu trách nhiệm tạo ra ngôn điệu. Tạo ra một âm thanh thuận theo tự nhiên là một trong những thách thức lớn nhất phải đối mặt trong quá trình thiết kế hệ thống chuyển đổi văn bản thành giọng nói.
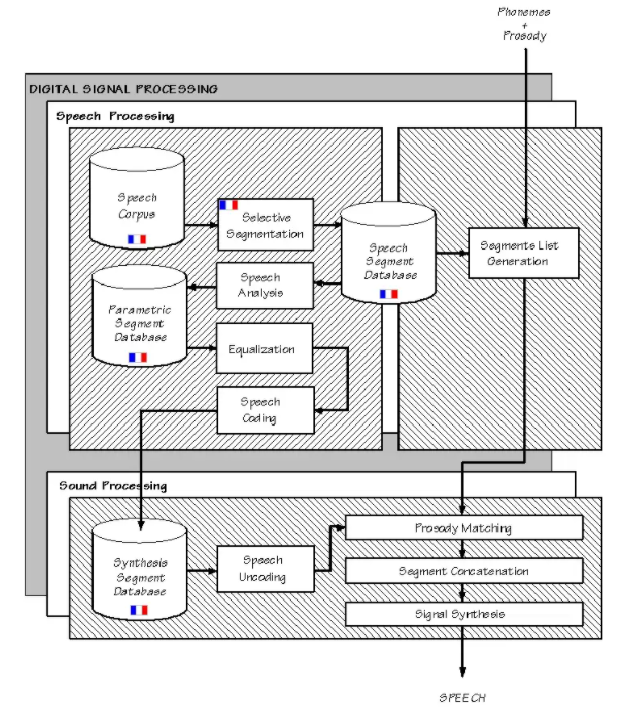
Digital Signal Processing – Xử lý tín hiệu kỹ thuật số (DSP)
Module xử lý tín hiệu số xử lý cách phát âm các từ, cụm từ và câu của máy tính thực tế, tương tự như phát âm giọng nói của con người. Quá trình này có thể được thực hiện theo hai cách: tổng hợp dựa trên quy tắc và tổng hợp ghép nối.
Tổng hợp dựa trên quy tắc
Bộ tổng hợp dựa trên quy tắc, thường là bộ tổng hợp định dạng, tạo ra giọng nói thông qua việc sửa đổi một số tham số. Các thông số như tần số cơ bản, giọng nói và mức độ tiếng ồn được sửa đổi theo thời gian để tạo ra dạng sóng giọng nói nhân tạo. Nhiều hệ thống tổng hợp giọng nói dựa trên formant tạo ra giọng nói không tự nhiên (không giống tiếng người). Số lượng lớn các tham số liên quan tạo ra các biến số trong quá trình phân tích và do đó sẽ tạo ra một số lỗi. Việc kết hợp các lỗi như vậy làm cho việc phát triển các bộ tổng hợp dựa trên quy tắc rất tốn thời gian. Mặc dù vậy, bộ tổng hợp dựa trên quy tắc phổ biến với các nhà ngữ âm học và âm vị học (ví dụ, bộ tổng hợp Klatt). Bộ tổng hợp dựa trên quy tắc thường có chương trình nhỏ hơn bộ tổng hợp nối ghép (vì bộ tổng hợp dựa trên quy tắc không dựa trên cơ sở dữ liệu của các mẫu giọng nói).
Tổng hợp ghép nối
Bộ tổng hợp ghép nối xâu chuỗi các đoạn lời nói đã ghi lại với nhau được trích xuất từ cơ sở dữ liệu các mẫu giọng nói. Kết quả là, bộ tổng hợp nối ghép tạo ra giọng nói nhân tạo có âm thanh tự nhiên nhất. Bộ tổng hợp ghép nối có hạn chế về mặt ngữ âm học của dữ liệu mà nó làm việc. Đôi khi có thể quan sát thấy sự cố âm thanh trong đầu ra của bộ tổng hợp ghép nối do sự không khớp về biên độ và âm sắc giữa các mẫu được ghép nối. Một quá trình được gọi là cân bằng được sử dụng để giảm bớt ảnh hưởng của sự không khớp về biên độ.
Trong khi tổng hợp giọng nói, bộ tổng hợp ghép nối tạo ra một chuỗi các phân đoạn được nối, được truy xuất từ cơ sở dữ liệu mẫu giọng nói của nó. Ưu điểm của các phân đoạn được điều chỉnh để phù hợp với các giá trị được suy ra từ đầu ra của module xử lý ngôn ngữ tự nhiên.
5. Ứng dụng thực tế
Công nghệ chuyển đổi văn bản thành lời nói đã phát triển trong vài thập kỷ qua. Ngày nay, trong dòng chảy của cuộc cách mạng 4.0, lời nói do máy tính tạo ra được sử dụng trong vô số các trường hợp khác nhau và trở thành một yếu tố phổ biến của giao diện người dùng. Ứng dụng của công nghệ Text-To-Speech bao phủ nhiều lĩnh vực của cuộc sống, từ giáo dục, xã hội đến truyền thông, giao thông vận tải…
Mục đích lớn nhất và dễ thấy nhất của công nghệ Text-To-Speech này mang lại chính là việc giúp cho những người gặp khó khăn trong việc đọc có thể tiếp nhận được tri thức mới. Đối với những người có vấn đề thị lực thì chắc chắn công nghệ này là rất hữu ích. Nhưng những người khó khăn trong việc đọc không chỉ đơn thuần là những người có vấn đề về thị lực mà còn bao gồm cả những người mắc hội chứng khó đọc. Những người này gặp rắc rối với việc đọc hiểu và đánh vần mặc dù thị lực và trí tuệ của họ bình thường.
Text-To-Speech còn được ứng dụng trong giáo dục, đặc biệt là trong việc học ngoại ngữ. Bất cứ một từ điển nào trên internet hay trên các thiết bị thông minh của chúng ta đều có chức năng phát âm từ mà chúng ta nhập vào trong từ điển, thậm chí là phát âm được cả một câu, một đoạn. Nó còn được ứng dụng trong các tài liệu trực tuyến, tạo điều kiện cho việc học trở nên hiệu quả hơn vì bằng cách cho phép cả hình ảnh và âm thanh cùng xuất hiện, công nghệ chuyển đổi văn bản thành giọng nói có thể giúp cải thiện khả năng hiểu, ghi nhớ, tạo ra động lực và sự tự tin cho người học.
Ngoài ra, trong lĩnh vực giao thông vận tải, Text-To-Speech cũng được áp dụng để giúp việc tham gia giao thông trở nên thông minh hơn. Ví dụ như trong hệ thống GPS và định vị, công nghệ này sẽ phát ra giọng nói để chỉ đường đến đích cho chúng ta. Hoặc trong các ứng dụng theo dõi xe buýt, tàu hỏa, máy bay theo thời gian thực, Text-To-Speech sẽ gửi thông báo về thông tin của hành trình bằng giọng nói.
6. Tổng kết
Trên đây là tổng quan về công nghệ Text-To-Speech và cách hoạt động của 1 hệ thống TTS. Hi vọng đã cung cấp cho các bạn những thông tin bổ ích!
Nguồn tham khảo
https://medium.com/sciforce/text-to-speech-synthesis-an-overview-641c18fcd35f https://core.ac.uk/download/pdf/32225276.pdf https://www.academia.edu/416871/A_Short_Introduction_to_Text_to_Speech_Synthesis
All rights reserved
