
Kafka Message Key: "Chìa khóa" để duy trì thứ tự dữ liệu.
Chào mọi người! Tiếp nối bài viết mở đầu về Kafka hôm trước, hôm nay chúng ta sẽ cùng nhau khám phá sâu hơn về Message Key - một nhân tố rất quan trọng trong việc đảm bảo thứ tự thông điệp khi truyền qua Kafka nhé!
Mở đầu
Trong thế giới của hệ thống phân tán (distributed systems), chúng ta thường bị ám ảnh bởi tính sẵn sàng (Availability) và khả năng mở rộng (Scalability). Thế nhưng, có một yếu tố "âm thầm" quyết định sự sống còn của tính đúng đắn về dữ liệu (Data Integrity), đó chính là Thứ tự (Ordering).
Bài toán:
Hãy tưởng tượng bạn đang xây dựng một hệ thống xử lý đơn hàng. Một luồng sự kiện (events) bình thường sẽ diễn ra như sau:
ORDER_CREATED(Khách hàng đặt bộ bàn phím cơ)PAYMENT_SUCCESS(Thanh toán thành công)ORDER_SHIPPED(Đang giao hàng)
Chuyện gì sẽ xảy ra nếu hệ thống của bạn (consumer) đọc ra sự kiện PAYMENT_SUCCESS trước cả khi biết đơn hàng đó tồn tại (ORDER_CREATED)? Kết quả nhẹ thì gây lỗi logic hệ thống (Race Condition), nặng thì làm sai lệch báo cáo tài chính và trải nghiệm khách hàng.
Lầm tưởng tai hại về Kafka
Nhiều người khi mới tiếp cận Kafka thường đọc lướt qua các tài liệu và tin rằng: "Kafka là một hàng đợi (queue), mà hàng đợi thì hiển nhiên là FIFO (First-In-First-Out)".
Sự thật là: Kafka chỉ đảm bảo thứ tự message trên từng Partition đơn lẻ.
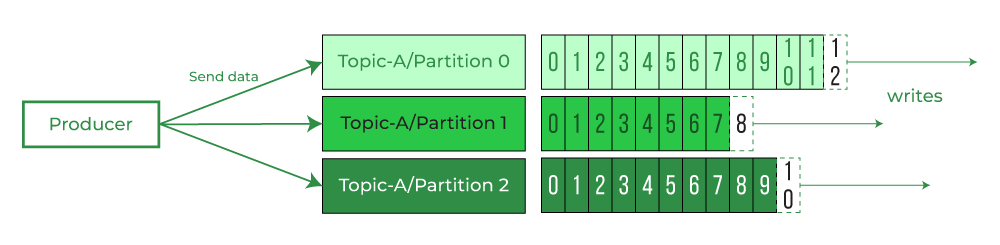
Nếu bạn gửi dữ liệu vào một Topic có 10 Partitions mà không kèm theo một chiến lược cụ thể, Kafka sẽ phân phối chúng theo chiến lược Sticky Partitioning hoặc thuật toán Round-robin. Khi đó, các sự kiện của cùng một đơn hàng sẽ bị xé lẻ ra các Partition khác nhau. Kết quả là khi Consumer đọc dữ liệu từ nhiều Partition cùng lúc, thứ tự thời gian của các sự kiện sẽ bị đảo lộn hoàn toàn.
Message Key – "Vị cứu tinh" thầm lặng
Đây chính là lúc Message Key xuất hiện. Nó không chỉ đơn thuần là một mẩu thông tin đính kèm cho có; nó đóng vai trò là "người điều hướng" (router). Bằng cách sử dụng Key một cách thông minh, chúng ta có thể ép tất cả các sự kiện liên quan đến cùng một thực thể (ví dụ: cùng một order_id) phải đi chung một con đường, vào chung một Partition.
Trong bài viết này, chúng ta sẽ cùng mổ xẻ cơ chế đằng sau "chiếc chìa khóa" này và cách tận dụng nó để duy trì tính nhất quán cho dữ liệu của bạn.
Cơ chế hoạt động: Key điều hướng dữ liệu như thế nào?
Để hiểu tại sao Key lại giúp duy trì thứ tự, chúng ta cần nhìn vào cách Producer "quyết định" gửi message đi đâu.
Khi không có Key: Thuật toán Round-robin
Nếu bạn gửi một message với key = null, mặc định Kafka Producer sẽ sử dụng chiến lược Sticky Partitioning (hoặc Round-robin ở các bản cũ).
- Cách chạy: Message 1 vào Partition 0, Message 2 vào Partition 1, Message 3 vào Partition 2...
- Hệ quả: Dữ liệu được trải đều, tối ưu hiệu suất ghi. Nhưng như đã nói ở Mục 1, các sự kiện liên quan đến cùng một khách hàng sẽ bị "lạc mất nhau" ở các phân vùng khác nhau.
Khi có Key: Phép thuật của Hashing
Khi bạn chỉ định một Key (ví dụ: customer_id: "123"), Producer không còn gửi bài ngẫu nhiên nữa. Nó thực hiện một quy trình gồm 2 bước:
- Hashing: Key sẽ được đưa qua một hàm Hash (mặc định là MurmurHash2 – một thuật toán cực nhanh và có độ phân tán cực tốt). Hàm này sẽ biến chuỗi "123" thành một con số nguyên 32-bit cố định.
- Modulo: Con số này sau đó được chia lấy dư cho tổng số Partition hiện có của Topic.
Kết quả: Miễn là số lượng Partition không đổi, thì key: "123" sẽ luôn luôn cho ra cùng một con số Partition.
Tại sao "Cùng Partition" lại đồng nghĩa với "Đúng thứ tự"?
Trong kiến trúc của Kafka, mỗi Partition thực chất là một Append-only Log.
- Dữ liệu được ghi vào cuối file theo thứ tự thời gian.
- Mỗi message có một số định danh tăng dần gọi là Offset.
- Consumer khi đọc một Partition sẽ đọc từ Offset thấp đến cao.
Vì vậy, khi chúng ta "ép" tất cả sự kiện của order_1 vào Partition 0, chúng ta đã tạo ra một hàng đợi mini dành riêng cho đơn hàng đó. Consumer sẽ đọc ORDER_CREATED trước, rồi mới tới PAYMENT_SUCCESS, không bao giờ có chuyện ngược lại.
Tính "Bất biến" của Key (Immutability)
Một điểm quan trọng cần lưu ý: Kafka không quan tâm nội dung bên trong Key là gì. Nó chỉ quan tâm đến byte array của Key đó. Điều này có nghĩa là nếu bạn thay đổi dù chỉ một dấu cách trong Key, "chìa khóa" của bạn sẽ mở ra một cánh cửa Partition hoàn toàn khác.
import { Injectable, OnModuleInit } from '@nestjs/common';
import { Client, ClientKafka, Transport } from '@nestjs/microservices';
@Injectable()
export class OrderService implements OnModuleInit {
@Client({
transport: Transport.KAFKA,
options: {
client: {
clientId: 'order-service',
brokers: ['localhost:9092'],
},
},
})
private client: ClientKafka;
async onModuleInit() {
await this.client.connect();
}
async createOrder(orderData: any) {
// Giả sử orderData có id là 'ORDER_123'
const message = {
key: orderData.id, // Đảm bảo key là string hoặc buffer
value: JSON.stringify(orderData),
};
// Gửi message kèm theo Key để Kafka hashing
return this.client.emit('order.events', message);
}
}
Khi nào nên dùng Key?
Việc lạm dụng Key có thể gây ra những vấn đề về hiệu năng (như Skewed Data), vì vậy chúng ta chỉ nên dùng Key khi bài toán thực sự đòi hỏi tính nhất quán về thứ tự. Dưới đây là 3 kịch bản điển hình:
Quản lý trạng thái thực thể
Đây là trường hợp phổ biến nhất. Trong các hệ thống Microservices, một thực thể (Entity) như Đơn hàng, Người dùng, Chuyến xe,... sẽ trải qua nhiều thay đổi trạng thái.
- Key:
order_idhoặccustomer_id. - Tại sao: Để đảm bảo sự kiện
CANCELLEDkhông bao giờ được xử lý trước sự kiệnCREATED. Khi tất cả sự kiện của cùng mộtorder_idnằm chung một Partition, Consumer sẽ cập nhật trạng thái vào Database theo đúng trình tự thời gian thực tế đã xảy ra.
Đồng bộ hóa cơ sở dữ liệu
Khi bạn muốn đồng bộ dữ liệu từ SQL Server/MySQL sang một hệ thống khác (như Elasticsearch hoặc Data Warehouse) thông qua Kafka.
- Key: Primary Key của bảng dữ liệu (ví dụ: user_id).
- Tại sao: Trong Database, bạn có thể Update một bản ghi nhiều lần. Nếu các bản ghi Update này nhảy sang các Partition khác nhau, hệ thống đích (Downstream) có thể nhận được dữ liệu cũ sau dữ liệu mới, dẫn đến việc ghi đè sai dữ liệu (Data Inconsistency). Dùng Primary Key làm Message Key giúp đảm bảo "phiên bản cuối cùng" luôn là phiên bản mới nhất.
Event Sourcing và Hệ thống Tài chính (Banking/Ledger)
Trong kiến trúc Event Sourcing, trạng thái hiện tại của một đối tượng không được lưu trực tiếp mà được tính toán bằng cách "re-play" (chạy lại) toàn bộ lịch sử các sự kiện của đối tượng đó từ đầu chí cuối.
- Key:
account_id(Số tài khoản) hoặcwallet_id(Mã ví điện tử). - Tại sao: Hãy tưởng tượng tài khoản của bạn có 0đ. Sự kiện 1:
DEPOSIT_100$(Nạp 100$). Sự kiện 2:WITHDRAW_50$(Rút 50$). Nếu consumer đọc nhầm sự kiện rút tiền trước, hệ thống sẽ báo lỗi "Tài khoản không đủ số dư" và chặn giao dịch ngay lập tức. Việc ápaccount_idlàm Key là bắt buộc để đảm bảo số dư tài khoản luôn được tính toán chính xác.
Mặt tối của Message Key
Hiểu được sức mạnh của Message Key là tốt, nhưng nếu dùng sai cách, bạn sẽ tự tay "bóp nghẹt" hệ thống của chính mình.
Bài toán thực tế:
Giả sử bạn làm hệ thống e-commerce và chọn country_code (Mã quốc gia) làm Message Key để scale hệ thống ra toàn cầu.
Topic của bạn có 4 partitions.
80% khách hàng của bạn đến từ Việt Nam (VN), 20% còn lại chia đều cho US, SG, JP.
Do thuật toán Hashing là cố định, toàn bộ message có key VN sẽ bị đẩy hết vào Partition 0. Kết quả là Partition 0 luôn trong tình trạng "quá tải", CPU tăng cao, consumer đọc không kịp dẫn đến nghẽn (Lag). Trong khi đó, Partition 1, 2, 3 thì lại quá "thảnh thơi". Lúc này, kiến trúc phân tán của Kafka hoàn toàn mất tác dụng.
Bài học rút ra: Khi chọn Message Key, hãy chọn những trường có độ phân tán cao (High Cardinality) như order_id, user_id, transaction_id. Tránh chọn các trường có số lượng giá trị hữu hạn và chênh lệch lớn như gender, status, country.
Lưu ý khi thay đổi số lượng partition trong 1 topic
Có một quy tắc trong công thức tính Partition mà chúng ta đã xem ở Mục 2:
Hãy chú ý vào biến . Chuyện gì xảy ra nếu hôm nay hệ thống của bạn quá tải, và bạn quyết định tăng số lượng Partition của Topic từ 3 lên 6?
- Trước khi tăng: MurmurHash2("ORDER_123") ra một con số, đem thì kết quả ra Partition 1.
- Sau khi tăng: Vẫn là MurmurHash2("ORDER_123") đó, nhưng bây giờ phải . Kết quả đột ngột biến thành Partition 4.
Hệ quả kinh hoàng: Kể từ thời điểm bạn tăng Partition, các sự kiện mới của ORDER_123 sẽ bị nhảy sang Partition 4, trong khi các sự kiện cũ vẫn đang nằm ở Partition 1 và chưa chắc đã được consumer đọc hết. Thứ tự dữ liệu của ORDER_123 chính thức bị phá vỡ!
Giải pháp: Hãy tính toán và thiết kế số lượng Partition đủ dùng cho tương lai ngay từ đầu. Nếu bắt buộc phải tăng Partition cho một Topic đang chạy sản xuất (Production), bạn sẽ phải tạo một Topic mới với số Partition mới, sau đó dùng một bộ kiến trúc chuyển đổi dữ liệu (MirrorMaker hoặc viết một ứng dụng bridge tự chế) để điều hướng, chấp nhận một khoảng thời gian downtime hoặc lag nhất định để xử lý nốt dữ liệu cũ.
Lời kết
Message Key trong Kafka giống như một con dao hai lưỡi. Nó là "vị cứu tinh" giúp bạn giải quyết triệt để bài toán thứ tự dữ liệu – một trong những bài toán đau đầu nhất của hệ thống phân tán. Thế nhưng, nó cũng đòi hỏi người kỹ sư phải có một cái đầu lạnh để chọn Key sao cho có độ phân tán tốt, và một tầm nhìn xa để cấu hình số lượng Partition hợp lý ngay từ ngày đầu bấm nút deploy.
Hy vọng bài viết này đã giúp bạn vén được bức màn bí mật về cơ chế hoạt động của Message Key. Ở bài viết tiếp theo, mình sẽ cùng các bạn tìm hiểu về Consumer Group và cơ chế Rebalance – một khái niệm cũng thú vị không kém nhé!
All rights reserved
