
Information Retrieval: Kết hợp kết quả của nhiều mô hình ranking (RRF)
Trong lĩnh vực Information Retrieval, ranking là một phần quan trọng. Nó giúp ưu tiên các kết quả có liên quan hơn. Trong nhiều trường hợp, sử dụng duy nhất một mô hình ranking có thể không phù hợp với những yêu cầu phong phú từ người dùng. Chính vì cậy, ý tưởng về kết hợp các kết quả ranking ra đời. Việc kết hợp kết quả từ nhiều mô hình ranking sẽ làm tăng độ chính xác của retrival. Trong bài viết này tôi sẽ đề cập đến một thuật toán giúp kết hợp kết quả ranking gọi là Reciprocal Rank Fusion (RRF). Thuật toán này được sử dụng khá phổ biến, và đặc biệt không yêu cầu phải tuning tham số.
Giới thiệu vài nét về bài toán Information retrieval
Về bài toán Information retrieval, đầu vào sẽ là một query (có thể là ảnh, hoặc là văn bản), đầu ra là danh sách các documents có liên quan đến query đó, thường được sắp xếp từ liên quan nhất đến ít liên quan nhất. Thông thường để giải quyết bài toán này, các mô hình ranking được sử dụng để ranking độ liên quan của các documents để trả về kết quả. Mỗi mô hình ranking thường sẽ có những ưu nhược điểm riêng, nên việc kết hợp chúng lại hứa hẹn sẽ làm tăng độ chính xác của kết quả.
Reciprocal Rank Fusion
li RRF hoạt động dựa trên việc thu thập kết quả của nhiều phương pháp ranking, gán cho mỗi document trong kết quả một reciprocal rank score, và sau đó kết hợp những score đó tạo thành thứ tự rank mới. Nguyên tắc là document hay xuất hiện với vị trí đầu trong nhiều chiến lược retrieval sẽ nhận được thứ hạng cao trong kết quả tổng hợp.
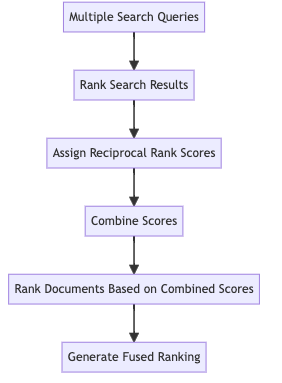
Cụ thể, có thể chia RRF thành các bước nhỏ như sau:
-
Thu thập kết quả ranking từ nhiều nhiều mô hình ranking. Ví dụ: đối với text, muốn tìm kiếm document có tiêu đề là "Một ngày đẹp trời", và nội dung tóm tắt là "Ngày đẹp trời gồm có: ngày nhận lương, ngày ăn ngon, ngày ngủ đủ giấc", trong tập hợp các documents có dạng tương tự.
- tiêu đề sẽ được dùng với phương pháp text search, kết quả trả ra (một danh sách các documents được sắp xếp từ liên quan nhất đến ít liên quan) sẽ được thu thập.
- nội dung tóm tắt sẽ được dùng phương pháp vector search, kết quả trả ra (một danh sách các documents được sắp xếp từ liên quan nhất đến ít liên quan) sẽ được thu thập.
Lưu ý từ tác giả: nội dung query có thể khác nhau (như ví dụ trên), hoặc giống nhau, tùy vào mục đích của từng bài toán cụ thể.
-
Gán reciprocal rank score cho từng document trong từng danh sách kết quả. Reciprocal rank score được tính dựa trên vị trí của document trong kết quả trả về. Công thức: . Trong đó, là vị trí của document trong kết quả trả về, là một hằng số, thông thường được chọn giá trị bằng .
-
Kết hợp scores. Đối với mỗi document, reciprocal rank scores cho từng phương pháp search sẽ được cộng lại, từ đó tạo thành score mới cho từng document
-
Re-rank. Score mới được tạo ra từ bước 3, sẽ được dùng để sắp xếp lại độ liên quan của các document.
Ta có thể tóm gọn các bước trên bằng sơ đồ như sau:
Implement RRF
Python code cho RRF
database = { # assuming your queries and results are stored in a dictionary
'query1': ['doc1', 'doc2', 'doc3'],
'query2': ['doc3', 'doc1', 'doc2'],
# more queries and their document results...
}
def result_func(q):
return database[q]
def rank_func(results, d):
return results.index(d) + 1 # adding 1 because ranks start from 1
def reciprocal_rank_fusion(queries, d, k, result_func, rank_func):
return sum([1.0 / (k + rank_func(result_func(q), d)) if d in result_func(q) else 0 for q in queries])
Các sử dụng
k = 5
d1 = 'doc1'
d2 = 'doc2'
queries = ['query1', 'query2'] # fill this with your actual query keys
print(reciprocal_rank_fusion(queries, d1, k, result_func, rank_func))
# Expected output: 0.30952380952380953
print(reciprocal_rank_fusion(queries, d2, k, result_func, rank_func))
# Expected output: 0.26785714285714285
# Score of d1 is higher than d2, which is expected because d1 is ranked higher in both queries
Kết luận
Phương pháp RRF được đánh giá là công cụ mạnh mẽ trong lĩnh vực Information Retrieval, đặc biệt được sử dụng nhiều trong Retrieval Augmented Generation (RAG).
Nhận xét chủ quan của tác giả: phương pháp này không tận dụng được score của từng search tool tạo ra combined score. Score của từng seach tool là gì ? Ví dụ, nếu dùng vector search, cụ thể là dùng Bert để tạo ra embedding vector, và dùng cosine similarity để tạo ra score từ đó ranking. Thì ta có thể coi cosine similarity là score của search tool này.
Tài liệu tham khảo
All rights reserved
