Hướng dẫn toàn diện về Trí tuệ nhân tạo với Python (Dịch.p4)
Bài đăng này đã không được cập nhật trong 6 năm
Nguồn: Edureka
Ở phần 3 chúng ta đã tìm hiểu qua 8 chủ đề:
- Machine Learning With Python
- Limitations Of Machine Learning
- Why Deep Learning?
- How Deep Learning Works?
- What Is Deep Learning?
- Deep Learning Use Case
- Perceptrons
- Multilayer Perceptrons
TIếp theo ở phần này, chúng ta sẽ tìm hiểu tiếp các chủ đề còn lại:
- Deep Learning With Python
- Introduction To Natural Language Processing (NLP)
- NLP Applications
- Terminologies In NLP
17. Deep Learning With Python
Để tóm tắt cách thức hoạt động của Deep Learning, chúng ta hãy xem xét triển khai Deep Learning với Python.
Problem Statement (Báo cáo sự cố): Để nghiên cứu bộ dữ liệu tín dụng ngân hàng và xác định xem giao dịch có lừa đảo hay không dựa trên dữ liệu trong quá khứ.
Data Set Description (Mô tả tập dữ liệu): Tập dữ liệu mô tả các giao dịch được thực hiện bởi chủ thẻ châu Âu trong năm 2013. Nó chứa các chi tiết giao dịch trong hai ngày, trong đó có 492 hoạt động gian lận trong số 284.807 giao dịch.
Logic: Để xây dựng Mạng thần kinh có thể phân loại giao dịch là lừa đảo hoặc không dựa trên các giao dịch trong quá khứ.
Bây giờ bạn đã biết mục tiêu của bản demo này, hãy bắt đầu với bản demo.
Bước 1: Nhập các gói cần thiết

Bước 2: Tải tập dữ liệu
Tải file creditcard_csv.csv hoặc creditcard.csv


Trong phần mô tả ở trên, biến mục tiêu là biến Class. Nó có thể chứa hai giá trị:
- Class 0: Biểu thị rằng giao dịch không lừa đảo
- Class 1: Biểu thị rằng giao dịch là lừa đảo
Các biến còn lại là các biến dự đoán sẽ giúp chúng tôi hiểu liệu giao dịch có lừa đảo hay không.
...
print(df_full.Class.value_counts())
0 284315
1 492
Name: Class, dtype: int64
Kết quả trên cho thấy chúng tôi có khoảng 284k giao dịch không gian lận và '492' giao dịch gian lận. Sự khác biệt giữa hai lớp là rất lớn và điều này làm cho tập dữ liệu của chúng tôi rất mất cân bằng. Do đó, chúng tôi phải lấy mẫu dữ liệu của mình theo cách sao cho số lượng giao dịch gian lận để không gian lận được cân bằng.
Đối với điều này, chúng ta có thể sử dụng một kỹ thuật lấy mẫu thống kê được gọi là Lấy mẫu phân tầng.
Bước 3: Chuẩn bị dữ liệu
...
#Sort the dataset by "class" to apply stratified sampling
df_full.sort_values(by='Class', ascending=False, inplace=True)
Tiếp theo, chúng ta sẽ loại bỏ cột thời gian vì không cần thiết để dự đoán đầu ra.
# Remove the "Time" coloumn
df_full.drop('Time', axis=1, inplace=True)
# Create a new data frame with the first "3000" samples
df_sample = df_full.iloc[:3000, :]
# Now count the number of samples for each class
print(df_sample.Class.value_counts())
0 2508
1 492
Name: Class, dtype: int64
Tập dữ liệu của chúng tôi có vẻ cân bằng tốt bây giờ.
#Randomly shuffle the data set
shuffle_df = shuffle(df_sample, random_state=42)
Bước 4: Nối dữ liệu
Nối dữ liệu là quá trình phân tách tập dữ liệu thành dữ liệu huấn luyện và kiểm tra.
# Spilt the dataset into train and test data frame
df_train = shuffle_df[0:2400]
df_test = shuffle_df[2400:]
# Spilt each dataframe into feature and label
train_feature = np.array(df_train.values[:, 0:29])
train_label = np.array(df_train.values[:, -1])
test_feature = np.array(df_test.values[:, 0:29])
test_label = np.array(df_test.values[:, -1])
# Display the size of the train dataframe
print(train_feature.shape)
(2400, 29)
# Display the size of test dataframe
print(train_label.shape)
(2400,)
Bước 5: Chuẩn hóa dữ liệu
# A function to plot the learning curves
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()
Bước 6: Xây dựng Neural Network (mạng lưới thần kinh)
Trong bản demo này, chúng tôi sẽ xây dựng một mạng lưới thần kinh chứa 3 lớp được kết nối đầy đủ với Dropout. Lớp thứ nhất và thứ hai có 200 đơn vị nơ-ron với chức năng kích hoạt ReLU và lớp thứ ba tức là lớp đầu ra có một đơn vị nơ-ron duy nhất.
Để xây dựng mạng lưới thần kinh, chúng tôi sẽ sử dụng Gói Keras mà chúng tôi đã thảo luận trước đó. Kiểu mô hình sẽ tuần tự, đây là cách dễ nhất để xây dựng mô hình trong Keras. Trong một mô hình tuần tự, mỗi lớp được gán các trọng số theo cách sao cho các trọng số trong lớp tiếp theo, tương ứng với lớp trước đó.
#Select model type
model = Sequential()
Tiếp theo, chúng ta sẽ sử dụng hàm add () để thêm các Dense Layers. "Dense" là loại lớp cơ bản nhất hoạt động cho hầu hết các trường hợp. Tất cả các nút trong một lớp dày đặc được thiết kế sao cho các nút trong lớp trước kết nối với các nút trong lớp hiện tại.
# Adding a Dense layer with 200 neuron units and ReLu activation function
model.add(Dense(units=200,
input_dim=29,
kernel_initializer='uniform',
activation='relu'))
# Add Dropout
model.add(Dropout(0.5))
Dropout à một kỹ thuật chính quy được sử dụng để tránh quá mức trong mạng lưới thần kinh. Trong kỹ thuật này, nơi các tế bào thần kinh được lựa chọn ngẫu nhiên được thả trong quá trình đào tạo.
# Second Dense layer with 200 neuron units and ReLu activation function
model.add(Dense(units=200,
kernel_initializer='uniform',
activation='relu'))
# Add Dropout
model.add(Dropout(0.5))
# The output layer with 1 neuron unit and Sigmoid activation function
model.add(Dense(units=1,
kernel_initializer='uniform',
activation='sigmoid'))
# Display the model summary
print(model.summary())
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 200) 6000
_________________________________________________________________
dropout_1 (Dropout) (None, 200) 0
_________________________________________________________________
dense_2 (Dense) (None, 200) 40200
_________________________________________________________________
dropout_2 (Dropout) (None, 200) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 201
=================================================================
Total params: 46,401
Trainable params: 46,401
Non-trainable params: 0
Để tối ưu hóa, chúng tôi sẽ sử dụng trình tối ưu hóa Adam (tích hợp sẵn với Keras). Tối ưu hóa được sử dụng để cập nhật các giá trị của các thông số trọng lượng và bais trong quá trình đào tạo mô hình.
# Using 'Adam' to optimize the Accuracy matrix
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
# Fit the model
# number of epochs = 200 and batch size = 500
train_history = model.fit(x=train_feature_trans, y=train_label,
validation_split=0.8, epochs=200,
batch_size=500, verbose=2)
Train on 479 samples, validate on 1921 samples
Epoch 1/200
- 1s - loss: 0.6916 - acc: 0.5908 - val_loss: 0.6825 - val_acc: 0.8360
Epoch 2/200
- 0s - loss: 0.6837 - acc: 0.7933 - val_loss: 0.6717 - val_acc: 0.8360
Epoch 3/200
- 0s - loss: 0.6746 - acc: 0.7996 - val_loss: 0.6576 - val_acc: 0.8360
Epoch 4/200
- 0s - loss: 0.6628 - acc: 0.7996 - val_loss: 0.6419 - val_acc: 0.8360
Epoch 5/200
- 0s - loss: 0.6459 - acc: 0.7996 - val_loss: 0.6248 - val_acc: 0.8360
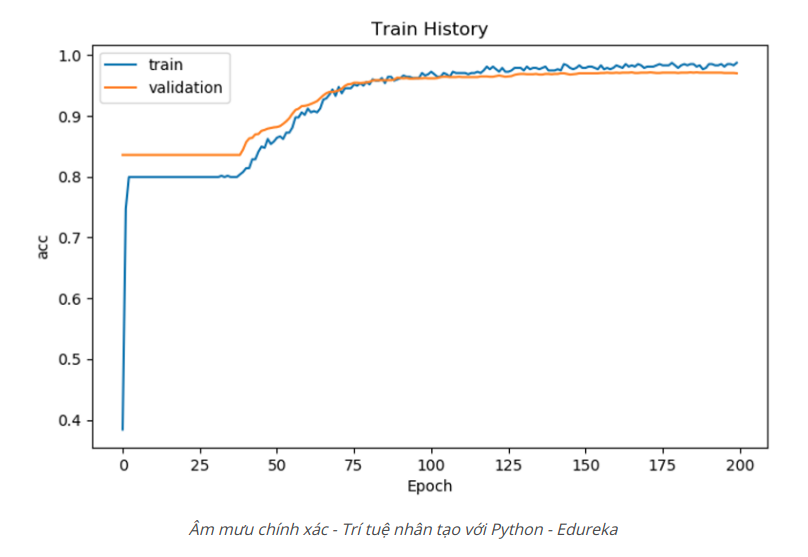
# Display the accuracy curves for training and validation sets
show_train_history(train_history, 'acc', 'val_acc')
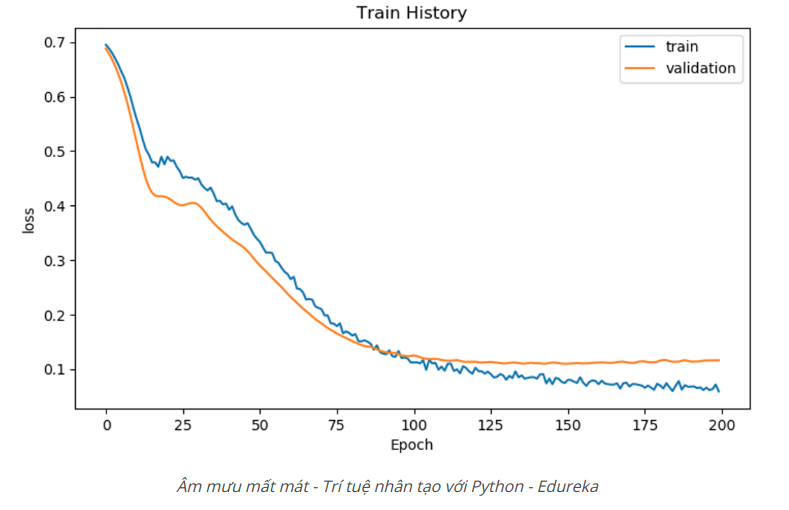
# Display the loss curves for training and validation sets
show_train_history(train_history, 'loss', 'val_loss')
Bước 7: Đánh giá mô hình
# Testing set for model evaluation
scores = model.evaluate(test_feature_trans, test_label)
# Display accuracy of the model
print('n')
print('Accuracy=', scores[1])
Accuracy= 0.98
prediction = model.predict_classes(test_feature_trans)
df_ans = pd.DataFrame({'Real Class': test_label})
df_ans['Prediction'] = prediction
df_ans['Prediction'].value_counts()
df_ans['Real Class'].value_counts()
cols = ['Real_Class_1', 'Real_Class_0'] # Gold standard
rows = ['Prediction_1', 'Prediction_0'] # Diagnostic tool (our prediction)
B1P1 = len(df_ans[(df_ans['Prediction'] == df_ans['Real Class']) & (df_ans['Real Class'] == 1)])
B1P0 = len(df_ans[(df_ans['Prediction'] != df_ans['Real Class']) & (df_ans['Real Class'] == 1)])
B0P1 = len(df_ans[(df_ans['Prediction'] != df_ans['Real Class']) & (df_ans['Real Class'] == 0)])
B0P0 = len(df_ans[(df_ans['Prediction'] == df_ans['Real Class']) & (df_ans['Real Class'] == 0)])
conf = np.array([[B1P1, B0P1], [B1P0, B0P0]])
df_cm = pd.DataFrame(conf, columns=[i for i in cols], index=[i for i in rows])
f, ax = plt.subplots(figsize=(5, 5))
sns.heatmap(df_cm, annot=True, ax=ax, fmt='d')
plt.show()

# Making x label be on top is common in textbooks.
ax.xaxis.set_ticks_position('top')
print('Total number of test cases: ', np.sum(conf))
Total number of test cases: 600
# Model summary function
def model_efficacy(conf):
total_num = np.sum(conf)
sen = conf[0][0] / (conf[0][0] + conf[1][0])
spe = conf[1][1] / (conf[1][0] + conf[1][1])
false_positive_rate = conf[0][1] / (conf[0][1] + conf[1][1])
false_negative_rate = conf[1][0] / (conf[0][0] + conf[1][0])
print('Total number of test cases: ', total_num)
Total number of test cases: 600
print('G = gold standard, P = prediction')
# G = gold standard; P = prediction
print('G1P1: ', conf[0][0])
print('G0P1: ', conf[0][1])
print('G1P0: ', conf[1][0])
print('G0P0: ', conf[1][1])
print('--------------------------------------------------')
print('Sensitivity: ', sen)
print('Specificity: ', spe)
print('False_positive_rate: ', false_positive_rate)
print('False_negative_rate: ', false_negative_rate)
Đầu ra:
G = gold standard, P = prediction
G1P1: 74
G0P1: 5
G1P0: 7
G0P0: 514
--------------------------------------------------
Sensitivity: 0.9135802469135802
Specificity: 0.9865642994241842
False_positive_rate: 0.009633911368015413
False_negative_rate: 0.08641975308641975
Như bạn có thể thấy chúng tôi đã đạt được độ chính xác 98%, điều này thực sự tốt.
Vì vậy, đó là tất cả cho Bản demo Deep Learning.
Bây giờ, hãy tập trung vào mô-đun cuối cùng nơi tôi sẽ giới thiệu Xử lý ngôn ngữ tự nhiên.
18. Introduction To Natural Language Processing (NLP)
Bạn hiểu Xử lý ngôn ngữ tự nhiên như thế nào?
Xử lý ngôn ngữ tự nhiên (NLP) là khoa học thu được những hiểu biết hữu ích từ văn bản ngôn ngữ tự nhiên để phân tích văn bản và khai thác văn bản.
NLP sử dụng các khái niệm về khoa học máy tính và Trí tuệ nhân tạo để nghiên cứu dữ liệu và rút ra thông tin hữu ích từ nó. Đó là những gì máy tính và điện thoại thông minh sử dụng để hiểu ngôn ngữ của chúng tôi, cả nói và viết.
Trước khi chúng tôi hiểu NLP được sử dụng ở đâu, hãy để tôi xóa bỏ một quan niệm sai lầm phổ biến. Mọi người thường có xu hướng bị nhầm lẫn giữa Khai thác văn bản (Text Mining) và NLP.
Sự khác biệt giữa Khai thác văn bản (Text Mining) và NLP là gì?
- Khai thác văn bản là quá trình lấy thông tin hữu ích từ văn bản.
- Xử lý ngôn ngữ tự nhiên là một kỹ thuật được sử dụng để thực hiện khai thác văn bản và phân tích văn bản.
Do đó, chúng ta có thể nói rằng Văn bản Khai thác có thể được thực hiện bằng cách sử dụng các phương pháp NLP khác nhau.
Bây giờ hãy hiểu NLP được sử dụng ở đâu.
19. Natural Language Processing Applications
Dưới đây là danh sách các ứng dụng trong thế giới thực sử dụng các kỹ thuật NLP:
- Phân tích tình cảm (Sentimental Analysis): Bằng cách triển khai các gã khổng lồ NLP Tech như Amazon và Netflix, hiểu rõ hơn về khách hàng của họ để nâng cao sản phẩm của họ và đưa ra khuyến nghị tốt hơn.
- Chatbot: Chatbots đang trở nên phổ biến trong lĩnh vực dịch vụ khách hàng. Một ví dụ phổ biến là Eva chatbot HDFC đã giải quyết hơn 3 triệu truy vấn của khách hàng, tương tác với hơn nửa triệu người dùng duy nhất và tổ chức hơn một triệu cuộc hội thoại.
- Nhận dạng giọng nói (Speech Recognition): NLP đã được sử dụng rộng rãi trong nhận dạng giọng nói, tất cả chúng ta đều biết về Alexa, Siri, trợ lý Google và Cortana. Chúng đều là các ứng dụng của NLP.
- Dịch máy (Machine Translation): Trình dịch phổ biến của Google sử dụng Xử lý ngôn ngữ tự nhiên để xử lý và dịch một ngôn ngữ này sang ngôn ngữ khác. Nó cũng được sử dụng trong trình kiểm tra chính tả, tìm kiếm từ khóa, khai thác thông tin.
- Kết hợp quảng cáo(Advertisement Matching): NLP cũng được sử dụng trong kết hợp quảng cáo để đề xuất quảng cáo dựa trên lịch sử tìm kiếm.
Bây giờ hãy hiểu các khái niệm quan trọng trong NLP.
20. Thuật ngữ trong xử lý ngôn ngữ tự nhiên
Trong phần này, tôi sẽ đề cập đến tất cả các thuật ngữ cơ bản theo NLP. Các quy trình sau đây được sử dụng để phân tích ngôn ngữ tự nhiên để rút ra một số hiểu biết có ý nghĩa:
Tokenization (Mã thông báo)
Token hóa về cơ bản có nghĩa là chia nhỏ dữ liệu thành các phần nhỏ hơn hoặc mã thông báo, để chúng có thể được phân tích dễ dàng.
Ví dụ: câu 'Mã thông báo rất đơn giản' có thể được chia thành các mã thông báo sau:
- Mã thông báo
- Chúng tôi
- Đơn giản
Bằng cách thực hiện mã thông báo, bạn có thể hiểu tầm quan trọng của từng mã thông báo trong một câu.
Stemming (Xuất phát)
Xuất phát là quá trình cắt bỏ các tiền tố và hậu tố của từ và chỉ tính đến từ gốc.
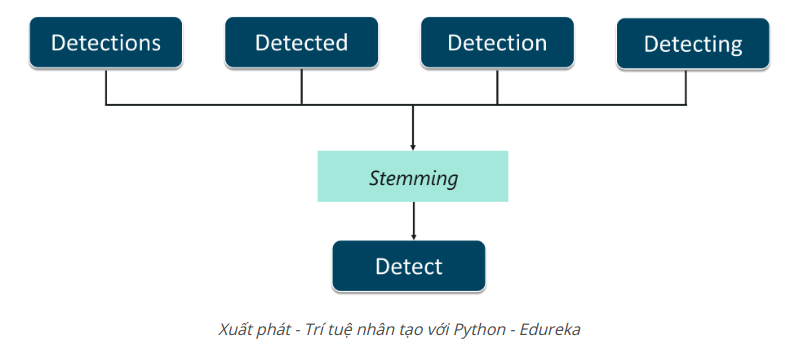
Hãy hiểu điều này với một ví dụ. Như thể hiện trong hình, các từ:
- Detection
- Detecting
- Detected
- Detections
tất cả có thể được cắt bớt từ gốc của chúng, tức là Detect. Stemming giúp chỉnh sửa các từ như vậy để việc phân tích tài liệu trở nên đơn giản hơn. Tuy nhiên, quá trình này có thể thành công trong một số dịp. Do đó, một quá trình khác gọi là Lemmatization được sử dụng.
Lemmatization (Bổ ngữ)
Lemmatization tương tự như Stemming, tuy nhiên, nó hiệu quả hơn vì phải xem xét phân tích hình thái của các từ. Đầu ra của từ vựng là một từ thích hợp.
Một ví dụ về Lemmatization là các từ gone, going, và went, được bắt nguồn từ từ’ go bằng cách sử dụng từ vựng.
Stop Words (Từ dừng)
Stop Words là một tập hợp các từ thường được sử dụng trong bất kỳ ngôn ngữ nào. Các Stop Words là rất quan trọng để phân tích văn bản và phải được loại bỏ để hiểu rõ hơn bất kỳ tài liệu nào. Logic là nếu các từ thường được sử dụng được xóa khỏi tài liệu thì chúng ta có thể tập trung vào các từ quan trọng nhất.

Ví dụ, hãy nói rằng bạn muốn làm một ly sữa dâu. Nếu bạn mở google và gõ how to make a strawberry milkshake bạn sẽ nhận được kết quả how to make a strawberry milkshake. Mặc dù bạn chỉ muốn kết quả cho một ly sữa dâu. Những từ này được gọi là từ dừng. Nó luôn luôn tốt nhất để loại bỏ những từ như vậy trước khi thực hiện bất kỳ phân tích.
Nếu bạn muốn tìm hiểu thêm về Xử lý ngôn ngữ tự nhiên, bạn có thể xem video này bởi các chuyên gia NLP của chúng tôi.
Như vậy, chúng ta đã kết thúc Artificial Intelligence With Python Blog . Nếu bạn muốn tìm hiểu thêm về Trí tuệ nhân tạo, bạn có thể đọc các blog này:
All rights reserved
