Hướng dẫn toàn diện về Trí tuệ nhân tạo với Python (Dịch.p3)
Bài đăng này đã không được cập nhật trong 6 năm
Nguồn: Edureka
Ở phần 2 chúng ta đã tìm hiểu qua 4 chủ đề:
- Machine Learning Basics
- Types Of Machine Learning
- Types Of Problems Solved By Using Machine Learning
- Machine Learning Process
TIếp theo ở phần này, cúng ta sẽ tìm hiểu tiếp các chủ đề sau:
- Machine Learning With Python
- Limitations Of Machine Learning
- Why Deep Learning?
- How Deep Learning Works?
- What Is Deep Learning?
- Deep Learning Use Case
- Perceptrons
- Multilayer Perceptrons
9. Machine Learning With Python
Trong phần này, chúng tôi sẽ triển khai Machine Learning bằng cách sử dụng Python. Hãy bắt đầu nào.
Problem Statement (Báo cáo sự cố): Để xây dựng mô hình Machine Learning, dự đoán ngày mai có mưa hay không bằng cách nghiên cứu dữ liệu trong quá khứ.
Data Set Description (Mô tả tập dữ liệu): Tập dữ liệu này chứa khoảng 145k quan sát về điều kiện thời tiết hàng ngày như được quan sát từ nhiều trạm thời tiết ở Úc. Tập dữ liệu có khoảng 24 tính năng và chúng tôi sẽ sử dụng 23 tính năng (biến dự đoán Predictor variables) để dự đoán biến mục tiêu (target variable), đó là “RainTomorrow”.
Tải tập dữ liệu weatherAUS: ở đây.
Biến mục tiêu này (RainTomorrow) sẽ lưu trữ hai giá trị:
- Yes: Biểu thị rằng trời sẽ mưa vào ngày mai
- No: Biểu thị trời sẽ không mưa vào ngày mai
Do đó, đây rõ ràng là một vấn đề phân loại (classification problem). Mô hình Machine Learning sẽ phân loại đầu ra thành 2 lớp, YES hoặc NO.
Logic: Xây dựng các mô hình Phân loại (Classification models) để dự đoán ngày mai trời sẽ mưa hay không dựa trên các điều kiện thời tiết.
Bây giờ mục tiêu đã rõ ràng, hãy để bộ não của chúng ta hoạt động và bắt đầu viết mã.
Bước 1: Nhập các thư viện cần thiết
# AI/main.py
# For linear algebra
import numpy as np
# For data processing
import pandas as pd
Bước 2: Tải tập dữ liệu
#AI/main.py
import ...
#Load the data set
df = pd.read_csv('./weatherAUS.csv')
#Display the shape of the data set
print('Size of weather data frame is :',df.shape)
#Display data
print(df[0:5])
Chạy lệnh python main.py sẽ hiển thị kết quả:

Bước 3: Xử lý dữ liệu
#AI/main.py
# Checking for null values
print(df.count().sort_values())
Và kết quả:
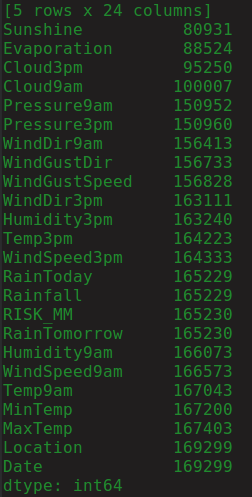
Lưu ý đầu ra, nó cho thấy bốn cột đầu tiên có hơn 40% giá trị null, do đó, tốt nhất là nếu chúng ta thoát khỏi các cột này.
Trong quá trình tiền xử lý dữ liệu luôn cần phải loại bỏ các biến không đáng kể. Dữ liệu không cần thiết sẽ chỉ làm tăng tính toán của chúng tôi. Do đó, chúng tôi sẽ xóa biến 'vị trí' và biến 'ngày' vì chúng không có ý nghĩa trong việc dự đoán thời tiết.
Chúng tôi cũng sẽ xóa biến 'RISK_MM' vì chúng tôi muốn dự đoán 'RainTomorrow' và RISK_MM (lượng mưa vào ngày hôm sau) có thể rò rỉ một số thông tin cho mô hình của chúng tôi.
#AI/main.py
...
df = df.drop(columns=['WindDir3pm', 'WindDir9am', 'WindGustDir', 'Sunshine','Evaporation','Cloud3pm','Cloud9am','Location','RISK_MM','Date'],axis=1)
print(df.shape)
(169299, 17)
Tiếp theo, chúng tôi sẽ xóa tất cả các giá trị null trong khung dữ liệu của chúng tôi.
#AI/main.py
...
#Removing null values
df = df.dropna(how='any')
print(df.shape)
(130840, 17)
Sau khi loại bỏ các giá trị null, chúng tôi cũng phải kiểm tra tập dữ liệu của chúng tôi xem có bất kỳ ngoại lệ nào không. Một ngoại lệ là một điểm dữ liệu khác biệt đáng kể so với các quan sát khác. Các ngoại lệ thường xảy ra do tính toán sai trong khi thu thập dữ liệu.
Trong đoạn mã dưới đây, chúng tôi sẽ loại bỏ các ngoại lệ:
#AI/main.py
import ...
from scipy import stats
...
z = np.abs(stats.zscore(df._get_numeric_data()))
print(z)
df= df[(z < 3).all(axis=1)]
print(df.shape)
Kết quả ghi được:
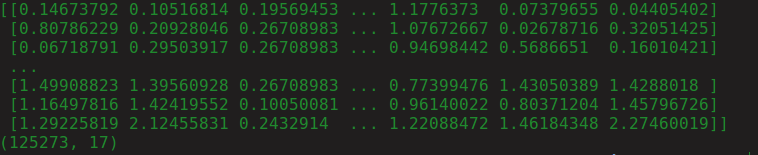
Tiếp theo, chúng tôi sẽ chỉ định 0s và 1s ở vị trí của CÓ và KHÔNG.
#AI/main.py
...
#Change yes and no to 1 and 0 respectvely for RainToday and RainTomorrow variable
df['RainToday'].replace({'No': 0, 'Yes': 1},inplace = True)
df['RainTomorrow'].replace({'No': 0, 'Yes': 1},inplace = True)
Bây giờ, thời gian chuẩn hóa dữ liệu để tránh bất kỳ sự bực bội nào trong khi dự đoán kết quả. Để làm điều này, chúng ta có thể sử dụng hàm MinMaxScaler có trong thư viện sklearn.
#AI/main.py
import ...
from sklearn import preprocessing
scaler = preprocessing.MinMaxScaler()
scaler.fit(df)
df = pd.DataFrame(scaler.transform(df), index=df.index, columns=df.columns)
df.iloc[4:10]
print(df)
Kết quả sẽ là:

Bước 4: Phân tích dữ liệu thăm dò (EDA)
Bây giờ chúng tôi đã xử lý trước bộ dữ liệu, đã đến lúc kiểm tra phân tích thực hiện và xác định các biến quan trọng sẽ giúp chúng tôi dự đoán kết quả. Để làm điều này, chúng tôi sẽ sử dụng hàm SelectKBest có trong thư viện sklearn:
#AI/main.py
import ...
from sklearn.feature_selection import SelectKBest, chi2
X = df.loc[:,df.columns!='RainTomorrow']
y = df[['RainTomorrow']]
selector = SelectKBest(chi2, k=3)
selector.fit(X, y)
X_new = selector.transform(X)
print(X.columns[selector.get_support(indices=True)])
Đầu ra cho chúng ta ba biến dự đoán quan trọng nhất:
- Rainfall
- Humidity3pm
- RainToday
Index(['Rainfall', 'Humidity3pm', 'RainToday'], dtype='object')
Mục đích chính của bản demo này là để giúp bạn hiểu cách thức hoạt động của Machine Learning, do đó, để đơn giản hóa các tính toán, chúng tôi sẽ chỉ gán một trong các biến quan trọng này làm đầu vào.
#AI/main.py
...
#The important features are put in a data frame
df = df[['Humidity3pm','Rainfall','RainToday','RainTomorrow']]
#To simplify computations we will use only one feature (Humidity3pm) to build the model
X = df[['Humidity3pm']]
y = df[['RainTomorrow']]
Trong đoạn mã trên, X và y biểu thị đầu vào và đầu ra tương ứng.
Bước 5: Xây dựng Machine Learning Model
Ở bước này, chúng tôi sẽ xây dựng mô hình Machine Learning bằng cách sử dụng training data set và đánh giá hiệu quả của mô hình bằng cách sử dụng testing data set.
Chúng tôi sẽ xây dựng các mô hình phân loại bằng cách sử dụng các thuật toán sau:
- Logistic Regression
- Random Forest
- Decision Tree
- Support Vector Machine
Dưới đây là đoạn mã cho từng mô hình phân loại sau:
Logistic Regression
#AI/main.py
...
# Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import time
# Calculating the accuracy and the time taken by the classifier
t0 = time.time()
# Data Splicing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
clf_logreg = LogisticRegression(random_state=0)
# Building the model using the training data set
clf_logreg.fit(X_train, y_train)
# Evaluating the model using testing data set
y_pred = clf_logreg.predict(X_test)
score = accuracy_score(y_test, y_pred)
# Printing the accuracy and the time taken by the classifier
print('Accuracy using Logistic Regression:', score) #0.8395113859146434
print('Time taken using Logistic Regression:', time.time() - t0) #0.10015130043029785
Random Forest Classifier
#AI/main.py
...
#Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
#Calculating the accuracy and the time taken by the classifier
t0=time.time()
#Data Splicing
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25)
clf_rf = RandomForestClassifier(n_estimators=100, max_depth=4,random_state=0)
#Building the model using the training data set
clf_rf.fit(X_train,y_train)
#Evaluating the model using testing data set
y_pred = clf_rf.predict(X_test)
score = accuracy_score(y_test,y_pred)
#Printing the accuracy and the time taken by the classifier
print('Accuracy using Random Forest Classifier:',score) #0.8424973608807118
print('Time taken using Random Forest Classifier:' , time.time()-t0) #1.558568000793457
Decision Tree Classifier
#AI/main.py
...
#Decision Tree Classifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
#Calculating the accuracy and the time taken by the classifier
t0=time.time()
#Data Splicing
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25)
clf_dt = DecisionTreeClassifier(random_state=0)
#Building the model using the training data set
clf_dt.fit(X_train,y_train)
#Evaluating the model using testing data set
y_pred = clf_dt.predict(X_test)
score = accuracy_score(y_test,y_pred)
#Printing the accuracy and the time taken by the classifier
print('Accuracy using Decision Tree Classifier:',score) #0.8382144472930176
print('Time taken using Decision Tree Classifier:' , time.time()-t0) #0.033601999282836914
Support Vector Machine
#AI/main.py
...
#Support Vector Machine
from sklearn import svm
from sklearn.model_selection import train_test_split
#Calculating the accuracy and the time taken by the classifier
t0=time.time()
#Data Splicing
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25)
clf_svc = svm.SVC(kernel='linear')
#Building the model using the training data set
clf_svc.fit(X_train,y_train)
#Evaluating the model using testing data set
y_pred = clf_svc.predict(X_test)
score = accuracy_score(y_test,y_pred)
#Printing the accuracy and the time taken by the classifier
print('Accuracy using Support Vector Machine:',score) #0.804614688583924
print('Time taken using Support Vector Machine:' , time.time()-t0) #49.53200387954712
Tất cả các mô hình phân loại cung cấp cho chúng tôi điểm chính xác khoảng 83-84% ngoại trừ Support Vector Machines. Xem xét kích thước của tập dữ liệu của chúng tôi, độ chính xác là khá tốt.
Để tìm hiểu thêm về Machine Learning, hãy đọc các blog này:
- What is Machine Learning? Machine Learning For Beginners
- Machine Learning Tutorial for Beginners
- Latest Machine Learning Projects to Try in 2019
10. Limitations Of Machine Learning
Sau đây là những hạn chế của Machine Learning:
- Machine Learning không có khả năng xử lý và xử lý dữ liệu chiều cao (high dimensional data).
- Nó không thể được sử dụng trong nhận dạng hình ảnh (image recognition) và phát hiện đối tượng (object detection) vì chúng yêu cầu thực hiện dữ liệu chiều cao.
- Một thách thức lớn khác trong Machine Learning là nói cho máy biết các tính năng quan trọng cần tìm để dự đoán chính xác kết quả. Chính quá trình này được gọi là trích xuất tính năng (feature extraction). Trích xuất tính năng là một quy trình thủ công trong Machine Learning.
Những hạn chế trên có thể được giải quyết bằng cách sử dụng Deep Learning.
11. Why Deep Learning?
- Deep learning là một trong những phương pháp duy nhất để chúng ta có thể vượt qua những thách thức của việc trích xuất tính năng. Điều này là do các deep learning models có khả năng tự học tập trung vào các tính năng phù hợp, đòi hỏi sự can thiệp tối thiểu của con người.
- Deep Learning chủ yếu được sử dụng để đối phó với dữ liệu chiều cao. Nó dựa trên khái niệm Neural Networks và thường được sử dụng trong phát hiện đối tượng và xử lý ảnh.
Bây giờ hãy để cho hiểu về cách thức hoạt động của Deep Learning.
12. How Deep Learning Works?
Deep Learning mimics the basic component of the human brain called a brain cell or a neuron. Inspired from a neuron an artificial neuron was developed.
(Deep Learning bắt chước thành phần cơ bản của bộ não con người gọi là tế bào não hoặc tế bào thần kinh. Lấy cảm hứng từ một tế bào thần kinh, một tế bào thần kinh nhân tạo đã được phát triển.)
Deep Learning dựa trên chức năng của một tế bào thần kinh sinh học, vì vậy, hãy hiểu cách chúng ta bắt chước chức năng này trong tế bào thần kinh nhân tạo (còn được gọi là perceptionron):
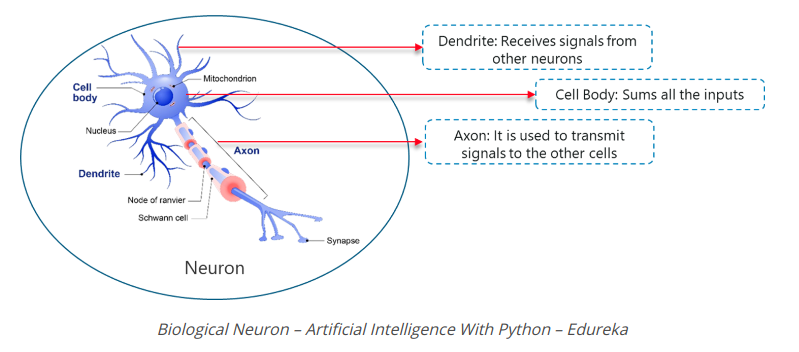
- Trong một tế bào thần kinh sinh học, Dendrites được sử dụng để nhận đầu vào. Những đầu vào này được tóm tắt trong cơ thể tế bào và thông qua Axon, nó được truyền đến tế bào thần kinh tiếp theo.
- Tương tự như tế bào thần kinh sinh học, một perceptron (tri giác) nhận được nhiều đầu vào, áp dụng các biến đổi và chức năng khác nhau và cung cấp một đầu ra.
- Bộ não con người bao gồm nhiều nơ-ron kết nối được gọi là mạng nơ-ron (neural network), tương tự, bằng cách kết hợp nhiều perceptrons, chúng tôi đã phát triển cái được gọi là Deep neural network.
Bây giờ hãy hiểu chính xác Deep Learning là gì
13. What Is Deep Learning?
Deep Learning is a collection of statistical machine learning techniques used to learn feature hierarchies based on the concept of artificial neural networks.
(Deep Learning là tập hợp các kỹ thuật học máy thống kê được sử dụng để học phân cấp tính năng dựa trên về khái niệm neural networks nhân tạo.)
Một Deep neural network bao gồm các lớp sau:
- The Input Layer
- The Hidden Layer
- The Output Layer
 Trong hình trên:
Trong hình trên:
- Lớp đầu tiên là lớp đầu vào nhận tất cả các đầu vào.
- Lớp cuối cùng là lớp đầu ra cung cấp đầu ra mong muốn.
- Tất cả các lớp ở giữa các lớp này được gọi là các lớp ẩn.
- Có thể có n số lớp ẩn, số lớp ẩn và số lượng tri giác trong mỗi lớp sẽ hoàn toàn phụ thuộc vào trường hợp sử dụng mà bạn đang cố gắng giải quyết.
Deep Learning được sử dụng trong các trường hợp sử dụng tính toán cao như Xác minh khuôn mặt, xe tự lái, v.v. Hãy hiểu tầm quan trọng của Deep Learning bằng cách xem xét trường hợp sử dụng trong thế giới thực.
14. Deep Learning Use Case
Xem xét cách PayPal sử dụng Deep Learning để xác định mọi hoạt động gian lận có thể có. PayPal đã xử lý hơn 235 tỷ đô la thanh toán từ bốn tỷ giao dịch của hơn 170 triệu khách hàng.
PayPal đã sử dụng thuật toán Machine learning và Deep Learning để khai thác dữ liệu từ lịch sử mua hàng của khách hàng ngoài việc xem xét các mẫu gian lận có khả năng được lưu trữ trong cơ sở dữ liệu của mình để dự đoán liệu một giao dịch cụ thể có lừa đảo hay không.
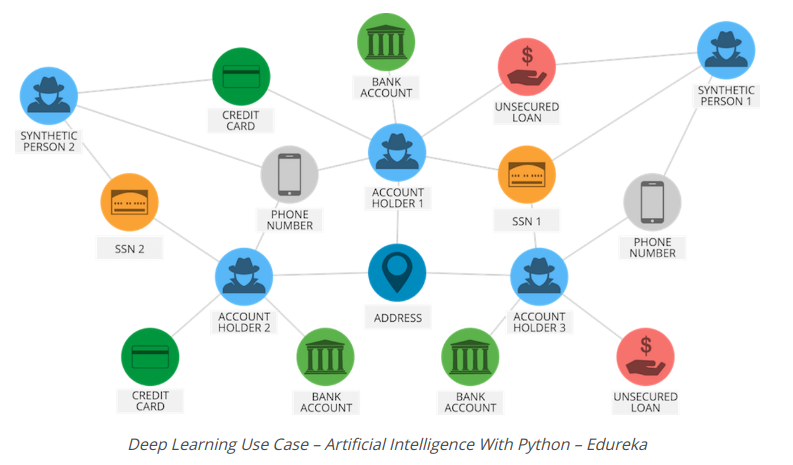
Công ty đã dựa vào công nghệ Deep Learning & Machine Learning trong khoảng 10 năm. Ban đầu, nhóm giám sát gian lận sử dụng các mô hình tuyến tính đơn giản. Nhưng qua nhiều năm, công ty đã chuyển sang một công nghệ Machine Learning tiên tiến hơn có tên là Deep Learning.
Quản lý rủi ro gian lận và Nhà khoa học dữ liệu tại PayPal, Ke Wang, trích dẫn:
What we enjoy from more modern, advanced machine learning is its ability to consume a lot more data, handle layers and layers of abstraction and be able to ‘see’ things that a simpler technology would not be able to see, even human beings might not be able to see.
(Những gì chúng ta thích từ học máy hiện đại hơn, tiên tiến hơn là khả năng tiêu thụ nhiều dữ liệu hơn, xử lý các lớp và các lớp trừu tượng và có thể nhìn thấy những thứ mà một công nghệ đơn giản hơn không thể nhìn thấy, thậm chí con người có thể không thể nhìn thấy.)
Một mô hình tuyến tính đơn giản có khả năng tiêu thụ khoảng 20 biến. Tuy nhiên, với công nghệ Deep Learning, người ta có thể chạy hàng ngàn điểm dữ liệu.
"There’s a magnitude of difference — you’ll be able to analyze a lot more information and identify patterns that are a lot more sophisticated"
(Càng có một sự khác biệt lớn - bạn có thể phân tích nhiều thông tin hơn và xác định các mẫu phức tạp hơn rất nhiều, theo Ke Ke Wang.)
Do đó, bằng cách triển khai công nghệ Deep Learning, PayPal cuối cùng có thể phân tích hàng triệu giao dịch để xác định bất kỳ hoạt động gian lận nào.
Để hiểu rõ hơn về Deep Learning, hãy hiểu cách thức hoạt động của Perceptron.
15. What Is A Perceptron?
Perceptron là một neural network một lớp được sử dụng để phân loại dữ liệu tuyến tính. Perceptionron có 4 thành phần quan trọng:
- Input
- Weights and Bias
- Summation Function
- Activation or transformation Function
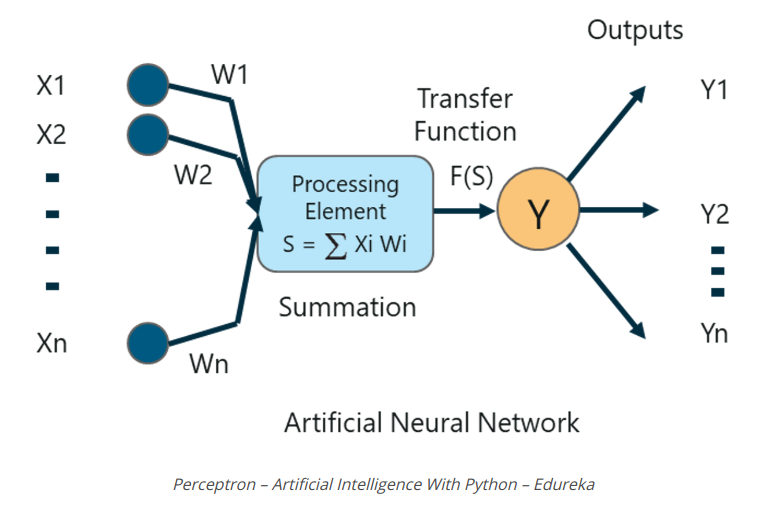
Logic cơ bản đằng sau một perceptron như sau:
Các đầu vào (x) nhận được từ lớp đầu vào được nhân với trọng số được chỉ định w. Các giá trị nhân sau đó được thêm vào để tạo thành Tổng trọng số (Weighted Sum). Tổng trọng số của các yếu tố đầu vào và trọng lượng tương ứng của chúng sau đó được áp dụng cho Hàm kích hoạt (Activation Function) có liên quan. Hàm kích hoạt ánh xạ đầu vào thành đầu ra tương ứng.
Weights and Bias In Deep Learning
Tại sao chúng ta phải gán trọng số (weights) cho từng đầu vào?
Khi một biến đầu vào được đưa vào network, một giá trị được chọn ngẫu nhiên được gán là trọng số của đầu vào đó. Trọng số của từng điểm dữ liệu đầu vào cho biết tầm quan trọng của đầu vào đó trong việc dự đoán kết quả.
Mặt khác, tham số bias cho phép bạn điều chỉnh đường cong chức năng kích hoạt theo cách đạt được đầu ra chính xác.
Summation Function
Khi các đầu vào được gán một số trọng lượng, sản phẩm của đầu vào và trọng lượng tương ứng được lấy. Thêm tất cả các sản phẩm này cung cấp cho chúng tôi Sum có trọng số. Điều này được thực hiện bởi hàm tổng.
Activation Function
Mục đích chính của các chức năng kích hoạt là ánh xạ tổng trọng số vào đầu ra. Các hàm kích hoạt như tanh, ReLU, sigmoid, v.v là những ví dụ về các hàm biến đổi.
Để tìm hiểu thêm về các chức năng của Perceptron, bạn có thể xem qua blog Deep Learning: Perceptron Learning Algorithm.
Bây giờ hãy hiểu về khái niệm đa lớp Perceptionron.
16. Multilayer Perceptrons
Why Multilayer Perceptron Is Used?
Một lớp Perceptionron không có khả năng xử lý dữ liệu chiều cao và chúng có thể được sử dụng để phân loại dữ liệu phân tách phi tuyến tính.
Do đó, các vấn đề phức tạp, liên quan đến một số lượng lớn các tham số có thể được giải quyết bằng cách sử dụng Multilayer Perceptrons.
What Is A Multilayer Perceptron?
Một Multilayer Perceptron là một bộ phân loại có chứa một hoặc nhiều lớp ẩn và nó dựa trên mạng nơ ron nhân tạo Feedforward. Trong các mạng Feedforward, mỗi lớp mạng thần kinh được kết nối đầy đủ với lớp sau.
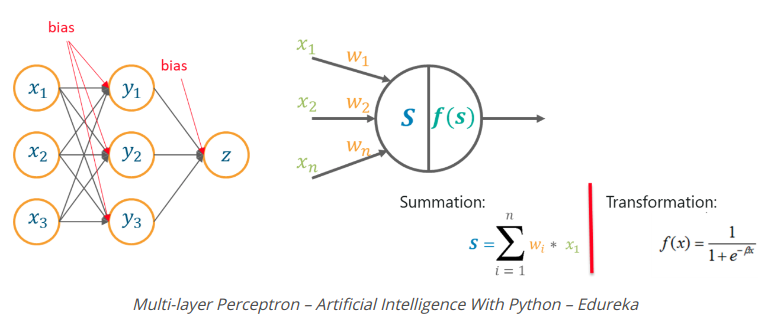
How does Multilayer Perceptron Work?
Trong một Perceptionron đa lớp, các trọng số được gán cho mỗi đầu vào lúc đầu được cập nhật để giảm thiểu lỗi kết quả trong tính toán.
Điều này được thực hiện bởi vì ban đầu chúng tôi gán ngẫu nhiên các giá trị trọng lượng cho từng đầu vào, các giá trị trọng lượng này rõ ràng không mang lại cho chúng tôi kết quả mong muốn, do đó cần phải cập nhật các trọng số sao cho đầu ra chính xác.
Quá trình cập nhật các trọng số và đào tạo các mạng được gọi là Backpropagation.
Backpropagation là logic đằng sau Perceptionrons đa lớp. Phương pháp này được sử dụng để cập nhật các trọng số sao cho biến đầu vào quan trọng nhất có trọng số tối đa, do đó giảm lỗi trong khi tính toán đầu ra.
Vì vậy, đó là logic đằng sau Artificial Neural Networks. Nếu bạn muốn tìm hiểu thêm, hãy chắc chắn rằng bạn đã cung cấp, đọc thêm Neural Network Tutorial – Multi-Layer Perceptron.
All rights reserved
