Hướng dẫn toàn diện về Trí tuệ nhân tạo với Python (Dịch.p2)
Bài đăng này đã không được cập nhật trong 6 năm
Nguồn: Edureka
Ở phần 1 chúng ta đã tìm hiểu qua 4 chủ đề:
- Why Is Python Best For AI?
- Demand For AI
- What Is Artificial Intelligence?
- Types Of Artificial Intelligence
TIếp theo ở phần này, cúng ta sẽ tìm hiểu tiếp các chủ đề sau:
- Machine Learning Basics
- Types Of Machine Learning
- Types Of Problems Solved By Using Machine Learning
- Machine Learning Process
5. Machine Learning Basics
Thuật ngữ Machine Learning lần đầu tiên được đặt ra bởi Arthur Samuel vào năm 1959. Nhìn lại, năm đó có lẽ là năm quan trọng nhất về mặt tiến bộ công nghệ.
Nói một cách đơn giản,
Machine learning is a subset of Artificial Intelligence (AI) which provides machines the ability to learn automatically by feeding it tons of data & allowing it to improve through experience. Thus, Machine Learning is a practice of getting Machines to solve problems by gaining the ability to think. (Machine Learning (ML) là một tập hợp con của Artificial Intelligence (AI) cung cấp cho máy khả năng tự động học bằng cách cung cấp cho nó hàng tấn dữ liệu và cho phép nó cải thiện thông qua trải nghiệm. Do đó, ML là một phương pháp giúp máy móc giải quyết vấn đề bằng cách đạt được khả năng suy nghĩ.)
Nhưng làm thế nào một cỗ máy có thể đưa ra quyết định?
Nếu bạn cung cấp cho máy một lượng dữ liệu tốt, nó sẽ học cách diễn giải, xử lý và phân tích dữ liệu này bằng cách sử dụng Machine Learning Algorithms.
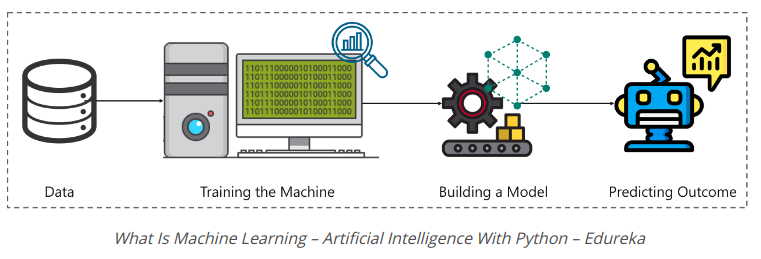
Để tổng hợp, hãy xem hình trên:
- Một quá trình Machine Learning bắt đầu bằng cách cung cấp cho máy nhiều dữ liệu.
- Sau đó, máy được đào tạo về dữ liệu này, để phát hiện những hiểu biết và mẫu ẩn.
- Những hiểu biết này được sử dụng để xây dựng Machine Learning Model bằng cách sử dụng thuật toán để giải quyết vấn đề.
Bây giờ chúng ta đã biết Machine Learning là gì, hãy cùng tìm hiểu các cách khác nhau mà máy có thể học.
6. Types Of Machine Learning
Một cỗ máy có thể học cách giải quyết vấn đề bằng cách làm theo bất kỳ một trong ba cách tiếp cận sau:
- Supervised Learning (Học có giám sát)
- Unsupervised Learning (Học không giám sát)
- Reinforcement Learning (Học tăng cường)
6.1. Supervised Learning
Supervised learning is a technique in which we teach or train the machine using data which is well labeled. (Học có giám sát là một kỹ thuật trong đó chúng tôi dạy hoặc huấn luyện máy sử dụng dữ liệu được dán nhãn tốt.)
Để hiểu về Supervised Learning, hãy để Hãy xem xét một sự tương tự. Khi còn nhỏ chúng ta đều cần hướng dẫn để giải các bài toán. Giáo viên của chúng tôi đã giúp chúng tôi hiểu bổ sung là gì và nó được thực hiện như thế nào.
Tương tự như vậy, bạn có thể nghĩ về Supervised Learning như một loại Máy học liên quan đến hướng dẫn. Tập dữ liệu được dán nhãn là giáo viên sẽ đào tạo bạn để hiểu các mẫu trong dữ liệu. Tập dữ liệu được dán nhãn không có gì ngoài tập dữ liệu huấn luyện.
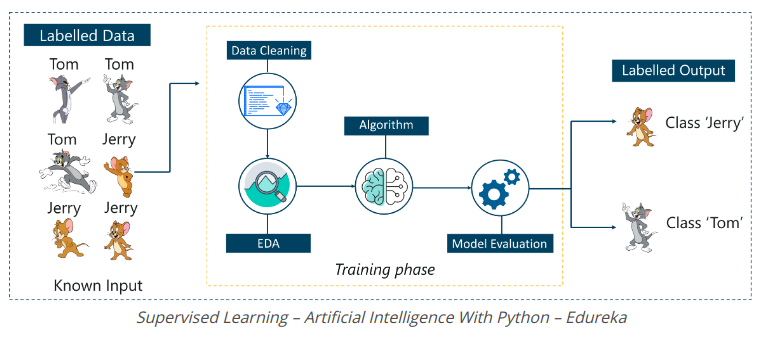
Hãy xem xét hình trên. Ở đây chúng tôi cho hình ảnh của Tom và Jerry và mục tiêu là để máy xác định và phân loại hình ảnh thành hai nhóm (hình ảnh Tom và hình ảnh Jerry).
Tập dữ liệu huấn luyện được cung cấp cho mô hình được dán nhãn, như bên trong, chúng tôi nói với máy, 'đây là giao diện của Tom và đây là Jerry'. Bằng cách đó, bạn có thể đào tạo máy bằng cách sử dụng dữ liệu được dán nhãn. Trong Supervised Learning, có một giai đoạn đào tạo được xác định rõ ràng được thực hiện với sự trợ giúp của dữ liệu được dán nhãn.
6.2. Unsupervised Learning
Unsupervised learning involves training by using unlabeled data and allowing the model to act on that information without guidance.(Học tập không giám sát bao gồm đào tạo bằng cách sử dụng dữ liệu không được gắn nhãn và cho phép mô hình hành động theo thông tin đó mà không cần hướng dẫn.)
Hãy nghĩ về Unsupervised Learning như một đứa trẻ thông minh học tập mà không cần bất kỳ sự hướng dẫn nào. Trong loại Machine Learning này, mô hình không được cung cấp dữ liệu được gắn nhãn, vì trong mô hình không có manh mối nào cho thấy "hình ảnh này là Tom và đây là Jerry", nó tự tìm ra các mô hình và sự khác biệt giữa Tom và Jerry trong hàng tấn dữ liệu.
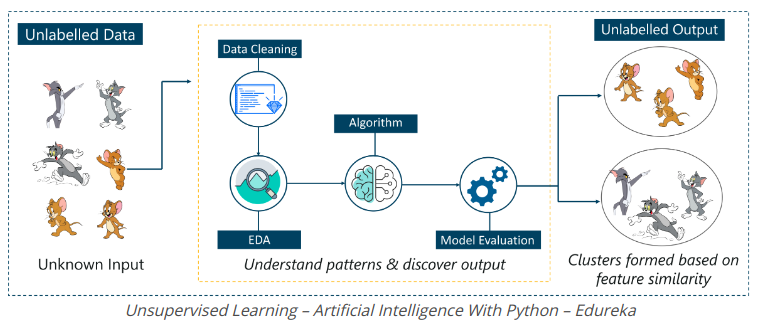
Ví dụ, nó xác định các tính năng nổi bật của Tom như tai nhọn, kích thước lớn hơn,...để hiểu rằng đây là hình ảnh loại 1. Tương tự, nó tìm các tính năng nổi bật như vậy trong Jerry và biết rằng hình ảnh này thuộc loại 2.
Do đó, nó phân loại các hình ảnh thành 2 lớp khác nhau mà khong biết Tom và Jerry là ai.
6.3. Reinforcement Learning
Reinforcement Learning is a part of Machine learning where an agent is put in an environment and he learns to behave in this environment by performing certain actions and observing the rewards which it gets from those actions. (Học tăng cường là một phần của ML khi một tác nhân được đưa vào môi trường và anh ta học cách cư xử trong môi trường này bằng cách thực hiện một số hành động nhất định và quan sát phần thưởng nhận được từ những hành động đó.)
Hãy tưởng tượng rằng bạn đã bị bỏ rơi tại một hòn đảo bị cô lập!
Bạn sẽ làm gì?
Hoảng loạn? Vâng, tất nhiên, ban đầu tất cả chúng ta sẽ như vậy. Nhưng khi thời gian trôi qua, bạn sẽ học được cách sống trên đảo. Bạn sẽ khám phá môi trường, hiểu điều kiện khí hậu, loại thực phẩm mọc ở đó, sự nguy hiểm của hòn đảo, v.v.
Đây chính xác là cách Reinforcement Learning hoạt động, nó liên quan đến một Agent (bạn, bị mắc kẹt trên đảo) được đặt trong một môi trường không xác định (đảo), nơi anh ta phải học bằng cách quan sát và thực hiện các hành động dẫn đến phần thưởng.
Reinforcement Learning chủ yếu được sử dụng trong các lĩnh vực ML nâng cao như xe tự lái, AplhaGo, v.v ... Vì vậy, nó bao gồm các loại Machine Learning.
Bây giờ, hãy nhìn vào loại vấn đề được giải quyết bằng cách sử dụng Machine Learning.
7. What Problems Can Machine Learning Solve?
Có ba loại vấn đề chính có thể được giải quyết bằng Machine Learning:
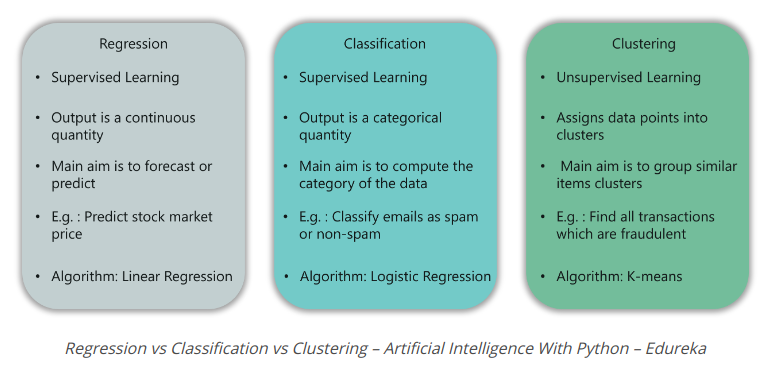
What is Regression? (Hồi quy là gì?)
Trong loại vấn đề này, đầu ra là một số lượng liên tục. Ví dụ, nếu bạn muốn dự đoán tốc độ của một chiếc xe được cho khoảng cách, thì đó là vấn đề Hồi quy. Vấn đề hồi quy có thể được giải quyết bằng cách sử dụng các thuật toán Supervised Learning như hồi quy tuyến tính.
What is Classification? (Phân lịa là gì?)
Trong loại này, đầu ra là một giá trị phân loại. Phân loại email thành hai lớp, thư rác và không spam là một vấn đề phân loại có thể được giải quyết bằng cách sử dụng các thuật toán phân loại Supervised Learning như Support Vector Machines, Naive Bayes, Logistic Regression, K Recent Neighbor, v.v.
What is Clustering? (Phân cụm là gì?)
Loại vấn đề này liên quan đến việc gán đầu vào thành hai hoặc nhiều cụm dựa trên tính tương tự của tính năng. Ví dụ: phân cụm người xem thành các nhóm tương tự dựa trên sở thích, tuổi tác, địa lý, v.v. của họ có thể được thực hiện bằng cách sử dụng các thuật toán Unsupervised Learning như Phân cụm K-Means.
Bây giờ, hãy cùng xem xét cách thức hoạt động của quá trình Machine Learning.
8. Machine Learning Process Steps
Quá trình Machine Learning liên quan đến việc xây dựng một mô hình Dự đoán có thể được sử dụng để tìm giải pháp cho Báo cáo sự cố.
Để hiểu được quy trình Machine Learning, hãy giả sử rằng bạn đã gặp phải một vấn đề cần giải quyết bằng cách sử dụng Machine Learning.
Vấn đề là dự đoán sự xuất hiện của mưa trong khu vực địa phương của bạn bằng cách sử dụng Machine Learning.
Các bước dưới đây được thực hiện theo quy trình Machine Learning:
Step 1: Define the objective of the Problem Statement (Xác định mục tiêu của Báo cáo sự cố)
Ở bước này, chúng ta phải hiểu chính xác những gì cần dự đoán. Trong trường hợp của chúng tôi, mục tiêu là dự đoán khả năng mưa bằng cách nghiên cứu điều kiện thời tiết.
Cũng cần thiết phải ghi chú về loại dữ liệu nào có thể được sử dụng để giải quyết vấn đề này hoặc loại phương pháp bạn phải tuân theo để đi đến giải pháp.
Step 2: Data Gathering (Thu thập dữ liệu)
Ở giai đoạn này, bạn phải đặt câu hỏi như:
- Những loại dữ liệu cần thiết để giải quyết vấn đề này?
- Là dữ liệu có sẵn?
- Làm thế nào tôi có thể nhận được dữ liệu?
Khi bạn biết các loại dữ liệu được yêu cầu, bạn phải hiểu làm thế nào bạn có thể lấy được dữ liệu này. Thu thập dữ liệu có thể được thực hiện bằng tay hoặc bằng phương pháp web scraping.
Tuy nhiên, nếu bạn là người mới bắt đầu và bạn chỉ muốn học Machine Learning, bạn không phải lo lắng về việc lấy dữ liệu. Có 1000 tài nguyên dữ liệu trên web, bạn chỉ cần tải xuống tập dữ liệu và bắt đầu thực hiện.
Quay trở lại vấn đề trong tay, dữ liệu cần thiết cho dự báo thời tiết bao gồm các biện pháp như độ ẩm, nhiệt độ, áp suất, địa phương, cho dù bạn có sống ở trạm đồi hay không, v.v.
Dữ liệu đó phải được thu thập và lưu trữ để phân tích.
Step 3: Data Preparation (Chuẩn bị dữ liệu)
Dữ liệu bạn thu thập gần như không bao giờ ở định dạng đúng. Bạn sẽ gặp rất nhiều mâu thuẫn trong tập dữ liệu như thiếu giá trị, biến dự phòng, giá trị trùng lặp, v.v.
Loại bỏ sự không nhất quán như vậy là rất cần thiết bởi vì chúng có thể dẫn đến tính toán và dự đoán sai. Do đó, ở giai đoạn này, bạn quét bộ dữ liệu cho bất kỳ sự không nhất quán nào và bạn sửa chúng sau đó.
Step 4: Exploratory Data Analysis (Phân tích dữ liệu thăm dò)
Giai đoạn này cần lặn sâu vào dữ liệu và tìm thấy tất cả những bí ẩn dữ liệu ẩn.
EDA hoặc Exploratory Data Analysis là giai đoạn động não của Machine Learning. Data Exploration liên quan đến việc hiểu các mẫu và xu hướng trong dữ liệu. Ở giai đoạn này, tất cả các hiểu biết hữu ích được rút ra và mối tương quan giữa các biến được hiểu.
Ví dụ, trong trường hợp dự đoán lượng mưa, chúng ta biết rằng có khả năng mưa rất lớn nếu nhiệt độ xuống thấp. Mối tương quan như vậy phải được hiểu và lập bản đồ ở giai đoạn này.
Step 5: Building a Machine Learning Model (Xây dựng mô hình ML)
Tất cả những hiểu biết và mô hình thu được trong Data Exploration được sử dụng để xây dựng Machine Learning Model. Giai đoạn này luôn bắt đầu bằng cách chia tập dữ liệu thành hai phần, training data (dữ liệu huấn luyện) và testing data (dữ liệu thử nghiệm).
Training data sẽ được sử dụng để xây dựng và phân tích mô hình. Logic của mô hình dựa trên Thuật toán ML đang được triển khai.
Trong trường hợp dự đoán lượng mưa, do đầu ra sẽ ở dạng True (nếu trời sẽ mưa vào ngày mai) hoặc False (không có mưa vào ngày mai), chúng ta có thể sử dụng thuật toán phân loại như Logistic Regression hoặc Decision Tree.
Việc chọn đúng thuật toán phụ thuộc vào loại vấn đề mà bạn đang cố gắng giải quyết, tập dữ liệu và mức độ phức tạp của vấn đề.
Step 6: Model Evaluation & Optimization (Đánh giá & tối ưu hóa mô hình)
Sau khi xây dựng mô hình bằng cách sử dụng tập training data, cuối cùng đã đến lúc đưa mô hình vào thử nghiệm.
Tập testing data được sử dụng để kiểm tra hiệu quả của mô hình và mức độ chính xác của nó có thể dự đoán kết quả.
Khi độ chính xác được tính toán, mọi cải tiến tiếp theo trong mô hình có thể được thực hiện ở giai đoạn này. Các phương thức như điều chỉnh tham số và xác nhận chéo có thể được sử dụng để cải thiện hiệu suất của mô hình.
Step 7: Predictions (Dự đoán)
Khi mô hình được đánh giá và cải tiến, cuối cùng nó được sử dụng để đưa ra dự đoán. Đầu ra cuối cùng có thể là Categorical variable (biến phân loại) (ví dụ: True or False) hoặc có thể là Continuous Quantity (số lượng liên tục) (ví dụ: giá trị dự đoán của một cổ phiếu).
Trong trường hợp của chúng tôi, để dự đoán sự xuất hiện của lượng mưa, đầu ra sẽ là một biến phân loại.
Đó là toàn bộ quá trình Machine Learning.
Trong phần tiếp theo, chúng ta sẽ thảo luận về các loại Thuật toán ML khác nhau.
Machine Learning Algorithms
Machine Learning Algorithms là logic cơ bản đằng sau mỗi mô hình Machine Learning. Các thuật toán này dựa trên các khái niệm đơn giản như Thống kê và Xác suất.
Theo dõi các blog được đề cập dưới đây để hiểu Toán và số liệu thống kê đằng sau Thuật toán học máy:
- A Complete Guide To Math And Statistics For Data Science
- All You Need To Know About Statistics And Probability
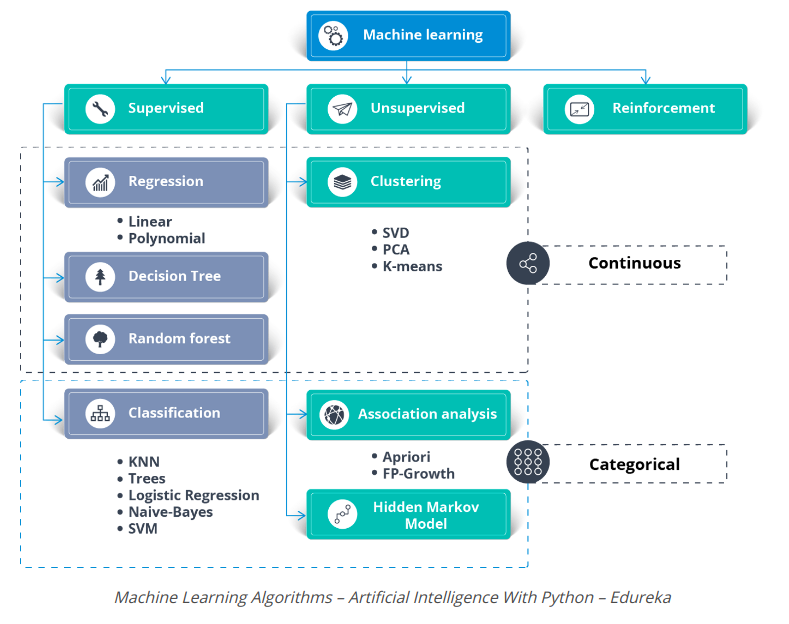
Hình trên cho thấy các thuật toán khác nhau được sử dụng để giải quyết vấn đề bằng Machine Learning.
Supervised Learning có thể được sử dụng để giải quyết hai loại vấn đề về Machine Learning:
- Regression (Hồi quy)
- Classification (Phân loại)
Để giải quyết vấn đề hồi quy, bạn có thể sử dụng thuật toán hồi quy tuyến tính nổi tiếng (Linear Regression Algorithm)
Các vấn đề phân loại có thể được giải quyết bằng các thuật toán phân loại sau:
- Logistic Regression
- Decision Tree
- Random Forest
- Naive Bayes Classifier
- Support Vector Machine
- K Nearest Neighbour
Unsupervised Learning có thể được sử dụng để giải quyết các vấn đề về cụm và liên kết. Một trong những thuật toán phân cụm nổi tiếng là thuật toán phân cụm K-means.
All rights reserved
