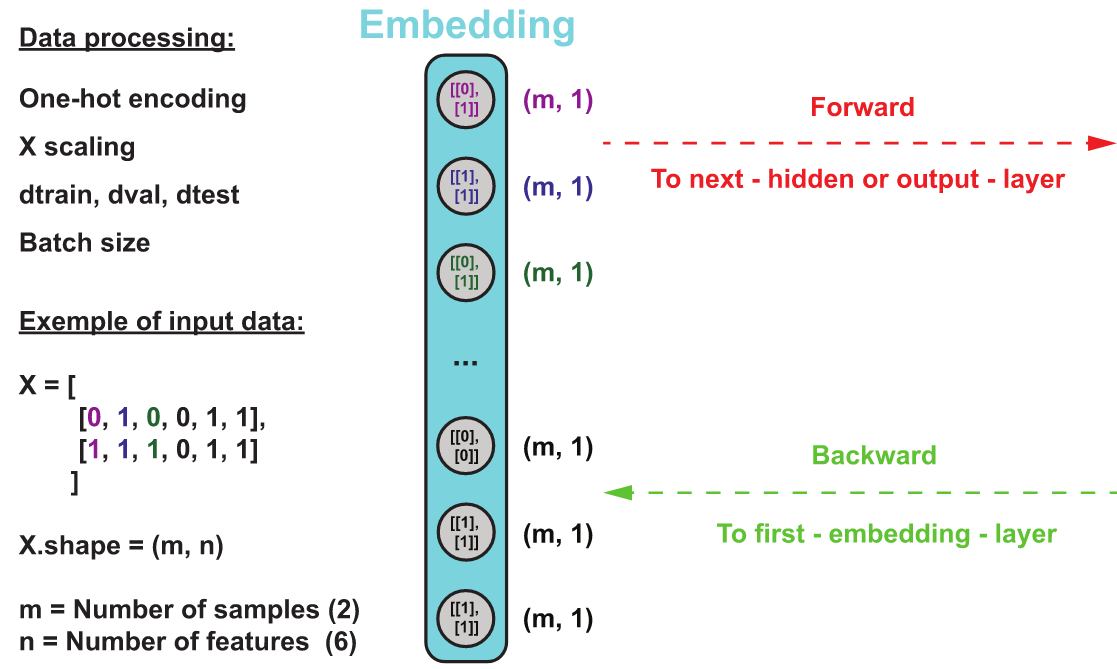
How embedding layer work
Bài đăng này đã không được cập nhật trong 3 năm
Why need word embedding?
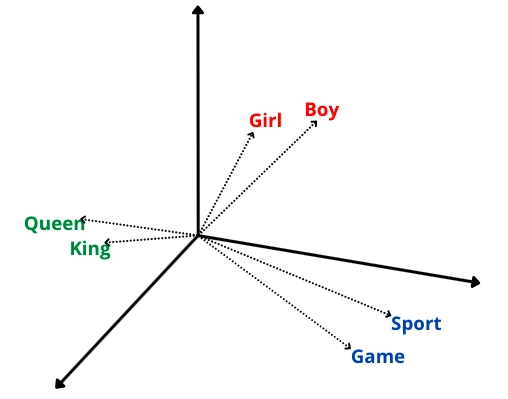
Before the term embedding was unknown, people used the traditional bag of words method or one hot encoding method to map the words to numbers. To implement this method, a lot of memory was required as generated vectors were sparse and large, and each vector represents a single word. To overcome this problem, word embedding techniques came into existence.
Sure! An embedding layer is a neural network layer that learns a representation (embedding) of discrete inputs (usually words or tokens) in a continuous vector space.
Here's an example of how an embedding layer works using a numpy array:
Suppose we have a set of 4 words: "cat", "dog", "bird", and "fish". We want to represent each of these words as a vector of length 3. We can initialize the embedding layer with random values for each word's vector representation:
import numpy as np
# initialize embedding layer with random values
embedding_layer = np.random.rand(4, 3)
This creates a numpy array with 4 rows (one for each word) and 3 columns (the length of the vector representation). Each row represents the vector representation of one of the words.
Now, suppose we have a sentence "I saw a cat". We can represent this sentence as a sequence of integers, where each integer corresponds to the index of the corresponding word in our vocabulary. For example, "I saw a cat" could be represented as the sequence [0, 1, 2, 0], where "I" corresponds to the first word "cat", "saw" corresponds to the second word "dog", and so on.
To get the vector representation of this sequence using the embedding layer, we can simply index into the layer with the sequence:
# sequence of indices representing the sentence "I saw a cat"
sequence = [0, 1, 2, 0]
# get the vector representation of the sequence using the embedding layer
embedding_representation = embedding_layer[sequence]
print(embedding_representation)
This outputs:
[[0.7998 0.0982 0.2799]
[0.3138 0.5116 0.0919]
[0.8009 0.7756 0.6911]
[0.7998 0.0982 0.2799]]
Each row of the output corresponds to the vector representation of the corresponding word in the input sequence. In this case, the first and fourth rows are the same because the first and last words in the sequence are both "cat".
Note that the values in the output are not always the same as the values in the embedding layer. The values in the output are the learned representations of the input words, which are updated during the training process
To get the vector representation of a sequence using an embedding layer
in a neural network, you can simply pass the sequence of indices as input to the layer. Here's an example using TensorFlow:
import tensorflow as tf
# define the embedding layer with input dimension 4, output dimension 3
embedding_layer = tf.keras.layers.Embedding(input_dim=4, output_dim=3)
# define a sequence of indices representing the sentence "I saw a cat"
sequence = tf.constant([[0, 1, 2, 0]])
# pass the sequence through the embedding layer
embedding_representation = embedding_layer(sequence)
print(embedding_representation)
This outputs:
[[[ 0.01026477 -0.01838384 -0.03530212]
[ 0.01458425 -0.01484107 0.03178691]
[-0.04269245 -0.00086897 -0.02909169]
[ 0.01026477 -0.01838384 -0.03530212]]]
Some formular math for converting embedding_layer.
Sure! Here's the mathematical formula for computing the output of an embedding layer given an input sequence of indices:
Let X be the input sequence of indices, with shape (batch_size, sequence_length), and let E be the embedding matrix, with shape (input_dim, output_dim). The output of the embedding layer Y is computed as follows:
Y = E[X]
Here, E[X] means selecting the rows of E corresponding to the indices in X. Specifically, if X[i, j] = k, then Y[i, j, :] = E[k, :]. The output Y has shape (batch_size, sequence_length, output_dim).
Note that during training, the values in E are learned by backpropagation through the network, and during inference, they are fixed.
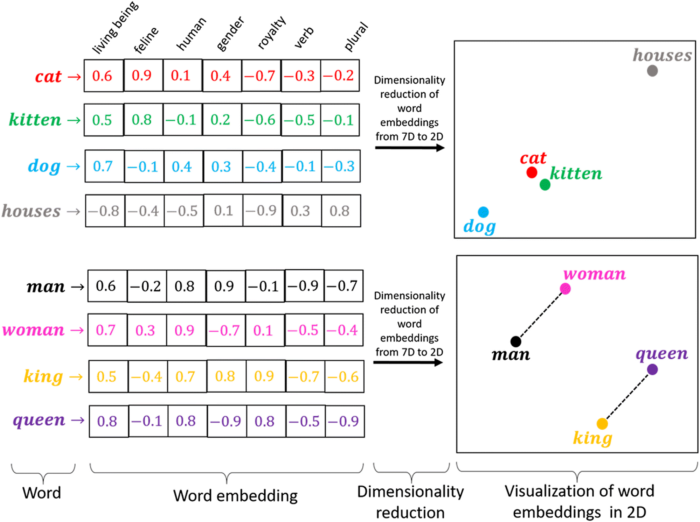
It order to use words for natural language processing or machine learning tasks, it is necessary to first map them onto a continuous vector space, thus creating word vectors or word embeddings. The Keras Embedding layer is useful for constructing such word vectors.
input_dim : the vocabulary size. This is how many unique words are represented in your corpus.
output_dim : the desired dimension of the word vector. For example, if output_dim = 100, then every word will be mapped onto a vector with 100 elements, whereas if output_dim = 300, then every word will be mapped onto a vector with 300 elements.
input_length : the length of your sequences. For example, if your data consists of sentences, then this variable represents how many words there are in a sentence. As disparate sentences typically contain different number of words, it is usually required to pad your sequences such that all sentences are of equal length. The keras.preprocessing.pad_sequence method can be used for this (https://keras.io/preprocessing/sequence/).
In Keras, it is possible to either 1) use pretrained word vectors such as GloVe or word2vec representations, or 2) learn the word vectors as part of the training process. This blog post (https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html) offers a tutorial on how to use GloVe pretrained word vectors. For option 2, Keras will randomly initialize vectors as the default option, and then learn optimal word vectors during the training process.
All rights reserved
