Hotword detection cho những trợ lý ảo thông minh
Bài đăng này đã không được cập nhật trong 7 năm
Chắc hẳn các bạn đã không còn xa lạ gì với những cái tên như Ok, Google, Google Assistant, Amazon Alexa, Siri, Cortana nữa. Chúng là những trợ lý ảo cá nhân, thông minh được phát triển bởi các ông lớn trong ngành công nghệ như Google, Amazon, Apple và Microsoft. Những trợ lý ảo nào được xây dựng nhằm mục đích hỗ trợ con người những công việc đơn giản như đặt lịch, tra cứu, tìm kiếm, dịch ngữ, nghe nhạc, điều khiển các ứng dụng điện thoại hay các thiết bị thông minh khác trong nhà.

Một đặc điểm chung của các trợ lý ảo này chắc các bạn cũng để ý thấy là khi ta muốn sử dụng chúng thì đều phải gọi tên nó như một chức năng kích hoạt kiểu như "Ok, Google", "Hey, Siri", "Alexa",...

Các từ này thường được gọi là các từ kích hoạt, từ khởi động hay hotword vì chúng được sử dụng để phát hiện điểm bắt đầu cho các phiên làm việc của thiết bị. Trong bài viết này, mình sẽ trình bày quá xây dựng một mô hình đơn giản để thực hiện detect các hotword đó thông qua một kiến trúc deeplearning và áp dụng nó trong việc sử dụng thời gian thực.
Xác định vấn đề và chuẩn bị dữ liệu huấn luyện
Giống như các bài toán sử dụng Deep learning khác, việc đầu tiên chúng ta cần làm là xác định vấn đề và phân loại bài toán để từ đó thực hiện việc chuẩn bị dữ liệu cho phù hợp. Ở đây, vấn đề cần tiếp cận là từ một audio liên tục lấy từ thời gian thực, ta phát hiện ra nó có chứa hotword hay không để khởi động hệ thống. Theo cách tiếp cận trước đây không sử dụng các kĩ thuật trí tuệ nhân tạo, quá trình này trải qua các bước:
- Chuẩn bị các audio mẫu sẵn có hotword
- Phân đoạn audio truyền tới thành các frame có kích thước bằng với kích thước của audio mẫu
- Tính độ tương quan giữa audio và các frame liên tiếp thông qua đồ thị miền tần số
- So sánh các độ tương quan với ngưỡng để xác định frame đó có hotword hay không
Các giải quyết này tiềm ẩn rất nhiều vấn đề đặc biệt là việc xử lý khi trong audio có nhiều nhiễu. Một cách tiếp cận khác chuyển bài toán này về bài toán labeling cho dữ liệu dạng chuỗi với nhãn 0 là không phải hotword và 1 là hotword.
Việc chuẩn bị dữ liệu đòi hỏi bộ dữ liệu huấn luyện cần phải giống với dữ liệu thực tế khi sử dụng nhất có thể. Để tạo được bộ dữ liệu này, ta cần chuẩn bị và thực hiện 1 số bước:
- Ghi lại âm thanh trong các môi trường nhiễu khác nhau như tiếng xe cộ, tiếng quạt, tiếng nói chuyện nơi đông người,... Các đoạn audio này sẽ là audio nền cho dữ liệu huẩn luyện của chúng ta.
- Ghi âm lại nhiều đoạn audio chứa từ khóa(hotword)
- Ghi âm lại nhiều đoạn audio nói các từ khác không phải từ khóa
Từ 3 phần dữ liệu trên, ta thực hiện bước để tạo dữ liệu đào tạo:
- Chọn ngẫu nhiên 1 audio background
- Chọn ngẫu nhiên 0-4 audio chứa hotword và ghi chồng vào audio background
- Chọn ngẫu nhiên 0-4 audio chứa các từ không phải hotword và ghi chồng vào audio background
Việc thự hiện các bước này giúp dữ liệu huẩn luyện của ta trung thực hơn và sát hơn dữ liệu thực tế hơn. Đối với nhãn đầu ra, chúng ta sẽ có 2 nhãn là hotword hoặc là không. Trước tiên, ta đánh dấu tất cả các mốc thời gian với đầu ra đều là 0. Sau đó, với mỗi lần xuất hiện hotword, ta cập nhật lại nhãn đích bằng cách gán 50 dấu thời gian tiếp theo là 1. Việc thêm 50 nhãn đầu ra là 1 giúp dữ liệu của ta bớt bị mất cân bằng nhãn hơn, nếu chỉ gán 1 nhãn 1 cho điểm bắt đầu của hotword thì sẽ có quá nhiều nhãn 0 trong nhãn đích. Việc tạo ra một tập dữ liệu mất cân bằng là vô cùng không hiệu quả trong quá trình huấn luyện mô hình.
Dưới đây là hình minh họa cho việc gán nhãn cho dữ liệu huấn luyện.

Biểu đồ màu xanh là biểu đồ phổ biểu diễn tần số của sóng âm thanh theo thời gian. Trục x là thời gian và trục y là tần số. Màu vàng càng nhiều thì tần số hoạt động càng lớn.
Dữ liệu đầu vào cho mô hình của chúng ta sẽ là dữ liệu phổ tần số theo thời gian cho từng âm thanh được tạo. Và đầu ra của mô hình là các nhãn chúng ta đã tạo ra trước đó.
Xây dựng Model
Đầu vào của chúng ta sẽ là các audio stream là một vector cường độ dao động theo thời gian. Trước khi đưa vào mô hình chúng ta phải trải qua một bước trích chọn đặc trưng là Fourier transform để lấy ra phổ tần số theo thời gian. Mô hình được thể hiện chi tiết bên dưới.
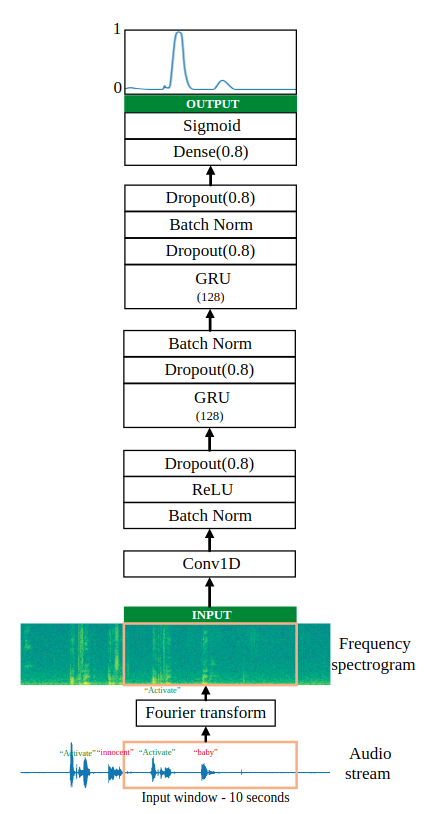
Bước tích chập 1D giúp trích xuất các tính năng âm thanh cấp thấp tương tự như cách kết hợp 2D trích xuất các tính năng hình ảnh. Điều này cũng giúp tăng tốc mô hình bằng cách giảm số lượng dấu thời gian.
Hai lớp GRU đọc chuỗi các đầu vào từ trái sang phải, sau đó cuối cùng sử dụng lớp fully connected với hàm kích hoạt sigmoid để đưa ra dự đoán. Sigmoid làm cho phạm vi của mỗi nhãn trong khoảng 0 ~ 1. 1 ứng với nhãn cho từ hotword.
def model(input_shape):
x_input = Input(shape = input_shape)
x = Conv1D(196, kernel_size=15, strides=4)(x_input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Dropout(0.8)(x)
x = GRU(units = 128, return_sequences = True)(x)
x = Dropout(0.8)(x)
x = BatchNormalization()(x)
x = GRU(units = 128, return_sequences = True)(x)
x = Dropout(0.8)(x)
x = BatchNormalization()(x)
x = Dropout(0.8)(x)
x = TimeDistributed(Dense(1, activation = "sigmoid"))(x)
model = Model(inputs = x_input, outputs = x)
return model
model = model(input_shape = (Tx, n_freq))
model.summary()
Với input_shape bao gồm số time steps theo phổ tần số và số tần số của đầu vào ứng với mỗi step. Mình có tham khảo một repository trên gihub để viết bài này nên thật hay khi có thể sử dụng luôn bộ dataset mà tác giả public để thử nghiệm mô hình. Dữ liệu huấn luyện luôn có sẵn tại đây. Với các spectrogram của audio đầu vào có kích thước là (5511, 101)(khoảng 10s). Hình dạng của mô hình cụ thể như sau:
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 5511, 101) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 1375, 196) 297136
_________________________________________________________________
batch_normalization_1 (Batch (None, 1375, 196) 784
_________________________________________________________________
activation_1 (Activation) (None, 1375, 196) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 1375, 196) 0
_________________________________________________________________
gru_1 (GRU) (None, 1375, 128) 124800
_________________________________________________________________
dropout_2 (Dropout) (None, 1375, 128) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 1375, 128) 512
_________________________________________________________________
gru_2 (GRU) (None, 1375, 128) 98688
_________________________________________________________________
dropout_3 (Dropout) (None, 1375, 128) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 1375, 128) 512
_________________________________________________________________
dropout_4 (Dropout) (None, 1375, 128) 0
_________________________________________________________________
time_distributed_1 (TimeDist (None, 1375, 1) 129
=================================================================
Total params: 522,561
Trainable params: 521,657
Non-trainable params: 904
Trong khi huẩn luyện mô hình, hàm loss được sử dụng là hàm binary_crossentropy.
opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=["accuracy"])
X = np.load("./XY_train/X.npy")
Y = np.load("./XY_train/Y.npy")
X_dev = np.load("./XY_dev/X_dev.npy")
Y_dev = np.load("./XY_dev/Y_dev.npy")
model.fit(X, Y, batch_size = 64, epochs=20)
Sau khi huẩn luyện mô hình và save weight mô hình thu được, khi tiến hành dự đoán chúng ta cũng sử dụng lại quá trình biến đối spectrogram của file test tương tự như quá trình tiền xử lý với dữ liệu training để tiến hành dự đoán.
Cách sử dụng mô hình Real-time
Tính đến thời điểm hiện tại, mô hình của chúng ta đã thể lấy một đoạn âm thanh tĩnh với chiều dài cố định và đưa ra dự đoán về vị trí hotword.
Dữ liệu đầu vào khi sử dụng không phải là các đoạn âm thanh tĩnh, nó là các luồng âm thanh trực tiếp được thiết bị thu về liên tục. Mô hình chúng ta đã xây dựng để nhận một đoạn âm thanh có chiều dài cố định làm đầu vào. Chúng ta có thể chia âm thanh đầu vào thành các frame ngắn để cho vào mô hình dự đoán nhưng đó không phải là một công việc thú vị. Nếu chia thành các đoạn âm thanh nhỏ 10s thì chúng ta phải đợi 10s để có được đầu vào cho mô hình. Điều đó không có ý nghĩa thực tế vì sở thích thích real-time của người dùng. Vì vậy, một giải pháp được đưa ra là có một cửa sổ trượt, trượt qua đoạn âm thanh đầu vào với kích thước cửa sổ trượt là 10s là bước nhảy là 0.5s. Điều đó có nghĩa là chúng ta yêu cầu mô hình cứ sau 0,5 giây lại thực hiện 1 dự đoán, điều đó làm giảm độ trễ và làm cho thiết bị phản hồi nhanh hơn. Để thực hiện 1 mục tiêu real-time của mô hình, chúng ta lại phải trả 1 cái giá khác đó là khối lương tính toán tăng lên rất nhiều so với kiểu cũ. Để hạn chế điều này, chúng ta có thể thêm một cơ chế tiền xử lý là phát hiện im lặng để bỏ qua việc dự đoán cho mô hình nếu cường độ âm dưới ngưỡng, điều này có thể tiết kiệm được khá nhiều về khối lượng tính toán.
Tham khảo
All rights reserved
