Hiểu về Kubernetes OOM & CPU Throttling và tối ưu hoá tài nguyên cho ứng dụng
This post hasn't been updated for 3 years
Khi làm việc với Kubernetes, lỗi Hết bộ nhớ (OOM) và điều tiết CPU là những vấn đề đau đầu chính trong việc xử lý tài nguyên trong các ứng dụng đám mây. Tại sao vậy?
Các yêu cầu về CPU và Bộ nhớ trong các ứng dụng đám mây ngày càng quan trọng hơn bao giờ hết vì chúng liên quan trực tiếp đến chi phí sử dụng cloud của bạn.
Với các giới hạn và yêu cầu, bạn có thể định cấu hình các pods của mình sẽ phân bổ tài nguyên bộ nhớ và CPU để ngăn chặn tình trạng cạn kiệt tài nguyên và điều chỉnh chi phí sử dụng cloud.
- Trong trường hợp một Node không có đủ tài nguyên, các Pods có thể bị loại bỏ thông qua quyền ưu tiên hoặc áp lực node.
- Khi một quá trình hết bộ nhớ (OOM), nó sẽ bị hủy vì không có tài nguyên cần thiết.
- Trong trường hợp mức tiêu thụ CPU cao hơn giới hạn thực tế, quá trình sẽ bắt đầu được điều chỉnh.
Tuy nhiên, làm cách nào để bạn có thể chủ động theo dõi mức độ đóng Kubernetes Pods của mình với OOM và điều tiết CPU?
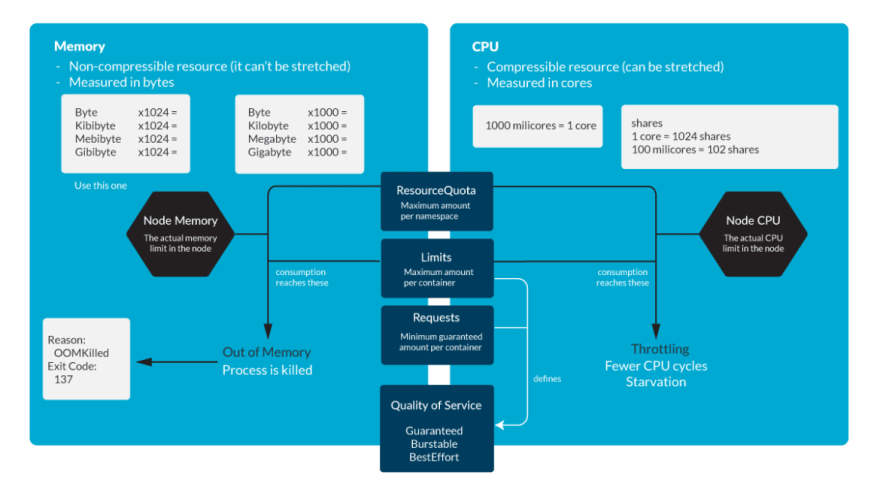
Kubernetes OOM Mọi container trong Pod đều cần bộ nhớ để chạy. Giới hạn Kubernetes được đặt cho mỗi vùng chứa theo định nghĩa Pod hoặc định nghĩa Deployment. Tất cả các hệ thống Unix hiện đại đều có cách để giết các tiến trình trong trường hợp chúng cần lấy lại bộ nhớ. Điều này sẽ được đánh dấu là Lỗi 137 hoặc OOMKilled.
State: Running
Started: Thu, 10 Oct 2019 11:14:13 +0200
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Thu, 10 Oct 2019 11:04:03 +0200
Finished: Thu, 10 Oct 2019 11:14:11 +0200
Code 137 này có nghĩa là quy trình đã sử dụng nhiều bộ nhớ hơn mức cho phép và phải kết thúc.
Đây là một tính năng có trong Linux, trong đó kernel đặt giá trị oom_score cho tiến trình đang chạy trong hệ thống. Ngoài ra, nó cho phép thiết lập một giá trị gọi là oom_score_adj, được Kubernetes sử dụng để cho phép Quality of Service. Nó cũng có tính năng OOM Killer, sẽ xem xét quy trình và chấm dứt những quy trình đang sử dụng nhiều bộ nhớ hơn mức cần thiết.
Lưu ý rằng trong Kubernetes, một quy trình có thể đạt đến bất kỳ giới hạn nào sau đây:
- Giới hạn Kubernetes được đặt trên container.n
- Kubernetes ResourceQuota được đặt trên namespace.
- Kích thước bộ nhớ thực tế của Node.
- Biểu đồ Kubernetes OOM
Cam kết quá mức bộ nhớ
Giới hạn có thể cao hơn yêu cầu, vì vậy tổng tất cả các giới hạn có thể cao hơn dung lượng của nút. Điều này được gọi là overcommit và nó rất phổ biến. Trong thực tế, nếu tất cả các container sử dụng nhiều bộ nhớ hơn yêu cầu, nó có thể làm cạn kiệt bộ nhớ trong node. Điều này thường gây ra cái chết của một số Pods để giải phóng một số bộ nhớ.
Giám sát Kubernetes OOM
Khi sử dụng trình xuất nút trong Prometheus, có một số liệu được gọi là node_vmstat_oom_kill. Điều quan trọng là phải theo dõi thời điểm một vụ tiêu diệt OOM xảy ra, nhưng bạn có thể muốn tiếp tục và có tầm nhìn về một sự kiện như vậy trước khi nó xảy ra.
Thay vào đó, bạn có thể kiểm tra mức độ gần của một quy trình với giới hạn Kubernetes:
(sum by (namespace,pod,container)
(rate(container_cpu_usage_seconds_total{container!=""}[5m])) / sum by
(namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"})) > 0.8
Điều tiết CPU Kubernetes
Điều tiết CPU là một hành vi trong đó các tiến trình trình bị chậm lại khi chúng sắp đạt đến một số giới hạn tài nguyên. Tương tự như trường hợp bộ nhớ, các giới hạn này có thể là:
Giới hạn Kubernetes được đặt trên container
Kubernetes ResourceQuota được đặt trên không gian tên. Kích thước bộ nhớ thực tế của nodes.
Hãy nghĩ về sự tương tự sau đây. Chúng ta có một đường cao tốc với một số phương tiện giao thông:
- CPU là con đường.
- Phương tiện đại diện cho quá trình, trong đó mỗi chiếc có kích thước khác nhau.
- Nhiều làn đại diện cho việc có nhiều lõi. Yêu cầu sẽ là một con đường dành riêng, chẳng hạn như làn đường dành cho xe đạp.
- Throttling ở đây được thể hiện dưới dạng tắc nghẽn giao thông: cuối cùng, tất cả các quy trình sẽ chạy, nhưng mọi thứ sẽ chậm hơn.
CPU Process trong Kubernetes
CPU được xử lý trong Kubernetes có chia sẻ. Mỗi lõi CPU được chia thành 1024 phần chia sẻ, sau đó được chia cho tất cả các tiến trình đang chạy bằng cách sử dụng tính năng cgroups (nhóm điều khiển) của nhân Linux.
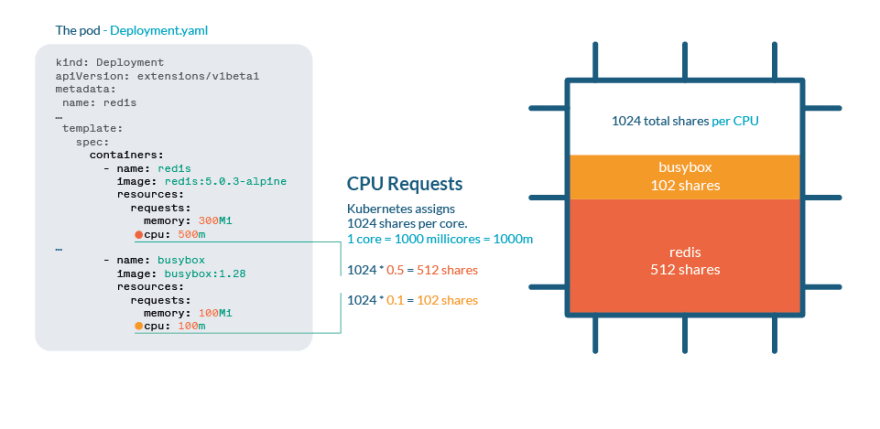
Nếu CPU có thể xử lý tất cả các quy trình hiện tại thì không cần thực hiện hành động nào. Nếu các quy trình đang sử dụng hơn 100% CPU, thì việc chia sẻ sẽ được thực hiện. Giống như bất kỳ Nhân Linux nào, Kubernetes sử dụng cơ chế CFS (Bộ lập lịch hoàn toàn hợp lý), do đó, các quy trình có nhiều lượt chia sẻ hơn sẽ nhận được nhiều thời gian hơn cho CPU.
Không giống như bộ nhớ, Kubernetes sẽ không giết Pods vì điều tiết CPU.
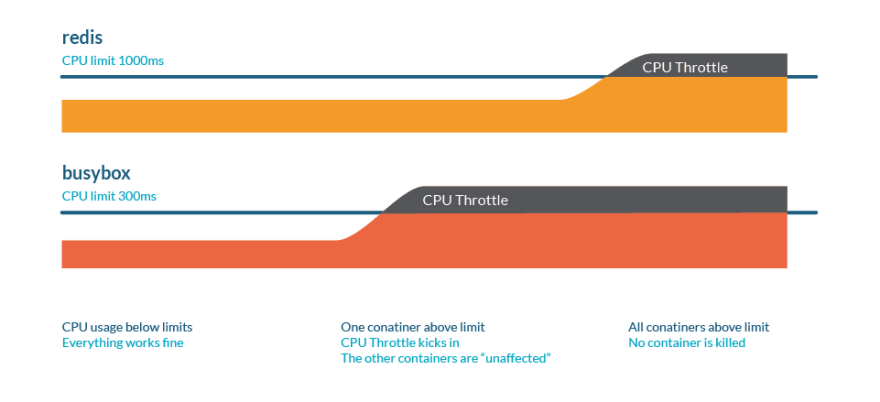
Bạn có thể kiểm tra số liệu thống kê CPU trong /sys/fs/cgroup/cpu/cpu.stat
CPU overcommit
Như chúng ta đã thấy trong bài viết về giới hạn và yêu cầu, điều quan trọng là phải đặt giới hạn hoặc yêu cầu khi chúng ta muốn hạn chế mức tiêu thụ tài nguyên của các quy trình của mình. Tuy nhiên, hãy cẩn thận khi thiết lập tổng số yêu cầu lớn hơn kích thước CPU thực tế, vì điều này có nghĩa là mọi container phải có một lượng CPU được đảm bảo.
Giám sát điều tiết CPU Kubernetes
Bạn có thể kiểm tra mức độ gần của một quy trình với giới hạn Kubernetes:
(sum by (namespace,pod,container)(rate(container_cpu_usage_seconds_total
{container!=""}[5m])) / sum by (namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"})) > 0.8
Trong trường hợp chúng ta muốn theo dõi số lượng điều chỉnh xảy ra trong cụm của mình, cadvisor cung cấp container_cpu_cfs_throttled_periods_total và container_cpu_cfs_periods_total. Với hai cái này, bạn có thể dễ dàng tính toán % điều tiết trong tất cả các chu kỳ CPU.
Best practices
Cẩn thận với các limit và requests
Giới hạn là một cách để thiết lập giới hạn tối đa cho các tài nguyên trong node của bạn, nhưng những giới hạn này cần được xử lý cẩn thận, vì ứng dụng của bạn có thể kết thúc bằng một quy trình bị điều chỉnh hoặc bị loại bỏ.
Chuẩn bị chống trục xuất
Bằng cách đặt các yêu cầu rất thấp, bạn có thể nghĩ rằng điều này sẽ cấp tối thiểu CPU hoặc Bộ nhớ cho các tiến trình của bạn. Nhưng kubelet sẽ loại bỏ những Pod có mức sử dụng cao hơn yêu cầu trước tiên, vì vậy bạn đang đánh dấu những Pod đó là những Pod đầu tiên bị loại bỏ!
Trong trường hợp bạn cần bảo vệ các Pods cụ thể khỏi bị ưu tiên (khi kube-scheduler cần phân bổ một Pods mới), hãy chỉ định các Priority Classes cho các quy trình quan trọng nhất của bạn.
Throttling là một kẻ thù thầm lặng
Bằng cách đặt các giới hạn không thực tế hoặc cam kết quá mức, bạn có thể không biết rằng các quy trình của mình đang bị điều chỉnh và hiệu suất bị ảnh hưởng. Chủ động theo dõi mức sử dụng CPU của bạn và biết giới hạn thực tế của bạn trong cả container và namespace. Một minh hoạ về quản lý CPU và memory của kubernetes
Ở đây mình ví dụ với dịch vụ Sun Spinner của Sunteco Cloud. Đầu tiên, bạn cần chọn đúng các tài nguyên cho các ứng dụng container:

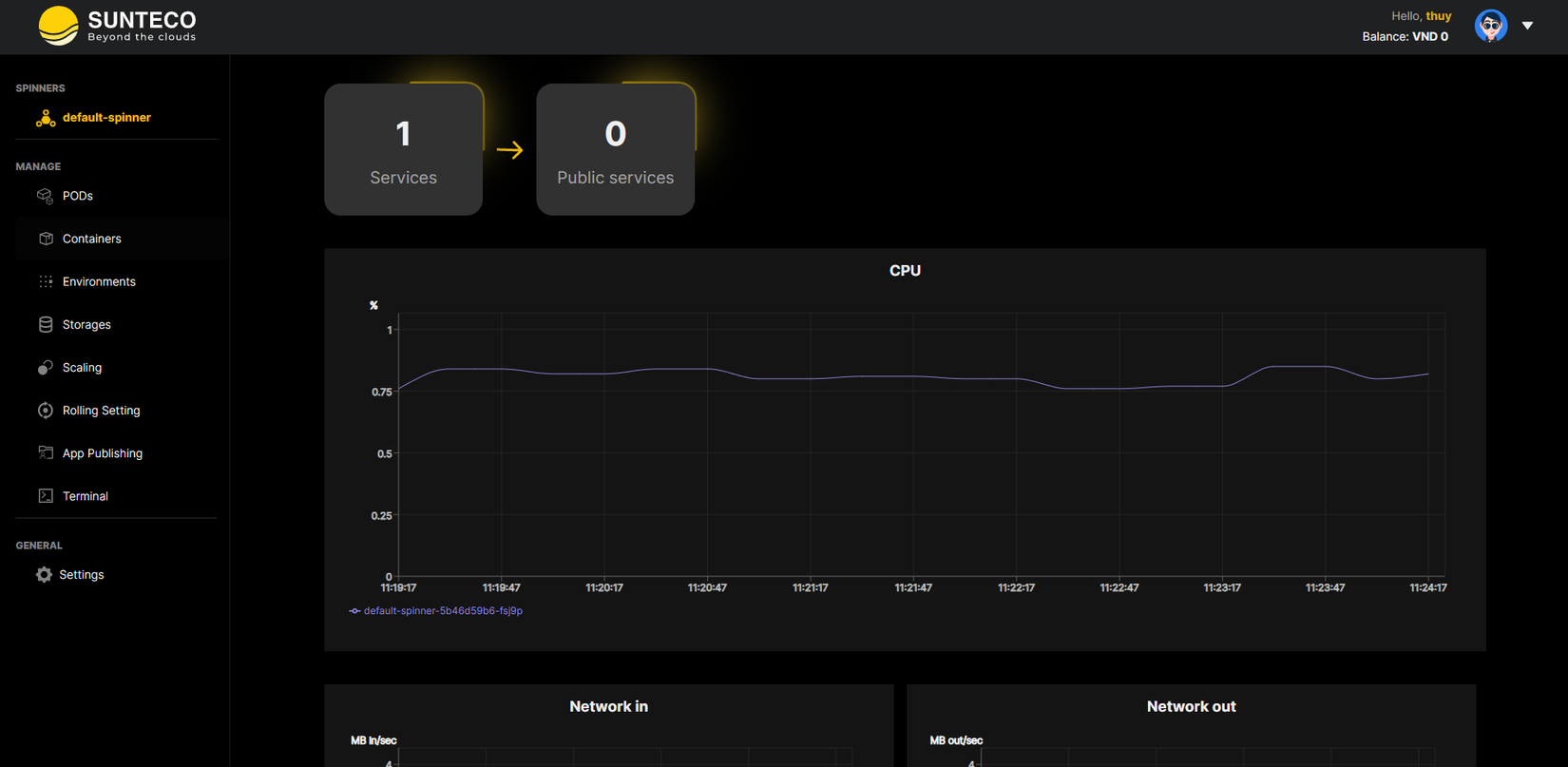
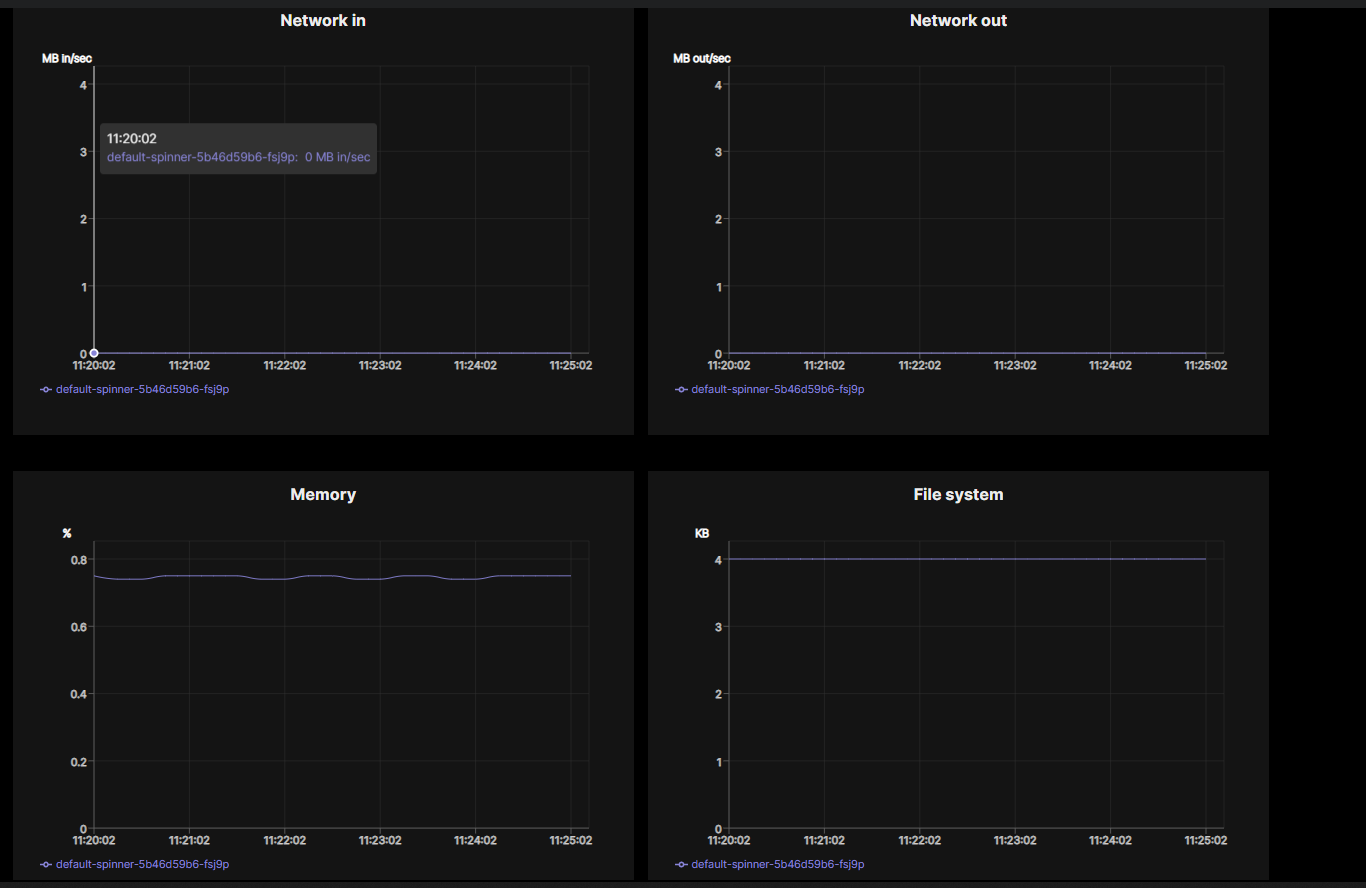
Điểm đặc biệt của Sun Spinner là cho phép người dùng dễ dàng theo dõi các thông số CPU, RAM của container, đồng thời điều chỉnh hợp lý các tài nguyên cho các pods để đảm bảo tất cả hoạt động tối ưu.
Các bạn có thể tự mình trải nghiệm dịch vụ Sun Spinner tại đây.
Nếu bạn có bất kỳ thắc mắc liên quan đến bài viết, hãy để lại bình luận bên dưới. Mình sẽ trả lời sớm nhất có thể!
All Rights Reserved
