Hiểu cơ bản khái niệm Auto-scale của K8S
Bài đăng này đã không được cập nhật trong 5 năm
Định nghĩa autoscaling?
Auto-scaling là cách thức tự động tăng/giảm tài nguyên máy tính mà được cấp cho app của chúng ta bất kì thời điểm nào khi cần. Điều này giúp tạo ra những hệ thống trên cloud có khả năng mở rộng 24/24 nhằm đáp ứng nhu cầu sử dụng.
HPA là gì?
HPA viết tắt từ Horizontal Pod Autoscaler - có thể hiểu đây là một bộ điều hành việc scale theo chiều ngang các Pod.
HPA đem lại các lợi ích: kinh tế, tự động hóa việc tăng giảm cấu hình hệ thống phù hợp với các hệ thống có khối lượng tải (mức enduser sủ dụng) biến đổi nhiều và khó dự đoán.
So với mô hình "truyền thống" kiểu fix cứng số lượng các pods, Auto scaling thích ứng để phù hợp với nhu cầu sử dụng. Chẳng hạn, khi lượng truy cập vào hệ thống vào buổi đêm giảm xuống, các pods có thể được set vào sleep mode (sleep mode để còn bật lại ngay đối phó với sự tăng bất thường từ lượng truy cập  )
)
Việc thiết lập HPA yêu cầu:
1. Metrics Server
Metrics Server là một server tập hợp lại các metrics (chỉ số đo lường) của các container (các pods) phục vụ cho chu trình autoscaling tích hợp trong K8S
Các bạn có thể nhìn trên sơ đồ trên, từng bước:
- Các metrics (mức sử dụng RAM, CPU) được thu thập từ các pods
- Các metrics này được đấy đến
kubelet - Metrics Server thu thập metrics thông qua
kubelet - Metrics được đẩy đến API server, HPA sẽ gọi API này để lấy các metrics, tính toán để scale pods.
Chú ý Metrics Server không dành cho các mục đích khác auto-scaling. Ví dụ, đừng dùng nó như một cách để monitor (theo dõi) hệ thống.
Cài đặt Metrics Server:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
Đối với KOPS:
Nếu bạn đang sử dụng kops để quản lý cluster, thì cần phải enble một config nữa để cho phép chạy metrics-server
https://github.com/kubernetes/kops/tree/master/addons/metrics-server
Kiểm tra việc cài đặt Metrics-Server:
Sau khi cài metrics server, command kubectl sẽ có thể sử dụng được. command này sẽ get metrics hiện tại của pods và nods. Nếu ta gõ command mà ko chạy thì có nghĩa việc cài đặt Metrics-server đã failed!
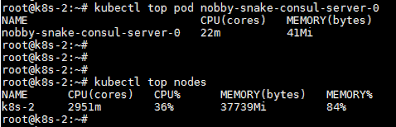
kubectl top node
kubectl top pod
2. Cluster Auto-Scaler
Khi Ban điều hành HPA tăng số lượng pod, thì rõ ràng node cũng cần phải được tăng thêm để đáp ứng được số pod mới này.
Cluster Auto-Scaler là một chức năng trong K8S, chịu trách nhiệm tăng / hoặc giảm số lượng của node sao cho phù hợp với số lượng pods vận hành.
Cluster Auto-Scaler sẽ điều chỉnh tự động kích thước của Kubernetes cluster (hay số nodes) khi một trong các điều kiện sau thỏa mãn:
- Một số pods run bị fail trong cluster do lý do không đủ tài nguyên.
- Có node trong cluster không được sử dụng hết công suất, và các pods của nó có thể vận hành được trên các node khác (đang có sẵn) mà có tài nguyên đang dư dả.
https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler
Cài đặt Cluster Auto-Scaler:
Chúng ta có thể xem hướng dẫn cài đặt Cluster Auto-Scaler trên từng nền tảng khác nhau theo các tài liệu dưới đây:
- GCE https://kubernetes.io/docs/concepts/cluster-administration/cluster-management/
- GKE https://cloud.google.com/container-engine/docs/cluster-autoscaler
- AWS https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
- Azure https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
- Alibaba Cloud https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
- OpenStack Magnum https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/magnum/README.md
- DigitalOcean https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/digitalocean/README.md
Kiểm tra việc cài đặt Cluster Auto-scaler:
Thử deploy một ứng dụng và nâng số lượng pod lên vượt mức tài nguyên của số node hiện tại. Nếu cluster auto-scaler tạo được node mới, và xóa node khi ta giảm pod đi thì có nghĩa việc cài đặt của chúng ta đã thành công.
3. Thiết lập các thông số Requests/Limits của tài nguyên và xác định trạng thái Liveness/Readiness
HPA dựa vào lượng % CPU được sử dụng để tính toán ra số pod cần scale, nên ta cầ phải hiểu được cách thức tính toán từ đó xác định được các thông số request/limit phù hợp cho từng pod. Tham khảo thêm [bài viết này] (https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/) để có được kiến thức cần thiết nhé.
Một pod đang chạy nhưng app bên trong nó có vấn đề, nếu không xác định được điều này thì cơ chế của HPA có thể gặp ảnh hưởng, khiến việc xác định số pod cần scale không chính xác. Tham khảo thêm tại đây
4. Tổng thể chu trình của việc scale
- Metrics server tổng hợp các thông số từ các pods hiện tại
- HPA sẽ check các thông số trên 15s một lần, nếu giá trị rơi vào khoảng thiết lập trong HPA thì nó sẽ tiến hành tăng/ giảm số lượng pods
- Trong trường hợp scale-up, (Một bộ phận tên) Kubernetes scheduler sẽ tạo một pods vào node mà có đủ tài nguyên mà pod yêu cầu
- Nếu không đủ tài nguyên, Cluster auto-scaler sẽ tăng số node lên để đáp ứng với lượng pod mà đang được dự định tạo mới
- Trong trường hợp scale-down, HPA sẽ giảm số lượng pod
- Cluster scaler nếu thấy các node đang "rảnh", và pods của 1 node X nào đó có thể chuyển sang một node khác để tận dụng tài nguyên thì pod sẽ chuyển sang, và node X đó sẽ được xóa (scale-down) đi)
HPA tính toán để scale như thế nào?
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
HPA được sử dụng để tự động scale (up/down) số lượng pod dựa trên việc thu thập, đánh giá các số liệu sử dụng hiện tại của CPU, Memory (hoặc có thể là metric khác mà bạn tự định nghĩa, nhưng phổ biến vẫn là CPU hoặc Memory)
HPA sẽ (theo mặc định) cứ 15s một lần sẽ kiểm tra các thông số CPU/ Memory sử dụng trên các pods hiện tại, và đối chiếu với khoảng thiết lập (mong muốn) của nó.
Công thức cụ thể như sau
tổngSốPodsCần = ceil[SốPodHiệnTại * ( ThôngSốHiệnTại / ThôngSốMongMuốn )]
Phép ceil là phép toán làm tròn lên
Ví dụ, Bạn mong muốn RAM sử dụng duy trì ở mức 500MB, nhưng hiện tại nhu cầu tăng lên đến 700MB, số Pods hiện tại đang là 1, thì
tổngSốPodsCần = ceil[1 * (700/500)]
Rõ ràng là Số Pod Cần sẽ phải Tỉ lệ thuận với Thông Số Hiện Tại, Thông số hiện tại đo được mà cao hơn mức mong muốn tức là hệ thống đang quá tải, cần phải scale lên, và ngược lại.
File thiết lập HPA (HPA Manifest):
Cuối cùng, mình sẽ giới thiệu file thiết lập HPA qua ví dụ dưới đây.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
Trong ví dụ này, hệ thống sẽ đc scale-up khi mức sử dụng CPU trung bình của các pod lớn hơn hoặc bằng 50% và ngược lại, scale-down khi mức tiêu thụ CPU dưới 50%
Nguồn bài viết: https://medium.com/devops-for-zombies/understanding-k8s-autoscale-f8f3f90938f4
All rights reserved
