
Hệ thống lớn sẽ quản lý Cron Job như thế nào ??? - Bài học thực tế từ Slack
Bài đăng này đã không được cập nhật trong 2 năm
Anh em đã biết đến Slack như là nền tảng làm việc hiện đại, nơi mọi người có thể giao tiếp, cộng tác và hoàn thành công việc một cách hiệu quả. Bằng cách kết hợp nhắn tin, công cụ và ứng dụng vào một không gian làm việc chung, Slack giúp các nhóm làm việc nhanh hơn, thông minh hơn và gắn kết hơn.
Một trong các thành phần quan trọng trong thiết kế của Slack đó chính là các Cron Job. Các Cron job sẽ đảm nhiệm thực thi các tác vụ quan trọng tại Slack như lập lịch và tự động gửi email, thông báo tin nhắn, nhắc lịch hẹn hay dọn dẹp các dữ liệu dư thừa.
Cùng với sự phát triển nhanh chóng của công ty và các nghiệp vụ liên quan trở lên phức tạp hơn thì số lượng các cron script và độ phức tạp các job cần chạy cũng tăng lên theo. Khiến cho việc bảo trì và quản lý việc chạy các Cron script trở lên vô cùng khó khăn, giảm độ tin cậy (reliability) của hệ thống
Cùng Sydexa tìm hiểu cách mà Slack phát triển một hệ thống ổn định hơn nha
Bạn cho chúng mình xin 1 upvote và comment để chúng mình nhận giải của viblo nha. Và chúng mình có động lực ra những bài viết thú vị hơn nữa 😄😄😄
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
1. Hiện trạng tại Slack lúc đó:
Hệ thống chạy các cron job của Slack gồm có 1 máy chủ đơn lẻ chứa các file scripts thực thi của các job và 1 crontab file với các thông tin về thời gian và cách lập lịch chạy cho các file script đó
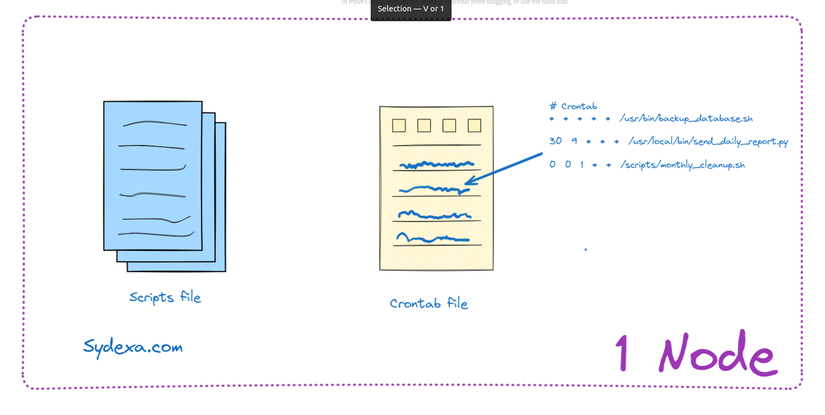
Ban đầu, một máy chủ đơn lẻ này sẽ đảm nhiệm việc thực thi tất cả các tập lệnh cron tại Slack. Tuy nhiên, khi quy mô hệ thống tăng lên, giải pháp này trở nên khó duy trì và quản lý.
Một giải pháp tạm thời đã được đưa ra là mở rộng theo chiều dọc (Vertical scaling), đơn giản chỉ là tăng số lượng core CPU và Ram để node này có thể xử lý được nhiều script hơn, nhưng kéo theo đó là chi phí vận hành tăng lên.
Tuy nhiên, mô hình này vẫn tiềm ẩn nhiều rủi ro - chỉ cần node xử lý cronjob gặp sự cố thì toàn bộ dịch vụ sẽ bị đình trệ, kéo theo sự gián đoạn của một số chức năng quan trọng trên Slack.
Và họ đã đưa đến quyết định xây dựng một thiết kế khác ổn định hơn để có thể sẵn sàng cho số lượng cron job lớn hơn mà vẫn đảm bảo được sự ổn định của hệ thống
2. Giải pháp mới tăng độ ổn định một cách lâu dài:
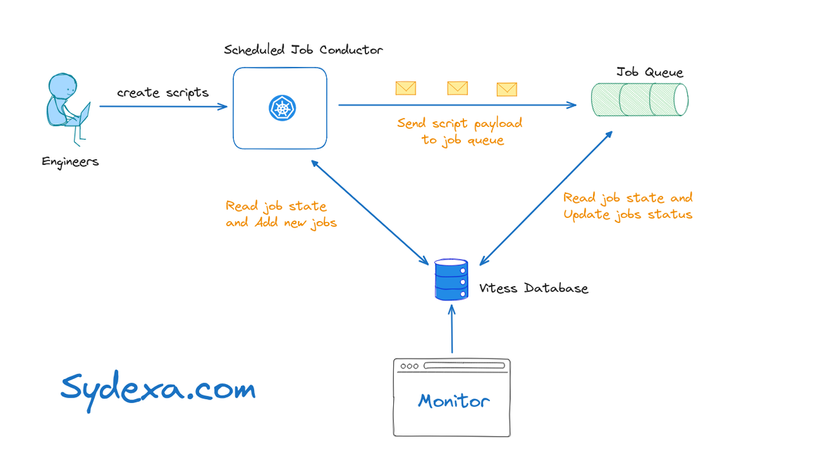
Trên là sơ đồ kiến trúc mới để xử lý các cron job của slack, hệ thống sẽ có 3 thành phần chính:
Scheduled Job Conductor: Một service được viết bằng Golang và triển khai trên Bedrock (Một công cụ được xây dựng xung quanh K8S được phát triển nội bộ tại slack)
Job Queue: một thành phần hiện có tại Slack, phục vụ rất nhiều yêu cầu khác nhau. Đây là một nền tảng tính toán không đồng bộ, xử lý khoảng 9 tỷ tác vụ mỗi ngày và bao gồm nhiều "hàng đợi" khác nhau.
Vitess database table: Giúp loại bỏ trùng lặp và giám sát công việc, nhằm tăng cường khả năng hiển thị xung quanh việc chạy và lỗi của các cron job.
Chúng ta cùng đi vào từng thành phần này để hiểu hơn bên trong đó có gì nhé
1. Scheduled Job Conductor
Service này bắt chước các tính năng của cron bằng cách sử dụng thư viện cron của ngôn ngữ lập trình Golang. Điều hay ho là thư viện này cho phép họ giữ lại được format của cron string, qua đó sẽ giảm thiểu việc thay đổi cấu trúc của crontab, đơn giản hoá quá trình migrate giảm thiểu những lỗi không đáng có.
Về triển khai thì Slack dùng một công cụ nội bộ được xây dựng bao quanh Kubernetes, giúp cho việc scale lên nhiều pods trở lên dễ dàng. Nhưng sẽ chỉ có 1 pod được dùng để xử lý các nhiệm vụ trong khi các pod còn lại sẽ ở trạng thái sẵn sàng chờ được kích hoạt và được dùng khi pod chính gặp sự cố.
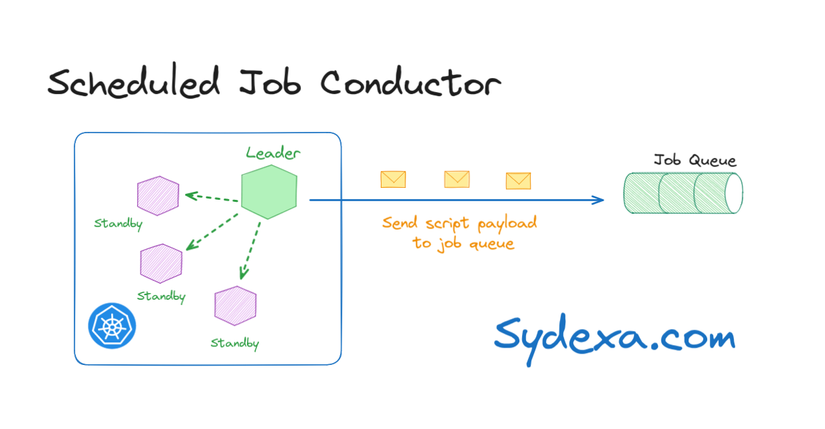
Việc chọn lựa 1 pod thay vì nhiều pod cùng chạy là do nếu nhiều pod cùng chạy thì độ phực tạp sẽ tăng lên và phải xử lý xung đột giữa các pod.
Các pod chỉ đóng vai trò lên lịch còn những công việc đòi hỏi khối lượng tính toán lớn hơn sẽ được chuyển giao cho Job Queue thực hiện
2. Slack Job Queue:
Các hàng đợi này hoạt động như những đường dẫn logic, chuyển các job thông qua Kafka vào Redis - nơi lưu trữ các metadata của chúng (ví dụ: thông tin liên quan đến việc worker nào đang chạy job này). Từ Redis, các tác vụ cuối cùng được chuyển cho worker đảm nhiệm xử lý và thực thi các cron job.
Trong kiến trúc này, mỗi "job" tương ứng với một tập lệnh cron đơn lẻ. Job Queue có thể thực thi các tập lệnh này cực kỳ nhanh chóng nếu chúng được phân tách vào "hàng đợi" riêng biệt.
Nhờ tận dụng Job Queue có sẵn của Slack, các kỹ sữ đã không chỉ giảm tải được những lo ngại về tài nguyên tính toán và bộ nhớ mà còn giúp rút ngắn đáng kể thời gian xây dựng ban đầu và giảm thiểu nỗ lực bảo trì về sau – một mũi tên chúng hai đích
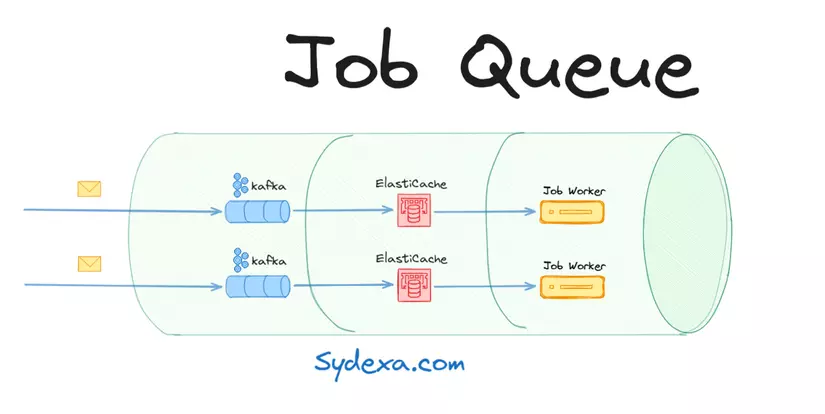
Vitess database table:
Cuối cùng, Slack sử dụng bảng Vitess - một cơ sở dữ liệu tương thích với MySQL có khả năng mở rộng cao trên nền tảng đám mây - để quản lý dữ liệu của các tác vụ (job). Bảng Vitess này có hai nhiệm vụ chính:
- Xử lý vấn đề trùng lặp dữ liệu, đảm bảo tính chính xác và nhất quán của thông tin tác vụ.
- Báo cáo và theo dõi trạng thái các tác vụ cho người dùng nội bộ, giúp họ có cái nhìn tổng quan về quá trình thực thi và phát hiện kịp thời các sự cố.

Hình ảnh trên minh họa dữ liệu trong Vitess database table
Mỗi lần thực thi một tác vụ (Job) sẽ được ghi lại dưới dạng một hàng mới trong bảng Vitess. Đồng thời, trạng thái của tác vụ cũng được cập nhật liên tục khi nó chuyển qua các giai đoạn khác nhau (được đưa vào hàng đợi, đang xử lý, hoàn thành).
Trước khi khởi động một lượt chạy mới của một tác vụ, hệ thống sẽ kiểm tra xem liệu có một phiên bản khác của tác vụ đó đang chạy hay không???. Bảng Vitess này còn đóng vai trò là nền tảng cho một trang web hiển thị thông tin thực thi của các tập lệnh cron.
Trang web này cho phép người dùng tra cứu trạng thái của các lần chạy tập lệnh và bất kỳ lỗi nào mà hệ thống gặp phải.
Và đó là hành trình Slack tạo ra một hệ thống mới giúp thực thi các cronjob một cách ổn định hơn rất nhiều, có khả năng mở rộng tốt hơn. Hệ thống này sẵn sàng cho rất nhiều cơ hội phát triển những tính năng phức tạp trong tương lai.
Nếu thấy bài viết này hay thì cho chúng mình xin 1 upvote và comment để chúng mình nhận giải của viblo nha 😄😄😄
Lời nhắn
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Bạn có thể tìm hiểu thêm:
Chia sẻ từ chính Slack: https://slack.engineering/executing-cron-scripts-reliably-at-scale/
Bedrock: https://slack.engineering/applying-product-thinking-to-slacks-internal-compute-platform/
Slack’s Job Queue: https://slack.engineering/scaling-slacks-job-queue/
Vitess: https://vitess.io/
All rights reserved
