Hệ điều hành máy tính hoạt động như thế nào? (phần 3)
Bài đăng này đã không được cập nhật trong 6 năm

Lời mở đầu
Bài viết thứ 3, cũng là bài viết cuối cùng trong loạt bài tìm hiểu về các hoạt động của hệ điều hành máy tính. Ở trong bài viết này, mình sẽ tìm hiểu và trình bày về một số hoạt động ít khi được chú ý nhưng vẫn đóng vai trò quan trọng trong hệ thống. Đó là Inter-Process Communication (truyền thông liên tiến trình), Distributed File Systems (hệ thống tệp tin phân tán) và Distributed Shared Memory (bộ nhớ chia sẻ phân tán).
1. Inter-Process Communication
Trong hệ thống tiến trình của máy tính thì sẽ có hai loại: Independent (tiến trình độc lập) và Cooporating (tiến trình hợp tác). Một tiến trình độc lập sẽ hoạt động mà không bị ảnh hưởng bởi các tiến trình khác, tức là nó có thể luôn đảm bảo được công việc mà nó thực thi. Ngược lại, khi tiến trình hợp tác hoạt động, nó có thể bị ảnh hưởng bởi các tiến trình liên quan, thậm chí có thể gây gián đoạn vô thời hạn.
Nếu chỉ nhìn qua khái niệm, ta có thể thấy rõ ràng tiến trình độc lập sẽ thực thi hiệu quả hơn, do nó không phải phụ thuộc vào cái gì ngoài bản thân tập lệnh của nó. Tuy nhiên, trong thực tế thì các tiến trình hợp tác mới thực sự là cái đem lại hiệu quả cao. Do các vấn đề liên quan đến tốc độ, sự thuận tiện và tính mô đun hóa mà tiến trình hợp tác sẽ đem lại hiệu quả tốt hơn. Khái niệm Inter-Process Communication (IPC) ra đời như là một cơ chế cho phép các tiến trình giao tiếp với nhau và đồng bộ hóa các hành động của chúng. Quá trình giao tiếp có thể giúp các tiến trình biết được trình trạng hoạt động, cũng như tình trạng sử dụng tài nguyên để phân bổ thời gian hợp lý.
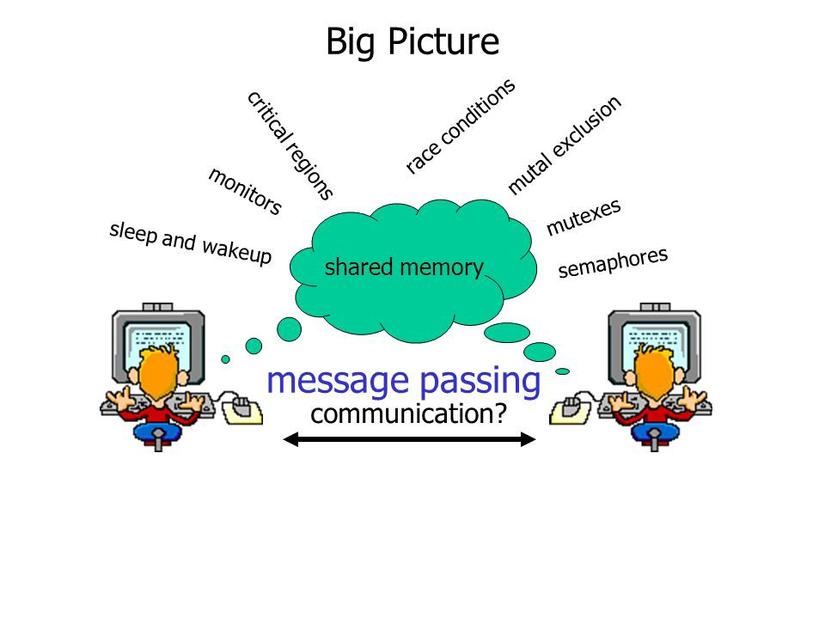
Các tiến trình có thể giao tiếp với nhau theo hai cách: Shared Memory(chia sẻ bộ nhớ) và Message Parsing (phân tích thông điệp).
1.1) Phương pháp Shared Memory
Giả sử ta có hai tiến trình, phân biệt gọi là Producer (tiến trình sản xuất) và Consumer (tiến trình tiêu thụ). Tiến trình sản xuất tạo ra một số vật phẩm và tiến trình tiêu thụ sẽ dùng những vật phẩm này. Hai tiến trình chia sẻ một không gian chung hoặc vị trí bộ nhớ nào đó được gọi là bộ đệm. Vật phẩm nói trên sẽ được tiến trình sản xuất lưu trữ trong bộ đệm này và tiến trình tiêu thụ sẽ lấy nó ra khi cần.
Vấn đề này sẽ có 2 hướng giải quyết:
- Cái đầu tiên còn được biết đến là
Unbounded Buffer Problem, trong đó tiến trình sản xuất có thể tiếp tục tạo ra các vật phẩm và không có giới hạn về kích thước của bộ đệm. - Ngược lại, cái thứ hai được gọi là
Bounded Buffer Problem, trong đó tiến trình sản xuất chỉ có thể tạo ra tối đa một số lượng vật phẩm nhất định. Sau đó nó cần chờ tiến trình tiêu thụ lấy ra dùng để giải phóng không gian bộ đệm và tiếp tục tạo ra vật phẩm mới. Về phía còn lại, tiến trình tiêu thụ nếu như không thấy có vật phẩm mình cần trong bộ đệm thì nó sẽ đợi cho đến khi tiến trình sản xuất tạo ra.
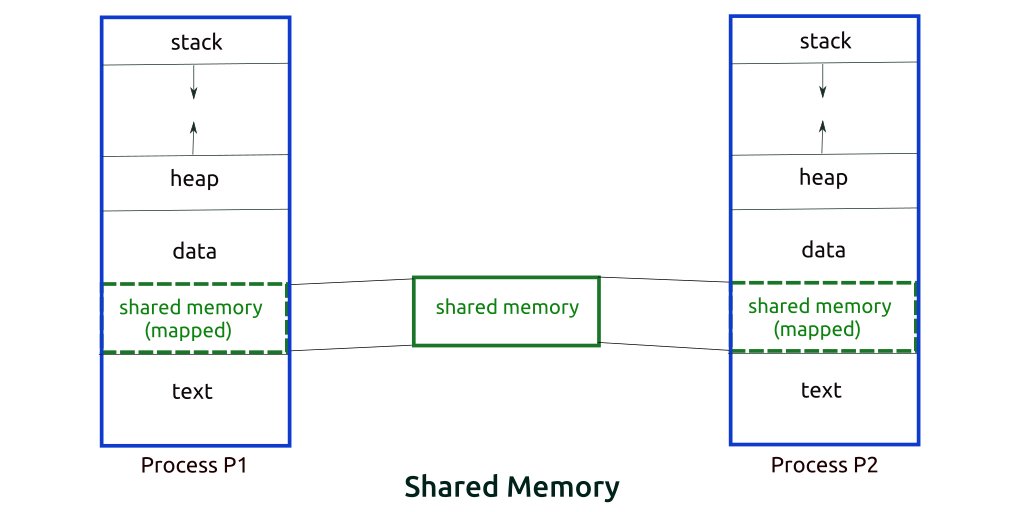
1.2) Phương pháp Message Parsing
Với phương pháp này, các tiến trình sẽ giao tiếp với nhau mà không cần sử dụng bất kỳ loại bộ nhớ dùng chung nào. Nếu hai tiến trình p1 và p2 muốn giao tiếp với nhau, chúng sẽ tiến hành như sau:
- Thiết lập một liên kết truyền thông (nếu liên kết đã tồn tại, không cần thiết lập lại liên kết.)
- Bắt đầu trao đổi các thông điệp bằng cách sử dụng các giao tiếp cơ bản. Đó là:
Send: gửi thông điệp, bao gồm 2 tùy chọn: send(message, destination) và send(mesage)Receive: nhận thông điệp, bao gồm 2 tùy chọn: receive(message, host) và receive(message)
Kích thước thông điệp có thể được cố định hoặc cũng có thể được thay đổi, mỗi cách có ưu điểm và nhược điểm riêng. Kích thước cố định thì dễ dàng hơn cho nhà thiết kế hệ điều hành nhưng phức tạp hơn đối với lập trình viên. Ngược lại, nếu nó có thể thay đổi, thì nó dễ dàng cho lập trình viên nhưng phức tạp đối với người thiết kế hệ điều hành.
Một thông điệp tiêu chuẩn có hai phần: header và body. Header được sử dụng để lưu trữ loại thông điệp (type), định danh đích, định danh nguồn, độ dài thông điệp và thông tin điều khiển. Thông tin điều khiển chứa thông tin như phải làm gì nếu hết dung lượng bộ đệm, số thứ tự và mức độ ưu tiên của nó. Nói chung, thông điệp được gửi bằng cách sử dụng kiểu FIFO (kiểu hàng đợi)
2. Distributed File Systems
Distributed File Systems (hệ thống tệp tin phân tán) sử dụng mô hình client/server-based application. Nó cho phép máy khách truy cập và xử lý dữ liệu được lưu trữ trên máy chủ như thể nó nằm trên máy tính của chính họ. Khi người dùng truy cập một tệp trên máy chủ, máy chủ sẽ gửi cho người dùng một bản sao của tệp, được lưu trong bộ nhớ cache trên máy tính của người dùng trong khi dữ liệu đang được xử lý và sau đó thông tin xử lý được trả về máy chủ. Cách tốt nhất là một hệ thống tệp phân tán tổ chức các dịch vụ tệp và thư mục của các máy chủ riêng lẻ thành một thư mục chung theo cách mà việc truy cập dữ liệu từ xa không cụ thể theo vị trí mà giống hệt với bất kỳ máy khách nào. Tất cả các tệp có thể truy cập được đối với tất cả người dùng của hệ thống và tổ chức tệp toàn cầu được phân cấp và dựa trên thư mục. Hay nói cách khác, với góc nhìn của các máy khách thì hệ thống tệp tin và thư mục là như nhau.
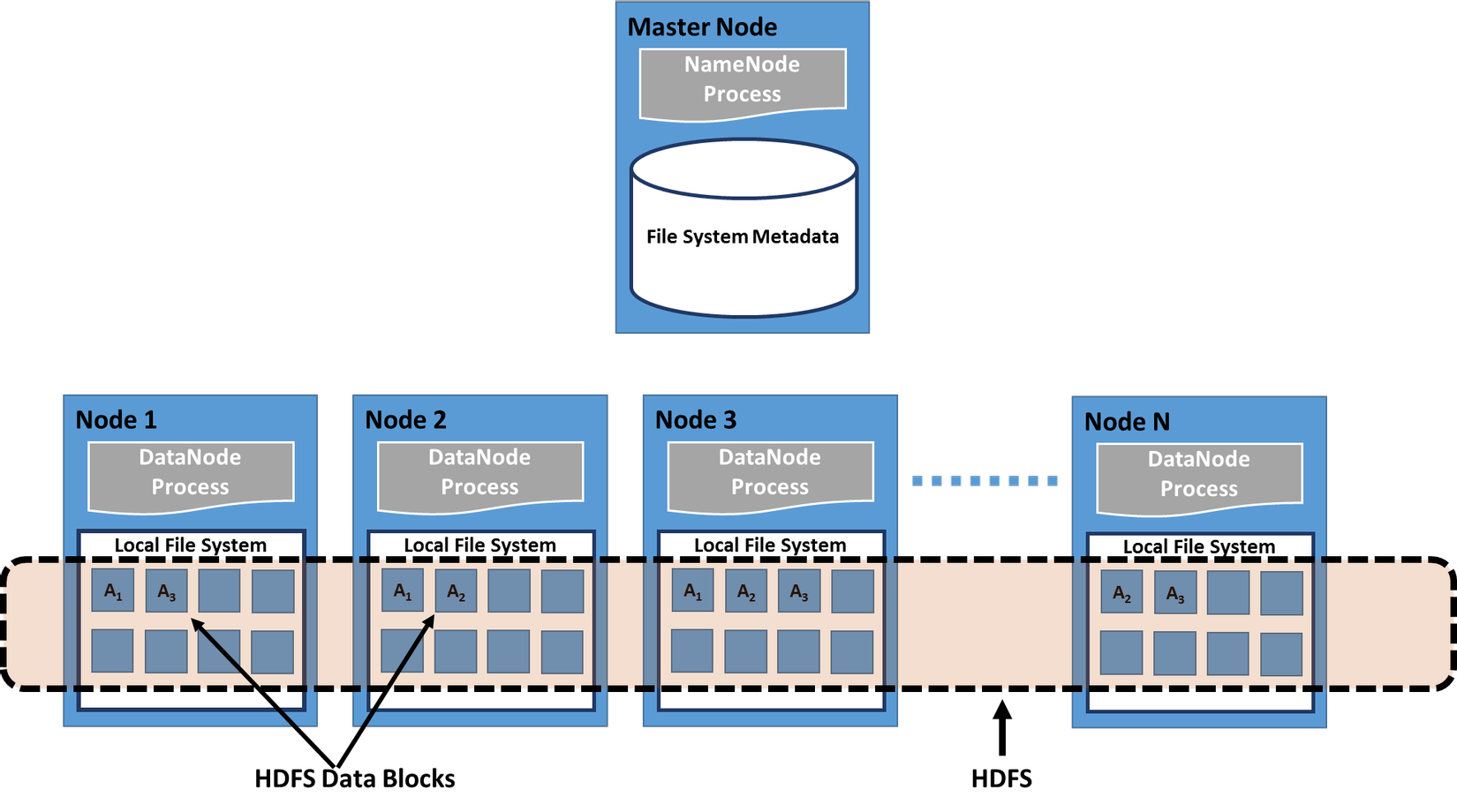
Do có nhiều máy khách có thể truy cập cùng một dữ liệu tại cùng một thời điểm, nên máy chủ phải có cơ chế (chẳng hạn như duy trì thông tin về thời gian truy cập) tổ chức hợp lý với các bản cập nhật để máy khách luôn nhận được phiên bản dữ liệu mới nhất và tránh sự xung đột phát sinh xuống mức tối thiểu. Các hệ thống tệp phân tán thường sử dụng sao chép tệp hoặc cơ sở dữ liệu (phân phối các bản sao dữ liệu trên nhiều máy chủ) để bảo vệ chống lại lỗi truy cập dữ liệu.
Một vài ví dụ về hệ thống tệp phân tán hiện nay: NFS (Network File System, của Sun Microsystem), NetWare (của Novell), DFS (Distributed File System, của Microsoft).
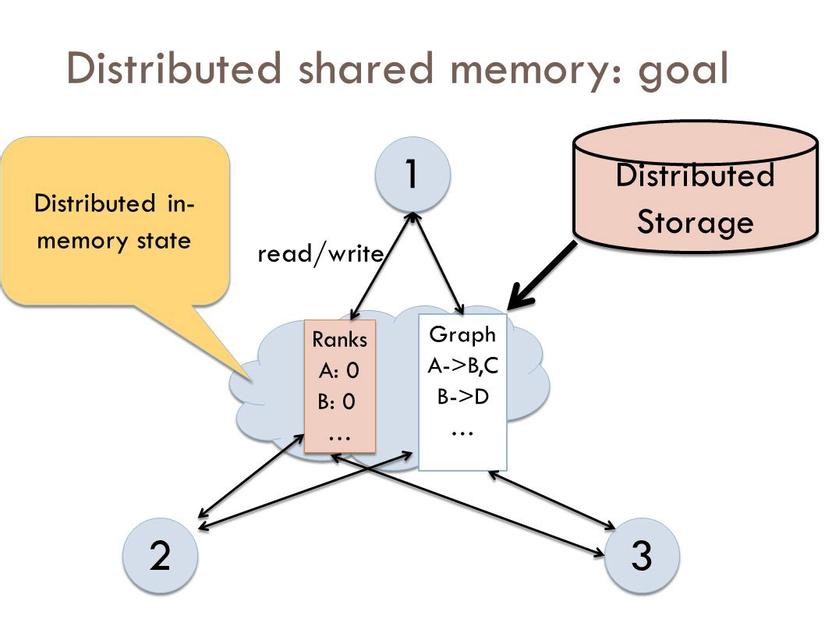
3. Distributed Shared Memory
Distributed Shared Memory (bộ nhớ chia sẻ phân tán, DSM) là một thành phần quản lý tài nguyên của hệ điều hành phân tán, thực hiện mô hình bộ nhớ dùng chung trong các hệ thống phân tán, không có bộ nhớ chia sẻ vật lý. Bộ nhớ dùng chung này cung cấp một không gian địa chỉ ảo được chia sẻ giữa tất cả các máy tính trong một hệ thống phân tán.
Trong DSM, dữ liệu được truy cập từ một không gian được chia sẻ tương tự như cách truy cập bộ nhớ ảo. Dữ liệu di chuyển giữa bộ nhớ thứ cấp và bộ nhớ chính. Đồng thời, dữ liệu cũng được chia sẻ giữa các bộ nhớ chính phân tán của các nút mạng khác nhau. Quyền sở hữu các trang trong bộ nhớ bắt đầu ở một số trạng thái được xác định trước nhưng thay đổi trong quá trình hoạt động bình thường. Thay đổi quyền sở hữu diễn ra khi dữ liệu di chuyển từ nút mạng này sang nút mạng khác do một tiến trình cụ thể truy cập.
Các ưu điểm của DSM bao gồm:
- Che dấu việc di chuyển dữ liệu và cung cấp một cách trừu tượng hóa đơn giản hơn để chia sẻ dữ liệu. Các lập trình viên không cần phải lo lắng về việc chuyển bộ nhớ giữa các máy như khi sử dụng mô hình truyền thông điệp.
- Cho phép chuyển các cấu trúc phức tạp bằng cách tham chiếu, giúp đơn giản hóa việc phát triển thuật toán cho các ứng dụng phân tán.
- Tận dụng lợi thế của vùng tham chiếu bằng cách di chuyển toàn bộ trang có chứa dữ liệu được tham chiếu thay vì chỉ là phần dữ liệu.
- Xây dựng các hệ thống nhiều bộ xử lý với chi phí rẻ hơn. Ý tưởng có thể được thực hiện bằng phần cứng thông thường và không yêu cầu bất cứ điều gì phức tạp để kết nối bộ nhớ dùng chung với bộ xử lý.
- Cho phép kích thước bộ nhớ lớn hơn có sẵn cho các chương trình, bằng cách kết hợp tất cả bộ nhớ vật lý của tất cả các nút. Bộ nhớ lớn này sẽ không phát sinh độ trễ của đĩa do hoán đổi như trong các hệ thống phân tán truyền thống.
- Không giới hạn số lượng nút mạng có thể được sử dụng. Không giống như các hệ thống đa bộ xử lý nơi bộ nhớ chính được truy cập thông qua một bus chung, do đó kích thước của hệ thống đa bộ xử lý bị giới hạn.
- Các chương trình được viết cho hệ thống đa xử lý bộ nhớ dùng chung có thể chạy trên các hệ thống DSM, giúp làm tăng tính tương thích.
Kết luận
Với tầm tìm hiểu hạn hẹp, mình đã giới thiệu qua các vấn đề liên quan đến hoạt động của hệ điều hành qua 3 phần của bài viết. Cảm ơn các bạn đã đọc 
Tài liệu tham khảo
- https://medium.com/cracking-the-data-science-interview/how-operating-systems-work-10-concepts-you-should-know-as-a-developer-8d63bb38331f
- https://edu.gcfglobal.org/en/computerbasics/understanding-operating-systems/1/
- https://computer.howstuffworks.com/operating-system.htm
- https://en.wikipedia.org/wiki/Operating_system
All rights reserved
