
Giới thiệu về Self prompting, mô hình self prompting trong các task Zero-Shot Open-Domain QA
Self prompting
Trong quá trình ứng dụng các mô hình ngôn ngữ lớn (LLM), một vấn đề nổi bật là sự phụ thuộc vào prompt engineering – việc thiết kế các câu lệnh đầu vào để hướng dẫn mô hình. Tuy nhiên, việc này đòi hỏi nhiều thử nghiệm thủ công, tốn thời gian, và thường thiếu tính nhất quán, đặc biệt khi đối mặt với các tác vụ phức tạp hoặc các yêu cầu thay đổi theo ngữ cảnh. Hơn nữa, hiệu suất của LLM rất nhạy cảm với cấu trúc và nội dung của prompt, dẫn đến sự bất ổn định trong kết quả.
Thay vì dựa vào con người để tạo và tinh chỉnh prompt, các phương pháp như CoT, self-prompting cho phép mô hình tự động viết, đánh giá và tối ưu hóa prompt của chính nó.
Cụ thể, Self-Prompting yêu cầu LLMs tạo ra từng bước nhiều bộ câu hỏi và câu trả lời giả lập, bao gồm các đoạn văn bản nền tảng và giải thích hoàn toàn từ đầu. Những yếu tố này sau đó được sử dụng để học trong ngữ cảnh. Kết quả thực nghiệm cho thấy phương pháp này vượt trội hơn hẳn các phương pháp zero-shot trước đó trên ba bộ dữ liệu ODQA phổ biến.
Trước khi nói kỹ hơn về framework này, mình sẽ viết lại về Chain of thought Prompting.
Chain-of-thought Prompting
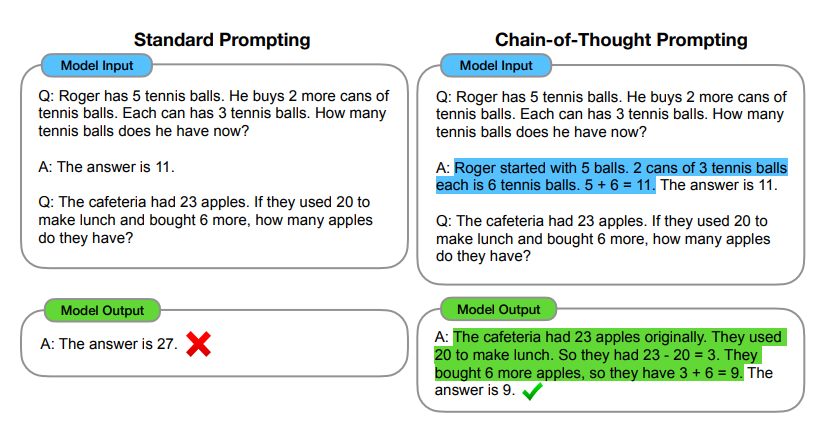
Hình 1: Chain-of-thought prompting cho phép các mô hình có thể giải quyết các nhiệm vụ phức tạp liên quan đến tính toán số học, hiểu biết thông thường, và lập luận logic. Quá trình CoT được hightlight trong hình trên.
Phương pháp này xét quá trình một người suy nghĩ khi giải quyết các vấn đề lập luận phức tạp thành nhiều bước nhỏ khác nhau. Chúng ta có thể tách 1 vấn đề thành nhiều bước nhỏ hơn và giải quyết trước khi đưa ra kết quả cuối cùng. VD: “After Jane gives 2 flowers to her mom she has 10 . . . then after she gives 3 to her dad she will have 7 . . . so the answer is 7.” Mục tiêu của bài báo CoT là cho phép mô hình có khả năng sinh ra được một Chain of thought - Một chuỗi các bước lập luận để đưa ra kết quả cho bài toán.
Chain of thought prompting có nhiều tính chất để hỗ trợ các mô hình ngôn ngữ với khả năng lập luận:
- Phương pháp chain of thought cho phép mô hình phân rã các vấn đề nhiều bước thành các bước trung gian, từ đó phân bổ thêm tài nguyên tính toán cho các bài toán đòi hỏi nhiều bước suy luận hơn. Điều này giúp mô hình tiếp cận các vấn đề phức tạp một cách có hệ thống và hiệu quả hơn.
- Chain of thought cung cấp một cửa sổ trực quan vào hành vi của mô hình, gợi ý cách nó đạt được một câu trả lời cụ thể. Điều này giúp con người có cơ hội phát hiện và sửa lỗi nếu đường đi lập luận gặp sai sót, mặc dù việc mô tả đầy đủ các phép tính hỗ trợ một câu trả lời vẫn còn là một câu hỏi chưa có lời giải.
- Lập luận theo chuỗi tư duy có thể được sử dụng cho các nhiệm vụ như math word problems, commonsense reasoning, và symbolic manipulation.
- Chain of thought có thể dễ dàng áp dụng trên các mô hình ngôn ngữ lớn có sẵn chỉ bằng cách thêm các ví dụ về chuỗi tư duy vào các mẫu gợi ý khi thực hiện few-shot prompting. Chain-of-Thought (CoT) đã chứng tỏ hiệu quả trong việc giải quyết các tác vụ đòi hỏi suy luận phức tạp, đặc biệt trong những câu hỏi nhiều bước, như toán học hay các vấn đề đòi hỏi lý luận sâu. Phương pháp này yêu cầu mô hình không chỉ cung cấp câu trả lời mà còn phải mô phỏng quá trình suy nghĩ qua các bước trung gian, từ đó tạo ra kết quả dễ hiểu và minh bạch hơn.
Các bạn có thể đọc qua về cách người ta sử dụng Auto CoT để tự động sinh ra các câu trả lời làm prompt tiếp để đưa đến đáp án cuối của 1 truy vấn trong link sau: https://arxiv.org/pdf/2210.03493
Tuy nhiên, dựa trên ý tưởng này, phương pháp Self Prompting được giới thiệu trong phần sau cải thiện được sự chính xác của việc suy luận bằng cách đưa ra các câu giải thích cho câu trả lời.
Self-prompting
Self-prompting gồm 2 giai đoạn:
- Preparation
- Inference
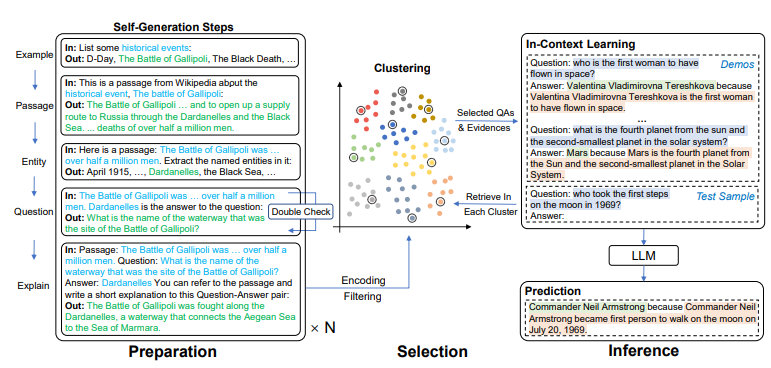
Hình 2: Framework cho Self prompting trên ODQA (open-domain QA). Trong bước self generation, phần màu xanh đại diện cho các nội dung được sinh ra trong bước trước, hoặc được thiết kế thủ công trong quá trình prompt engineering. Trong quá trình inference, các question, answer, explaination là kết quả của cả quá trình test và demonstration.
Tại quá trình preparation
Chúng ta hướng dẫn LLM để tự động gen ra một số lượng lớn các cặp câu trả lời đúng sai (pseudo dataset) theo các bước sau:

-
Bước 1 : Passage Generation :
-
Để đảm bảo tính đa dạng của các đoạn văn được tạo ra, i đầu tiên chọn mẫu các chủ đề khác nhau (chẳng hạn như các quốc gia, sách, điểm du lịch) có khả năng xuất hiện trong ODQA dựa trên phân phối các synset cho các thực thể xuất hiện trong các câu trả lời của TriviaQA (Joshi et al., 2017).
-
Cụ thể, abstract và summary các thực thể này để định nghĩa một bộ chủ đề cấp cao như chính trị, thể thao, địa lý, phim ảnh, truyền hình, v.v. Sau đó, dưới mỗi chủ đề cấp cao, chúng tôi tiếp tục phân chia nó thành các chủ đề nhỏ hơn; ví dụ, chủ đề thể thao được chia thành các vận động viên, đội thể thao, và sự kiện thể thao, dẫn đến một danh sách chủ đề đầy đủ.
-
Prompt:
“This is a passage from Wikipedia about the {topic}, {example}:”.
-
-
Bước 2 : Named Entity Recognition :
-
Trích xuất các named entity( ví dụ: ngày, tên và địa điểm) trong các câu trả lời trên. Các named entity xuất hiện trong các câu trả lời.
-
Prompt:
“Here is a passage: {passage} Extract the named entities in it:”
-
-
Bước 3 : Question Generation :
- Sử dụng các passage, entity để LLM đưa ra câu hỏi với câu trả lời dựa trên passage đã đưa ra với
- Promt:
“{passage} {entity} is the answer to the question:” - Để đảm bảo độ chính xác của câu hỏi, chúng ta dùng LLM để double check (Tự trả lời câu hỏi đã sinh) xem LLM đã có thể cover được entity và giữ nó lại khi trả lời bằng LLM không.
-
Bước 4: Explain the QA pair:
- Với mỗi QA pair, chúng ta tiếp tục yêu cầu LLM trả lại một câu giải thích phù hợp với passage.
- Prompt:
“Passage: {passage} Question: {question} Answer: {answer} You can refer to the passage and write a short explanation to this Question-Answer pair:”.
Inference:
Tại bước này, chúng ta sẽ prompt LLM để sử dụng bộ QA đã sinh được trước đó. 2 mục tiêu sẽ được tập trung đó chính là selection và format.
Clustering-based Retrieval (selection):
Giả sử cần k ví dụ cho việc trình diễn trong ngữ cảnh; pseudo QA sẽ được nhóm thành k cluster theo thuật toán k-means. Đối với một câu hỏi nhất định, encode câu hỏi bằng Sentence-BERT và lấy example giống nhau nhất từ mỗi nhóm với cosine similarity.
Answer then Explain(format):
Đây là bước tổng hợp và format lại các example đã lấy ra được. Trong phần đầu vào, chúng ta đưa ra các example theo thứ tự Question→ Answer → Explanation và đưa ra câu truy vấn tại kết thúc của chuỗi.
Bằng cách này, LLM có thể có được nhiều thông tin hơn là chỉ trả lời và cũng có thể đưa ra lời giải thích cho câu trả lời của chính nó.
Bài viết đến đây đã dài, mình xin dừng bút tại đây. Tóm lại: Self prompting là một phương pháp mạnh mẽ trong việc tối ưu hóa khả năng của các mô hình ngôn ngữ lớn (LLMs) với các tính chất:
- Linh hoạt và thích ứng: Self-prompting có thể áp dụng cho nhiều tác vụ khác nhau mà không cần thay đổi cấu trúc mô hình quá nhiều, giúp mô hình dễ dàng thích nghi với các ngữ cảnh và nhiệm vụ mới.
- Ứng dụng trong Zero-shot: Phương pháp này đặc biệt hữu ích trong các tác vụ zero-shot, nơi mô hình phải giải quyết các câu hỏi hoặc nhiệm vụ mà nó chưa được huấn luyện trước
Tuy không thể thay thế hoàn toàn CoT, tuy nhiên phương pháp này hiệu quả trong các task yêu cầu QA với độ chính xác cao do có bước double check các suy luận mà LLM tự gen ra mà không cần thủ công prompt như Manual CoT.
Tài liệu tham khảo:
https://arxiv.org/html/2212.08635v3
https://openreview.net/forum?id=92gvk82DE-
All rights reserved
