
Giải thích kiến trúc của XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
1. Lời mở đầu
Xin chào mọi người, lại là tôi đây. Trong bài viết này mình sẽ giới thiệu về XTTS của Coqui AI, một mô hình ứng dụng trong việc clone giọng nói của người khác, đầu vào là file audio mình muốn clone và text mà mình muốn nói bằng giọng đó, kết quả trả ra sẽ là đoạn âm thanh mong muốn.
Ok thì câu hỏi đặt ra là tại sao lại là voice clone, thì đợt này mình đang làm đồ án tốt nghiệp, đồ án liên quan đến SadTalker, Wav2lip, và XTTS của Coqui AI, Sadtalker thì mình có viết 1 bài rồi, Wav2lip mình mở paper ra đọc thì cũng không có nhiều thứ để viết lắm, cho nên chúng ta sẽ có bài về XTTS của Coqui AI.
Chủ yếu mình muốn viết ra để tổng hợp lại những gì đã học được, và cũng muốn chia sẻ kiến thức đến mọi người, như thường lệ thì mình viết theo cấu trúc của paper xtts.
Do đây cũng là lần đầu mình tiếp xúc lĩnh vực voice này nên có thể còn nhiều sai sót, hi vọng có thể nhận được sự giúp đỡ của các bạn.
2. Kiến trúc mô hình XTTS
Đây là phần Abstract ở paper gốc, mô tả về việc đa phần các hệ thống Zero-shot Multi-speaker TTS (ZS-TTS) chỉ hỗ trợ một ngôn ngữ. Một số models như YourTTS, VALL-E X, Mega-TTS 2 và Voicebox bắt đầu khám phá về Multilingual ZS-TTS, nhưng mà vẫn bị giới hạn bởi việc chỉ hỗ trợ các ngôn ngữ high/medium resource, các ngôn ngữ low/medium resource thì ... phải chịu 🤣. Cho nên XTTS ra đời để xử lý vấn đề đó.
XTTS được xây dựng trên nền của mô hình Tortoise, chỉ áp dụng một vài thay đổi của nó và trong paper XTTS cũng có nói về sự khác nhau của 2 mô hình.
2.1. Các nghiên cứu trước đó
Đầu tiên phải hiểu ZS-TTS (Zero-shot multi-speaker TTS) là gì? Thì các hệ thống Text-to-Speech (TTS) hầu hết được thiết kế dựa trên chỉ một người (single speaker's voice), tuy nhiên hiện nay chúng ta sẽ hứng thú hơn với việc đồng nhất giọng nói cho new speaker (không có trong tập huấn luyện) mà chỉ sử dụng few seconds of speech. Đó gọi là ZS-TTS.
Các mô hình ZS-TTS hiện tại cũng chỉ hỗ trợ only a single language, các mô hình bên dưới đây và XTTS sẽ chủ yếu khai phá về lĩnh vực multilingual ZS-TTS.
YourTTS là mô hình đầu tiên trong lĩnh vực multilingual ZS-TTS model. YourTTS được huấn luyện khoảng 1000 speaker của tiếng Anh, 5 speakers trong tiếng Pháp và 1 speaker tiếng Bồ Đào Nha. YourTTS đạt được kết quả SOTA (State of the art) với ngôn ngữ tiếng Anh, và có hứa hẹn với tiếng Pháp và Bồ Đào Nha.
Tiếp theo là sự ra đời của VALL-E X, được xây dựng trên nền của VALL-E, giới thiệu về language ID để hỗ trợ multilingual TTS và speech-to-speech translation.
Sau đó là Mega-TTS, mô hình có khả năng xử lý arbitrary-length speech prompts (mình cũng không hiểu và nghiên cứu về mấy phần này cho lắm). Mega-TTS được huấn luyện với 38k giờ của multi-domain language-balanced speech với tiếng Anh và tiếng Trung. Mega-TTS đạt được kết quả SOTA với short speech prompts và cho ra kết quả tốt hơn với longer speech prompts.
Sau đó, cùng lúc với XTTS được xây dựng thì Voicebox cũng ra đời, Voicebox là non-autogressive continuous normalizing flow model, nó có thể consume context không chỉ trong quá khứ mà còn trong tương lai. Voicebox được huấn luyện với 6 ngôn ngữ và cũng đạt được SOTA với cross-lingual ZS-TTS.
Do đây là lĩnh vực mới mình nghiên cứu nên nhiều phần mình không hiểu, không giải thích cụ thể, chi tiết được, mong các bạn thông cảm 🥲
2.2. Kiến trúc XTTS
Phần 2.1 trên nói về các nghiên cứu trước đó, tuy nhiên số lượng ngôn ngữ được hỗ trợ vẫn rất là thấp. YourTTS với 3 ngôn ngữ, VALL-E X và Mega-TTS 2 chỉ hỗ trợ 2 ngôn ngữ. Voicebox hỗ trợ 6 ngôn ngữ.
XTTS đến và đề xuất massive multilingual ZS-TTS model hỗ trợ 16 ngôn ngữ, bao gồm: English (en), Span-ish (es), French (fr), German (de), Italian (it), Portuguese (pt), Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh), Hungarian (hu), Korean (ko), and Japanese (ja). Tiếc là vẫn không tìm thấy tiếng Việt của chúng mình đâu 😬, tuy nhiên có đội viXTTS của CapLeaf đã finetune XTTS với ngôn ngữ tiếng Việt trên bộ dataset viVoice, có thời gian thì mọi người có thể xem qua.
Đây là những phần chính mà XTTS trình bày:
- We introduced XTTS, a new multilingual ZS-TTS model that achieves SOTA results in 16 languages;
- XTTS is the first massively multilingual ZS-TTS model sup-porting low/medium resource languages;
- Our model can perform cross-language ZS-TTS without needing a parallel training dataset
- TTS model and checkpoints are publicly available at CoquiTTS and also on Hugging Face XTTS repository
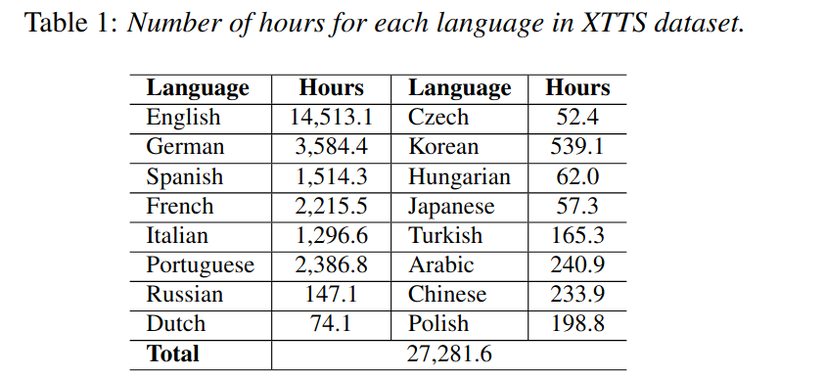
Dưới đây là kiến trúc chính của XTTS.
Ok giờ mình sẽ đi vào từng phần một.
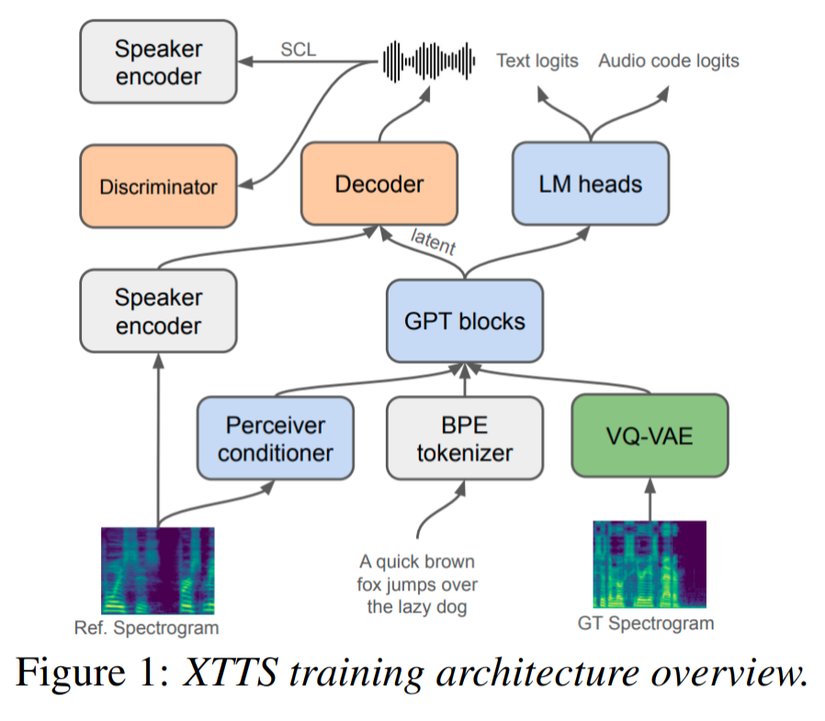
2.2.1. VQ-VAE (Vector Quantised-Variational AutoEncoder)
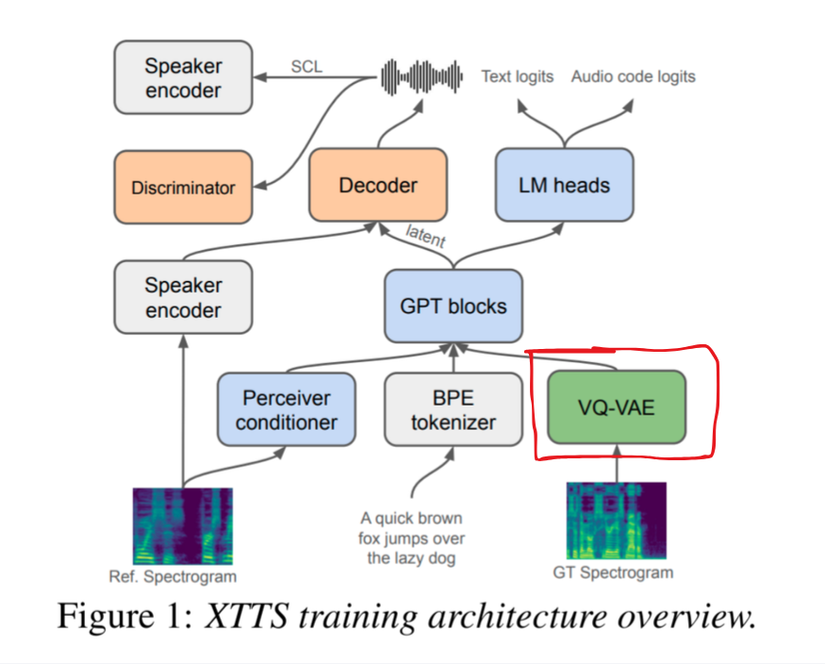
VQ-VAE (Vector Quantised-Variational AutoEncoder) là mô hình với 13M tham số, nó nhận vào mel-spectrogram (Ảnh phổ Mel) làm đầu vào. Tại sao lại là mel-spectrogram thay vì spectrogram thì là vì nó phù hợp cho các mô hình AI deep learning có thể hiểu được thông tin.
VQ-VAE sẽ coi mel-spectrogram là hình ảnh, và thực hiện mã hóa mỗi frame với 1 codebook, mỗi codebook chứa 8192 codes ở 21.53Hz frame-rate.
Đến đây thì 1 số khái niệm khó hiểu như codebook và codes xảy ra. Codebook có thể hiểu là một cái thư viện, hoặc là một quyển từ điển gồm 8192 thành phần (con số 8192 là được lấy ý tưởng từ Tortoise).
Với mỗi giây âm thanh, mel-spectrogram được chia thành 22 frame (~21.53Hz frame rate), mỗi frame ứng với 1 codes trong codebook, VD: frame đầu tiên ứng với codes thứ 15 trong codebook.
Mỗi codes trong codebook sẽ mô tả đặc trưng vật lý của âm thanh, ví dụ với âm thanh "A lô". (Ví dụ từ Gemini 2.5 pro):
*Lát cắt số 1 (Đầu chữ A): Có thể gán vào Code #10.<br>
Ý nghĩa Code #10: "Âm thanh mở miệng, cường độ lớn, tần số trung bình".<br>
Lát cắt số 5 (Cuối chữ A): Có thể gán vào Code #55.<br>
Ý nghĩa Code #55: "Âm thanh khép dần, cường độ giảm, ngân dài".<br>
Lát cắt số 10 (Khoảng nghỉ giữa A và Lô): Có thể gán vào Code #999.<br>
Ý nghĩa Code #999: "Im lặng" hoặc "Tiếng lấy hơi nhẹ".<br>*
Ok TUY NHIÊN 8192 chỉ là từ model Tortoise thôi, còn khi thực nghiệm, nhóm XTTS của Coqui AI nhận thấy rằng 8192 là quá nhiều, một số code trong codebook còn không được đụng tới, cho nên tác giả chỉ lọc lấy 1024 codes có tần suất xuất hiện nhiều nhất thôi, để tăng tốc độ huấn luyện, loại bỏ thông tin ít được sử dụng.
In preliminary experiments, we verified that filtering the less frequent codes improved the model’s expressiveness.*
2.2.2. BPE Tokenizer
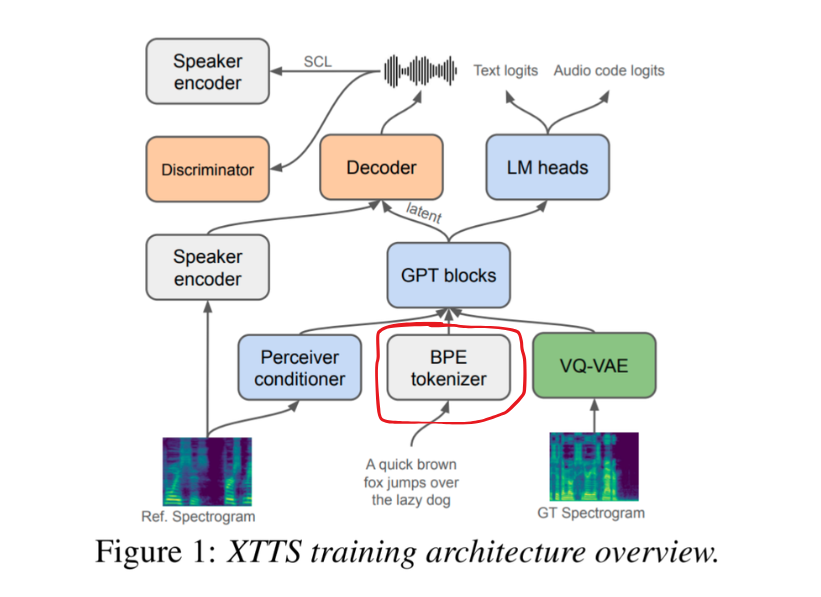 Phần này chủ yếu sẽ được dùng để tách từ (tokenization) nằm ở khoảng giữa việc tách theo ký tự (character-level) và tách theo từ (word-level).
Phần này chủ yếu sẽ được dùng để tách từ (tokenization) nằm ở khoảng giữa việc tách theo ký tự (character-level) và tách theo từ (word-level).
Nó bắt đầu bằng các ký tự đơn lẻ, sau đó thống kê và liên tục gộp các cặp ký tự xuất hiện thường xuyên nhất lại với nhau để tạo thành một đơn vị mới (token).
Kết quả là các từ phổ biến sẽ được giữ nguyên (ví dụ: "apple").
Các từ hiếm hoặc phức tạp sẽ được tách thành các từ con (sub-words) có ý nghĩa (ví dụ: "unhappiness" "un", "happi", "ness").
Ok thì tại sao XTTS lại chọn BPE để embedding text, đó là vì XTTS hỗ trợ tới 16 ngôn ngữ, nếu dùng từ điển thông thường (mỗi từ là 1 token) kho từ vựng sẽ lên tới hàng triệu từ (16 ngôn ngữ). Điều này làm mô hình GPT-2 trở nên khổng lồ và chậm chạp sử dụng BPE tùy chỉnh để nén toàn bộ 16 ngôn ngữ về tổng 6681 tokens.
Còn đối với tiếng Hàn, Nhật, và Trung Quốc, họ chuyển toàn bộ văn bản sang ký tự Latin (Romanized) trước khi đưa vào BPE.
2.2.3. Perceiver Conditioner
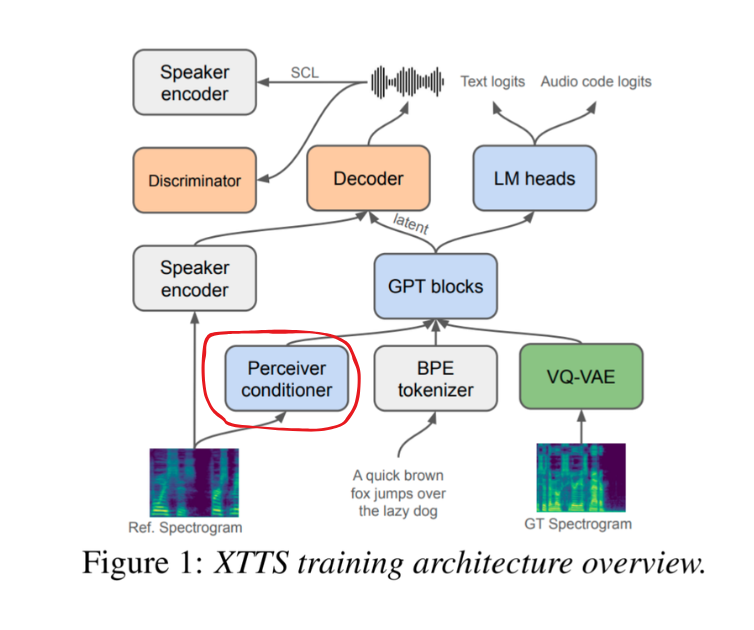
Phần Perceiver Conditioner này mục đích là để trích ra embedding cho giọng nói của người dùng theo cùng số chiều (tức là audio người dùng up lên là 10s hay 5s thì vẫn embedding ra 32 vector, mỗi vector 1024 chiều (trong Tortoise chỉ sử dụng 1 vector 1024 chiều thôi)
Ngoài ra các bạn có thể thắc mắc Ref. Spectrogram và GT Spectrogram là gì và khác biệt nhau ra sao, thì giả sử chúng ta có audio là 10 giây, đoạn GT spectrogram có thể là 3s đầu, text đưa vào BPE Tokenizer là chính xác âm thanh của đoạn Groundtruth đó. Ref. Spectrogram sẽ là cùng file audio đó, nhưng ở 7s còn lại
2.2.4. GPT Blocks
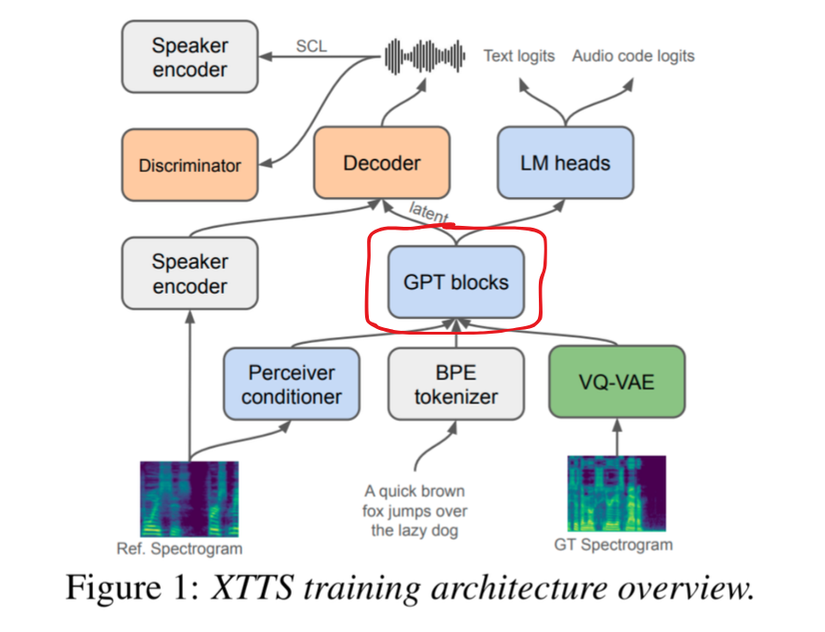 Với output từ Perceiver conditioner, BPE Tokenizer và VQ-VAE, chúng ta sẽ được đưa vào khối GPT blocks.
Mục đích là để nhúng toàn bộ thông tin từ 3 thành phần trên, đưa qua khối GPT Blocks (GPT 2) để embedding thông tin quan trọng,
Với output từ Perceiver conditioner, BPE Tokenizer và VQ-VAE, chúng ta sẽ được đưa vào khối GPT blocks.
Mục đích là để nhúng toàn bộ thông tin từ 3 thành phần trên, đưa qua khối GPT Blocks (GPT 2) để embedding thông tin quan trọng,
GPT Blocks chủ yếu dùng cơ chế Multihead Attentions (six 16-head Scaled Dot-Product Attention layers), với 443M tham số.
2.2.5. Decoder
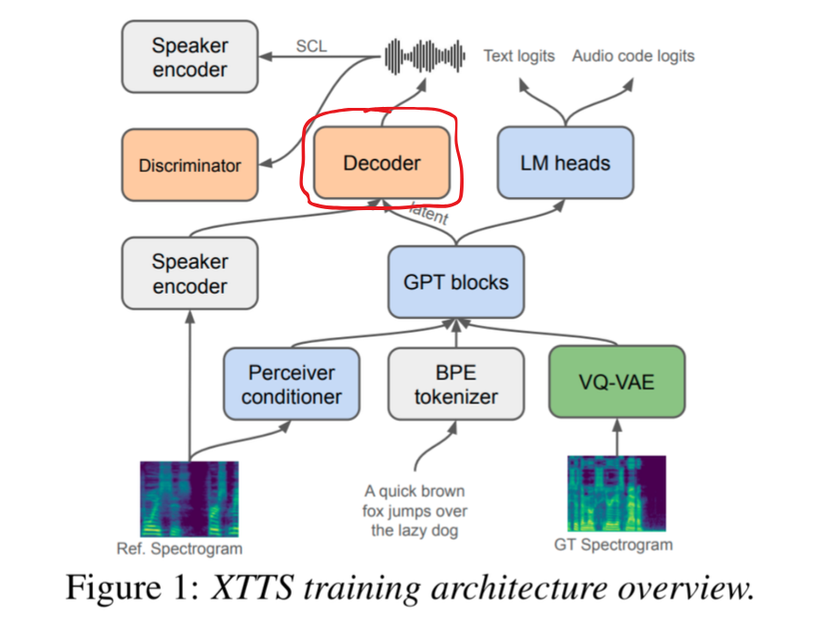 Encoder được xây dựng dựa trên HiFi-GAN vocoder, nhận đầu vào là latent vector từ GPT-2 encoder để sinh ra file audio đích muốn clone.
Encoder được xây dựng dựa trên HiFi-GAN vocoder, nhận đầu vào là latent vector từ GPT-2 encoder để sinh ra file audio đích muốn clone.
Câu hỏi đặt ra là tại sao phải đi lằng nhằng như thế, không từ VQ-VAE đi thẳng qua Decoder luôn mà phải qua thằng trung gian là GPT Blocks, thì trong paper tác giả có chỉ ra bởi vì VQ-VAE đã nén toàn bộ thông tin lại rồi, việc tái tạo lại audio trực tiếp từ VQ-VAE dẫn đến việc pronunciation issues and artifacts.
2.2.6. Các phần còn lại
Speaker Encoder: Đây là mô hình H/ASP, nó nhận đầu vào là Ref Spectrogram và nén toàn bộ đặc trưng giọng nói của người đó thành một vector duy nhất (Speaker Embedding). Tức là theo kiểu định danh về giọng nói, (e.g. Giọng nói của ông A này có đặc trưng là hơi khàn khàn...)
LM Heads: Đầu ra của GPT Blocks thay vì chỉ được đưa qua Decoder thì cũng được đưa qua LM Heads, dùng để sinh ra 2 output là Text logits, và Audio code logits để GPT blocks có thể học được cả ngữ nghĩa của câu đang nói.
Speaker Encoder ở cuối: Phần này để đảm bảo Audio đích sinh ra cũng đi qua mô hình H/ASP để đảm bảo đặc trưng giọng nói của audio sinh ra, khớp với đặc trưng của audio đầu vào (Speaker Encoder ở phần đầu vào)
3. Tổng kết.
Vậy là chúng ta đã đi qua kiến trúc cơ bản của XTTS, mô hình đạt được SOTA hiện tại với 16 ngôn ngữ khác nhau, bài viết có nhiều thiếu xót nên hi vọng có thể nhận được sự thông cảm và góp ý của mọi người.
4. Tài liệu tham khảo
All rights reserved
