
Fine tuning pre-trained model trong pytorch và áp dụng vào Visual Saliency Prediction
Bài đăng này đã không được cập nhật trong 6 năm
1. Introduction
1.1 Fine-tuning là gì ?
Chắc hẳn những ai làm việc với các model trong deep learning đều đã nghe/quen với khái niệm Transfer learning và Fine tuning. Khái niệm tổng quát: Transfer learning là tận dụng tri thức học được từ 1 vấn đề để áp dụng vào 1 vấn đề có liên quan khác. Một ví dụ đơn giản: thay vì train 1 model mới hoàn toàn cho bài toán phân loại chó/mèo, người ta có thể tận dụng 1 model đã được train trên ImageNet dataset với hằng triệu ảnh. Pre-trained model này sẽ được train tiếp trên tập dataset chó/mèo, quá trình train này diễn ra nhanh hơn, kết quả thường tốt hơn. Có rất nhiều kiểu Transfer learning, các bạn có thể tham khảo trong bài này: Tổng hợp Transfer learning. Trong bài này, mình sẽ viết về 1 dạng transfer learning phổ biến: Fine-tuning.
Hiểu đơn giản, fine-tuning là bạn lấy 1 pre-trained model, tận dụng 1 phần hoặc toàn bộ các layer, thêm/sửa/xoá 1 vài layer/nhánh để tạo ra 1 model mới. Thường các layer đầu của model được freeze (đóng băng) lại - tức weight các layer này sẽ không bị thay đổi giá trị trong quá trình train. Lý do bởi các layer này đã có khả năng trích xuất thông tin mức trìu tượng thấp , khả năng này được học từ quá trình training trước đó. Ta freeze lại để tận dụng được khả năng này và giúp việc train diễn ra nhanh hơn (model chỉ phải update weight ở các layer cao). Có rất nhiều các Object detect model được xây dựng dựa trên các Classifier model. VD Retina model (Object detect) được xây dựng với backbone là Resnet.
1.2 Tại sao pytorch thay vì Keras ?
Chủ đề bài viết hôm nay, mình sẽ hướng dẫn fine-tuning Resnet50 - 1 pre-trained model được cung cấp sẵn trong torchvision của pytorch. Tại sao là pytorch mà không phải Keras ? Lý do bởi việc fine-tuning model trong keras rất đơn giản. Dưới đây là 1 đoạn code minh hoạ cho việc xây dựng 1 Unet dựa trên Resnet trong Keras:
from tensorflow.keras import applications
resnet = applications.resnet50.ResNet50()
layer_3 = resnet.get_layer('activation_9').output
layer_7 = resnet.get_layer('activation_21').output
layer_13 = resnet.get_layer('activation_39').output
layer_16 = resnet.get_layer('activation_48').output
#Adding outputs decoder with encoder layers
fcn1 = Conv2D(...)(layer_16)
fcn2 = Conv2DTranspose(...)(fcn1)
fcn2_skip_connected = Add()([fcn2, layer_13])
fcn3 = Conv2DTranspose(...)(fcn2_skip_connected)
fcn3_skip_connected = Add()([fcn3, layer_7])
fcn4 = Conv2DTranspose(...)(fcn3_skip_connected)
fcn4_skip_connected = Add()([fcn4, layer_3])
fcn5 = Conv2DTranspose(...)(fcn4_skip_connected)
Unet = Model(inputs = resnet.input, outputs=fcn5)
Bạn có thể thấy, fine-tuning model trong Keras thực sự rất đơn giản, dễ làm, dễ hiểu. Việc add thêm các nhánh rất dễ bởi cú pháp đơn giản. Trong pytorch thì ngược lại, xây dựng 1 model Unet tương tự sẽ khá vất vả và phức tạp. Người mới học sẽ gặp khó khăn vì trên mạng không nhiều các hướng dẫn cho việc này. Vậy nên bài này mình sẽ hướng dẫn chi tiết cách fine-tune trong pytorch để áp dụng vào bài toán Visual Saliency prediction
2. Visual Saliency prediction
2.1 What is Visual Saliency ?

Khi nhìn vào 1 bức ảnh, mắt thường có xu hướng tập trung nhìn vào 1 vài chủ thể chính. Ảnh trên đây là 1 minh hoạ, màu vàng được sử dụng để biểu thị mức độ thu hút. Saliency prediction là bài toán mô phỏng sự tập trung của mắt người khi quan sát 1 bức ảnh. Cụ thể, bài toán đòi hỏi xây dựng 1 model, model này nhận ảnh đầu vào, trả về 1 mask mô phỏng mức độ thu hút. Như vậy, model nhận vào 1 input image và trả về 1 mask có kích thước tương đương.

Để rõ hơn về bài toán này, bạn có thể đọc bài: Visual Saliency Prediction with Contextual Encoder-Decoder Network. Dataset phổ biến nhất: SALICON DATASET
2.2 Unet
Note: Bạn có thể bỏ qua phần này nếu đã biết về Unet
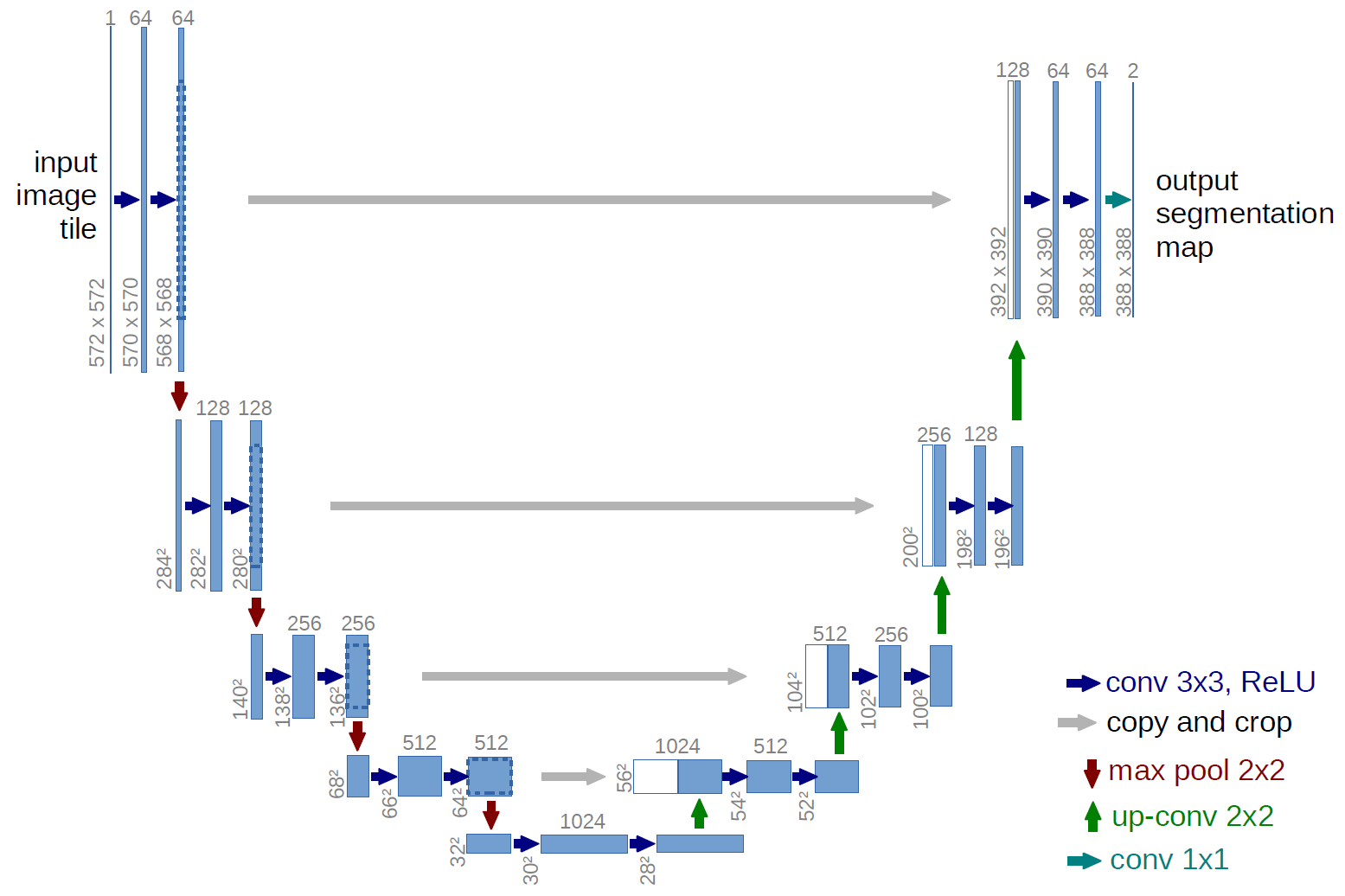
Đây là 1 bài toán Image-to-Image. Để giải quyết bài toán này, mình sẽ xây dựng 1 model theo kiến trúc Unet. Unet là 1 kiến trúc được sử dụng nhiều trong bài toán Image-to-image như: semantic segmentation, auto color, super resolution ... Kiến trúc của Unet có điểm tương tự với kiến trúc Encoder-Decoder đối xứng, được thêm các skip connection từ Encode sang Decode tương ứng. Về cơ bản, các layer càng cao càng trích xuất thông tin ở mức trìu tượng cao, điều đó đồng nghĩa với việc các thông tin mức trìu tượng thấp như đường nét, màu sắc, độ phân giải... sẽ bị mất mát đi trong quá trình lan truyền. Người ta thêm các skip-connection vào để giải quyết vấn đề này.
Với phần Encode, feature-map được downscale bằng các Convolution. Ngược lại, tại phần decode, feature-map được upscale bởi các Upsampling layer, trong bài này mình sử dụng các Convolution Transpose.
2.3 Resnet
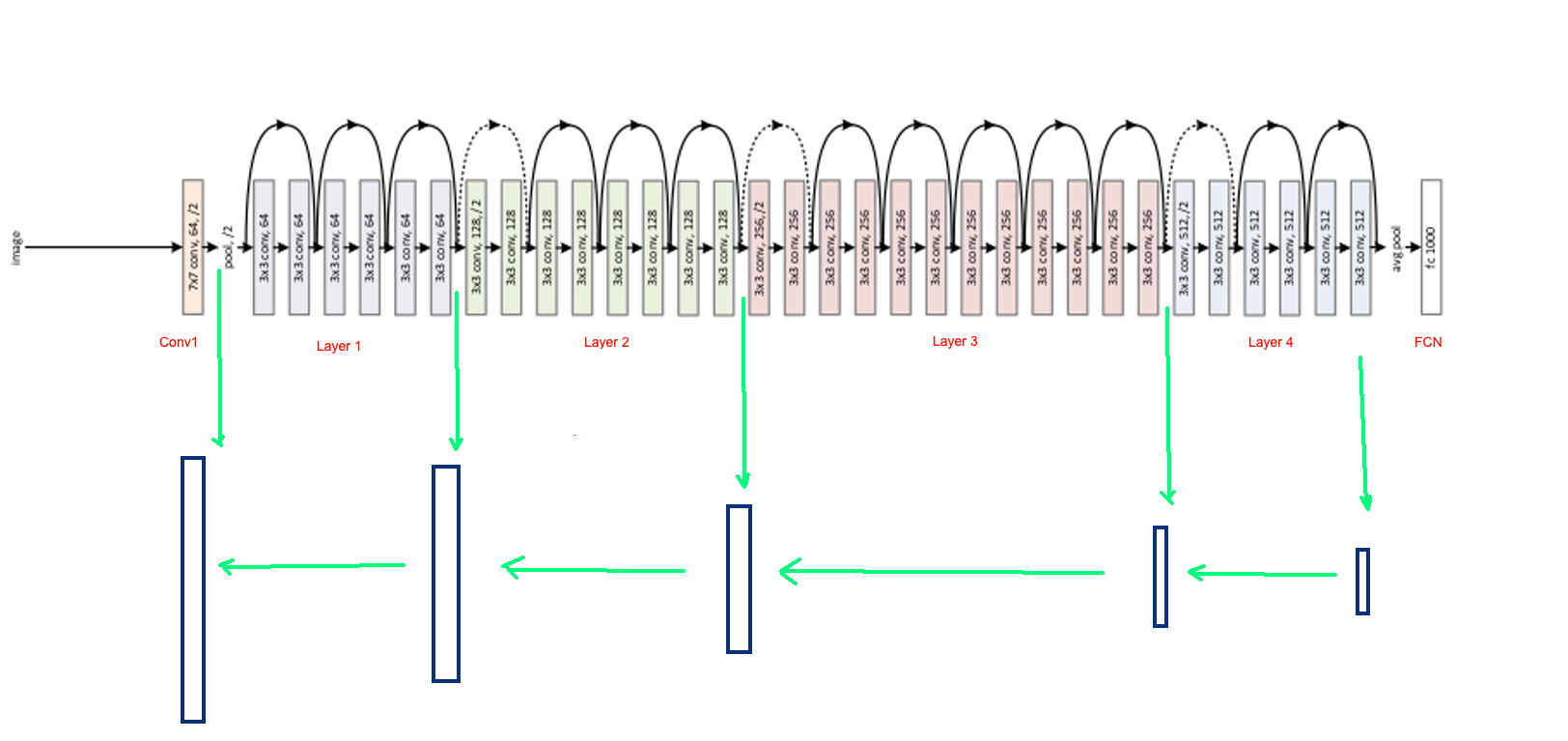
Để giải quyết bài toán, mình sẽ xây dựng model Unet với backbone là Resnet50. Bạn nên tìm hiểu về Resnet nếu chưa biết về kiến trúc này. Hãy quan sát hình minh hoạ dưới đây. Resnet50 được chia thành các khối lớn [Conv1, layer1, layer2, layer3, layer4, FCN] . Unet được xây dựng với Encoder là Resnet50. Ta sẽ lấy ra output của từng khối, tạo các skip-connection kết nối từ Encoder sang Decoder. Decoder được xây dựng bởi các Convolution Transpose layer (xen kẽ trong đó là các lớp Convolution nhằm mục đích giảm số chanel của feature map -> giảm số lượng weight cho model).
Theo quan điểm cá nhân, pytorch rất dễ code, dễ hiểu hơn rất nhiều so với Tensorflow 1.x hoặc ngang ngửa Keras. Tuy nhiên, việc fine-tuning model trong pytorch lại khó hơn rất nhiều so với Keras. Trong Keras, ta không cần quá quan tâm tới kiến trúc, luồng xử lý của model, chỉ cần lấy ra các output tại 1 số layer nhất định làm skip-connection, ghép nối và tạo ra model mới.

Trong pytorch thì ngược lại, bạn cần hiểu được luồng xử lý và copy code những layer muốn giữ lại trong model mới. Hình trên là code của resnet50 trong torchvision. Bạn có thể tham khảo link: torchvision-resnet50. Như vậy khi xây dựng Unet như kiến trúc đã mô tả bên trên, ta cần đảm bảo đoạn code từ Conv1 -> Layer4 không bị thay đổi. Hãy đọc phần tiếp theo để hiểu rõ hơn.
3. Code
Tất cả code của mình được đóng gói trong file notebook Salicon_main.ipynb. Bạn có thể tải về và run code theo link github: github/trungthanhnguyen0502 . Trong bài viết mình sẽ chỉ đưa ra những đoạn code chính.
Import các package
import albumentations as A
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as T
import torchvision.models as models
from torch.utils.data import DataLoader, Dataset
import ....
3.1 utils functions
Trong pytorch, dữ liệu có thứ tự dimension khác với Keras/TF/numpy. Thông thường với numpy hay keras, ảnh có dimension theo thứ tự . Thứ tự trong Pytorch ngược lại là . Mình sẽ xây dựng 2 hàm toTensor và toNumpy để chuyển đổi qua lại giữa hai format này.
def toTensor(np_array, axis=(2,0,1)):
return torch.tensor(np_array).permute(axis)
def toNumpy(tensor, axis=(1,2,0)):
return tensor.detach().cpu().permute(axis).numpy()
## display one image in notebook
def plot_img(img):
...
## display multi image
def plot_imgs(imgs):
...
3.2 Define model
3.2.1 Conv and Deconv
Mình sẽ xây dựng 2 function trả về module Convolution và Convolution Transpose (Deconv)
def Deconv(n_input, n_output, k_size=4, stride=2, padding=1):
Tconv = nn.ConvTranspose2d(
n_input, n_output,
kernel_size=k_size,
stride=stride, padding=padding,
bias=False)
block = [
Tconv,
nn.BatchNorm2d(n_output),
nn.LeakyReLU(inplace=True),
]
return nn.Sequential(*block)
def Conv(n_input, n_output, k_size=4, stride=2, padding=0, bn=False, dropout=0):
conv = nn.Conv2d(
n_input, n_output,
kernel_size=k_size,
stride=stride,
padding=padding, bias=False)
block = [
conv,
nn.BatchNorm2d(n_output),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(dropout)
]
return nn.Sequential(*block)
3.2.2 Unet model
Init function: ta sẽ copy các layer cần giữ từ resnet50 vào unet. Sau đó khởi tạo các Conv / Deconv layer và các layer cần thiết.
Forward function: cần đảm bảo luồng xử lý của resnet50 được giữ nguyên giống code gốc (trừ Fully-connected layer). Sau đó ta ghép nối các layer lại theo kiến trúc Unet đã mô tả trong phần 2.
Tạo model: cần load resnet50 và truyền vào Unet. Đừng quên Freeze các layer của resnet50 trong Unet.
class Unet(nn.Module):
def __init__(self, resnet):
super().__init__()
self.conv1 = resnet.conv1
self.bn1 = resnet.bn1
self.relu = resnet.relu
self.maxpool = resnet.maxpool
self.tanh = nn.Tanh()
self.sigmoid = nn.Sigmoid()
# get some layer from resnet to make skip connection
self.layer1 = resnet.layer1
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
# convolution layer, use to reduce the number of channel => reduce weight number
self.conv_5 = Conv(2048, 512, 1, 1, 0)
self.conv_4 = Conv(1536, 512, 1, 1, 0)
self.conv_3 = Conv(768, 256, 1, 1, 0)
self.conv_2 = Conv(384, 128, 1, 1, 0)
self.conv_1 = Conv(128, 64, 1, 1, 0)
self.conv_0 = Conv(32, 1, 3, 1, 1)
# deconvolution layer
self.deconv4 = Deconv(512, 512, 4, 2, 1)
self.deconv3 = Deconv(512, 256, 4, 2, 1)
self.deconv2 = Deconv(256, 128, 4, 2, 1)
self.deconv1 = Deconv(128, 64, 4, 2, 1)
self.deconv0 = Deconv(64, 32, 4, 2, 1)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
skip_1 = x
x = self.maxpool(x)
x = self.layer1(x)
skip_2 = x
x = self.layer2(x)
skip_3 = x
x = self.layer3(x)
skip_4 = x
x5 = self.layer4(x)
x5 = self.conv_5(x5)
x4 = self.deconv4(x5)
x4 = torch.cat([x4, skip_4], dim=1)
x4 = self.conv_4(x4)
x3 = self.deconv3(x4)
x3 = torch.cat([x3, skip_3], dim=1)
x3 = self.conv_3(x3)
x2 = self.deconv2(x3)
x2 = torch.cat([x2, skip_2], dim=1)
x2 = self.conv_2(x2)
x1 = self.deconv1(x2)
x1 = torch.cat([x1, skip_1], dim=1)
x1 = self.conv_1(x1)
x0 = self.deconv0(x1)
x0 = self.conv_0(x0)
x0 = self.sigmoid(x0)
return x0
device = torch.device("cuda")
resnet50 = models.resnet50(pretrained=True)
model = Unet(resnet50)
model.to(device)
## Freeze resnet50's layers in Unet
for i, child in enumerate(model.children()):
if i <= 7:
for param in child.parameters():
param.requires_grad = False
3.3 Dataset and Dataloader
Dataset trả nhận 1 list các image_path và mask_dir, trả về image và mask tương ứng.
Define MaskDataset
class MaskDataset(Dataset):
def __init__(self, img_fns, mask_dir, transforms=None):
self.img_fns = img_fns
self.transforms = transforms
self.mask_dir = mask_dir
def __getitem__(self, idx):
img_path = self.img_fns[idx]
img_name = img_path.split("/")[-1].split(".")[0]
mask_fn = f"{self.mask_dir}/{img_name}.png"
img = cv2.imread(img_path)
mask = cv2.imread(mask_fn)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
mask = cv2.cvtColor(mask, cv2.COLOR_BGR2GRAY)
if self.transforms:
sample = {
"image": img,
"mask": mask
}
sample = self.transforms(**sample)
img = sample["image"]
mask = sample["mask"]
# to Tensor
img = img/255.0
mask = np.expand_dims(mask, axis=-1)/255.0
mask = toTensor(mask).float()
img = toTensor(img).float()
return img, mask
def __len__(self):
return len(self.img_fns)
Test dataset
img_fns = glob("./Salicon_dataset/image/train/*.jpg")
mask_dir = "./Salicon_dataset/mask/train"
train_transform = A.Compose([
A.Resize(width=256,height=256, p=1),
A.RandomSizedCrop([240,256], height=256, width=256, p=0.4),
A.HorizontalFlip(p=0.5),
A.Rotate(limit=(-10,10), p=0.6),
])
train_dataset = MaskDataset(img_fns, mask_dir, train_transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, drop_last=True)
# Test dataset
img, mask = next(iter(train_dataset))
img = toNumpy(img)
mask = toNumpy(mask)[:,:,0]
img = (img*255.0).astype(np.uint8)
mask = (mask*255.0).astype(np.uint8)
heatmap_img = cv2.applyColorMap(mask, cv2.COLORMAP_JET)
combine_img = cv2.addWeighted(img, 0.7, heatmap_img, 0.3, 0)
plot_imgs([img, mask, combine_img])
Test result
3.4 Train model
Vì bài toán đơn giản và để cho dễ hiểu, mình sẽ train theo cách đơn giản nhất, không validate trong qúa trình train mà chỉ lưu model sau 1 số epoch nhất định
train_params = [param for param in model.parameters() if param.requires_grad]
optimizer = torch.optim.Adam(train_params, lr=0.001, betas=(0.9, 0.99))
epochs = 5
model.train()
saved_dir = "model"
os.makedirs(saved_dir, exist_ok=True)
loss_function = nn.MSELoss(reduce="mean")
for epoch in range(epochs):
for imgs, masks in tqdm(train_loader):
imgs_gpu = imgs.to(device)
outputs = model(imgs_gpu)
masks = masks.to(device)
loss = loss_function(outputs, masks)
loss.backward()
optimizer.step()
3.5 Test model
img_fns = glob("./Salicon_dataset/image/val/*.jpg")
mask_dir = "./Salicon_dataset/mask/val"
val_transform = A.Compose([
A.Resize(width=256,height=256, p=1),
A.HorizontalFlip(p=0.5),
])
model.eval()
val_dataset = MaskDataset(img_fns, mask_dir, val_transform)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, drop_last=True)
imgs, mask_targets = next(iter(val_loader))
imgs_gpu = imgs.to(device)
mask_outputs = model(imgs_gpu)
mask_outputs = toNumpy(mask_outputs, axis=(0,2,3,1))
imgs = toNumpy(imgs, axis=(0,2,3,1))
mask_targets = toNumpy(mask_targets, axis=(0,2,3,1))
for i, img in enumerate(imgs):
img = (img*255.0).astype(np.uint8)
mask_output = (mask_outputs[i]*255.0).astype(np.uint8)
mask_target = (mask_targets[i]*255.0).astype(np.uint8)
heatmap_label = cv2.applyColorMap(mask_target, cv2.COLORMAP_JET)
heatmap_pred = cv2.applyColorMap(mask_output, cv2.COLORMAP_JET)
origin_img = cv2.addWeighted(img, 0.7, heatmap_label, 0.3, 0)
predict_img = cv2.addWeighted(img, 0.7, heatmap_pred, 0.3, 0)
result = np.concatenate((img,origin_img, predict_img),axis=1)
plot_img(result)
Kết quả thu được:

Đây là bài toán đơn giản nên mình chú trọng vào quá trình và cách thức fine tuning trong pytorch hơn là đi sâu vào giải quyết bài toán. Cảm ơn các bạn đã đọc
4. Reference
Dataset: salicon.net
Code bài viết: https://github.com/trungthanhnguyen0502/-Viblo-Visual-Saliency-prediction
Resnet50 torchvision code: torchvision-resnet
Bài viết cùng chủ đề Visual saliency: Visual Saliency Prediction with Contextual Encoder-Decoder Network!
Theo dõi các bài viết chuyên sâu về AI/Deep learning tại: Vietnam AI Link Sharing Community
Đừng quên upvote cho mình nhé 
All rights reserved
