Explore dữ liệu với các thư viện chỉ bằng những dòng code đơn giản.
Bài đăng này đã không được cập nhật trong 4 năm
Xin chào các bạn, hôm nay mình sẽ tiếp bước bài viết Exploring dữ liệu chỉ một dòng code . Ở bài viết này mình cũng chỉ dùng một vài dòng code đơn giản để khám phá dữ liệu của mình đang có.
Như chúng ta đều biết việc khám phá và phân tích dữ liệu đóng vai trò cực kì quan trọng, mục đích của khám phá dữ liệu là để biết được những data nào quan trọng và để biết được dữ liệu mình đang có là gì. Tuy nhiên việc phân tích bằng pandas thuần thì nó cần khá nhiều effort trong việc code và cũng cần có nhiều kinh nghiệm. Và thật may mắn rằng có nhiều người giỏi đã tạo ra một số package giúp việc EDA đơn giản hơn ví dụ như ở bài trước mình đã viết: Pandas Profiling, và ở bài này mình sẽ tiếp tục với Sweetviz, và PandasGUI. Ok, get started.
Sweetviz
Sweetviz là một package python mã nguồn mở nhằm giúp tạo ra các hình ảnh trực quan đẹp mắt và đưa ra báo cáo một cách nhanh gọn chỉ vài dòng code. Đầu ra của package này là một ứng dụng HTML hoàn toàn độc lập.
Còn bây giờ thì cài đặt Sweetviz nào:
pip install sweetviz
Sau khi đã cài đặt thành công chúng ta tiến hành EDA dữ liệu sử dụng package sweetviz này nhé. Mình tiếp tục sử dụng tập dữ liệu quen thuộc là titanic mọi người Download ở đây nhé. import các thư viện cần thiết:
import pandas as pd
import sweetviz as sv
Đọc dữ liệu:
data = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
Ok tiếp theo đến đoạn vi diệu đây chỉ cần vài dòng code thôi là chúng ta đã có một báo cáo phân tích, trực quan hóa dữ liệu một cách xịn sò luôn.
my_report = sv.analyze(data)
my_report.show_html()
Ở lệnh show_html sẽ tạo ra report SWEETVIZ_REPORT.html và được lưu lại. Việc chúng ta cần làm bây giờ là show file html đã được lưu:
import IPython
IPython.display.HTML('SWEETVIZ_REPORT.html')
Kết quả:
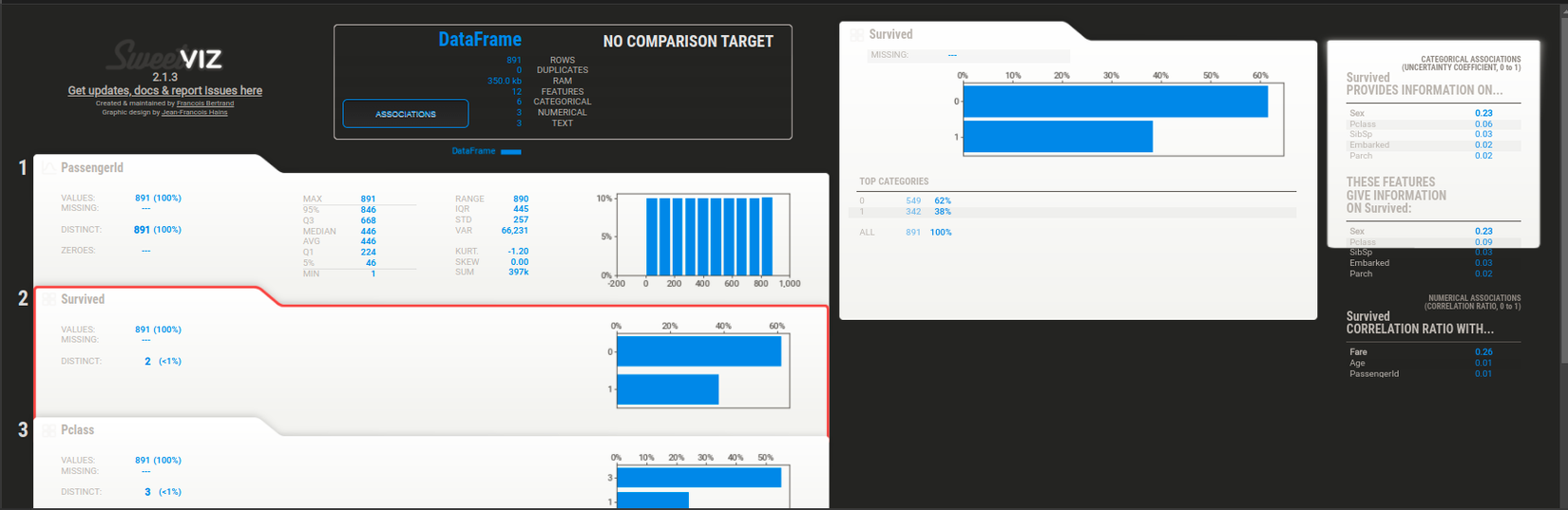
Hình: report
Mọi người có thể xem thêm ở đây.
Sau khi phân tích xong chúng ta sẽ được một file báo cáo như ở trên và có thể tương tác trên báo cáo này luôn.
Vẽ biểu đồ heatmap đối với Sweetviz vô cùng đơn giản, bạn chỉ cần click vào Associations thì sẽ có biểu đồ heatmap như dưới đây:
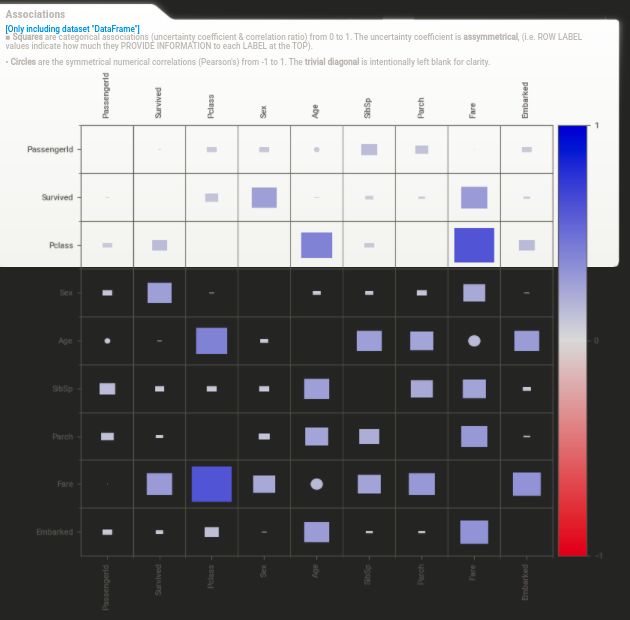
Hình: heatmap
Ở heatmap này ngoài việc hiển thị các tương quan số truyền thống, nó thống nhất trong một đồ thị duy nhất cả tương quan số mà còn cả hệ số không chắc chắn (đối với phân loại-phân loại) và tỷ lệ tương quan (đối với phân loại-số). Hình vuông đại diện cho các biến liên quan đến đặc trưng theo phân loại và vòng tròn đại diện cho các tương quan số-số. Các liên kết phân loại-phân loại (được cung cấp bởi hệ số không chắc chắn) là ASSYMMETRICAL, có nghĩa là mỗi hàng biểu thị mức độ mà tiêu đề hàng (ở bên trái) cung cấp thông tin trên mỗi cột. Ví dụ: “Giới tính”, “Hạng” và “Giá vé” là các yếu tố cung cấp nhiều thông tin nhất về “Sống sót”. Đối với bộ dữ liệu Titanic, thông tin này khá cân xứng nhưng không phải lúc nào cũng vậy.
Thực chất điểm mạnh của Sweetviz là so sánh các tập dữ liệu với nhau và chúng ta cùng thử xem tính năng này nhé. Bây giờ mình sẽ thử so sánh giữa tập train và test của bộ dữ liệu titanic này nhé xem nó thật sự có phải là điểm mạnh của package này không??
train = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
test = pd.read_csv('https://raw.githubusercontent.com/dsindy/kaggle-titanic/master/data/test.csv')
import sweetviz
my_report = sweetviz.compare([train, "Train"], [test, "Test"], "Survived")
my_report.show_html("Report.html") # Not providing a filename will default to SWEETVIZ_REPORT.html
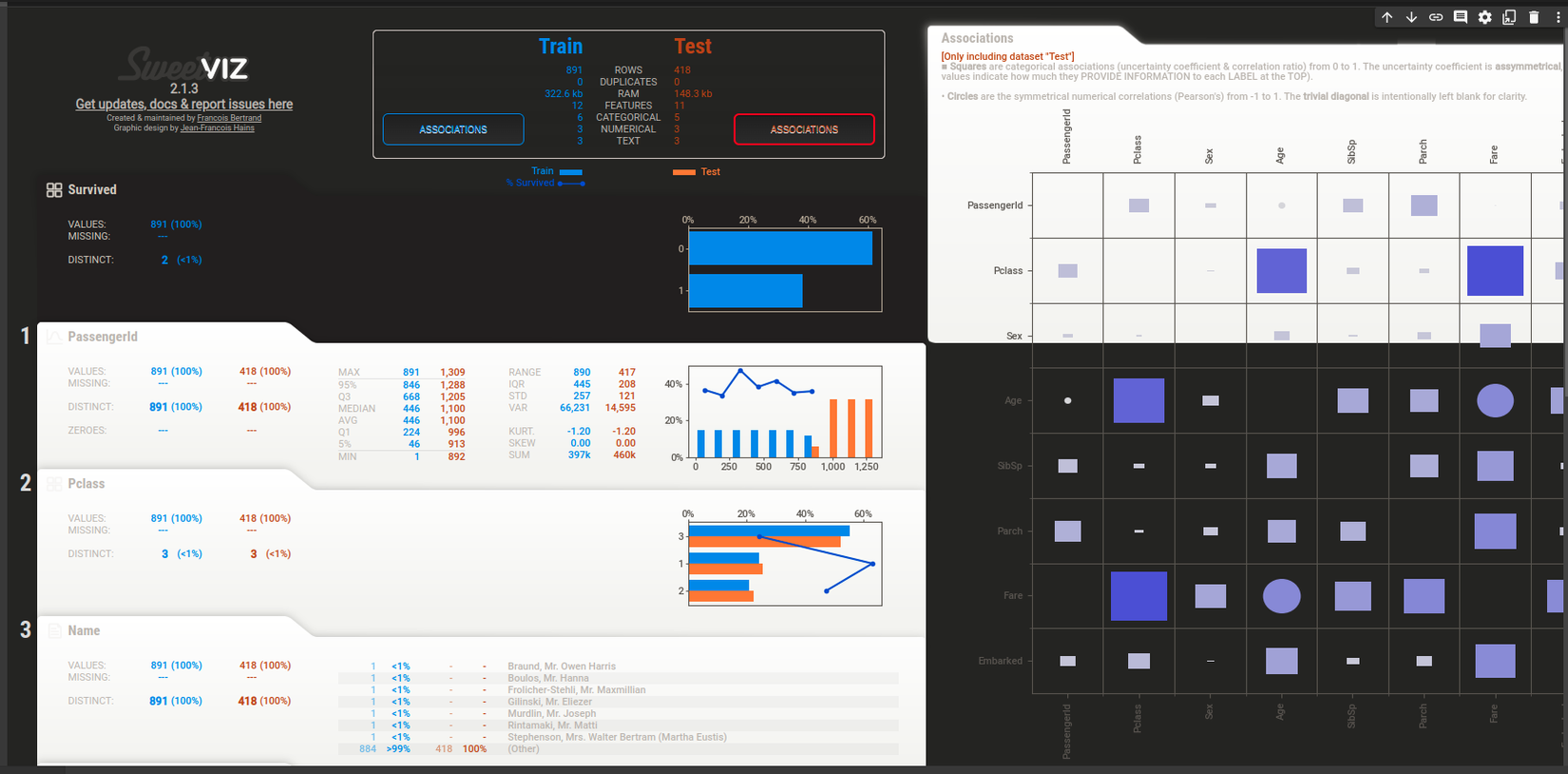
Hình: sweetviz compare
Mọi người có thể xem ở đây
Dựa vào hình trên chúng ta có thể so sánh trực tiếp 2 tập dữ liệu trên 1 bản báo cáo luôn và giúp cho chúng ta dễ dàng hơn giảm tải việc nhìn bản của dữ liệu này rồi lại quay qua nhìn dữ liệu kia.
Theo như cảm nhận của mình về Sweetviz:
-
Hình ảnh đẹp
-
Thông tin thống kê dễ hiểu
-
Khả năng phân tích tập dữ liệu liên quan đến giá trị mục tiêu
-
Khả năng so sánh giữa hai tập dữ liệu
Nhược điểm:
-
Không có hình dung giữa các biến, chẳng hạn như biểu đồ scatter plot
-
Hoặc mở báo cáo ở 1 tab khác
PandasGUI
PandasGUI khác với Sweetviz hay pandas_profiling . Thay vì tạo báo cáo, PandasGUI tạo khung dữ liệu GUI (Giao diện người dùng đồ họa) giúp chúng ta có thể sử dụng để phân tích Khung dữ liệu Pandas của mình chi tiết hơn.
Đầu tiên, chúng ta cần cài đặt gói PandasGUI.
!pip install pandasgui
from pandasgui import show import pandas as pd
Đọc dữ liệu và sử dụng pandasgui:
train = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv") gui = show(train)
Mình sẽ có kết quả như dưới đây:
 Hình: pandasgui
Hình: pandasgui
Như hình trên bạn cũng có thể thấy Pandasgui cung cấp: Filter, Statistic, Grapher, Reshaper bạn có thể lựa chọn theo mong muốn.
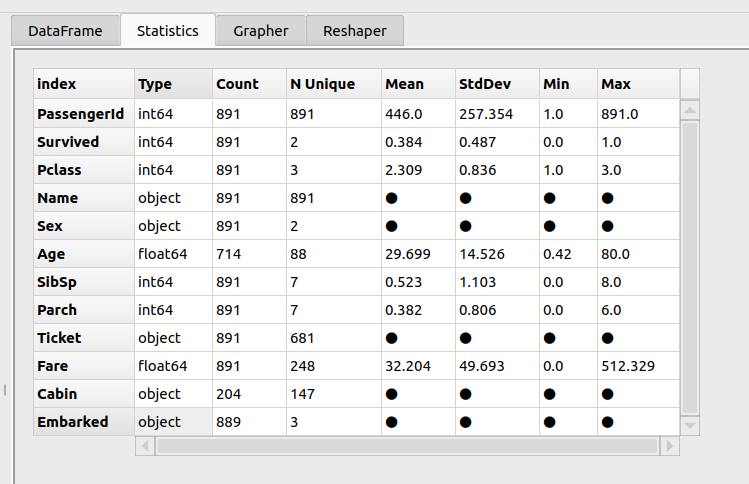
Hình: Statistic
Như ở hình trên mình thấy statistic này khá giống với df.info() tuy nhiên ở đây có thêm phần Nunique nữa 
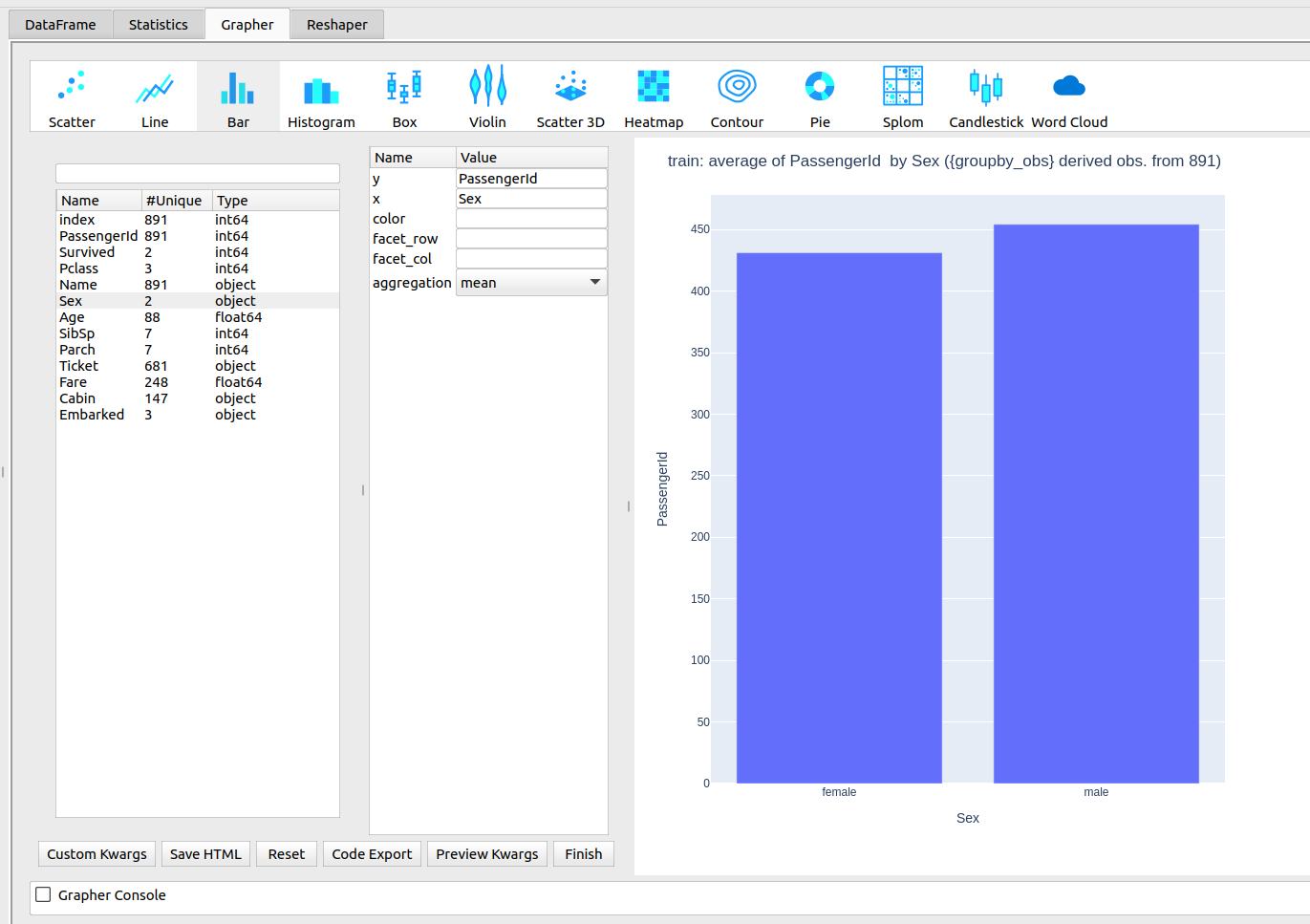
Hình: Grapher
Còn với Grapher thì bạn chỉ cần chọn Grapher -> biểu đồ mong muốn -> chon ra cột bạn muốn vẽ -> được hình vẽ như trên.
So với Pandas_profiling và Sweetviz thì pandasgui cần mình thao tác nhiều hơn . Các bạn có thể lựa chọn package mà bạn mong muốn trong 3 package trên túm lại thì chúng đều giúp mình tiết kiệm thời gian EDA dữ liệu .
Kết Luận
Cảm ơn mọi người đã đọc bài viết của mình, nếu hữu ích thì upvoted cho mình nhé 
Reference
https://github.com/fbdesignpro/sweetviz
All rights reserved
