
Evaluating and Testing models - có vẻ phức tạp hơn bạn nghĩ
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
Đánh giá/kiểm thử là một trong những khâu quan trọng nhất trong kỹ thuật phần mềm. Việc kiểm thử đảm bảo tránh các lỗi phát sinh trong quá trình sử dụng sản phẩm của người dùng, cũng như kiểm tra liệu sản phẩm đã đạt đến yêu cầu nào đó của người lập trình cũng như khách hàng.
Trong Machine Learning, mọi thứ cũng cơ bản là vậy. Đánh giá không chỉ đơn giản là dùng 1 metric nào đấy như accuracy. Vậy nó gồm những gì? Cùng mình tìm hiểu nhé.
Trước khi vào bài, mình xin phép chỉ đề cập đến mô hình (models) thay vì hệ thống (systems), đơn giản là mình không nghĩ mình đủ trình độ và kinh nghiệm để bàn đến các hệ thống học máy phức tạp
1. Tại sao lại cần coi trọng việc đánh giá/kiểm thử?
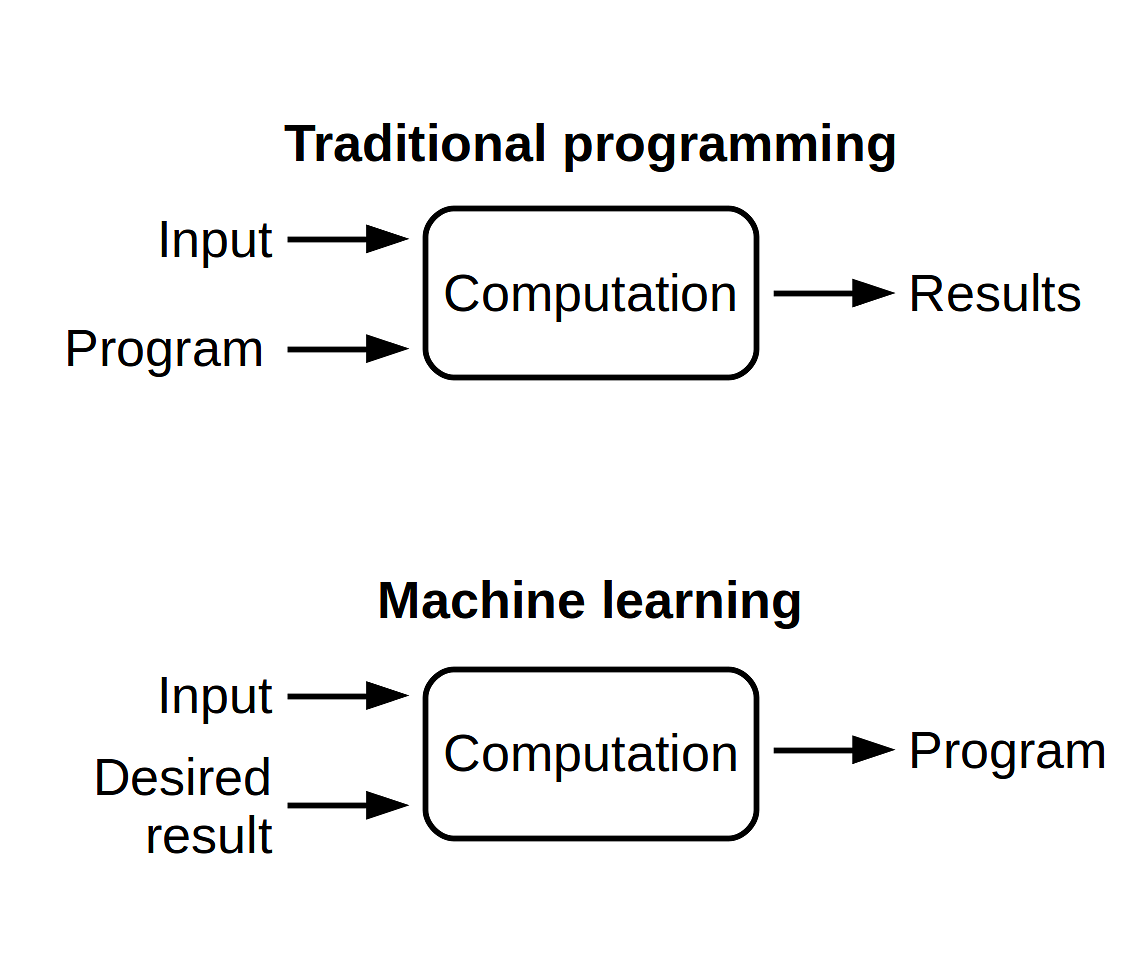
Mô hình học máy là thứ được tạo ra từ dữ liệu đầu vào và đầu ra, từ đó có thể dự đoán đầu ra với đầu vào chưa biết. Nói cách khác, ta hy vọng mô hình có thể có behavior (hành vi) mà ta mong muốn, học được các đặc trưng của dữ liệu nhằm dự đoán một kết quả hợp lý với dữ liệu chưa biết. Vì vậy, một con số đơn lẻ như accuracy hoặc precision khá là "vô thưởng vô phạt" nếu đó là thứ duy nhất ta có sau khi hoàn tất kiểm thử.
Tại sao ư? Mô hình của bạn giống như 1 cái black box, bên trong là lượng lớn tham số. Chỉ với một/một vài metrics, việc đánh giá được hành vi mô hình là điểu bất khả thi. Bạn có thể gặp các trường hợp sau:
- Hành vi mô hình không thể được biết chỉ với một/một vài metrics: ta có thể lấy ví dụ về các bài toán dữ liệu không cân bằng, dữ liệu nhãn A chiếm 99% tập test. Vậy mô hình chỉ cần dự đoán nhãn A là đạt độ chính xác 99%. Vậy nghĩa là con số "99%" này có thể khiến ta nhầm tưởng về performance mô hình
- Phân phối dữ liệu trong khi huấn luyện khác với phân phối dữ liệu trong thực tế: có thể là dữ liệu test không đủ nhiều, không đủ tốt, không sát với dữ liệu thực tế. Hoặc dữ liệu test đủ tốt, nhưng trong tương lai phân phối của dữ liệu thực tế bị thay đổi. Các bạn có thể xem qua bài viết này của anh Phạm Văn Toàn nhé.
- Bias: "tôi là con của cô ấy" dịch là "I am her son" hay là "I am her daughter"? Đó chính là gender bias trong bài toán dịch máy. Hoặc từ "you" trong tiếng anh, đôi khi dịch ra tiếng Việt có thể có vô vàn cách. Sự lựa chọn của mô hình thể hiện behavior của nó và thể hiện đặc điểm của dữ liệu huấn luyện.
- Đôi khi, có những tập nhỏ dữ liệu có tính quan trọng hơn các dữ liệu khác, vì vậy đôi khi sẽ xảy ra trường hợp performance tổng thể của mô hình tăng, nhưng performance lại giảm với phần dữ liệu quan trọng nào đó
- Trong thực tế, thứ bạn muốn đánh giá chưa chắc đã là thứ bạn cần. Mục tiêu tối thượng của mô hình là cải thiện hệ thống, giúp tăng doanh thu. Đôi khi metrics bạn sử dụng không thể đánh giá đầy đủ nhu cầu thực tế, ví dụ như các mô hình recommendation chẳng hạn. Đôi khi độ trễ (latency) cũng quan trọng không kém độ chính xác.
2. Các lỗi phổ biến khi đánh giá và kiểm thử mô hình
- Nhầm lẫn giữa đánh giá và kiểm thử:
- Đánh giá: là sự tóm tắt, tổng kết performance của mô hình trên tập validation và tập test thông qua các metrics, các đồ thị.
- Kiểm thử: là sự kiểm tra kỹ lưỡng về cả trăm thứ mà bài viết này mình chỉ đề cập về behavior của mô hình
Trong hoạt động của hệ thống, 2 việc trên nên được thực hiện song song. Tuy nhiên, hầu hết mọi người lại "trộn lẫn" 2 quá trình này lại: đánh giá được thực hiện tự động từ 1 tập dữ liệu bằng các hàm nào đó, còn kiểm thử được thực hiện "bằng tay" trong khi inference mô hình.
- Không kiểm thử dữ liệu (dữ liệu huấn luyện, dữ liệu test, dữ liệu thực tế,...)
- Chưa đánh giá và kiểm thử ở production
- Quá dựa dẫm vào các hàm đánh giá tự động
- Metrics để đánh giá chưa đủ tốt để đánh giá nhu cầu thực tế
3. Evaluate models with metrics - Thế nào mới là đủ?
Câu trả lời là... chả biết  . Lựa chọn metrics gì, bao nhiêu cho đủ phụ thuộc vào dữ liệu, mô hình và kỳ vọng của bạn cũng như yêu cầu khách hàng. Việc evaluate cần được thực hiện ở cả trong và sau khi huấn luyện mô hình, với cả 3 tập train, validation và test
. Lựa chọn metrics gì, bao nhiêu cho đủ phụ thuộc vào dữ liệu, mô hình và kỳ vọng của bạn cũng như yêu cầu khách hàng. Việc evaluate cần được thực hiện ở cả trong và sau khi huấn luyện mô hình, với cả 3 tập train, validation và test
3.1. Classification metrics
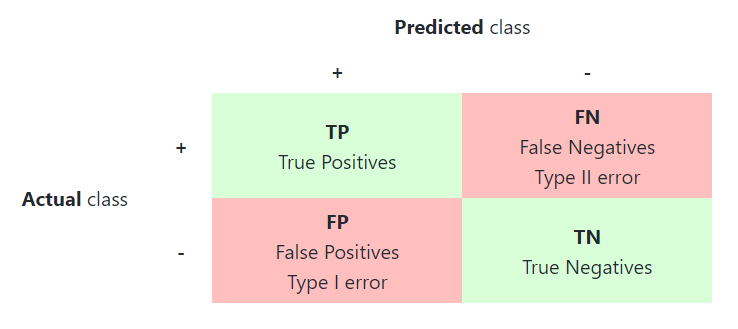
- Confusion matrix: với bài toán binary classification, confusion matrix có thể giúp ta hiểu một phần về behavior của mô hình khi dự đoán, và đặc biệt hữu ích với các bài toán có dữ liệu mất cân bằng. Nó được định nghĩa gồm 4 phần tử:
- True Positive (TP): nhãn dữ đoán là Positive và nó đúng (với nhãn thực sự)
- False Negative (FN): nhãn dự đoán là Negative và nó sai
- True Negative (TN): nhãn dự đoán là Negative và nó đúng
- False Positive (FP): nhãn dự đoán là Positive và nó sai
Lưu ý Positive và Negative chỉ là tượng trưng cho 2 nhãn trong bài toán Binary Classification
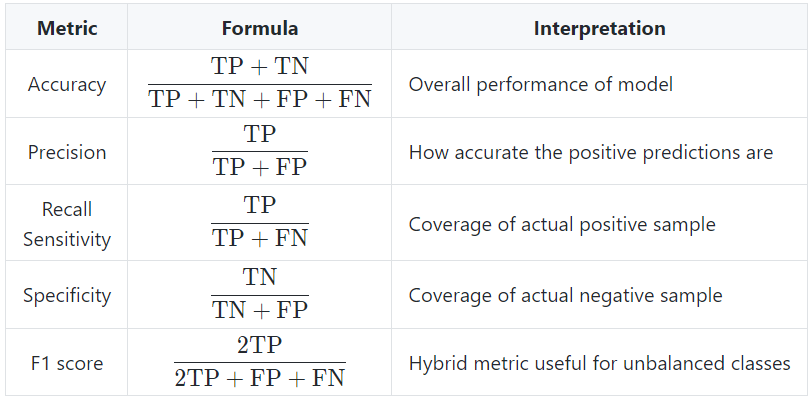
- Các chỉ số dựa trên TP, FN, TN, FP
![image.png]()
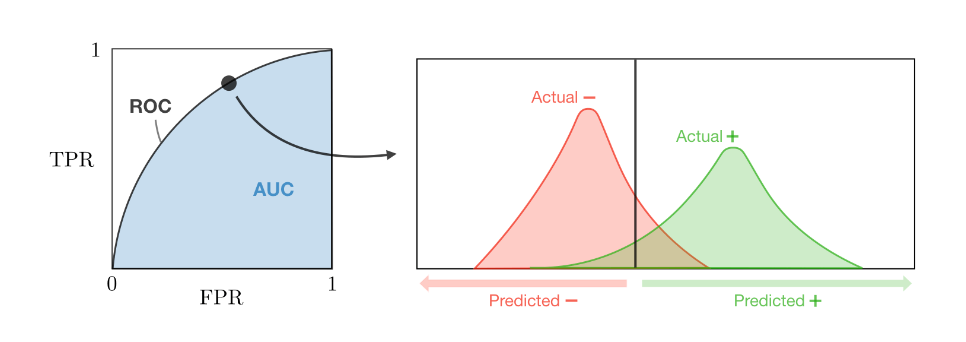
- ROC: ROC là đường cong biểu diễn khả năng phân loại của mô hình tại các ngưỡng (threshold) dựa trên 2 chỉ số:
- True Positive Rate (TPR) = = Recall/Sensitivity. Chỉ số này cho biết tỷ lệ các trường hợp dự đoán đúng là Positivite trên tổng số trường hợp thực sự là Positive, nghĩa là tỷ lệ dự đoán đúng với nhãn thực sự là Positive. TPR càng cao, mô hình dự báo càng tốt trên dữ liệu nhãn Positive.
- False Positive Rate (FPR) = = 1 - Specificity. Chỉ số này giống TPR nhưng với dữ liệu nhãn Negative.
- AUC: là diện tích đường cong nằm dưới đường ROC trong đồ thị và nằm trong khoảng . AUC càng lớn thì mô hình có khả năng phân loại càng tốt.
(Lưu ý: giá trị ngưỡng nằm trong khoảng trong đồ thị đường cong ROC là giá trị để dự đoán nhãn. Giả sử ngưỡng = 0.6, khi mô hình dự đoán xác suất Positive là 0.61 thì kết quả dự đoán của mô hình sẽ là Positive)
![image.png]()
Bạn có thể đọc thêm về AUC, ROC cũng như mối quan hệ phân phối xác suất giữa TPR và FPR trên bài viết này của anh Phạm Đình Khánh.
- Thực tế còn rất nhiều metrics nữa nhưng mình chỉ đưa ra những metrics phổ biến nhất thôi.
3.2. Regression metrics
Do phần này không liên quan nhiều đến đặc trưng dữ liệu như phần 3.1 nên mình hơi ngại viết. Mọi người có thể xem ở đây nhé
4. Behavior Tests
Mục đich của Behavior Test - đương nhiên rồi - là để kiểm thử về hành vi của mô hình. Nghe hơi mông lung nhỉ? Không sao, mình sẽ đi vào ngay luôn đây
4.1. Pre-train tests
Chẳng ai muốn sau khi dành vài tiếng huấn luyện mô hình thì lại không dùng được do vài lỗi vặt cả. Vì vậy, kiểm thử trước khi huấn luyện là điều rất cần thiết, dù ta đôi khi thường không để ý lắm
Một vài tác vụ kiểm thử có thể được cân nhắc:
- Lỗi cú pháp
- Các giá trị hyperparameters
- Shape của đầu vào, đầu ra có đúng yêu cầu/fit với hệ thống không?
- Khoảng giá trị của đầu ra đúng với bài toán không?
- Kiểm tra dữ liệu (tỷ lệ nhãn, khoảng giá trị, data leakage,...)
- ...
4.2. Post-train tests
Mục tiêu của phần này là giúp ta hiểu được logic và hành vi của mô hình sau khi được huấn luyện. Mình sẽ phân tích phần này theo paper Beyond Accuracy: Behavioral Testing of NLP models with CheckList
4.2.1. Invariance Tests
Invariance Tests (kiểm thử bất biến) cho phép ta xác nhận rằng có những sự thay đổi nào đó ở input mà ta kỳ vọng sẽ không ảnh hưởng đến output
Một vài ví dụ về Invariance Tests
- Với model Image Classification, việc thêm một ít nhiễu (tăng một giá trị nhỏ ở một vài điểm ảnh) không làm thay đổi giá trị nhãn dự đoán
- Với model Sentiment Analysis, việc thay đổi tên riêng hoặc địa điểm trong câu không làm thay đổi giá trị dự đoán của mô hình
- Các metrics đánh giá mô hình NLP không giảm/giảm không đáng kể khi tăng độ dài đầu vào văn bản hoặc chèn lỗi đánh máy (Robustness)
4.2.2. Directional Expectation Tests
Directional Expectation Tests cho phép ta xác nhận rằng có những sự thay đổi ở input mà ta kỳ vọng sẽ xảy ra ảnh hưởng tương ứng đến output. Ảnh hưởng này là kỳ vọng của ta về behavior của mô hình.
Một vài ví dụ về Directional Expectation Tests
- Với model dự đoán giá nhà, việc giữ nguyên các chỉ số khác, chỉ tăng số phòng ngủ sẽ tăng giá căn nhà. Chỉ giảm diện tích căn nhà sẽ giảm giá nhà.
- Với model dịch máy, việc thay đổi tên riêng hoặc địa điểm trong câu gốc sẽ làm thay đổi tên hoặc địa điểm tương ứng trong câu đầu ra của mô hình
4.2.3. Minimum Functionality Tests (data unit tests)
Đúng như tên gọi, Minimum Functionality Tests là việc kiểm thử trên các trường hợp hoặc nhóm trường hợp cụ thể trong tập dữ liệu, hay nói cách khác, là việc sử dụng các test cases đơn giản để đánh giá 1 behavior nào đó của dữ liệu (ví dụ 1 tập toàn nhãn negative để đánh giá khả năng dự đoán của mô hình trên dữ liệu negative thực tế)
5. Fairness Tests
Mục đích của việc này là để xác định khi nào model sẽ xảy ra bias và cách giảm thiểu chúng. Để kiểm thử đạt hiệu quả, việc thu thập dữ liệu, đánh giá mô hình nói riêng và hệ thống nói chung cần được thực hiện với nhiều người/nhóm người với nhiều chủng tộc, giới tính, tôn giáo, sắc tộc,... khác nhau. Mọi người có thể tham khảo blog Fairness Indicators của Google.
6. Robustness Tests
Robustness khá khó dịch (với mình) nhưng mọi người có thể tạm hiểu là sức chịu đựng, giới hạn của mô hình. Mô hình càng robust thì càng có khả năng dự đoán tốt ngay cả với dữ liệu đầu vào gặp các trường hợp không mong muốn. Tuy nghe có vẻ quan trọng nhưng robustness tests thường không được chú trọng khi kiểm thử mô hình
Các ví dụ về Robustness Tests:
- Kiểm tra sự quan trọng của các feature với mô hình
- Model có nhạy cảm với covariance shifting/data drift không?
- Model có dễ bị staleness không?
- Tăng độ dài câu/audio test có ảnh hưởng performance không?
- Thêm nhiễu vào ảnh/audio có ảnh hưởng performance không?
- ...
7. Lời kết
Mình cũng chả biết nói gì ở đây cả, cảm ơn mọi người đã đọc nhé =))
All rights reserved
