
[Domain adaptation - P1] Tổng quan về kỹ thuật transfer learning và domain adaptation
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Transfer learning là một kỹ thuật rất hay trong lĩnh vực học sâu, nhờ đó chúng ta có thể giải quyết một nhiệm vụ mới với kiến thức thu được từ một nhiệm vụ cũ để giải quyết việc thiếu dữ liệu được gắn nhãn. Đặc biệt, deep domain adaptation (một nhánh của transfer learning) được chú ý nhiều nhất trong các bài báo gần đây. Các mạng nơ-ron sâu thường có số lượng tham số lớn để học cách biểu diễn từ một tập dữ liệu và một phần thông tin có thể được sử dụng thêm cho một nhiệm vụ mới. Trong bài viết này, mình sẽ đưa ra khảo sát toàn diện liên quan đến deep domain adaptation và phân loại những tiến bộ gần đây thành ba loại dựa trên các cách tiếp cận thực hiện: fine-tuning networks (tinh chỉnh mô hình), adversarial domain adaptation (miền thích ứng đối nghịch) và sample-reconstruction approaches (cách tiếp cận tái tạo mẫu).
Trong suốt thập kỷ qua, lĩnh vực Thị giác máy tính đã có những bước phát triển vượt bậc. Sự tiến bộ này chủ yếu là do hiệu quả không thể phủ nhận của mạng nơ-ron tích chập (CNN). CNN cho ta thấy nó có thể lấy được đặc trưng rất tốt từ dữ liệu dạng ảnh thông qua các kernel. Ví dụ, trong cài đặt phân loại, bạn thường sử dụng một trong các kiến trúc mạng phổ biến hiện nay như ResNet, VGG, EfficientNet,RepVGG,... để huấn luyện cùng với bộ dữ liệu có nhãn của bạn. Gần đây, nổi lên với kiến trúc mạng MLP, lấy cảm hứng từ mô hình ViT, chia ảnh thành 16 phần và thực hiện tính toán trên từng vùng, các mô hình gần đây như RepMLP, ResMLP. được huẩn luyện trên tập imagenet, sử dụng những pretrained-model đó và
Mặt khác, bạn có thể sử dụng kỹ thuật transfer learning bằng cách sử dụng các pretrained model đã được huấn luyện trên tập imagenet sau đó huấn luyện nó trên bộ dữ liệu hiện có của mình, điều này sẽ làm cho mô hình của bạn học nhanh hơn vì có khởi đầu tốt hơn việc bạn lấy ngẫu nhiên các trọng số cho mô hình, không những học nhanh hơn mà nó còn đạt độ chính xác cao hơn.
Cả 2 hướng tiếp cận trên chỉ thích ứng tốt trên bộ dữ liệu có phân phối giống với tập huấn luyện, việc đưa vào mô hình đầu vào có phân phối khác với dữ liệu huấn luyện sẽ làm cho mô hình có kết quả không tốt nữa. Ví dụ, bạn có 1 bài toán cho xe tự hành đó là nhận dạng biển báo giao thông, tòa nhà, cây cối, người đi bộ,... ở TP Hà Nội sử dụng semantic segmentation, bạn sẽ huấn luyện mô hình của mình với bộ dữ liệu này và đạt kết quả rất tốt, khi đưa ra thực tế trên đường phố Hà Nội hoạt động khá tốt. Nhưng khi sử dụng mô hình đó ở Singapore thì mô hình lại đạt kết quả không cao do xe cộ đã khác đi rất nhiều, về màu sắc và hình dáng, tòa nhà, đường phố đều khác.
Lý do khiến mô hình của bạn hoạt động không tốt trong các trường hợp này là miền dữ liệu đã bị thay đổi. Trong trường hợp cụ thể này, miền của dữ liệu đầu vào đã thay đổi trong khi các trọng số của mô hình được học trên nhãn ban đầu vẫn giữ nguyên. Trong một số bài toán đặc thù, việc lấy dữ liệu đích ở bài toán gốc là rất khó nên bạn sẽ phải huấn luyện mô hình trên dữ liệu nguồn tương tự sau đó muốn cho mô hình có thể thích ứng được với dữ liệu đích kia. Kỹ thuật domain adaptation ( thích ứng miền) được ra đời để giải quyết những bài toán này.
Nói chung, thích ứng miền sử dụng dữ liệu được gắn nhãn trong một hoặc nhiều miền nguồn để giải quyết các nhiệm vụ mới trong miền đích. Như vậy thì yếu tố về sự tương quan giữa miền dữ liệu nguồn và miền dữ liệu đích rất quan trọng, xác định mức độ thành công của việc điều chỉnh.
Tổng quan về transfer learning và domain adaptation
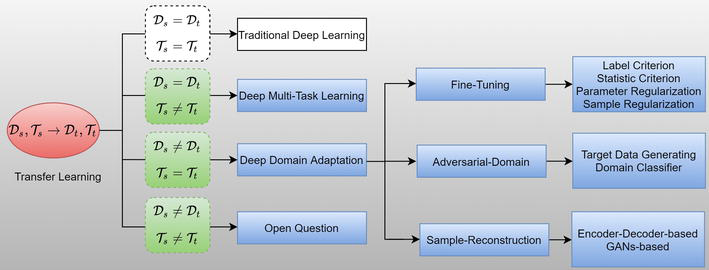
Hình 1 : Cấu trúc dạng cây của transfer learning Trước tiên nhìn vào hình ảnh trên chắc hẳn nhiều bạn sẽ thắc mắc là kí hiệu gì đúng không nào? Vậy mình sẽ giải thích từng kí hiệu nhé.
Định nghĩa : Giả sử chúng ta có một tập dữ liệu , trong đó là không gian chiều dữ liệu, dữ liệu được tuân theo phân phối . Một miền dữ liệu được định nghĩa như sau . Do đó một miền dữ liệu chứa 2 thành phần đó là không gian chiều dữ liệu và phân phối xác suất trên tập dữ liệu đó.
Định nghĩa : Giả sử chúng ta có một tập dữ liệu và nhãn trong đó là không gian nhãn. Một miền dữ liệu được định nghĩa như sau .
Vậy Transfer learning là gì? Cho một miền nguồn và nhiệm vụ tương ứng , mô hình sẽ dự đoán từ tri thức của và . Mục tiêu là học dự đoán từ tri thức của và . Mục tiêu của Transfer learning là cải thiện hiệu năng của bằng cách sử dụng tri thức từ , trong đó .
Transfer Learninglà một nghiên cứu rộng trong lĩnh vực học máy. Nó được chia thành 4 loại: Traditional Deep Learning, Deep Multi-Task Learning, Deep Domain Adaptation và Open Question.\
-
Với bài toán có , vấn đề trở thành bài toán học sâu truyền thống. Trong trường hợp này, dữ liệu được chia thành dữ liệu huấn luyện và dữ liệu kiểm thử , sau đó bạn huấn luyện mô hình nơ-ron để học trên và áp dụng nó để dự đoán trên tập .
-
Với bài toán có , transfer learning biến thành bài toán multi-task learning. Cùng chung miền dữ liệu nhưng đầu ra của mô hình phải học nhiều nhiệm vụ khác nhau, ở đây chúng ta phải sử dụng một mạng đủ lớn để có thể học đặc trưng chia sẻ giữa nhiều nhiệm vụ. Ví dụ, nhận đầu vào là 1 ảnh trên đường phố, chúng ta phải sử dụng một mô hình học sâu có đủ khả năng để có thể nhận dạng ra được người đi bộ, xe cộ, tòa nhà, làn đường, ...
-
Với bài toán có , deep domain adaptation được sử dụng để chuyển tri thức, thông tin từ dữ liệu nguồn sang dữ liệu đích. Nói chung, mục tiêu của domain adatation là học một hàm ánh xạ để giảm sự phân kỳ miền giữa và bao gồm dịch chuyển phân phối và các không gian đặc trưng khác nhau. Cụ thể, nhận miền nguồn là cho nhiệm vụ và cho nhiệm vụ , trong đó # . Domain adaptation có mục tiêu học trong khi tri thức từ và có thể sử dụng để nâng cao .
-
Với bài toán có , việc sử dụng transfer learning phải được tiến hành cẩn thận. Nếu miền dữ liệu khác xa so với thì việc chuyển đổi sẽ làm cho hàm dự đoán có hiệu năng giảm đi, chưa kể đến việc các nhiệm vụ và cũng khác nhau .Từ một tổng quan tài liệu về học sâu, chúng tôi nhận thấy rằng có rất ít nghiên cứu về kịch bản này và nó vẫn còn là một câu hỏi mở.
Tóm lại, các định nghĩa trên cho chúng ta câu trả lời cho việc chuyển giao những gì, và bốn kịch bản chứng minh vấn đề nghiên cứu về thời điểm chuyển giao. Trong các phần tiếp theo,mình sẽ giới thiệu và tóm tắt ba phương pháp chính của domain adaptation.
Các phương pháp chính của domain adaptation
Mục tiêu của domain adaptation là giảm sự khác biệt về phân phối miền giữa miền nguồn và miền đích để kiến thức đã học từ miền nguồn có thể được áp dụng thêm cho miền đích.
Có 3 loại domain adaptation chính đó là : fine-tunning network, adversarial domain adaptation và data-reconstruction approaches.
fine-tunning network
Một cách tự nhiên để giảm sự thay đổi miền là tinh chỉnh các mạng được đào tạo trước với dữ liệu trong miền đích, vì các nghiên cứu trước đây cho thấy rằng các mạng nơ-ron sâu được học từ các bộ dữ liệu lớn như ImageNet có thể được sử dụng hiệu quả để giải quyết nhiều tác vụ khác nhau trong thị giác máy tính. Cụ thể, đối với một mô hình được đào tạo trước như VGG hoặc ResNet , chúng ta có thể đóng băng chúng lại và coi nó như 1 bộ trích xuất cố định và chỉ huấn luyện những lớp FC sau đó, hoặc có thể mở ra để huấn luyện cùng với các lớp FC sau,. Ý tưởng chính đằng sau điều này là các biểu diễn cấp thấp đã học trước đó chủ yếu bao gồm các đặc điểm chung như bộ dò cạnh, góc. Trong quá trình tinh chỉnh mạng, sự khác biệt giữa miền nguồn và miền đích thường được đo bằng một tiêu chí như tiêu chí dựa trên nhãn lớp và tiêu chí thống kê. Thay vì sử dụng trực tiếp phép đo như một tiêu chí để điều chỉnh mạng, các kỹ thuật chính quy cũng có thể được sử dụng để tinh chỉnh, chủ yếu bao gồm chính quy tham số và chính quy mẫu.
Adversarial domain adaptation
GAN là một phương pháp đầy rất hay và nhận được nhiều sự chú ý nhất do cách tiếp cận học tập không giám sát và tính linh hoạt mô hình. Cụ thể, thông thường có hai mạng trong GAN, đó là một mạng generator và một mạng classification. Mạng generator có tạo ra một kịch bản giả từ một không gian đầu vào được gọi là không gian ẩn và mạng classification có thể phân biệt các mẫu thật với mẫu giả. Bằng cách luân phiên huấn luyện hai mạng này, cả hai đều có thể nâng cao khả năng của mình. Ý tưởng cơ bản đằng sau GAN là chúng ta muốn phân phối dữ liệu mà trình tạo học được gần với phân phối dữ liệu thực. Và điều này rất giống với nguyên tắc của domain adaptation, đó là sự phân phối dữ liệu đã học giữa miền nguồn và miền đích gần nhau.
Data-reconstruction approaches
Phương pháp tiếp cận tái tạo dữ liệu là một loại phương pháp deep domain adaptation sử dụng kiến trúc bộ mã hóa và giải mã . Trong đó mạng mã hóa được sử dụng để sinh ra véc-tơ biểu diễn của nó và mạng giải mã để có thể cấu trúc lại dữ liệu đầu vào từ véc-tơ biểu diễn đó. Chủ yếu có hai loại phương pháp để tiến hành tái tạo dữ liệu: (1) Một cách điển hình là sử dụng mạng sâu bộ mã hóa-giải mã; (2) Một cách khác là tiến hành xây dựng lại mẫu dựa trên các GAN như cycle GAN.
Tổng kết
Ở phần này thì mình chỉ đưa ra khái niệm cơ bản của các kỹ thuật transfer learning và domain adaptation. Một số khái niệm cơ bản của domain adaptation được đưa ra, bài viết sau mình sẽ đi sâu vào từng loại của domain adaptation và ứng dụng của nó.
Tài liệu tham khảo
All rights reserved
