Distributed monolith và pha cứu thua ngoạn mục của team DevOps
Bài đăng này đã không được cập nhật trong 3 năm
Code này dù đúng dù sai thì người bị hại vẫn là team DevOps.
Câu nói này dù là mình mới phịa ra để câu like thôi nhưng sau một hồi nghiền ngẫm thì thấy cũng xứng đáng để trở thành một chân lý mới của giới làm hạ tầng chứ chẳng chơi. Các bạn DevOps lưu lại nhé để đến lúc hệ thống có vấn đề thì có cái để mà làm caption than thở trên facebook.
Còn đây là câu chuyện về việc triển khai ứng dụng Monolith dưới dạng Distributed và một góc nhìn tích cực hơn về cái gọi là anti-pattern của hệ thống microservice này.

First things first
Đầu tiên lại là màn chào hỏi quen thuộc, mình là Minh Monmen và là một Thợ diệt cỏ. Đây là cách bọn mình gọi team DevOps ở công ty vì team này có nhiệm vụ là chuyên tìm và diệt trừ code cỏ của developer. Ngoài việc diệt cỏ ra thì mình cũng đảm nhiệm vai trò solution architect cho nhiều dự án khác nhau nữa. Nói chung là công việc của mình thường xoay quanh quy trình tìm - diệt - đưa giải pháp.
Câu chuyện này vốn đã xảy ra cũng khá lâu rồi, từ ngày mình còn làm mạng xã hội cơ. Thế nhưng gần đây mình có được trải nghiệm lại trong một tình huống tương tự với vai trò là quan sát viên nên mới nhớ ra để kể lại cho các bạn. Mong rằng sau câu chuyện này các bạn sẽ biết thêm một phương án dự phòng khẩn cấp nếu gặp phải tình huống tương tự.
Trước khi bắt đầu bài viết thì mình cũng hy vọng rằng các bạn đều hiểu những thuật ngữ kiểu microservice, monolith, distributed nghĩa là gì để mình đỡ mất công giải thích lại. Ngoài ra trong bài viết có thể có 1 số các kiến thức hoặc thuật ngữ khác liên quan tới kubernetes, api gateway,... thì cũng cố tự tìm hiểu giùm mình nha.
Sẵn sàng bánh kẹo trà nước ngồi nghe chưa? Oke bắt đầu.
Chuyện từ một chiếc monolith
Ai cũng sẽ bắt đầu với monolith. Và NÊN như vậy.
Trong một kỷ nguyên của cờ lao (cloud), của đít tri biu tựt (distributed), của mai cờ rô sơ vít (microservice) thì ông dev nào cũng muốn mình được xây dựng một hệ thống microservice từ con số 0 - tức là xây mới hoàn toàn cho nó đúng chuẩn ấy. Điều này chắc chẳng có gì phải bàn, bởi vì chẳng ai muốn ngồi sửa một chiếc app truyền thống cũ kỹ chậm chạp, đắp thêm đầu thêm đuôi cho nó thành hình microservice cả. Ông nào cũng muốn đập đi làm lại cho lẹ vậy thôi.
Thế nhưng cuộc đời thì không như là mơ và câu chuyện làm sản phẩm thì tất nhiên là không như là làm thơ rồi. Nuôi một đứa bé thì phải bắt đầu từ lúc mới sinh, rồi vệ sinh bú mớm bao năm nó mới lớn thành cô học sinh ngoan ngoãn xinh đẹp chứ đâu có chuyện cứ thai nghén 18 năm rồi đẻ ra cái đã thành người lớn luôn đỡ phải nuôi như thế. Làm sản phẩm thì sẽ phải cân nhắc đưa sản phẩm ra mắt càng sớm càng tốt. Ra mắt rồi thì được tới đâu ta sửa tới đó. Câu chuyện over-engineering thì mình cũng đã đề cập trong bài viết Software Architect - Bad practices rồi các bạn có thể sang đó tham khảo.
Oke thế thì bắt đầu từ monolith để làm sản phẩm cho nhanh vậy. Ban đầu bọn mình cũng chỉ xuất phát từ một monolith bằng PHP chứa hết các logic.

Nó vẫn chạy khá ổn trên môi trường dev với một số ít người dùng nội bộ. Thế nhưng khi lên production xong và lại cộng với hiệu ứng truyền thông thì cũng kha khá người dùng truy cập dẫn đến app lăn quay ra chết. Mặc dù điều này cũng được dự kiến trước rồi 😅 tuy nhiên việc nó chết hơi nhanh cũng khiến tụi mình khá shock và luống cuống trong việc xử lý. Rất nhiều phương án ngay trong đêm được bọn mình triển khai như scale database, tạo thêm index, scale app,...
Các phương án này thì đều có hiệu quả ít nhiều, dần dần bọn mình cũng thấy load của database và backend service giảm xuống, truy cập vào app cũng dần nhanh hơn. Thế nhưng cũng chỉ được một thời gian là app lại lăn ra chết.
Well, check hệ thống khi đó thì:
- Tải của database bình thường
- Tải của app bình thường
- Số lượng người dùng không nhiều (quá)
Thế nhưng con nginx (mà bọn mình đặt trước php-fpm) thì lại liên tục báo request 499 và mobile app không gọi được API dẫn đến tê liệt.
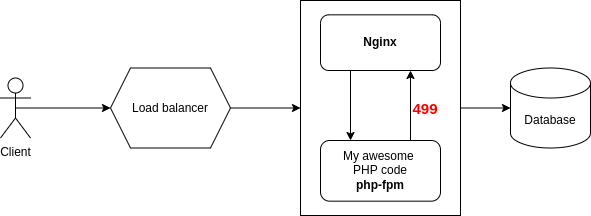
Ban đầu mình nghĩ là do config php-fpm chạy trong container chưa chuẩn, dẫn đến nó tạo ít worker nên xử lý được ít request. Tuy nhiên dù có tăng config php-fpm lên, hay sau đó bọn mình còn scale app lên gần 200 instance (200 pod trên kubernetes) thì vẫn chỉ được một lúc là lăn ra chết cả.
Khung cảnh lúc đó đúng là:
Sếp thì đi tới đi lui Dev thì ngơ ngác: "Code tui lỗi gì?"
Lỗi của service thứ ba
Sau khi thi triển hết 72 phép thần thông để debug thì bọn mình cũng nhận ra kẻ nào mới là nguyên nhân gây ra chết hệ thống thật sự.
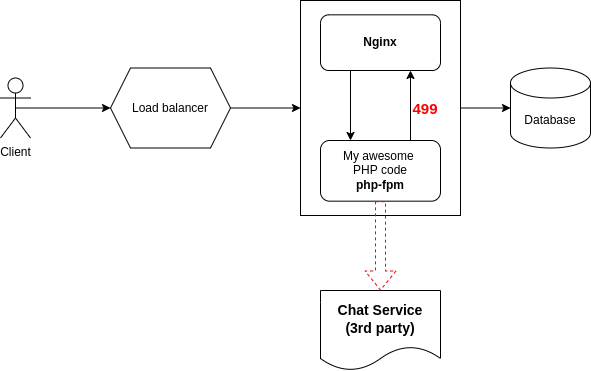
Số là ban đầu bọn mình có sử dụng một nền tảng chat opensource từ bên thứ ba. Và mặc dù nó hoạt động rất ổn với các hệ thống chat nội bộ tuy nhiên khi scale lên để phục vụ người dùng phổ thông thì nó không đáp ứng được dẫn đến request tới nó đều response rất chậm. Chính việc phải chờ đợi khi request tới hệ thống chat kia đã làm đầy hết các worker process của php-fpm dẫn đến các request thông thường khi gọi tới app cũng bị nginx từ chối vì phải chờ đợi quá lâu.
Biết được kẻ phạm tội thì đã là một chiến thắng đáng kể. Nhưng khắc phục nó ra sao thì lại là một bài toán khó mà tụi mình chưa từng trải qua bao giờ. Tất nhiên là ai cũng biết trong trường hợp này thì phải tối ưu thằng chat kia cho nó response nhanh hơn, rồi đặt timeout vào service backend của mình để không chờ thằng chat quá lâu nữa,... Thế nhưng tất cả những cái phương pháp trong SGK ấy lại đều cần có một yếu tố là thời gian. Trong khi đấy thì thời gian là cái mà tụi mình không có.
Lúc ấy thì chưa phổ biến mấy cái service mesh rồi traffic control rồi circuit breaker đâu, nên đừng ai bảo: Chết vì service call service là vấn đề cố hữu của microservice rồi sao không áp dụng các biện pháp đó nha.
Distributed monolith to the rescue
Sau khi vận dụng tương đối nhiều bộ não thì phương án khả thi duy nhất (và nhanh chóng) mà khi đó tụi mình nghĩ ra chính là chấp nhận hy sinh.

Hệ thống của bọn mình được deploy trên kubernetes bằng helm chart và được quản lý bằng ArgoCD. Do đó tụi mình lợi dụng việc triển khai app và routing dễ dàng để deploy chính app của tụi mình lên bằng 1 deployment khác sau đó routing toàn bộ API liên quan tới chat ra deployment mới này. Và Distributed monolith đầu tiên của tụi mình ra đời.
Với cách triển khai này, toàn bộ phần core API liên quan tới user, post, comment,... được phục vụ bằng 1 deployment và chat sẽ được phục vụ bằng 1 deployment khác. Tất nhiên là sau đó thì deployment chat vẫn tiếp tục sống dở chết dở, nhưng nó chỉ là một tính năng ở trong app thôi và phần lớn người dùng vẫn có thể dùng các tính năng khác một cách bình thường. Đây chính là việc chấp nhận một phần hệ thống hy sinh cho mục tiêu cao cả hơn.

Sau này mình tiếp tục gặp nhiều bài toán khác cũng tương tự, khi một resource phụ nào đó làm chết service chính, hay việc read (ít quan trọng hơn) giết chết các action write (quan trọng hơn) thì cách xử lý nhanh nhất đều sẽ là tạo ra nhiều deployment với các config riêng biệt để hạn chế ảnh hưởng của các action này.
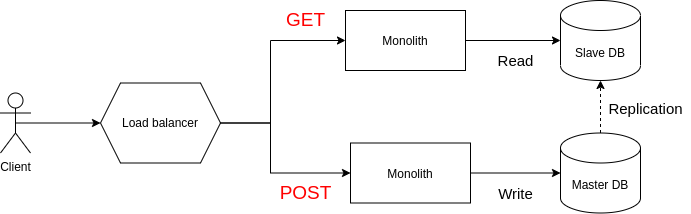
Mặc dù helm chart mặc định đã làm được việc 1 chart deploy nhiều lần với nhiều file config, tuy nhiên mình khuyến khích các bạn sử dụng một công cụ quản lý helm deployment để quản lý việc clone này tốt hơn. Như bọn mình đang sử dụng là thằng ArgoCD nhé.
Một số chia sẻ thêm
Bài toán gốc của vấn đề chính là việc phụ thuộc lẫn nhau giữa các thành phần trong microservice, khi service A phụ thuộc vào service B,... dẫn đến việc B chết thì A cũng chết theo, hoặc data của service B phải chia sẻ data với service A.
Đây cũng là một trong những vấn đề khó khăn nhất khi triển khai microservice. Người ta cũng cho các bạn rất nhiều pattern thiết kế để xử lý như là:
- Gộp chung service, định nghĩa lại chức năng của các service khi 2 service quá phụ thuộc vào nhau.
- Tạo nhiều thành phần trong 1 service cùng share data nhưng không cần gọi chéo (ví dụ tách riêng component read và write)
- Event/subscription model để sync data giữa các service, mỗi service tự quản lý data liên quan tới mình.
Hoặc nếu không thể tránh việc gọi chéo do thiết kế hệ thống không thể thay đổi được, thì có thể sử dụng các công cụ hỗ trợ để quản lý việc gọi chéo như là triển khai service mesh với tính năng circuit breaker, timeout để hạn chế các service kéo chết nhau. Tuy nhiên thì khi áp dụng service mesh thì nhớ để ý tới latency mà nó thêm vào khi các service gọi nhau nha. Nhiều khi con số này nó rất lớn và bạn sẽ không dễ chấp nhận đâu (ví dụ như tụi mình là không dám xài luôn).
Một lưu ý khác đó là việc thiết kế các service gọi nhau cũng nên có chiến lược chia lớp rõ ràng. Hạn chế call service kiểu loạn xì ngầu như này (nếu có thể tránh):

Mà hãy chia hệ thống thành 2 lớp rõ ràng như này:
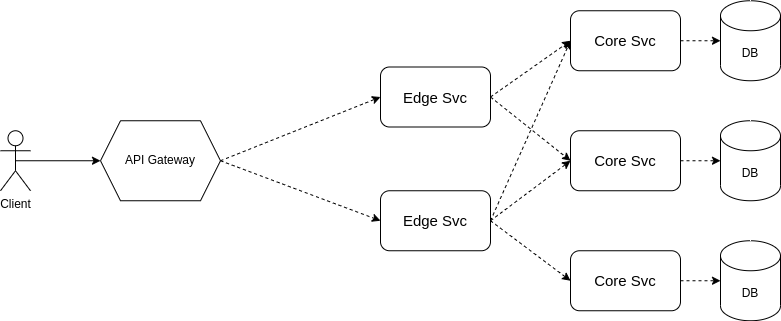
Trong đó:
- lớp core service sẽ được dùng để quản lý trực tiếp data và thực hiện các nghiệp vụ chính. Trong lớp core service có thể tổ chức nhiều service nhỏ thực hiện các nghiệp vụ chuyên biệt như tối ưu read, write,...
- lớp edge service sẽ thực hiện các nghiệp vụ tổng hợp data từ các service khác nhau và trả cho người dùng.
Thiết kế như này thì việc gọi chéo sẽ chỉ diễn ra tại các edge service và sẽ dễ dàng tối ưu connection, timeout, retry, failover,... hơn.
Ví dụ:
- Core service bao gồm post svc, comment svc, profile svc,...
- Edge service bao gồm feed svc, search svc,...
Tổng kết
Nếu mọi người đọc về Distributed monolith thì thường chỉ hay đọc những bài viết mang màu sắc tiêu cực, nào là đây là anti-pattern, đây là làm microservice bị sai, đây là thứ mọi người nên tránh,... Tuy nhiên thì trong một số trường hợp đặc thù thì nó lại có tác dụng như một phương án chữa cháy khẩn cấp trước khi code của developer có thể thay đổi.
Một số đặc điểm để các bạn nghĩ tới solution này nếu gặp vấn đề:
- Hệ thống gặp vấn đề với resource phụ, các bên thứ ba, hoặc các action không quan trọng làm ảnh hưởng tới action quan trọng,...
- Resource phụ phải tách biệt với resource chính.
- Có thể tách được việc sử dụng resource phụ ngay từ bước routing
Một lưu ý dành cho các bạn là đây chỉ là giải pháp tình thế cho thời kỳ quá độ lên microservice thôi. Đừng lạm dụng mà nghĩ đây là lời giải giúp ứng dụng monolith nặng nề của bạn bước vào kỷ nguyên mới nhé.
Chào thân ái và quyết thắng.
All rights reserved
