
Diffusion Models cơ bản - Phần 1
Diffusion Models đang dần phổ biến. Nhiều trường đại học và khóa học đã đưa Diffusion Models vào chương trình giảng dạy. Mình viết bài này với hy vọng bài viết này sẽ có ích phần nào với các bạn muốn tìm hiểu về Diffusion Models.
Một số từ tạm dịch
- Diffusion: khuếch tán
- Quasi-static process: quá trình chuẩn tĩnh
- Thermodynamic Equilibrium: cân bằng nhiệt động học (NĐH)
- Forward Diffusion Process: quá trình khuếch tán thuận
- Reverse Diffusion Process: quá trình đảo ngược
- Transition kernel: nhân biến đổi.
Lời mở đầu
Diffusion Models đứng sau một số sản phẩm đình đám trong lĩnh vực sinh ảnh. Ứng dụng của loại mô hình này đã được mở rộng sang Object Detection, Image Segmentation,... Danh sách này nhiều khả năng sẽ còn mở rộng hơn nữa. Bài viết này sẽ giới thiệu từ ý tưởng cơ bản, những khái niệm trong nhiệt động học đã truyền cảm hứng cho Diffusion Models trong học sâu. Sau đó, ta sẽ đi đến lý thuyết và cách huấn luyện Diffusion Models trong học sâu.
I. Từ Nhiệt động học
1. Diffusion là gì?
Diffusion (Khuếch tán) là hiện tượng chuyển động của các phân tử (hoặc ion, năng lượng...) từ vùng có mật độ cao hơn sang vùng có mật độ thấp hơn.

2. Cân bằng nhiệt động học là gì?
Một hệ (system) để được gọi là Cân bằng nhiệt động học cần đồng thời đạt được các điều kiện:
- Cân bằng về nhiệt
- Cân bằng cơ học
- Cân bằng hoá học
- Cân bằng pha
 Hình 2: Hai hệ gồm khí bên trong bình. Bên trái: hệ cân bằng nhiệt. Bên phải: hệ không cân bằng nhiệt.
Hình 2: Hai hệ gồm khí bên trong bình. Bên trái: hệ cân bằng nhiệt. Bên phải: hệ không cân bằng nhiệt.
Chúng ta không cần thiết phải hiểu về 4 yếu tố kể trên. Nhưng sẽ tốt hơn nếu chúng ta hình dung được những yếu tố này. Ví dụ, xét đến yếu tố đầu tiên là Cân bằng nhiệt. Một hệ được gọi là Cân bằng nhiệt nếu nhiệt độ tại mọi điểm của hệ là giống nhau. Hình 2 minh hoạ một hệ cân bằng nhiệt(bên trái) và một hệ không cân bằng nhiệt (bên phải). Ta có thể thấy ở hình bên trái nhiệt độ tại các điểm của hệ khá "giống" nhau, còn ở hình bên phải nhiệt độ ở các điểm là rất khác nhau.
3. Quasi-static process


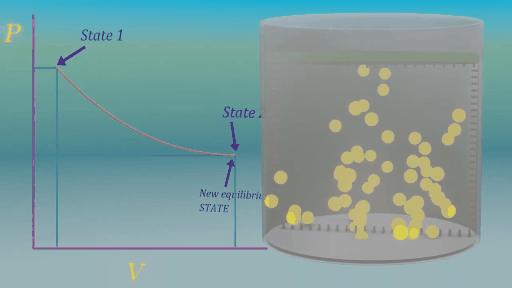
Như vậy ta đã biết một hệ cân bằng NĐH phải cân bằng về nhiều mặt. Xét một hệ cân bằng NĐH sử dụng các hạt đặt trên đỉnh pít tông để nén khí như trong hình 3. Giả sử ban đầu hệ có thể tích là là áp suất là . Mỗi cặp (, ) sẽ xác định một trạng thái.
Giả sử các hạt này là rất nhẹ và có rất nhiều hạt trên đỉnh pít tông. Nếu ta lấy ra một hạt trên đỉnh pít tông. Thể tích khí ở bên dưới sẽ nới rộng ra một chút là đạt được trạng thái cân bằng mới (, ). Lấy ta tiếp tục việc lấy ra dần từng hạt một cách chậm rãi ta sẽ thu được (, ), (, ), ...(, ). Với T là số lần lấy hạt ra, và các trạng thái (, ) đều cân bằng NĐH (). Quá trình chuyển từ trạng thái (, ) sang (, ) cực kỳ chậm như vậy là quasi-static và được minh họa ở hình 4.
Lý do người ta quan tâm đến quá trình quasi-static là tất cả Quá trình có thể đảo ngược (reversible process) đều là quá trình quasi-static. Nếu ta thêm lại dần dần các hạt đã lấy ra (từng chút từng chút một như lúc lấy ra) ta sẽ thu được các trạng thái trung gian. Trong điều kiện lý tưởng (các hạt vô cùng nhẹ, không có ma sát, thả không vận tốc ban đầu,...), các trạng thái trung gian sẽ chính là đảo ngược quá trình lấy ra (, ), (, ),...(, ), (, ). Quá trình đảo ngược này được minh hoạ trong hình 5.
II. Diffusion trong Deep Learning
Trong phần này chúng ta sẽ tìm hiểu cách ý tưởng Diffusion trong Deep Learning được triển khai.
1. Ý tưởng tổng quan
Ý tưởng cơ bản của Diffusion trong Deep Learning là phá hủy cấu trúc của dữ liệu một cách có hệ thống và cực kỳ chậm thông qua Quá trình khuếch tán thuận. Quá trình này có tính lặp lại và được minh họa ở hình 6. Sau đó chúng ta sẽ học cách để đảo ngược quá trình này. Quá trình đảo ngược được minh họa ở hình 7.
Cụ thể hơn, chúng ta sẽ định nghĩa quá trình khuếch tán thuận. Quá trình này chuyển phân phối phân phối dữ liệu (vốn phức tạp) sang một phân phối đơn giản và có thể dễ dàng làm việc (như lấy mẫu). Sau đó ta sẽ học cách để đảo ngược quá trình này. Nếu làm được điều này(thực tế là làm được), Quá trình đảo ngược sẽ được sử dụng để sinh dữ liệu. Trong hai quá trình này, chúng ta chỉ cần sử dụng mạng neural để học cách thực hiện quá trình đảo ngược. Quá trình thuận hoàn toàn được cố định (fully defined, fixed) trước hoặc chỉ cần học một số biến phụ. Trong bài viết này, chúng ta sẽ cố định hoàn toàn Quá trình thuận.


Hy vọng đến đây chúng ta đã hình dung được phần nào ý tưởng diffusion trong Deep Learning. Sau đây chúng ta sẽ đi vào tìm hiểu chi tiết của hai quá trình trên.
2. Quá trình khuếch tán thuận
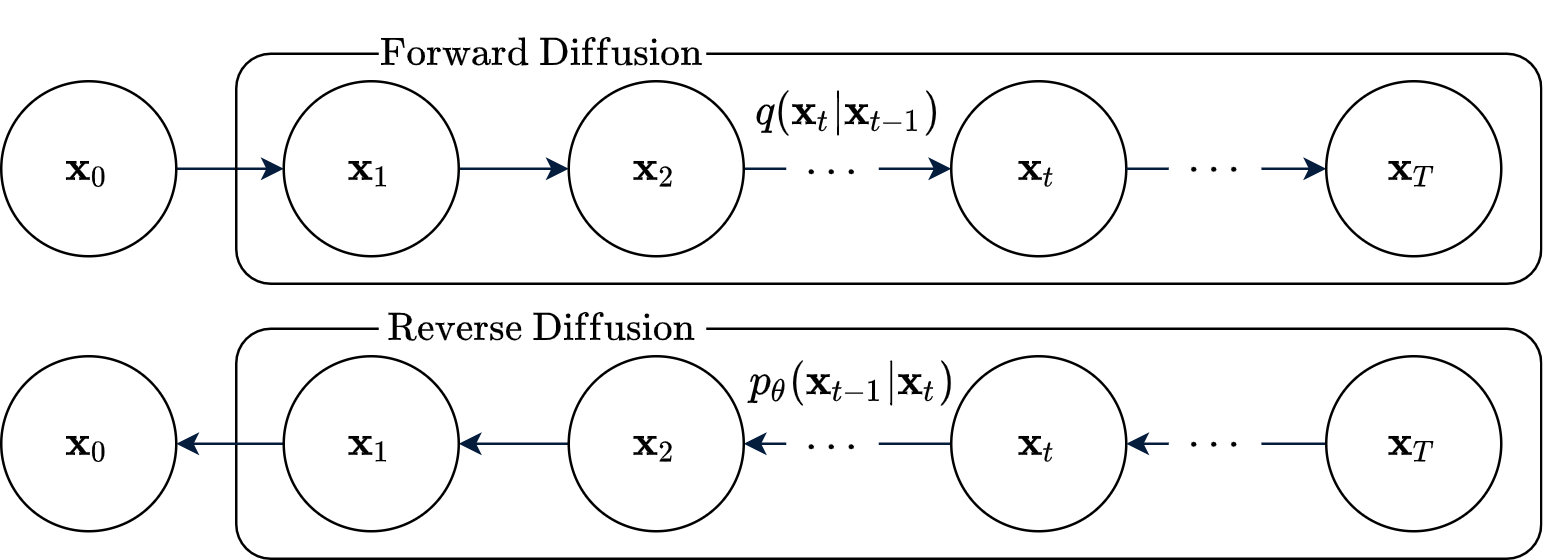
Quá trình thuận xuất phát từ phân phối của dữ liệu và chuyển đổi dần dần thành phân phối có thể dễ dàng lấy mẫu . Phân bố của được chọn trước là một prior.
Trong hình 8, ở quá trình thuận, là dữ liệu; là các biến ẩn (latent) có cùng số chiều với , T là số bước biến đổi. Quá trình khuếch tán được mô tả bằng một chuỗi Markov, nghĩa là trạng thái chỉ phụ thuộc vào . Nhân biến đổi (transition kernel) của chuỗi được chọn sao cho:
là tốc độ khuếch tán ở bước . Như vậy ta có thể tính dựa vào như sau:
Dựa vào công thức trên ta hoàn toàn có thể xác định được từ , và sau đó xác định được từ . Cứ như vậy tác sẽ tính được đến từ . Nếu ta đặt , và qua các phép biến đổi, ta có:
Đây là một tính chất quan trọng của quá trình thuận. Tính chất này trên cho phép ta lấy mẫu được ở một bước t bất kỳ một cách trực tiếp (mà không phải đi từ bước 0, 1, 2,... rồi mới đến t). Đồng thời, công thức trên cũng cho ta thấy rõ được quá trình biến đổi dần dần phân phối dữ liệu thành nhiễu đẳng hướng. Cụ thể, vì < 1 với mọi , nên khi tiến tới (ví dụ ), sẽ tiến tới và sẽ tiến tới . Phần biến đổi để thu được công thức trên các bạn có thể xem ở dưới đây:
Phân phối của quá trình thuận thu được bằng cách bắt đầu từ và áp dụng nhân biến đổi bên trên qua T bước là:
Như đã nói ở trên, quá trình khuếch tán thuận mà chúng ta lựa chọn đã hoàn toàn được cố định. Như vậy chúng ta cần chọn trước các giá trị , còn được gọi là lịch trình phương sai. Các giá trị này cần thoả mãn hai điều kiện:
- Tổng lượng nhiễu phải đủ lớn giúp chuyển phân phối dữ liệu trở thành nhiễu đẳng hướng Gaussian.
- Lượng nhiễu ở mỗi bước phải đủ nhỏ để có thể đảo ngược được. (Điều này tương tự như điều kiện để một quá trình là quasi-static ở phần I)
Giá trị của T phải được chọn trước. Để thoả mãn hai điều kiện trên thì T bắt buộc phải đủ lớn. T càng lớn thì ta có thể làm cho càng nhỏ. Để tóm tắt lại phần này mình xin trích lại slide của tác giả paper ở hình 9.

3. Quá trình đảo ngược
Quá trình đảo ngược cũng là một chuỗi Markov có những trạng thái như quá trình thuận nhưng theo chiều ngược lại, như được thể hiện ở hình 8. Quá trình đảo ngược còn được gọi quá trình sinh. Phân phối của quá trình sinh có được qua T bước áp dụng nhân biến đổi (tương tự quá trình thuận):
Với . Để đảo ngược được chúng ta chỉ cần xác định nhân biến đổi ngược và biến đổi T bước để thu được . Nếu nhỏ thì quá trình thuận và quá trình đảo ngược sẽ có cùng functional form. Vì nhân biến đổi thuận là Gaussian và đủ nhỏ, nên ta biết rằng nhân biến đổi nghịch cũng là một phân phối Gaussian. Còn mean và covariance của phân phối này thì chúng ta có thể sử dụng mạng neural để ước lượng. Ta có thể viết nhân biến đổi ngược dưới dạng tổng quát nhất như sau:
Chi phí tính toán của Diffusion Model chủ yếu đến từ chi phí tính toán của hai mô hình và . Để tóm tắt lại phần này, mình lại xin trích slide của tác giả ở hình 10.

Tips: hãy chú ý rằng các phân phối liên quan đến quá trình thuận là , với quá trình đảo ngược là
4. Hàm mục tiêu
Warning: Hãy sẵn sàng, đây là phần phức tạp nhất của Diffusion
4.1 Tối ưu likelihood
Việc huấn luyện được thực hiện bằng cách tối ưu chặn trên của Negative Log Likelihood:
Ta không thể tính toán hàm loss trên trực tiếp được vì không tính được hai phân phối thành phần trên. Do đó, ta cần biến đổi như sau để đưa về tính cách khoảng KL Divergence giữa các phân phối Gaussian (đó là lý do mà chúng ta phải thiết kế quá trình thuận thật cẩn thận để mọi thứ đều là Gaussian):
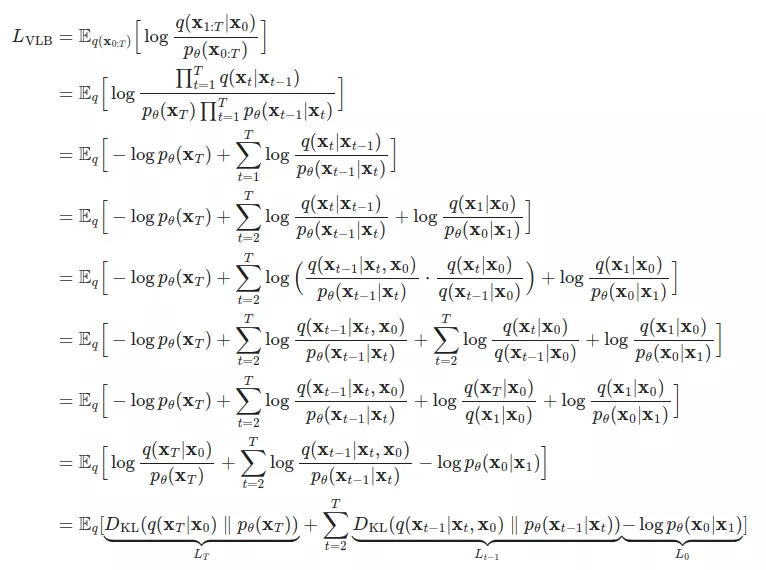
Hãy chú ý đến các thành phần ở dòng biến đổi cuối cùng. Ở các phần sau đây, chúng ta sẽ nói về từng thành phần này.
4.2 Thành phần
Xét 2 thành phần của KL divergence bên trên. Thành phần đầu tiên, chỉ phụ thuộc vào quá trình thuận và không chứa tham số tối ưu được. Thành phần thứ hai, được chọn trước là . Do đó, là hằng số trong quá trình huấn luyện và ta có thể bỏ qua thành phần này.
4.3 Thành phần
Nếu như các transition kernel với chiếu một không gian liên tục này sang không gian liên tục khác thì với nó cần chiếu một không gian liên tục về một không gian rời rạc (không gian của input).
Do sự khác biệt đó, thành phần cuối cùng của quá trình đảo ngược được tính theo cách riêng:
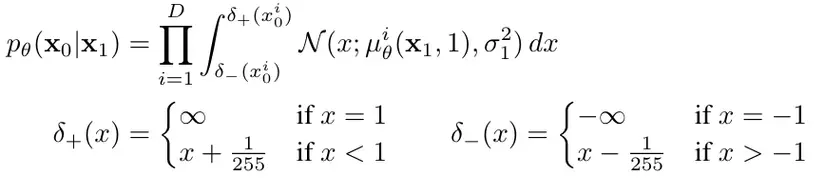
Trong đó, là chiều của dữ liệu, là chỉ số để lấy ra số chiều. Giả sử mỗi thành phần màu của ảnh đầu màu được chia vào 256 bin. Công thức trên tính xác suất rơi vào bin đúng. Xác suất này tính được sử dụng CDF của phân phối Gaussian.
Công thức trên chỉ áp dụng với dữ liệu ảnh đầu vào gồm những số integer được scale tuyến tính về .
Code Pytorch tính thành phần này các bạn có thể xem ở đây
4.4 Thành phần
là tổng của các KL divergence giữa và . Hai thành phần này đóng vai trò tương ứng là target và prediction trong quá trình training. Như đã nói ở trên với đủ nhỏ, là phân bố Gaussian. Cho dù vậy, chúng ta không thể dễ dàng ước lượng được phân phối này vì nó yêu cầu sử dụng cả tập dữ liệu. Tuy nhiên chúng ta có thể xác định được phân phối này khi đặt điều kiện trên bằng cách áp dụng quy tắc Bayes. Ta có . Cả ba thành phần để tính lúc này để thuộc quá trình thuận và có thể xác định được dễ dàng. Qua các phép biến đổi ta có thể viết lại như sau:
Chi tiết phần biến đổi để ra được công thức trên các bạn có thể xem thêm ở đây.
Để tối ưu thành phần chính ,chúng ta cần sử dụng một mạng neural để ước lượng . Tổng quát nhất, . Thực nghiệm cho thấy việc học không cải thiện chất lượng sinh sample nên chúng ta cố định
Áp dụng công thức tính KL Divergence cho 2 phân bố Gaussian ta có
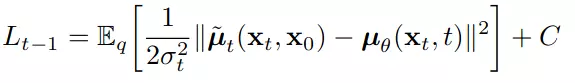
Trong đó C là hằng số. Nhìn vào công thức trên, chúng ta thấy rằng cách trực tiếp nhất là xây dựng mô hình dự đoán . Tuy nhiên, các thành phần của đều đã biết trước chỉ trừ . Nên thay vào đó ta có thể xây dựng mô hình dự đoán , rồi sau đó gián tiếp dự đoán . Ta chọn cách tham số hóa như sau:
Thay khai triển của và , ta có trở thành:
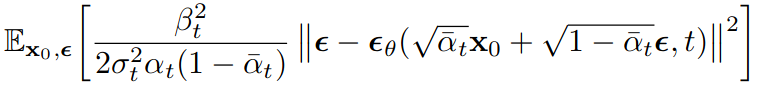
4.5 Đơn giản hóa hàm mục tiêu
Tổng kết lại các phần trên:
Vì là hằng số nên hàm tối ưu của chúng ta chỉ gồm 2 thành phần là và . Tuy nhiên, thực nghiệm cho thấy rằng việc huấn luyện mô hình theo hàm mục tiêu được đơn giản hóa như sau cho kết quả tốt hơn:
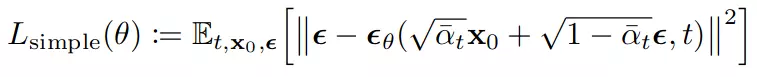
trong đó t là phân bố đều giữa 1 và T. Trường hợp tương ứng với , giá trị của tích phân được xấp xỉ bằng khai triển Taylor của hàm mật độ xác suất Gaussian. Với t > 1, tương ứng với phiên bản không trọng số(hay có thể coi là đánh trọng số lại) của .
Việc chọn hàm đơn giản như trên cho kết quả tốt hơn có thể được giải thích là do nó làm giảm ảnh hưởng khi giá trị nhỏ. Giá trị của nhỏ tương ứng với ảnh ít nhiễu. Từ đó, giúp mô hình tập trung hơn vào việc học dự đoán nhiễu khi lớn. Vì khi lớn thì lượng nhiễu trong ảnh cũng lớn nên khó để dự đoán hơn.
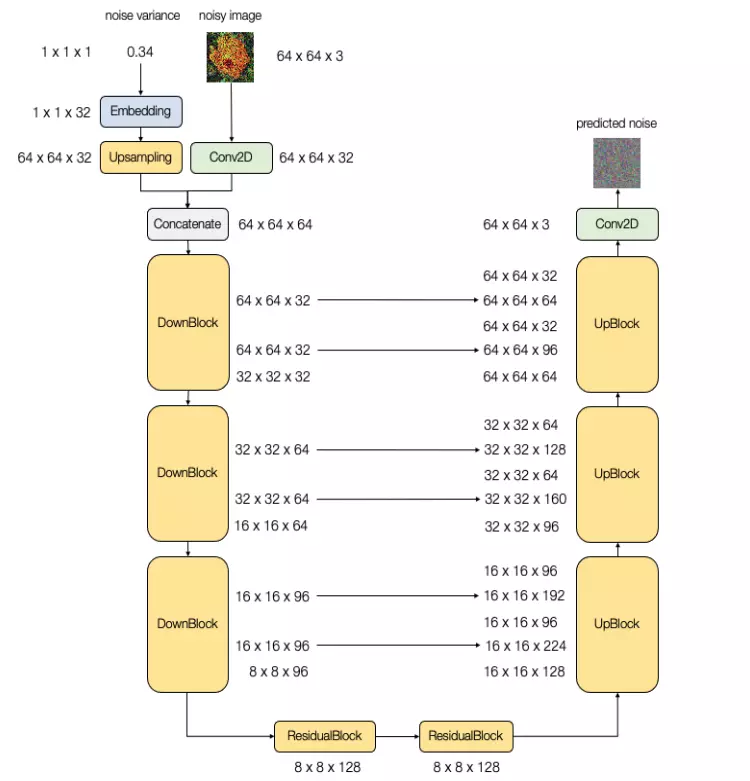
5. Kiến trúc mô hình
Kiến trúc mô hình sử dụng trong Diffusion Models cần có chiều của đầu ra phải giống với chiều của đầu vào. Do đó, các mạng tương tự U-Net thường được sử dụng. Những mô hình này có một vài thay đổi so với thông thường để thông tin làm một đầu vào.
Thông tin về thời gian cũng có thể được đại diện bằng noise variance. Chúng sẽ được biến đổi bằng Sinusoidal Embedding trước khi đưa vào U-Net. Ý tưởng phía sau là biến đổi một giá trị scalar về vector nhiều chiều hơn để tạo ra một biểu diễn phức tạp hơn.
Hai hình dưới đây minh họa một ví dụ về kiến trúc U-Net sử dụng trong Diffusion Models và giá trị của embeddings khi đưa vào.
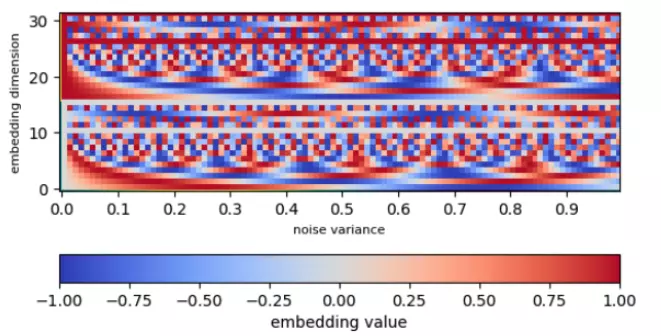
6. Sinh ảnh (sẽ cập nhật thêm sau)
Sau khi có được mô hình để dự đoán . Ta có thể dễ dàng sinh dữ liệu mới theo các bước sau:

Hints: dòng thứ 4 là do
Tra cứu (sẽ cập nhật thêm sau)
Phần cuối cũng bài viết cung cấp mục tra cứu và giải thích các ký hiệu phổ biến được sử dụng.
| Ký hiệu | Ý nghĩa | Ví dụ |
|---|---|---|
| số timestep tối đa | ||
| phương sai của nhiễu thêm được vào ở timestep sang | và (linspace) | |
| phương sai của tổng lượng nhiễu ở timestep | 1e-05 và = 0.999957 |
Lời kết
Trong bài này mình đã trình bày cơ bản về Diffusion Models. Phần mối liên giữa Khuếch tán trong Nhiệt động học và trong Học sâu mình không trình bày cụ thể mà để mở để các bạn có sự liên hệ, tưởng tượng riêng của mình. Hy vọng các bạn thấy bài viết này hữu ích. Nếu có vấn đề hay thắc mình gì đừng ngại cho mình biết ở phần comment để mình cải thiện ở các phần sau nhé. Cảm ơn các bạn đã đọc bài. Hẹn gặp lại ở bài viết sau về chủ đề Diffusion Models.
Toàn bộ credit thuộc về các nguồn tài liệu tham khảo. Mình recommend các bạn đọc tài liệu số 6.
Tài liệu tham khảo
- [1] [2015 ICML] Deep Unsupervised Learning using Nonequilibrium Thermodynamics
- [2] Deep Unsupervised Learning using Nonequilibrium Thermodynamics
- [3] Denoising Diffusion Probabilistic Models
- [4] Quasi-Equilibrium and Thermodynamic Equilibrium
- [5] Quasi-static process
- [6] What are Diffusion Models?
- [7] Paper reading DDPM
- [8] Improved Denoising Diffusion Probabilistic Models
- [9] Generative Deep Learning
All rights reserved
