Deep Neural Networks
Trong bài thứ tư này, chúng ta sẽ tìm hiểu về Deep neural networks. Từ này đã trở lên thông dụng ngày nay trong ngành công nghiệp và lĩnh vực nghiên cứu.
Mục tiêu của bài viết này :
- Xem deep neural networks khi các lớp kết nối với nhau.
- Xây dựng và huấn luyện một mạng thần kinh sâu có L lớp
- Phân tích kích thước ma trận và vectơ để kiểm tra việc triển khai mạng thần kinh
- Hiểu cách sử dụng bộ đệm để truyền thông tin từ forward propagation sang backward propagation
- Hiểu vai trò của hyperparameters trong Deep learning
Notation:
- Ký hiệu chữ cái in hoa A, Z, W, B là các ma trận
- Ký hiệu các chữ cái thường a, z, w, b là các vector kích thước (x,1)
- Ký hiệu đại diện cho lớp thứ .
- L là số lớp của mạng lưới thần kinh
- là số unit trong lớp thứ
- là layer's activations với g ở đây là các hàm kích hoạt như sigmod(), relu(), ...
- và là các thông số của lớp (layer parametes).
- Ký hiệu đại diện cho example.
- VÍ dụ: là thí dụ thứ của tập training.
- Ký hiệu chữ thường đại diện cho ví trí thứ của 1 vector
- Ví dụ: dại diện cho ví trí của layer's activations.
Đây là các ký hiệu mà chúng ta sẽ dùng trong cả bài này. Hãy ghi nhớ chúng để bắt đầu bài đọc, hoặc bạn có thể nhanh chóng kéo lên đầu trang để xem trong trường học bạn quên.
Deep L-Layer Neural Network
Trong phần này, chúng ta sẽ xem xét làm sao các khái niệm forward và backpropogation có thể được áp dụng trong deep neural networks. Shallow và deep là một vấn đề về mức độ. Như ta đã học từ bài trước thì Logistic regression là một mô hình rất nông nó chỉ có 1 layer, (nhớ rằng chúng ta không tính đầu vào của 1 lớp).
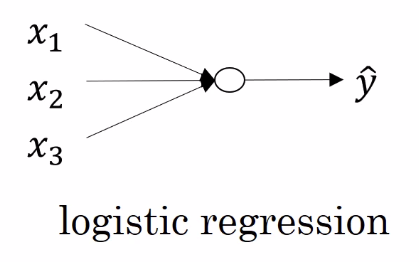
Một Deep Neural Network có số lượng lớp ấn nhiều hơn.
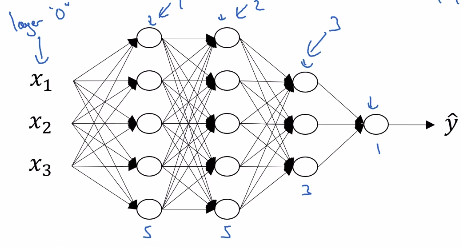
Với mạng thân trên, ta thấy các điểm như sau:
- Có layer
- Số unit của các layer lần lượt là , , ,
Forward Propagation in a Deep Network
Đâu tiên chúng ta nhìn vào Forward Propagation của mạng lưới thần kinh trên với 1 dữ liệu đào tạo duy nhất. Ta có:
Tổng quát hóa với trường hợp có layer :
Chúng ta có thể vectorize các bước này khi có m dữ liệu đào tạo như sau:
Getting your matrix dimensions right
Phân tích kích thước của ma trận là một trong những công cụ gỡ lỗi tốt nhất để kiểm tra mức độ chính xác của code của chúng ta. Chúng ta sẽ thảo luận về những gì nên là kích thước chính xác cho mỗi ma trận trong phần này. Hãy xem xét ví dụ sau:

Mạng lưới thần kinh trên có số layer L = 5 với 4 hidden layer và 1 output layer. Số unit trong mỗi layer được thể hiện trên hình vẽ.
Ta phân tích kích thước của . Khi có 1 dữ liệu đào tạo.
- Kích thước của hay
- Kích thước của hay
- Kích thước của hay
- Do đó, kích thước của hay
Suy ra dạng tổng quát của và các dẫn suất của chúng khi có m training example:
- trong đó L là hàm loss function.
- Kích thước của
Đây là một số kích thước ma trận tổng quát sẽ giúp code của bạn chạy một cách trơn tru. Chúng ta đã thấy một số điều cơ bản của deep neural networks cho đến thời điểm này. Nhưng tại sao chúng ta cần đại diện sâu sắc ngay từ đầu? Tại sao làm cho mọi thứ phức tạp khi giải pháp dễ dàng hơn tồn tại? Hãy cùng tìm hiểu!
Why Deep Representations?
Trong các mạng lưới thần kinh sâu, chúng ta có một số lượng lớn các lớp ẩn. Những lớp ẩn này thực sự đang làm gì? Để hiểu điều này, hãy xem xét hình ảnh dưới đây:

Mạng lưới thần kinh sâu tìm mối quan hệ với dữ liệu (quan hệ đơn giản đến phức tạp). Lớp ẩn đầu tiên có thể đang làm gì, đang cố gắng tìm các hàm đơn giản như xác định các cạnh trong ảnh trên. Và khi chúng ta đi sâu hơn vào mạng, các chức năng đơn giản này kết hợp với nhau để tạo thành các chức năng phức tạp hơn như nhận diện khuôn mặt. Một số ví dụ phổ biến về việc tận dụng **deep neural network ** là:
- Nhận dạng khuôn mặt
- Image ==> Edges ==> Face parts ==> Faces ==> desired face
- Nhận dạng âm thanh:
- Audio ==> Low level sound features like (sss, bb) ==> Phonemes ==> Words ==> Sentences
Building Blocks of a Deep Neural Network
Ta xem xét bất kỳ lớp trong Deep Neural Network, đầu vào của lớp này là các activation từ lớp trước (l-1) và đầu ra của lớp này là các activations của chinh lớp nó.
- Input:
- Output:
Lớp này trước tiên tính dựa trên được truyền vào . này được lưu dưới dạng cache, trong cache này cũng lưu để về sau còn cập nhật các tham số. Đối với backward propagation, trước tiên, nó sẽ tính , nghĩa là đạo hàm activation ở lớp , đạo hàm của trọng số , và cuối cùng là . Các bạn hãy hình dùng các bước như sau:
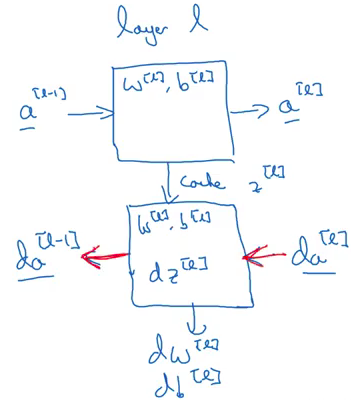
Đay là cách mỗi khối hay lớp trong Deep Neural Network. Bây giờ ta sẽ xem cách thức hiện của Forward and Backward Propagation trong từng khối như thế nào.
Forward and Backward Propagation
Forward Propagation for layer :
- Input:
- Output: trong đó là một hàm của
Với 1 dữ liệu đạo tạo thì ta tính như sau:
Vectorized với m dữ liệu đào tạo ta được:
với .
Chúng ta sẽ tính và cho mỗi lớp của mạng. Sau khi tính toán các activations, bước tiếp theo là backward propagation (lan truyền ngược), trong đó chúng tôi cập nhật các trọng số bằng cách sử dụng gradient descent như mình đã trình bày ở các bài trước.
Backward propagation for layer
- Input:
- Ouput:
Với 1 dữ liệu đạo tạo thì ta tính như sau:
Vectorized với m dữ liệu đào tạo ta được:
Với ở đây là hàm loss fuction và cost function
Với lập trình thì ta có thể viết của thể tính dW, db, dA_prev như sau:
dW = 1/m * np.dot(dZ, A_prev.T)
db = 1/m * np.sum(dZ, axis = 1, keepdims = True)
dA_prev = np.dot(W.T, dZ)
Update Parameters
Sau khi Backward propagation, thì ta sẽ cập nhật tham số như sau, với là learning rate ta tự khởi tạo.
Đây là cách chúng ta thực hiện deep neural networks..
Deep neural networks. hoạt động tốt đáng ngạc nhiên (có thể không quá ngạc nhiên nếu bạn đã sử dụng chúng trước đó!). Chỉ chạy một vài dòng mã cho chúng ta kết quả khả quan. Điều này là do chúng tôi đang cung cấp một lượng lớn dữ liệu cho mạng và nó đang học hỏi từ dữ liệu đó bằng cách sử dụng các lớp ẩn.
Chọn đúng hyperparameters giúp chúng ta làm cho mô hình của mình hiệu quả hơn. Mình sẽ đề cập chi tiết về điều chỉnh siêu tham số trong bài viết tiếp theo của loạt bài này.
Parameters vs Hyperparameters
Đây là một câu hỏi thường gặp của những người mới học Deep learning. Sự khác biệt chính giữa Parameters vs Hyperparameters là các Parameters được mô hình học trong thời gian đào tạo, trong khi Hyperparameters có thể được thay đổi trước khi đào tạo mô hình và ta phải tự chọn qua kinh ngiệm.
Các Parameters của mạng nơ ron sâu là và , mô hình cập nhật trong bước Backward propagation. Mặt khác, có rất nhiều Hyperparameters cho một deep NN,, bao gồm:
- Learning rate
- Number of iterations
- Number of hidden layers
- Units in each hidden layer
- Chọn activation function
Đây là một tổng quan ngắn gọn về sự khác biệt giữa hai khía cạnh này. Bạn có thể tham khảo bài viết của anh Toàn phần thứ 7 để biết thêm chi tiết.
References
- Tuần 4 khóa học Neural Networks and Deep Learning trên coursera.
- Video trên yotube về tuần 4, có Translate, rất dễ cho những bạn mới học như mình
 , với mỗi phần trong bài viết của mình trùng tên với video link
, với mỗi phần trong bài viết của mình trùng tên với video link - Một video trực quan khác về cách net work học, mọi người có thể tham khảo: Watching Neural Networks Learn
TL,DR
Đến đây đã hoàn thành khóa học đầu tiên Neural Networks and Deep Learning (Course 1 of the Deep Learning Specialization) Bây giờ chúng ta biết làm thế nào để thực hiện forward and backward propagation and gradient descent cho các deep neural networks. Chúng ta cũng đã thấy làm thế nào vectorization giúp chúng ta thoát khỏi các vòng lặp rõ ràng, làm cho code của chúng ta hiệu quả trong quá trình.
Chắc 1 số bài viết tới mình sẽ giới thiệu các nền tảng để lập trình bao gồm python, numpy, panda, matplot, sau đó mình sẽ hướng dẫn làm lại bài thực hành tuần 4 trên khóa học để các bạn có cái nhìn rõ nét hơn cách code các phần ở trên từng bước một, để các bạn về sau khi làm quen với các thư viện có sẵn như Tensorflow, keras, pytorch,.. sẽ hiểu bên dưới chúng thực hiện những gì và để mình cũng nhớ lâu hơn . Rất mong được sự ủng hộ của các bạn.
Trong phần tiếp theo (sẽ bao gồm khóa 2) sẽ 1 thời dài sau, chúng ta sẽ xem làm thế nào chúng ta có thể cải thiện mạng lưới thần kinh sâu bằng cách điều chỉnh hyperparameter, regularization và optimization. Đó là một trong những khía cạnh khó khăn và hấp dẫn hơn của deep learning.
All rights reserved
