Database connection pooling: Tổng quan và implement benchmark
Bài đăng này đã không được cập nhật trong 2 năm
Một nhà thông thái nào đó đã nói: “Muốn lên trình backend, thì database là một phần không thể bỏ qua”.
Vâng, trong series backend nâng cao này, mình muốn tiếp tục bằng tối ưu hiệu năng database, phần đầu tiên sẽ là connection pooling. Vậy connection pooling là gì? Sử dụng connection pool như thế nào? Hãy tham khảo bài viết này nha.
First things first
Again, mình là Kiên, một anh dev với tay nghề khá thập cẩm, series backend nâng cao này chính là một trong những nỗ lực của mình để đào sâu kĩ năng backend. Hi vọng sẽ có ích với các bạn, và cả mình nữa 🤗.
Database connection
Nếu theo dõi series này từ đầu, bạn sẽ biết về TCP handshake, mà chưa thì bạn có thể đọc lại để nắm về nó. Và hiển nhiên, các database dạng RDBMS như MSSQL, MySQL, Postgresql đều support protocol giao tiếp qua TCP/IP như một tiêu chuẩn, đặc biệt nếu bạn kết nối tới các database từ xa, và phải thêm SSL/TLS để bảo mật connection.
Đây là diagram mô phỏng cho session của một kết nối database postgres:
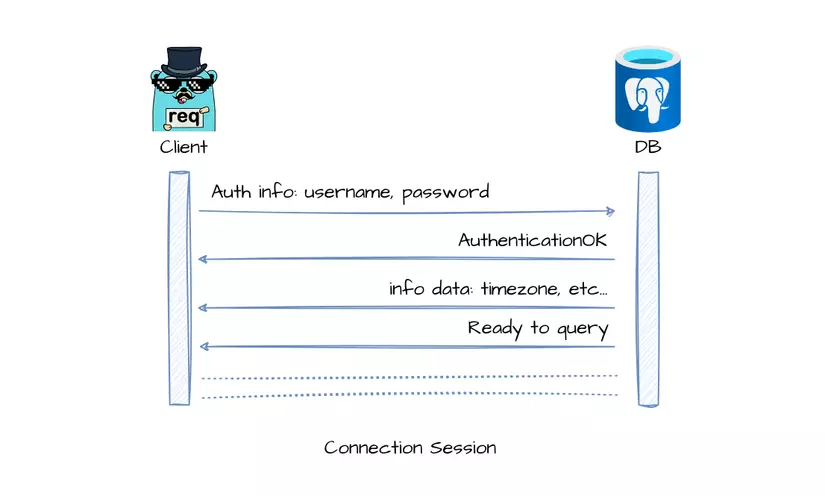
Do đó, nếu mỗi lần có request, nếu application phải tạo mới 1 connection tới DB, thì sẽ phải thực hiện handshake lại, việc này sẽ rất tốn resource và làm chậm app đi. Vì vậy connection pooling ra đời.
Connection pool là gì?
Thực chất, connection pool là một implementation của design pattern Object Pool. Khá giống với singleton, đây là một pattern được tạo ra với mục đích để có thể sử dụng lại được các object mà chúng ta mong muốn.
Dĩ nhiên với những thao tác đắt đỏ như thiết lập 1 kết nối mới tới DB thì pattern này lại quá ư là hợp lý.
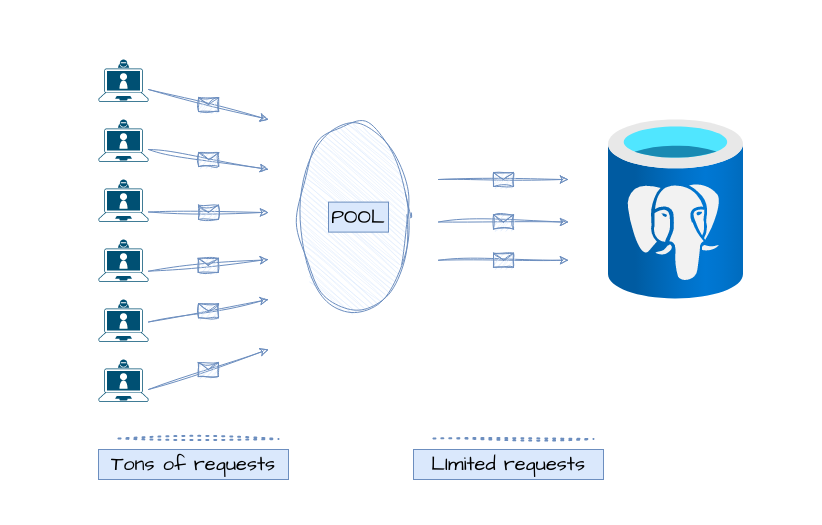
Giống như việc chở khách qua sông ở bến đò, có rất nhiều thuyền, nhưng để mặc con thuyền quá lâu dưới nước sẽ làm mục gỗ nhanh hơn. Nên thuyền được cất vào kho.
Mỗi lần chở người qua là phải: Bê 1 chiếc thuyền từ kho bên bờ sông xuống, chở người qua bên kia bờ, rồi chạy về, đưa thuyền đi cất => tốn thời gian.
Trong khi đó chúng ta sẽ đặt tối đa khoảng 100 chiếc thuyền neo đậu bên cạnh sông khi không có khách, mỗi thuyền sẽ được dừng nghỉ 1 buổi, hết buổi không có khách ngồi thuyền đó thì mới đưa cất đi.
Nửa phút quảng cáo
Gần đây mình mới mua 1 cuốn sách mang tên “Làm chủ các mẫu thiết kế kinh điển trong lập trình” của anh Tạ Văn Dũng, một người anh senior rất tâm huyết với nghề, cũng như rất nhiệt tình trong việc giúp đỡ và giải đáp thắc mắc cho junior đi sau (trong đó có mình).
Anh là founder của tổ chức mã nguồn mở YoungMonkeys - github, có khá là nhiều thư viện và framework đã được team implement sẵn, đặc biệt đối với các startup làm về game.
Các bạn có thể tìm thấy pattern Object Pool này ở trang số 86:

Các bạn có thể tham khảo mua sách ở đây, mình không nhận đồng PR nào cả, mình chỉ muốn ủng hộ anh Dũng thôi, vì phần lớn lợi nhuận của sách này đều được tác giả gửi tặng chương trình cặp lá yêu thương, peace!
Connection pooling trong database
Ahh hhh hmmm, chúng ta quay lại bài giảng.
Database - cơ sở dữ liệu cũng là một phần mềm, cũng nằm trên máy chủ vật lý, mà đã thế thì nó cũng sẽ có giới hạn về số lượng kết nối trong cùng 1 thời điểm.
Con số mặc định cho số lượng connection tối đa của MySQL là 151.
Với Postgresql thì sẽ là 100.
MSSQL thì kinh dị hơn với con số …. 32.767. (Chắc do tốn tiền nên vậy 😂)
Trong khuôn khổ bài này mình sẽ chỉ tập trung đào sâu với Postgresql.
Cách implement connection pooling
Về cơ bản chúng ta có 2 cách để implement connection pooling.
- Cách đầu tiên là cài các phần mềm, extension thêm vào, chẳng hạn như pgbouncer.
- Cách thứ 2, chính là implement connection pooling phía layer backend.
Chúng ta có thể implement 1 pooler cách đơn giản bằng cách sử dụng 1 Queue/ Stack và 1 mutex Lock, vì nó là design pattern mà, dĩ nhiên. Tham khảo tutorial của Microsoft Java sample to illustrate connection pooling.
Trên thực tế thì chúng ta chẳng đi re-invent the wheel làm gì, các thư viện hiện tại đã hỗ trợ sẵn rồi, chỉ việc dùng thôi. Xem phần tiếp dưới đây:
Benchmark connection pooling
Tiết học lí thuyết đã xong, chúng ta chuyển qua tiết thực hành nhé.
Đầu tiên để minh chứng rằng connection pooling thực sự boost performance, mình có ý tưởng như sau:
Tạo một API đơn giản với 3 endpoint, với 3 phương pháp sử dụng database connection khác nhau:
- Khởi tạo 1 connection mới cho mọi request.
- Khởi tạo 1 connection từ đầu và dùng nó cho mọi request (singleton).
- Khởi tạo 1 connection pool với số lượng idle connection cao.
Sau đó sẽ test 3 endpoint này bằng cả browser và tool benchmark tấn công dồn dập 👻.
Đầu tiên là cấu hình máy mình:
➜ ~ neofetch
Máy Kiên Đẹp Trai
-----------------
OS: Ubuntu 22.10 x86_64
Host: Latitude 5420
Kernel: 5.19.0-38-generic
CPU: 11th Gen Intel i7-1185G7 (8) @ 4.800GHz
GPU: Intel TigerLake-LP GT2 [Iris Xe Graphics]
Memory: 8862MiB / 31491MiB
Một vài khái niệm
Chúng ta làm quen trước vài khái niệm của connection pooling:
- Pool size: Kích thước của connection pool, dĩ nhiên không được vượt quá số lượng kết nối tối đa của DB rồi.
- Idle connection: Các connection “tạm nghỉ”, khi được sử dụng xong thì các idle connection không được release luôn, mà được ở lại trạng thái này.
- Connection lifetime: Đại loại là thời gian mà các connection "live", đạt ngưỡng này thì force close connection.
💡 Không có gì chắc chắn rằng các “idle connection” sẽ luôn luôn sống và không cần phải handshake lại với DB vì các lí do như timeout (thời gian đã set) hoặc do phía DB. Do đó có thể vài thư viện thực hiện cơ chế ping liên tục bằng các idle connection để giữ tụi nó luôn luôn không bị close. Dĩ nhiên thì làm vậy sẽ tốn resource hơn để quản lý.
Dựng database postgres và data
Tí nữa mình sẽ để repo benchmark ở cuối bài viết cho nên code mẫu mình trình bày sẽ đại khái dưới dạng pseudo.
Bạn nào tò mò muốn thử có thể clone về thử, nhưng mình vẫn sẽ hướng dẫn từng bước mình làm cái benchmark này nhé.
Để chuẩn bị data cho bài test thì mình tạo 1 table products như sau:
CREATE TABLE IF NOT EXISTS products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
price NUMERIC(10, 2) NOT NULL,
description TEXT
);
Sau đó lên mockaroo để tạo 1000 dòng data:
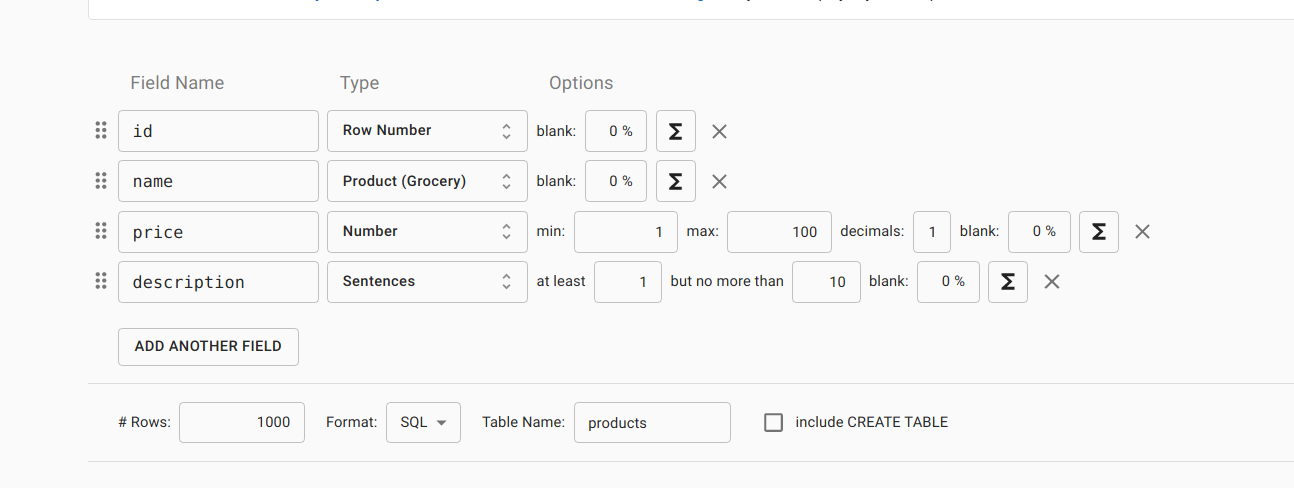
Sau khi download về, mình có copy paste lại 1000 dòng thành hơn mấy chục nghìn dòng dữ liệu.
Để tạo 1 database postgres trên máy, cách nhanh nhất là mình dùng docker:
version: "3.9"
services:
postgres:
image: postgres:13.1-alpine
container_name: postgres_container
volumes:
- ./seed.sql:/docker-entrypoint-initdb.d/seed.sql
- ./data/postgres:/var/lib/postgresql/data
environment:
- POSTGRES_DB=${POSTGRES_DB:-postgres}
- POSTGRES_USER=${POSTGRES_USER:-postgres}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD:-password1}
ports:
- "5433:5432"
restart: unless-stopped
Theo kế hoạch thì những bài tiếp theo của series này, mình sẽ nói về docker, nếu bạn chưa hiểu docker là gì, thì đón đọc những bài tiếp theo nhé. Phần hiện tại bạn chỉ cần biết nó là công cụ để mình tạo 1 database postgres là được.
Okay, chạy dòng lệnh docker compose up -d để có 1 database có sẵn data. DB này có port 5433, username và password như file yaml. (Chọn port 5433 tại vì sợ nó conflict với DB có sẵn trên máy mình thôi)
Chuyển qua phần tiếp theo
Dựng API bằng Go
Mình đang code Go, cho nên mình sẽ chọn Go để làm API cho ví dụ benchmark (sử dụng Gin framework, 1 framework nhẹ và mạnh mẽ).
Tương tự với DDL products bên trên, mình có model Product:
type Product struct {
ID int `json:"id"`
Name string `json:"name"`
Price float64 `json:"price"`
Description string `json:"description"`
}
Tương tự tạo 1 model response của API, có chứa thêm 2 field để mình estimate thời gian của request:
type Response struct {
Elapsed int64 `json:"elapsed"`
Average float64 `json:"average"`
Products []*Product `json:"products"`
}
Kế tiếp, khai báo query để select 1000 product từ DB cũng như connection string cho DB.
Sau đó nữa, tạo 1 connection Pool, 1 singleton connection để dùng cho 3 endpoint như idea mình đã nêu phía trên:
var dsn = "postgres://postgres:password1@localhost:5433/postgres?sslmode=disable"
var query = "SELECT id, name, price, description FROM products limit 1000"
func main() {
// Postgres allows 100 connections in default
// Set the maximum number of idle connections in the pool
idleConn := 50
// Set the maximum number of connections in the pool
maxConnections := 90
// Set the maximum amount of time a connection can be reused
maxConnLifetime := 2 * time.Minute
poolConn, err := sqlx.Open("postgres", dsn)
if err != nil {
log.Fatalf("Unable to connect to database: %v\n", err)
}
defer poolConn.Close()
poolConn.SetMaxOpenConns(maxConnections)
poolConn.SetMaxIdleConns(idleConn)
poolConn.SetConnMaxLifetime(maxConnLifetime)
// normal connection
conn, err := sqlx.Open("postgres", dsn)
if err != nil {
log.Fatalf("Unable to connect to database: %v\n", err)
}
// default will be 2 idle connections
// so set it to 1 to simulate
conn.SetMaxIdleConns(1)
// Initialize the HTTP router
router := gin.Default()
router.StaticFile("/", "./index.html")
// Handlers...
// Start the HTTP server
if err := router.Run(":8080"); err != nil {
log.Fatalf("Unable to start HTTP server: %v\n", err)
}
}
Ở đây mình chọn thư viện sqlx, thư viện này nếu chúng ta tạo 1 connection singleton, thì mặc định nó đã bật chế độ connection pool rồi, do đó mình set số lượng về 1 để giả lập tình trạng không có pool ở các ngôn ngữ và thư viện khác.
Về phần pool, mình cài đặt pool size là 90, và số lượng idle connection là 50, một con số khá lớn, và lifetime là 2 phút.
Rồi, chúng ta thêm 3 endpoint với method GET:
products/pooled: Sử dụng connection pool.products/normal: Sử dụng một singleton connection cho toàn bộ request.products/new: Thành lập 1 kết nối mới cho mọi request.
Bạn có thể thấy, behavior của 3 endpoint này giống nhau hoàn toàn, trừ việc sử dụng connection tới database thôi.
router.GET("/products/normal", func(c *gin.Context) {
startTime := time.Now()
// Query the database for all products
rows, err := conn.Query(query)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
products, err := scanProducts(rows)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
elapsed := time.Since(startTime).Microseconds()
allCount++
allTime += elapsed
c.JSON(http.StatusOK, model.Response{Elapsed: elapsed, Average: float64(allTime / allCount), Products: products})
})
router.GET("/products/pooled", func(c *gin.Context) {
startTime := time.Now()
// Query the database for all products
rows, err := poolConn.Query(query)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
products, err := scanProducts(rows)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
elapsed := time.Since(startTime).Microseconds()
poolCount++
poolTime += elapsed
c.JSON(http.StatusOK, model.Response{Elapsed: elapsed, Average: float64(poolTime / poolCount), Products: products})
})
router.GET("/products/new", func(c *gin.Context) {
startTime := time.Now()
conn, err := sqlx.Open("postgres", dsn)
if err != nil {
log.Fatalf("Unable to connect to database: %v\n", err)
}
rows, err := conn.Query(query)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
products, err := scanProducts(rows)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
elapsed := time.Since(startTime).Microseconds()
newCount++
newTime += elapsed
c.JSON(http.StatusOK, model.Response{Elapsed: elapsed, Average: float64(newTime / newCount), Products: products})
})
Xong phía backend, qua code chút HTML để test phía browser nào:
<body>
<button onclick="getProducts('normal')">Get Products</button>
<button onclick="getProducts('new')">Get Products | New</button>
<button onclick="getProducts('pooled')">
Get Products | Connection Pool
</button>
<script>
function getProducts(mode) {
let lastResult = null;
const promises = [];
for (let i = 0; i < 200; i++) {
promises.push(
fetch(`/products/${mode}`)
.then((response) => response.json())
.then(({ elapsed, average, products }) => {
lastResult = { elapsed, average };
console.log({ elapsed, average });
})
);
}
Promise.all(promises)
.then(() => {
console.log(`Last result for ${mode}:`, lastResult);
})
.catch((error) => console.error(error));
}
</script>
</body>
Code này rất đơn giản, với mỗi lần nhấn button, thì mình sẽ dùng promise chạy bất đồng bộ 200 request tới endpoint tương ứng.
Kết quả test benchmark
Bấm chạy chương trình, và chúng ta có 3 button với response của mỗi request có 1000 product, response nặng khoảng 86.53 KB.
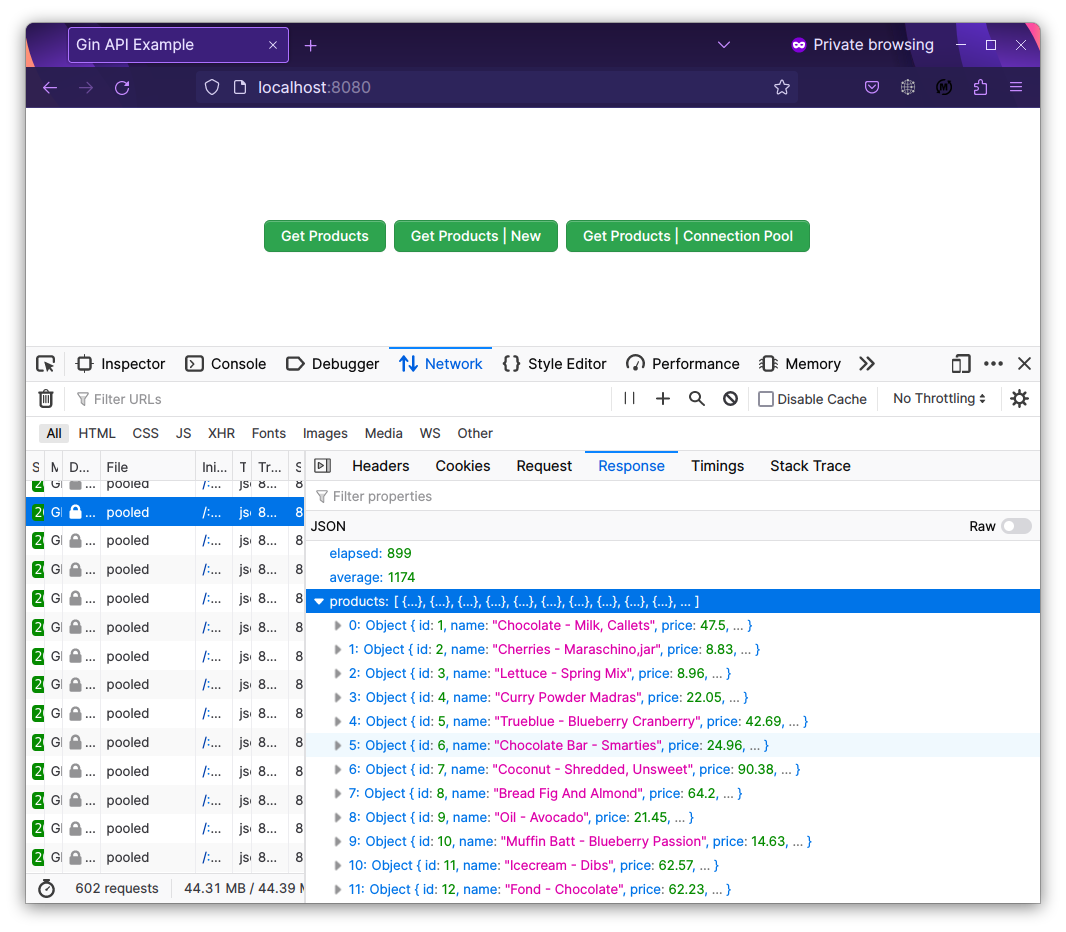
Để duy trì tính ổn định cho bài test, mỗi lần chạy benchmark 1 endpoint, mình sẽ restart app để app reset lại connection pool.
Đầu tiên chúng ta thử với endpoint /products/new , nơi mà connection sẽ được tạo mới lại 200 lần, sau khi bấm nút, thì sau chưa tới 100 request đã bị lỗi:
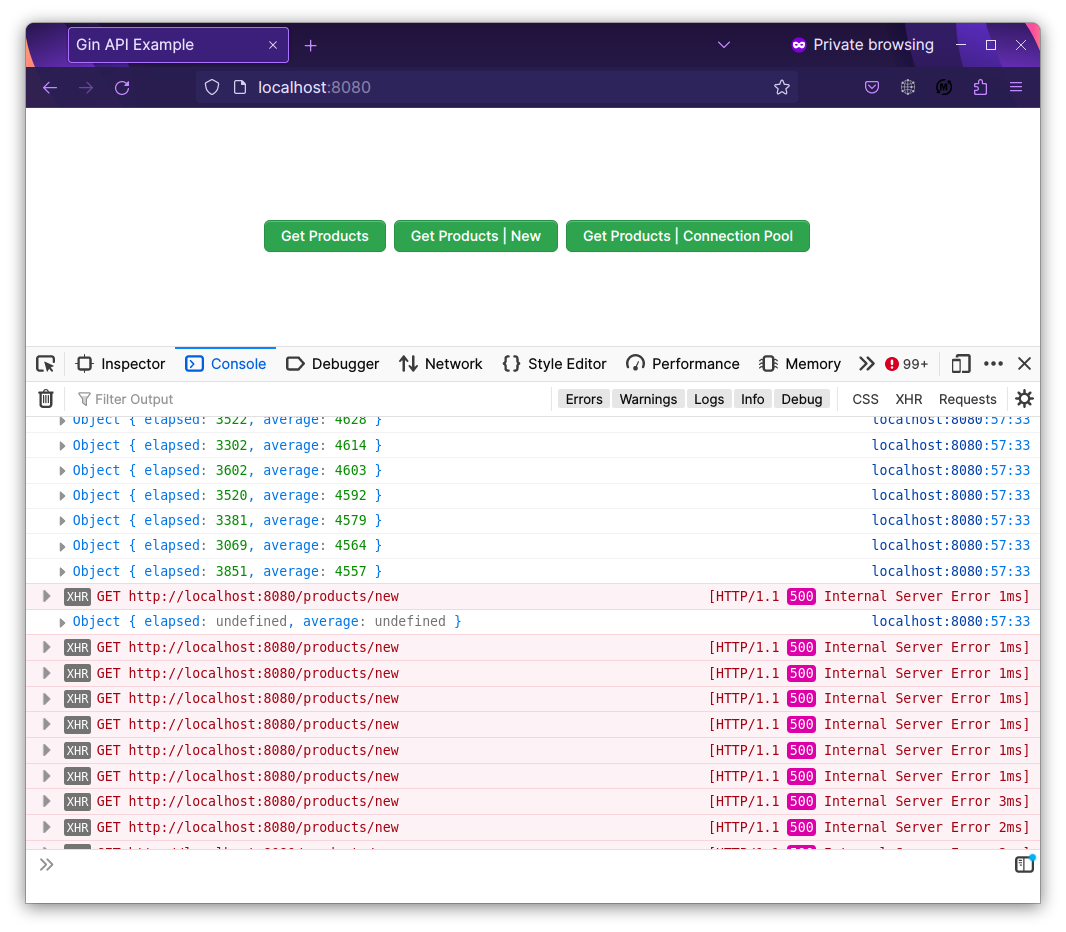
Đây chính là error message:
error "pq: sorry, too many clients already"
Đấy, chưa gì mới vậy thôi mà DB đã chửi rồi.
Thời gian trung bình của request ở endpoint này là khoảng: 6380 micro seconds ~ 6.3ms
Tiếp tục với nút normal, nơi mà sử dụng singleton connection cho mọi request, /products/normal:
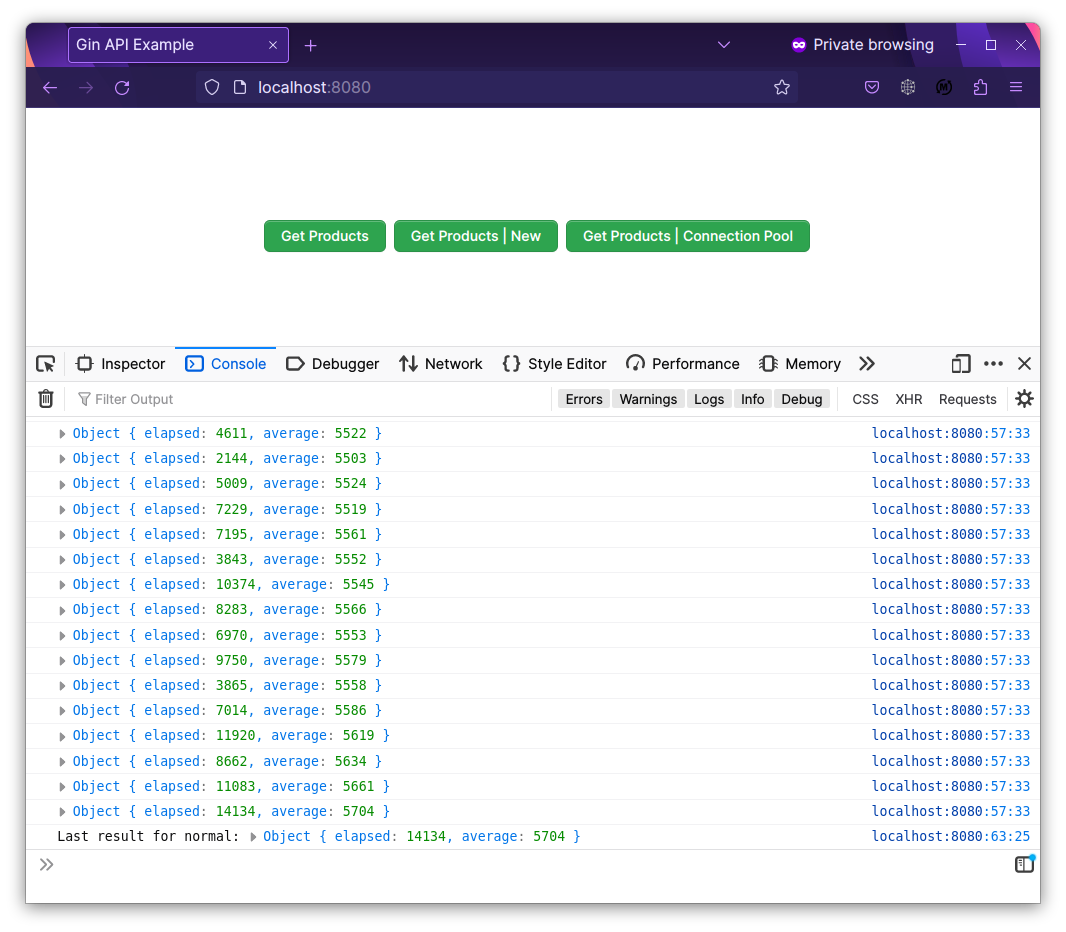
Okay, ngon nghẻ không bị lỗi request nào hết.
Thời gian request trung bình là: 5704 micro seconds ~ 5.7ms
Chúng ta tới với trùm cuối /products/pooled:
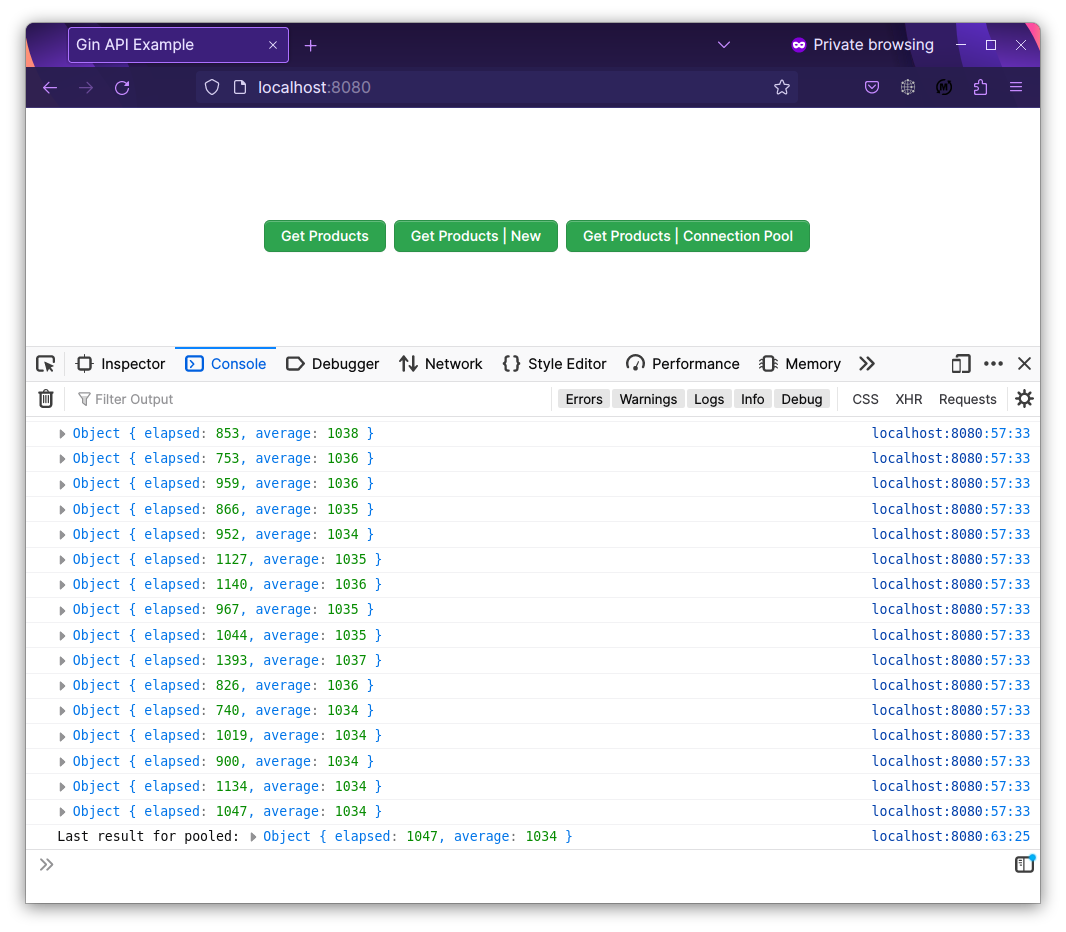
Kinh chưa? Không fail lần nào.
Con số ấn tượng: 1034 microseconds ~ 1.03ms
Benchmark hardcore hơn
Bạn có thể thấy con số khá ấn tượng của connection pool khi chúng ta chạy dồn dập 200 request bằng javascript. Tuy nhiên để giả lập tình huống thực tế lúc server nhận hàng ngàn concurrent request, mình sẽ sử dụng 1 công cụ khác để benchmark: go-wrk.
Công cụ này giúp benchmark / stress test mạnh mẽ hơn, hỗ trợ config thời gian chạy bench, số goroutine chạy đồng thời, con số này tỉ lệ thuận với số lượng request cùng gửi đi trong 1 thời điểm.
Cài đặt:
go install github.com/tsliwowicz/go-wrk@latest
Command benchmark có dạng: go-wrk -c <số goroutine> -d <số giây> <url> . Mặc định sẽ chạy 10 giây.
Config đầu tiên của mình: Chạy trong vòng 10 giây, với 20 goroutine (bạn có thể tạm hiểu goroutine là 1 thread).
Test endpoint /products/new
100 requests in 185.685138ms, 8.46MB read
Requests/sec: 538.55
Transfer/sec: 45.56MB
Avg Req Time: 37.137027ms
Fastest Request: 12.724131ms
Slowest Request: 58.512859ms
Number of Errors: 29433
Theo kết quả bạn có thể thấy ngoài tốc độ phản hồi bị tăng đáng kể tới mức 37ms, và số lượng request bị fail do hết connection cũng tới gần 30k. Hầu như chỉ có thể xử lý được 100 request, ngang bằng số lượng connection tối đa mặc định của DB.
Okay, reset lại app và test endpoint tiếp theo.
Test endpoint /products/normal
Running 10s test @ http://localhost:8080/products/normal
20 goroutine(s) running concurrently
9358 requests in 10.00261655s, 791.59MB read
Requests/sec: 935.56
Transfer/sec: 79.14MB
Avg Req Time: 21.37768ms
Fastest Request: 2.44047ms
Slowest Request: 102.748343ms
Number of Errors: 0
Nếu chúng ta sử dụng phương pháp singleton connection, chỉ cho phép 1 idle connection thì không hề có 1 request nào bị lỗi, trong 10 giây thu được 9358 request, phản hồi với thời gian 21ms.
Test endpoint /products/pooled
20 goroutine(s) running concurrently
17010 requests in 9.98895932s, 1.41GB read
Requests/sec: 1702.88
Transfer/sec: 144.04MB
Avg Req Time: 11.744808ms
Fastest Request: 1.576952ms
Slowest Request: 84.103652ms
Number of Errors: 0
Đỉnh chứ, thời gian phản hồi nhanh gấp đôi phương pháp singleton, và cũng xử lý được tới 17k request trong vòng 10 giây.
Tuy nhiên mình vẫn muốn hà hiếp cái API này thêm chút nữa, hãy tăng độ khó cho game bằng việc tăng số lượng goroutine lúc bench lên 200!
Bạn có thể đoán được kết quả rồi đấy!
Test endpoint /products/new
100 requests in 51.987238ms, 8.46MB read
Requests/sec: 1923.55
Transfer/sec: 162.71MB
Avg Req Time: 103.974476ms
Fastest Request: 48.576556ms
Slowest Request: 126.737139ms
Number of Errors: 24624
Thời gian phản hồi tăng đáng kể!
Test endpoint /products/normal
Em này có vẻ cũng không kham nổi số lượng request đồng thời đó!
8206 requests in 7.75374229s, 694.15MB read
Requests/sec: 1058.33
Transfer/sec: 89.53MB
Avg Req Time: 188.977389ms
Fastest Request: 2.688429ms
Slowest Request: 965.145213ms
Number of Errors: 3171
Test endpoint /products/pooled
Cuối cùng vẫn phải để chụy gánh, với connection pool, chỉ có 15 request bị fail
16792 requests in 10.005117575s, 1.39GB read
Requests/sec: 1678.34
Transfer/sec: 141.97MB
Avg Req Time: 119.165287ms
Fastest Request: 2.598255ms
Slowest Request: 1.004313542s
Number of Errors: 15
Thống kê lại một chút cho các bạn dễ hình dung:
| Concurent req | /products/new | /products/normal | /products/pooled |
|---|---|---|---|
| 20 gouroutine | 37ms 100 req |
21ms 9k req |
11ms 17k req |
| 200 goroutine | 103ms 100 req 24k failed |
188ms 8k req 3k failed |
119ms 16k req 15 failed |
Các bạn có thể thấy, hiệu năng khi sử dụng connection pooling thể hiện rõ ràng nhất khi mình tăng số lượng request đồng thời. Bên cạnh đó số lượng request bị lỗi cũng sẽ giảm đi.
Tuy nhiên đánh đổi điều đó là các request sẽ phải wait lâu hơn 1 chút xíu để đợi connection từ pool.
Trên đây là do mình đã disable SSL trong connection string, nếu dự án thực tế chúng ta sử dụng SSL với các remote cloud DB thì connection pooling sẽ hiệu quả rõ rệt đấy 🥸.
Config connection pool như thế nào cho hợp lý?
Khi chúng ta cài đặt các thông số như số lượng kết nối nghỉ, thời gian timeout, số lượng kết nối tối đa (pool size) bla bla, thì chúng ta cũng phải thiết lập sao cho:
- Không lãng phí tài nguyên.
- Không cài quá thấp, dẫn đến không cải thiện hiệu năng được bao nhiêu.
Mình cũng có tìm hiểu về vấn đề này, thực chất con số tối đa connection là 90 mình thiết đặt ở phần code phía trên có vẻ là quá mức cần thiết.
Bạn có thể thấy, chỉ với 1 connection duy nhất mà option /normal cũng đã xử lý được 8k request, bằng 1 nửa so với endpoint pooled.
Mình đã kiểm tra lại với số lượng tối đa idle connection và max connection là 4, ngang bằng với số core vật lý của em laptop thân yêu.
Kết quả đúng như mình nghĩ, không khác nhiều so với con số 50 và 90.
Nếu deploy lên server, thì nên thiết đặt số kết nối tối đa bé hơn hoặc bằng số lượng core/ thread của server nhé.
Kết luận
Túm cái váy lại thì connection pooling là một kỹ thuật giúp tăng hiệu suất, giảm tỉ lệ request bị lỗi. Kĩ thuật này rất hữu ích với các hệ thống backend có lượng request đồng thời lớn, do đó sẽ rất tốt nếu anh em hiểu rõ và nắm vứng nó.
Happy coding!
All rights reserved
