Data Ingestion Using Apache Nifi For Building Data Lake Using Twitter Data
Bài đăng này đã không được cập nhật trong 4 năm
What is Data Collection and Ingestion?
Data Collection and Data Ingestion are the processes of fetching data from any data source which we can perform in two ways -
- Real-time Streaming
- Batch Streaming
In Today’s World, Enterprises are generating data from different Sources and building Real Time Data lake; we need to Integrate various sources of Data into One Stream.
In this Blog We are sharing how to Ingest, Store and Process Twitter Data using Apache Nifi and in Coming Blogs, we will be Sharing Data Collection and Ingestion from Below Sources
-
Data ingestion From Logs
-
Data Ingestion from IoT Devices
-
Data Collection and Ingestion from RDBMS (e.g., MySQL)
-
Data Collection and Ingestion from ZiP Files
-
Data Collection and Ingestion from Text/CSV Files
Objectives for the Data Lake
-
A Central Repository for Big Data Management
-
Reduce costs by offloading analytical systems and archiving cold data
-
Testing Setup for experimenting with new technologies and data
-
Automation of Data pipelines
-
MetaData Management and Catalog
-
Tracking measurements with alerts on failure or violations
-
Data Governance with clear distinction of roles and responsibilities
-
Data Discovery, Prototyping, and experimentation
Introduction to Apache NiFi
Apache NiFi provides an easy to use, the powerful, and reliable system to process and distribute the data over several resources.
Apache NiFi is used for routing and processing data from any source to any destination. The process can also do some data transformation.
It is a UI based platform where we need to define our source from where we want to collect data, processors for the conversion of the data, a destination where we want to store the data.
Each processor in NiFi have some relationships like success, retry, failed, invalid data, etc. which we can use while connecting one processor to another. These links help in transferring the data to any storage or processor even after the failure by the processor.
Benefits of Apache NiFi
-
Real-time/Batch Streaming
-
Support both Standalone and Cluster mode
-
Extremely Scalable, extensible platform
-
Visual Command and Control
-
Better Error handling
Core Features of Apache NiFi
Guaranteed Delivery - A core philosophy of NiFi has been that even at very high scale, guaranteed delivery is a must. It is achievable through efficient use of a purpose-built persistent write-ahead log and content repository.
Data Buffering / Back Pressure AND Pressure Release - NiFi supports buffering of all queued data as well as the ability to provide back pressure as those lines reach specified limits or to an age of data as it reaches a specified age (its value has perished).
Prioritized Queuing - NiFi allows the setting of one or more prioritization schemes for how data from a queue is retrieved. The default is oldest first, but it can be configured to pull newest first, largest first, or some other custom scheme.
Flow Specific QoS - There are points of a data flow where the data is critical, and it is less intolerant. There are also times when it must be processed and delivered within seconds to be of any value. NiFi enables the fine-grained flow particular configuration of these concerns.
Data Provenance - NiFi automatically records, indexes, and makes available provenance data as objects flow through the system even across fan-in, fan-out, transformations, and more. This information becomes extremely critical in supporting compliance, troubleshooting, optimization, and other scenarios.
Recovery / Recording a rolling buffer of fine-grained history - NiFi’s content repository is designed to act as a rolling buffer of history. As Data ages off, it is removed from the content repository or as space is needed.
Visual Command and Control - NiFi enables the visual establishment of data flows in real-time. And provide UI based approach to build different data flow.
Flow Templates - It also allows us to create templates of frequently used data streams. It can also help in migrating the data flows from one machine to another.
Security - NiFi supports Multi-tenant Authorization. The authority level of a given data flow applies to each component, allowing the admin user to have a fine grained level of access control. It means each NiFi cluster is capable of handling the requirements of one or more organizations.
Parallel Stream to Multiple Destination - With NiFi we can move data to multiple destinations at one time. After processing the data stream, we can route the flow to the various destinations using NiFi’s processor. It can be helpful when we need to back our data on multiple destinations.
NiFi Clustering
When we require moving a large amount of data, then the only single instance of NiFi is not enough to handle that amount of data. So to handle this we can do clustering of the NiFi Servers, this will help us in scaling.
We just need to create the data flow on one node, and this will make a copy of this data flow on each node in the cluster.
NiFi introduces Zero-Master Clustering paradigm in Apache NiFi 1.0.0. A previous version of Apache NiFi based upon a single “Master Node” (more formally known as the NiFi Cluster Manager).
If the master node gets lost, data continued to flow, but the application was unable to show the topology of the flow, or show any stats. But in Zero-Master we can make changes from any node of the cluster.
And if master node disconnects, then automatically any active node is elected as Master Node.
Each node has the same the data flow, so they work on the same task as the other nodes are working, but each operates on the different datasets.
In NiFi cluster, one node is elected as the Master(Cluster Coordinator), and another node sends heartbeats/status information to the master node. This node is responsible for the disconnection of the other nodes that do not send any pulse/status information.
This election of the master node is done via Apache Zookeeper. And In the case when the master nodes get disconnected, Apache Zookeeper elects any active node as the master node.
Data Collection and Ingestion from Twitter using Apache NiFi to Build Data Lake
-
Amazon S3
-
Amazon Redshift
-
Apache Kafka
-
Apache Spark
-
Apache Flink
-
ElasticSearch
-
Apache Hive
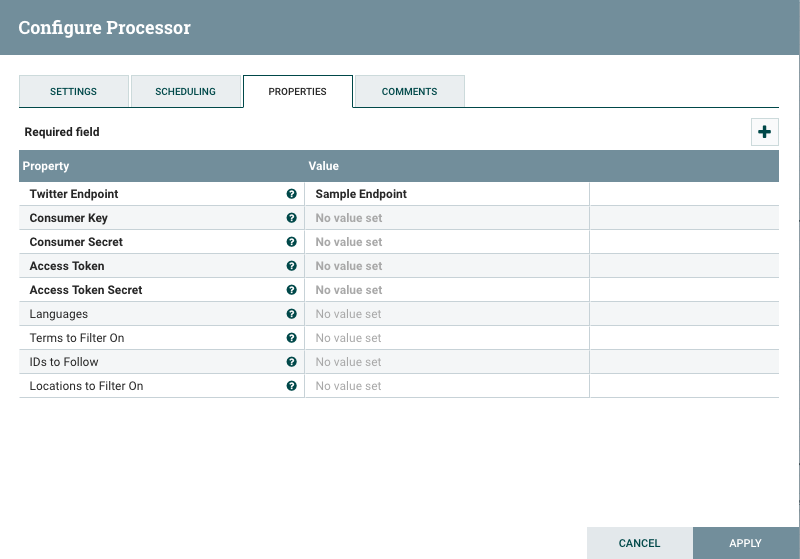
Fetching Tweets with NiFi’s Processor
NiFi’s ‘GetTwitter’ processor is used to fetch tweets. It uses Twitter Streaming API for retrieving tweets. In this processor, we need to define the endpoint which we need to use. We can also apply filters by location, hashtags, particular IDs.
Twitter Endpoint - Here we can set the endpoint from which data should get pulled. Available parameters -
-
Sample Endpoint - Fetch public tweets from all over the world.
-
Firehose Endpoint - This is same as streaming API, but it ensures 100% guarantee delivery of tweets with filters.
-
Filter Endpoint - If we want to filter by any hashtags or keywords
Consumer Key - Consumer key provided by Twitter.
Consumer Secret - Consumer Secret provided by Twitter.
Access Token - Access Token provided by Twitter.
Access Token Secret - Access Token Secret provided by Twitter.
Languages - Languages for which tweets should fetch out.
Terms to Filter - Hashtags for which tweets should fetch out.
IDs to follow - Twitter user IDs that should be followed.
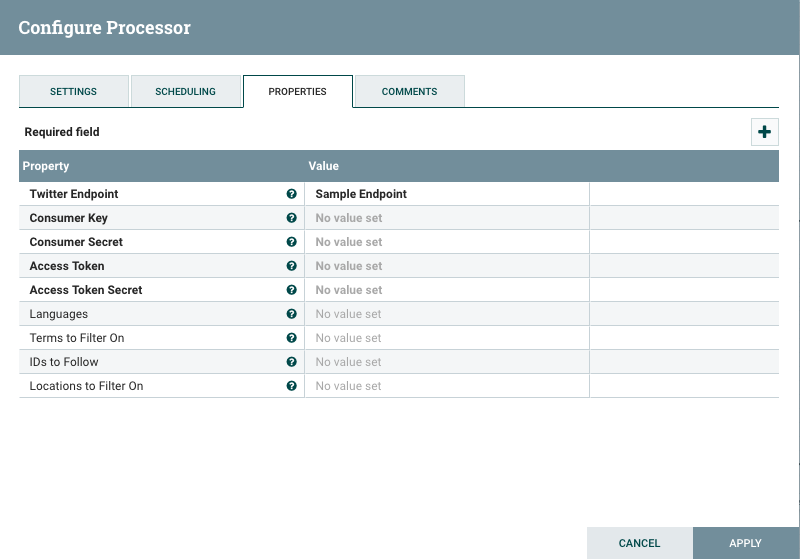
Now processor GetTwitter is ready for transmission of the data(tweets). From here we can move our data stream to anywhere like Amazon S3, Apache Kafka, ElasticSearch, Amazon Redshift, HDFS, Hive, Cassandra, etc. NiFi can move data multiple destinations parallelly.
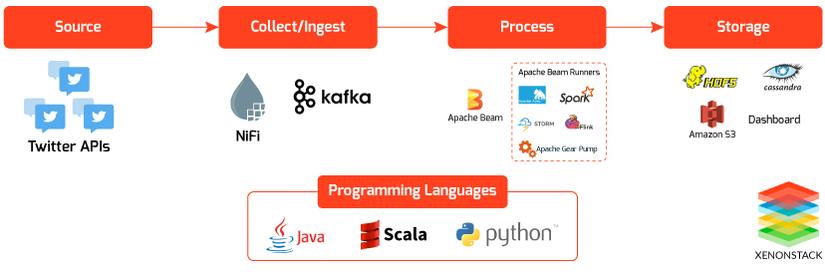
Data Integration Using Apache NiFi and Apache Kafka
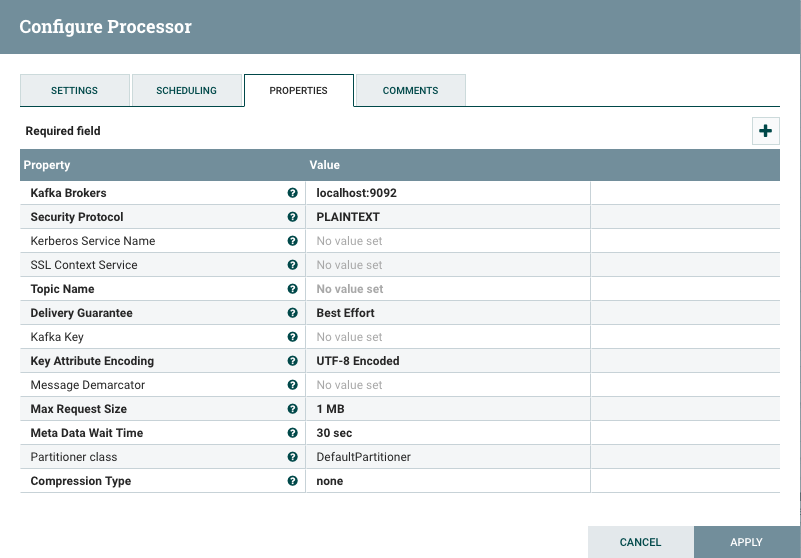
For this, we are using NiFi processor ‘PublishKafka_0_10’.
In the Scheduling Tab, we can configure how many concurrent tasks to be executed and schedule the processor.
In Properties Tab, we can set up our Kafka broker URLs, topic name, request size, etc. It will write data to the given topic. For the best results, we can create a Kafka topic manually of a defined partitions.
Apache Kafka can be used to process data with Apache Beam, Apache Flink, Apache Spark.
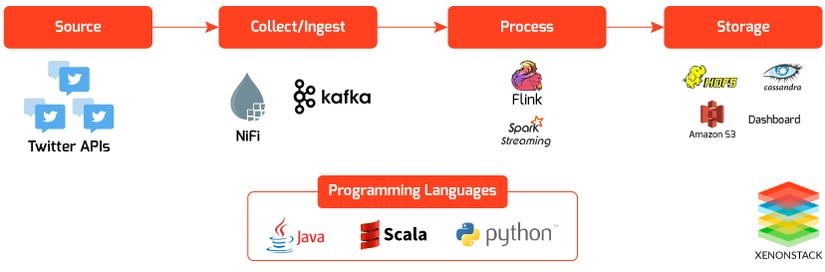
Data Integration Using Apache NiFi to Amazon RedShift with Amazon Kinesis Firehose Stream
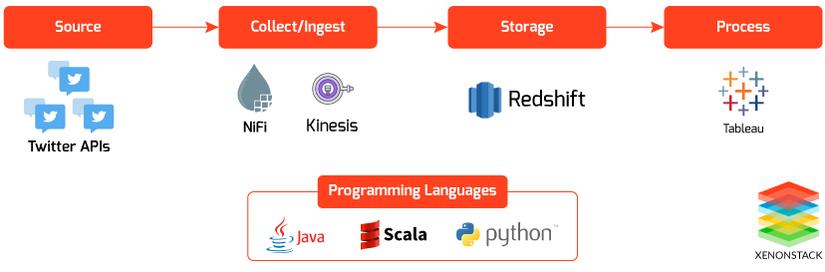
Now we integrate Apache NiFi to Amazon Redshift. NiFi uses Amazon Kinesis Firehose Delivery Stream to store data to Amazon Redshift.
This delivery Stream should get utilized for moving data to Amazon Redshift, Amazon S3, Amazon ElasticSearch Service. We need to specify this while creating Amazon Kinesis Firehose Delivery Stream.
Now we have to move data to Amazon Redshift, so firstly we need to configure Amazon Kinesis Firehose Delivery Stream. While delivering data to Amazon Redshift, firstly the data is provided to Amazon S3 bucket, and then Amazon Redshift Copy command is used to move data to Amazon Redshift Cluster.
Continue Reading The Full Article At - XenonStack.com/Blog
All rights reserved
