Consistent Hashing - Chìa khóa để tối ưu các hệ thống lưu trữ phân tán
Bài đăng này đã không được cập nhật trong 3 năm
Overview
Đối với các hệ thống lưu trữ phân tán, việc phân phối dữ liệu đồng đều giữa các server đóng vai trò rất quan trọng, nó giúp đảm bảo hiệu năng cho hệ thống cũng như tránh được tình trạng tài nguyên của một server cạn kiệt trong khi các server khác dư thừa.
Rehashing problem
Với một hệ thống lưu trữ có n server, người ta thường nghĩ đến một cách phân chia dữ liệu khá phổ biến:
ServerIndex = hash_function(key) % N
Trong đó:
- ServerIndex: thứ tự server
- hash_function: hàm băm
- key ( khóa của dữ liệu dạng key-value)
- N: số lượng server
Ví dụ: với N = 4, ta sẽ phân bổ dữ liệu như hình sau
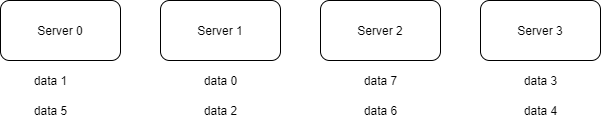
Trong trường hợp số lượng server không đổi, cách làm này hoạt động rất ổn.
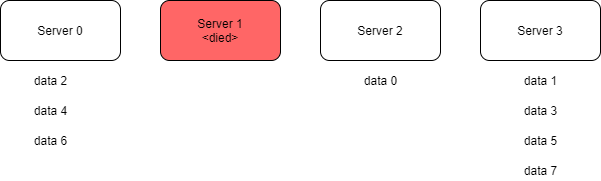
Tuy nhiên, đối với những hệ thống cần scale up/down, vấn đề nảy sinh khi ta thêm mới hoặc xóa bớt server, một lượng lớn dữ liệu sẽ cần được phân bổ lại. Ví dụ ở đây ta giảm bớt một server, N=3, khi áp dụng công thức trên để phân chia dữ liệu, gần như tất cả các bản ghi dữ liệu cần phân bố lại:
Và nếu bạn đang sử dụng cache client để lấy dữ liệu, điều này đồng nghĩa với việc các cache clients sẽ kết nối tới nhầm server, gây nên hiện tượng hàng loạt cache misses.
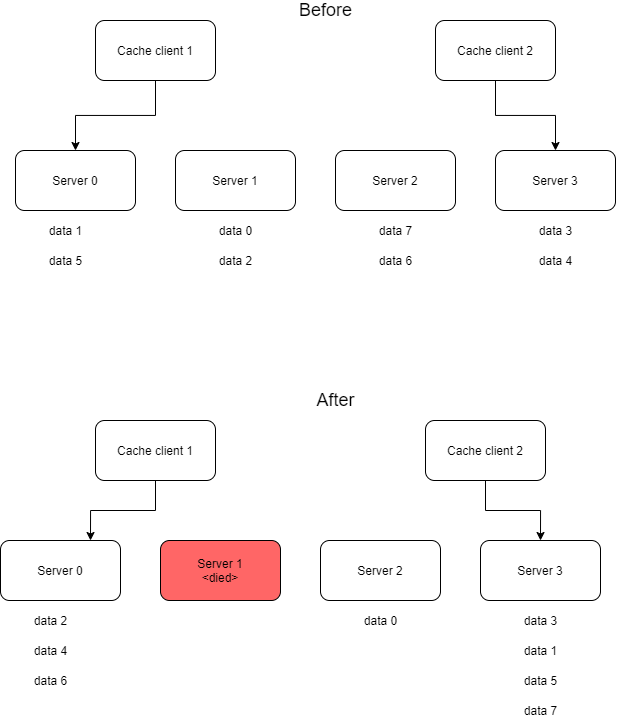
Giải pháp cho vấn đề này chính là consistent hashing
Consistent hashing
Định nghĩa
Theo wikipedia
"Consistent hashing is a special kind of hashing technique such that when a hash table is resized, only n/m keys need to be remapped on average where n is the number of keys and m is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation."
Chúng ta có thể hiểu consistent hashing là một kĩ thuật mã hóa mà khi kích thước của hash table thay đổi, chỉ có trung bình khoảng k/n bản ghi cần thay đổi vị trí lưu trữ, với k là số bản ghi, n là số chủ thể lưu trữ (servers, partitions), trong khi nếu sử dụng kĩ thuật modular operation (%) , gần như tất cả bản ghi cần phân phối lại.
Cách thức hoạt động
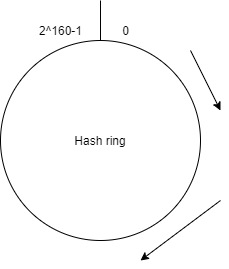
Gọi f() là hàm băm được sử dụng, mỗi hàm băm sẽ có một khoảng giá trị đầu ra (hash space) nhất định, ví dụ SHA-1 có hash space từ 0 tới 2^160-1, ta xây dựng được một vòng băm (hash ring) tương ứng.
Tiếp đến, thực hiện băm cho các server (theo IP hoặc server name, ....)
f(serverIP)
# or f(server-name)
Băm cho các bản ghi dữ liệu
f(key)
Kết quả băm server và dữ liệu sẽ được biểu diễn trên vòng băm
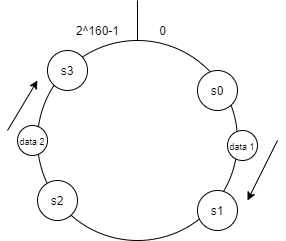
Để xác định dữ liệu thuộc server nào, ta dịch chuyển theo chiều kim đồng hồ để tìm kiếm server gần nhất. Như ví dụ trên, data1 sẽ thuộc nằm ở server1, data2 thuộc về server3.
Khi thêm một server
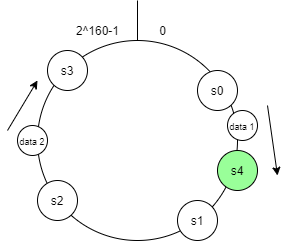
Ở đây, sau khi thêm server s4, chỉ những bản ghi nằm giữa s0 và s4 cần phân phối lại, cụ thể là chuyển từ s1 sang s4.
Khi xóa một server
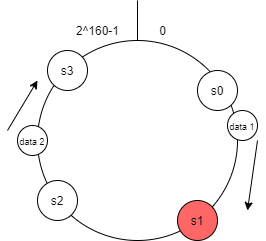
Tương tự, trong trường hợp này, sau khi xóa server s1, chỉ những bản ghi nằm giữa s0 và s1 cần thay đổi vị trí lưu trữ, cụ thể là chuyển từ s1 sang s2.
Nhược điểm
Có thể thấy, với mỗi thao tác scale down, dữ liệu của server bị xóa được dồn hết tới một server khác, dẫn tới việc kích thước các partition (khoảng giữa hai server liền kề trên hash ring) sẽ khác nhau, lượng dữ liệu phân bổ trên các server chênh lệch khá lớn.
Cải tiến consistent hashing : Virtual Nodes.
Ý tưởng ở đây là phân chia một server thành nhiều virtual node, và sử dụng virtual node thay cho server trên hash ring.
Ở đây mỗi server được chia thành 2 node.
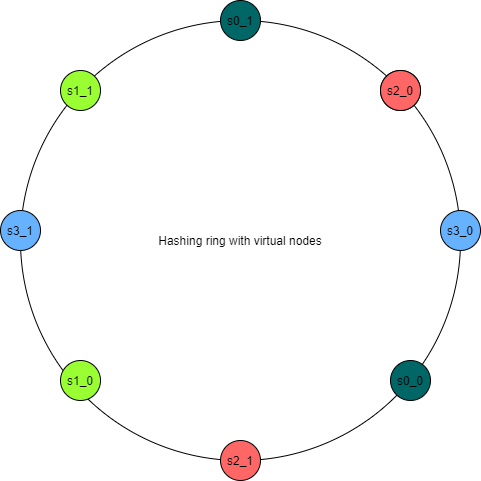
Khi một server bị loại bỏ, dữ liệu của nó sẽ được phân chia cho nhiều server khác.
 Ví dụ như hình trên, nếu server 2 ( tướng ứng với 2 virtual node s2_0 và s2_1 ) bị xóa, dữ liệu sẽ được phân bố lại cho s3_0 và s1_0.
Ví dụ như hình trên, nếu server 2 ( tướng ứng với 2 virtual node s2_0 và s2_1 ) bị xóa, dữ liệu sẽ được phân bố lại cho s3_0 và s1_0.
Tổng kết
Trong bài viết này, chúng ta đã thảo luận với nhau về cách sử dụng Consistent hashing, cũng như những lợi ích mà nó đem lại:
- Giảm thiểu tối đa lượng dữ liệu cần phân phối lại khi scale up/ scale down
- Phân chia dữ liệu đồng đều giữa các server/partition
Do tính đơn giản và hiệu quả, Consistent hashing đã và đang được sử dụng rộng rãi trên các hệ thống lưu trữ phân tán nổi tiếng như
- Amazon Dynamo database
- Apache Cassandra partition
- Akamai CDN
Hy vọng bài viết sẽ hữu ích cho mọi người 😁😁!
All rights reserved
