Chương 2. Deep into Kafka - Kafka in Action Series
Chương 2. Deep into Kafka 📚
Trong chương này, chúng ta sẽ cùng khám phá chi tiết các thành phần cơ bản của Kafka, từ khái niệm producing và consuming messages cho đến cấu trúc nội bộ như brokers, ZooKeeper và các gói mã nguồn quan trọng như Kafka Streams hay Kafka Connect. Đây là nền tảng giúp bạn hiểu rõ Kafka hoạt động như thế nào và vì sao nó lại trở thành công cụ phổ biến trong kiến trúc xử lý dữ liệu thời gian thực.
2.1 Producing and Consuming a Message 🔄
Về cơ bản 1 message/record, sẽ có 1 cặp key value
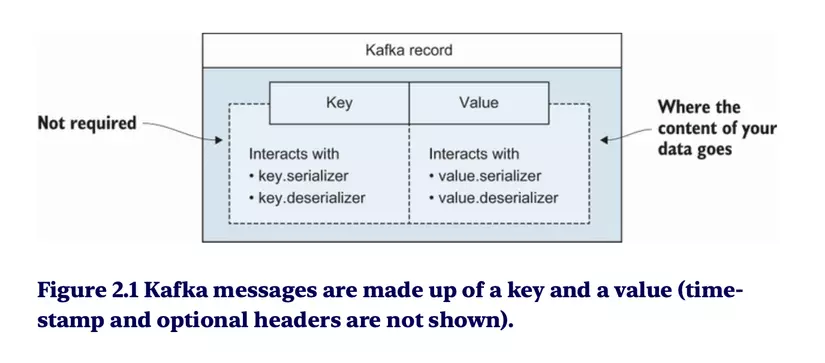
2.2 What are Brokers? 🖥️
Brokers là gì?
- Broker là các máy chủ trong Kafka, nơi dữ liệu được lưu trữ và quản lý.
- Một cluster Kafka có thể bao gồm nhiều brokers để tăng khả năng mở rộng và chịu lỗi.
Vai trò của broker trong Kafka
- Quản lý và lưu trữ messages trong partitions.
- Thực hiện cơ chế replication (sao chép dữ liệu) để đảm bảo độ tin cậy.
- Chia sẻ tải giữa các broker để xử lý dữ liệu lớn.
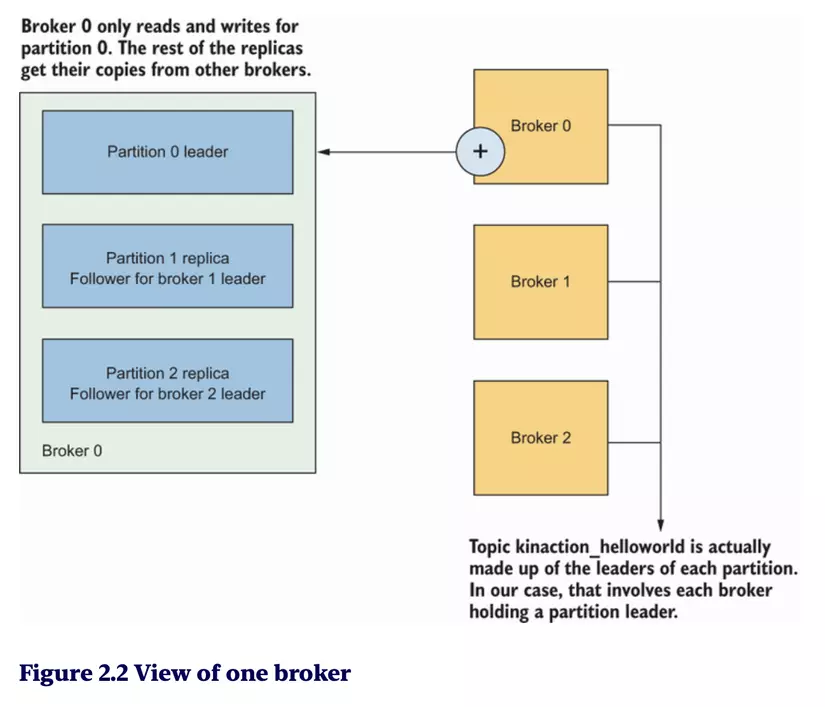
Hình 2.2, mỗi broker nắm một partition leader và các follower của các partition còn lại
2.3 Tour of Kafka 🚀
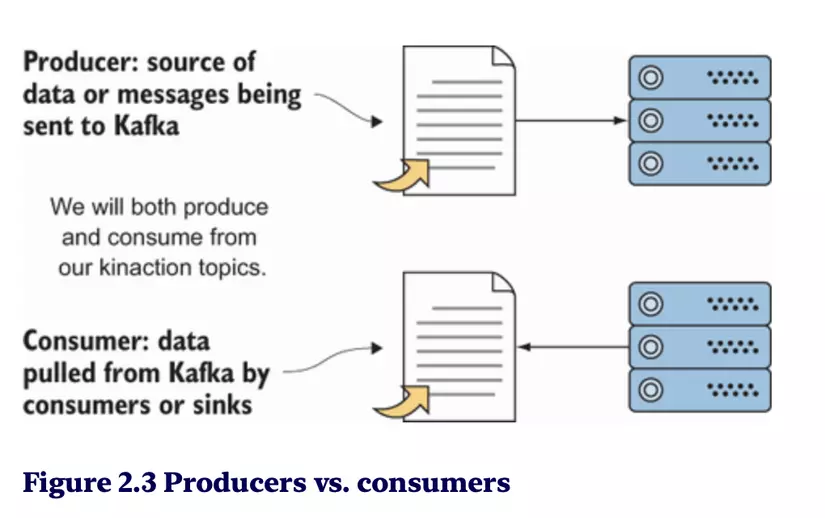
Producers and Consumers
- Producers: Gửi tin nhắn đến Kafka topics.
- Consumers: Đọc tin nhắn từ Kafka topics.
- Producers và consumers hoạt động độc lập và không cần biết đến nhau, nhờ đó hệ thống được tách rời và dễ mở rộng.
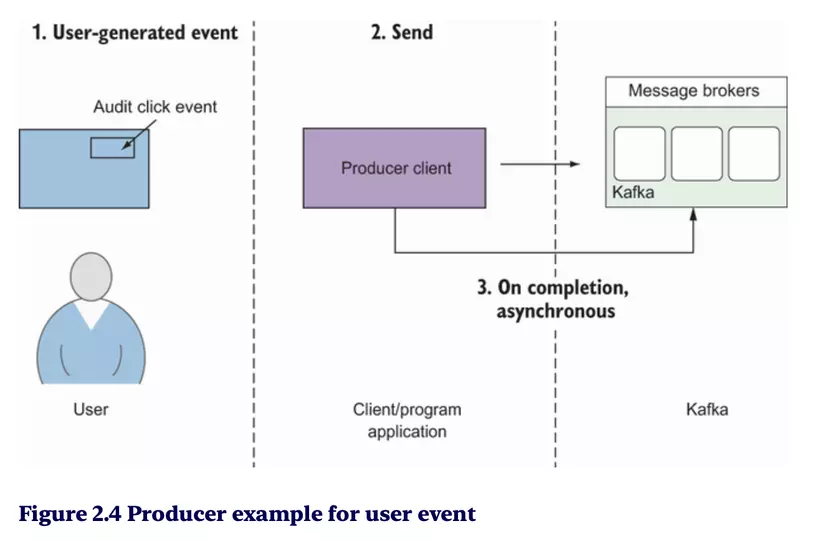
Producer gửi message:
Alert alert = new Alert(1, "Stage 1", "CRITICAL", "Stage 1 stopped");
ProducerRecord<Alert, String> producerRecord =
new ProducerRecord<Alert, String>
("kinaction_alert", alert, alert.getAlertMessage()); ❶
producer.send(producerRecord, ❷
new AlertCallback()); ❸
producer.close();
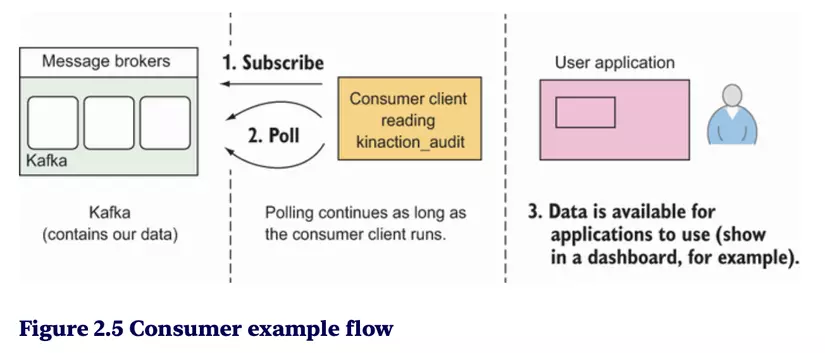
Consumming message
consumer.subscribe(List.of("kinaction_audit")); ❶
while (keepConsuming) {
var records = consumer.
poll(Duration.ofMillis(250)); ❷
for (ConsumerRecord<String, String> record : records) {
log.info("kinaction_info offset = {}, kinaction_value = {}",
record.offset(), record.value());
OffsetAndMetadata offsetMeta =
new OffsetAndMetadata(++record.offset(), "");
Map<TopicPartition, OffsetAndMetadata> kaOffsetMap = new HashMap<>();
kaOffsetMap.put(new TopicPartition("kinaction_audit",
record.partition()), offsetMeta);
consumer.commitSync(kaOffsetMap);
}
}
...
❶ The consumer subscribes to the topics that it cares about.
❷ Messages are returned from a poll of data.
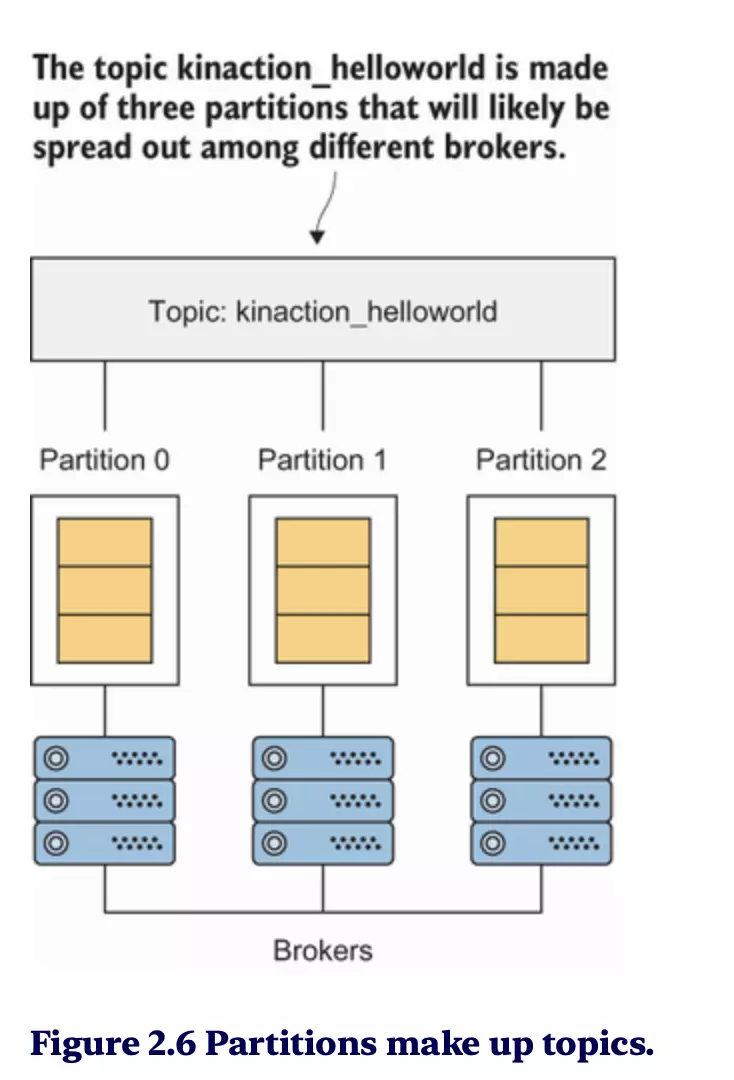
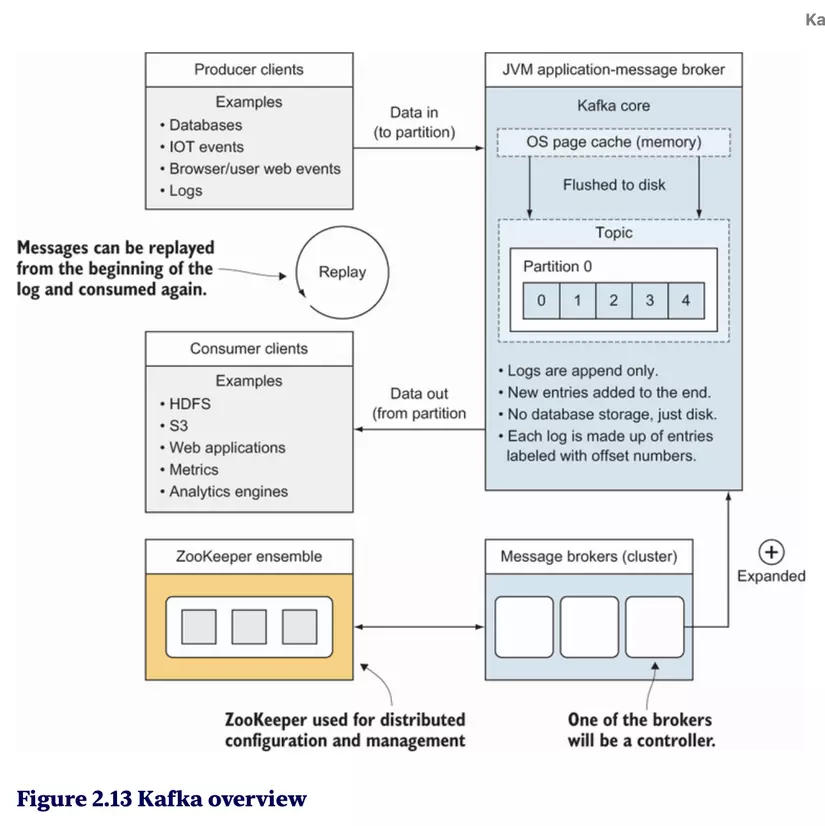
Topics overview
- Topic là trung tâm lưu trữ các tin nhắn.
- Topic được chia thành partition để dữ liệu có thể được xử lý song song.
ZooKeeper usage
- ZooKeeper là dịch vụ điều phối, chịu trách nhiệm quản lý Kafka cluster.
- Nó giám sát trạng thái của các broker và phân bổ partition leader.
Kafka’s high-level architecture
- Kafka sử dụng kiến trúc phân tán, bao gồm các thành phần chính:
- Producers
- Brokers
- Consumers
- ZooKeeper
- Dữ liệu được lưu trữ trong partition để đảm bảo khả năng mở rộng và xử lý song song.
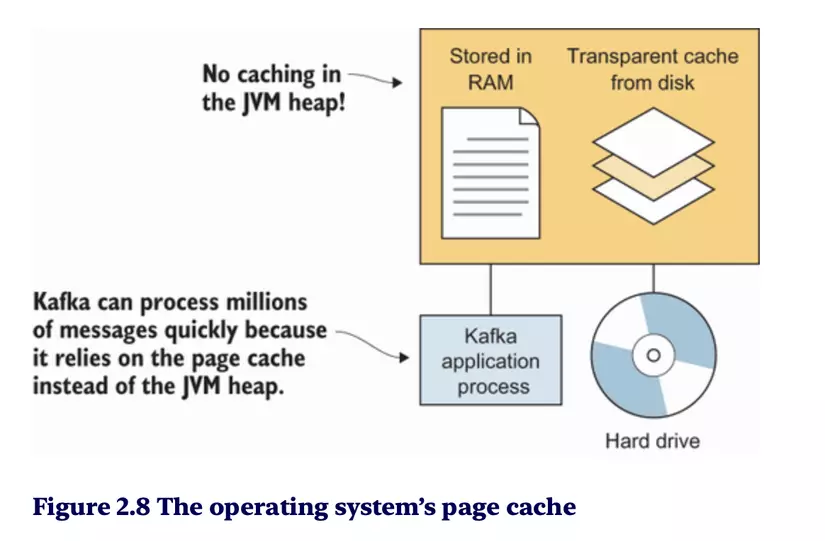
Kafka đạt được hiệu suất cao trong việc xử lý hàng triệu thông điệp nhờ sử dụng OS Page Cache, thay vì dựa vào bộ nhớ heap của JVM. Điều này mang lại một số lợi ích quan trọng:
-
No caching in the JVM heap:
- Kafka không lưu trữ dữ liệu tạm trong bộ nhớ heap của JVM, giúp giảm áp lực lên Garbage Collector (GC) và tránh tắc nghẽn hệ thống.
-
Stored in RAM:
- Kafka tận dụng RAM của hệ điều hành để lưu trữ dữ liệu tạm thời, tăng tốc độ truy cập.
-
Transparent cache from disk:
- Kafka dựa vào cơ chế cache trong hệ điều hành để tải dữ liệu từ đĩa cứng lên RAM, giúp việc truy xuất nhanh chóng và hiệu quả.
-
Kafka application process:
- Các ứng dụng Kafka có thể đọc dữ liệu trực tiếp từ page cache mà không cần xử lý dữ liệu thô từ đĩa cứng, giảm độ trễ I/O.
🔥 Tại sao Kafka không sử dụng JVM Heap?
- Hiệu suất: JVM Heap thường bị hạn chế bởi Garbage Collection, gây chậm trễ khi quản lý bộ nhớ.
- Sử dụng tài nguyên hệ điều hành: Page Cache của hệ điều hành được tối ưu hóa để xử lý các thao tác I/O với đĩa, giúp Kafka đọc/ghi dữ liệu hiệu quả hơn.
- Dữ liệu lớn: Kafka thường xử lý hàng terabyte dữ liệu, vượt quá giới hạn của bộ nhớ JVM Heap.
The commit log
- Kafka lưu trữ các tin nhắn dưới dạng commit log, một cấu trúc dữ liệu ghi tuần tự.
- Mỗi tin nhắn được gắn một offset và được lưu trữ cho đến khi hết thời gian quy định hoặc dung lượng lưu trữ.
2.4 Various Source Code Packages and What They Do 💻
Kafka Streams
- Kafka Streams là thư viện để xử lý dữ liệu thời gian thực được lưu trữ trong Kafka.
- Nó giúp bạn xây dựng các ứng dụng stream processing mà không cần thêm hệ thống khác như Spark hoặc Flink.
Kafka Streams API là một công cụ mạnh mẽ được xây dựng để đơn giản hóa việc tạo ứng dụng xử lý dữ liệu streaming. Nó tận dụng lõi của Kafka và mở rộng khả năng bằng cách bổ sung các tính năng như stateful processing (xử lý dữ liệu có trạng thái) và distributed joins (ghép nối phân tán), giúp các ứng dụng streaming trở nên mạnh mẽ mà không tăng thêm độ phức tạp.
Lợi ích của Kafka Streams API
-
API dễ sử dụng:
- Kafka Streams API cung cấp một cú pháp fluent API, giống với Java 8's Stream API.
- Điều này cho phép các nhà phát triển làm việc với luồng dữ liệu bằng cách sử dụng các phương thức quen thuộc như
filter(),map(), vàreduce().
-
Xử lý dữ liệu trên nền Kafka:
- API tận dụng cơ chế phân vùng (partitioning) và khả năng lưu trữ log (log retention) của Kafka.
- Kết hợp với các tính năng như state store, nó cho phép xử lý dữ liệu trạng thái phức tạp mà không làm tăng tải hệ thống.
-
Phân phối và mở rộng:
- Kafka Streams API hoạt động trên nguyên tắc phân tán, cho phép xử lý dữ liệu trên nhiều node trong một cluster.
- Điều này giúp mở rộng hệ thống dễ dàng mà không làm giảm hiệu suất.
-
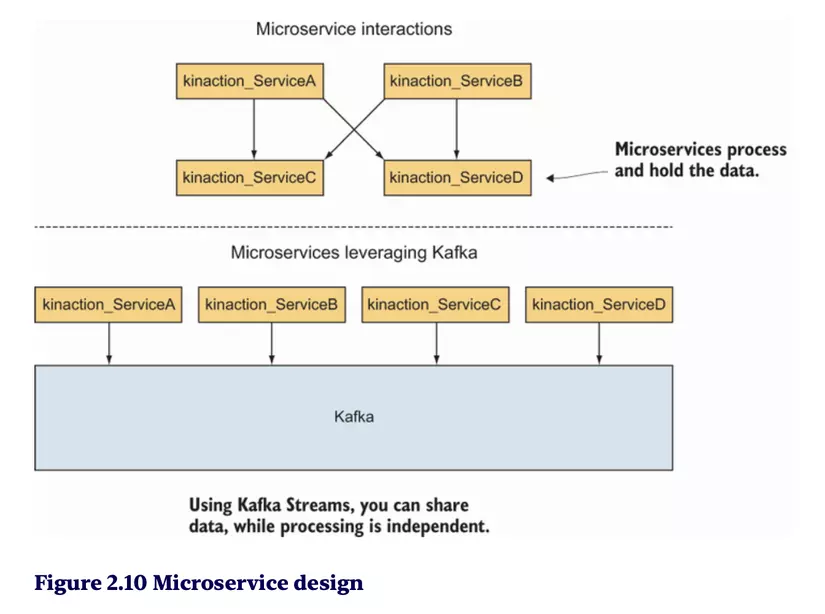
Ứng dụng trong Microservice:
- Thay vì mỗi ứng dụng microservice cô lập dữ liệu riêng, Kafka Streams cho phép chia sẻ dữ liệu tập trung qua Kafka.
- Các ứng dụng giờ đây có thể xử lý dữ liệu độc lập, loại bỏ nhu cầu giao tiếp trực tiếp phức tạp giữa các microservices.
So sánh trước và sau khi sử dụng Kafka (Hình 2.10)
-
Trước (Không dùng Kafka):
- Các microservices giao tiếp trực tiếp với nhau thông qua nhiều giao diện (interfaces), tạo ra kết nối chặt chẽ và khó mở rộng.
-
Sau (Sử dụng Kafka):
- Kafka trở thành trung tâm, cung cấp một nền tảng chia sẻ dữ liệu duy nhất.
- Các microservices không cần kết nối trực tiếp với nhau mà có thể truy cập dữ liệu từ Kafka một cách độc lập.
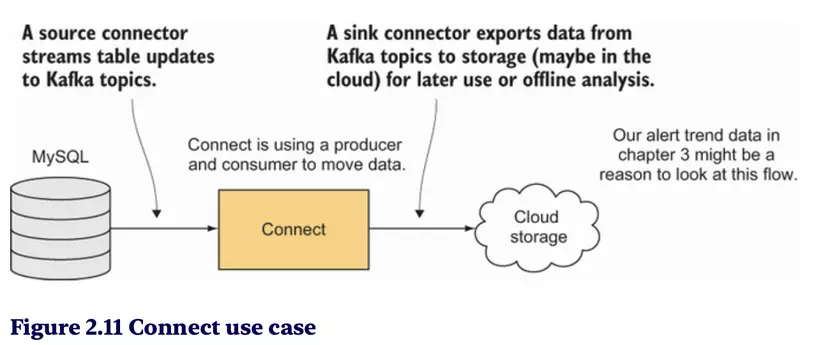
Kafka Connect
- Kafka Connect là công cụ để kết nối Kafka với các hệ thống khác như databases, Hadoop, hoặc Elasticsearch.
- Nó hỗ trợ các source connectors (đọc dữ liệu vào Kafka) và sink connectors (ghi dữ liệu từ Kafka ra ngoài).
AdminClient package
- Gói này cung cấp các API quản trị Kafka như:
- Tạo và xóa topic.
- Quản lý cấu hình topic và broker.
ksqlDB
- ksqlDB là công cụ giúp thực thi các truy vấn SQL trên dữ liệu Kafka.
- Người dùng có thể viết câu lệnh SQL để lọc, chuyển đổi và tổng hợp dữ liệu theo thời gian thực.
2.5 Confluent Clients 🤝
Confluent Clients là các thư viện khách hàng được phát triển bởi Confluent để mở rộng khả năng sử dụng Kafka.
Các client này hỗ trợ nhiều ngôn ngữ lập trình như Java, Python, và Go, giúp developer dễ dàng tích hợp Kafka vào ứng dụng của họ.
2.6 Stream Processing and Terminology 🌊
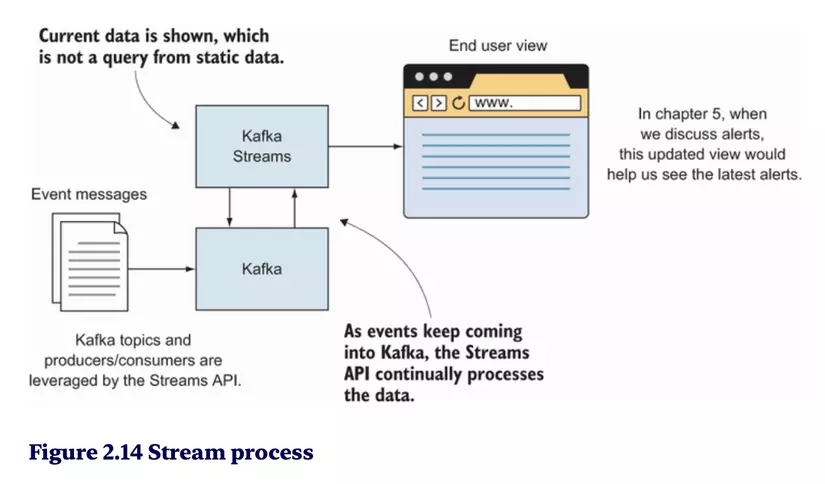
Stream processing là gì?
- Stream processing là quá trình xử lý dữ liệu liên tục khi nó được tạo ra trong thời gian thực.
Kafka Streams và các khái niệm liên quan
- Exactly-once: Đảm bảo mỗi tin nhắn chỉ được xử lý một lần duy nhất. Đây là một thách thức lớn trong hệ thống phân tán, nhưng Kafka đã giải quyết được.
Ví dụ:
Một hệ thống thanh toán có thể sử dụng Kafka Streams để đảm bảo mọi giao dịch chỉ được xử lý một lần, tránh tình trạng xử lý trùng lặp.
References 🔗
Để mở rộng kiến thức, bạn có thể tham khảo:
- Apache Kafka Documentation
- Confluent Platform
- Các khóa học Kafka trên Udemy hoặc Coursera.
Lời kết 🎯
Chương 2 đã giúp bạn làm quen với các khái niệm cốt lõi trong Kafka như producer, consumer, broker, và kiến trúc cơ bản của Kafka. Ngoài ra, các công cụ mạnh mẽ như Kafka Streams, Kafka Connect, và ksqlDB sẽ giúp bạn tận dụng tối đa Kafka trong các dự án thực tế.
Trong các chương tiếp theo, chúng ta sẽ tiếp tục đi sâu vào cách triển khai và tối ưu hóa Kafka trong hệ thống của bạn. 🚀
All rights reserved
