Chương 1. Giới Thiệu về Kafka: Cơ Sở Hạ Tầng của Dữ Liệu Thời gian thực - Kafka In Action Series
Chương 1. Giới thiệu về Kafka 🚀

Apache Kafka là một nền tảng truyền tải dữ liệu theo dạng luồng (event streaming) mã nguồn mở, được thiết kế để xây dựng các pipeline dữ liệu thời gian thực và các ứng dụng xử lý dữ liệu liên tục. Kafka được phát triển bởi LinkedIn và sau đó được chuyển giao cho Apache Software Foundation. Ngày nay, Kafka đã trở thành một công cụ mạnh mẽ trong việc xử lý và phân phối luồng dữ liệu với hiệu suất cao và độ trễ thấp.
Trong bài viết này, chúng ta sẽ khám phá Kafka là gì, cách thức hoạt động của nó, và lý do vì sao Kafka lại quan trọng trong xử lý dữ liệu hiện đại.
Mục lục 📝
- Kafka là gì? 🧐
- Các khái niệm cơ bản trong Kafka ⚙️
- Kafka hoạt động như thế nào? 🛠️
- Các trường hợp sử dụng Kafka 💡
- So sánh Kafka với các hệ thống nhắn tin khác 🔄
- Bắt đầu với Kafka 🚀
- Lời kết 🎯
Kafka là gì? 🧐
Kafka là một hệ thống nhắn tin phân tán theo mô hình publish-subscribe (xuất bản và đăng ký), được tối ưu hóa để xử lý các luồng dữ liệu real-time. Kafka cho phép người dùng xuất bản (gửi) và đăng ký (nhận) các bản tin (tin nhắn hoặc sự kiện). Đây là nền tảng lý tưởng để xây dựng các ứng dụng event-driven (dựa trên sự kiện) với khả năng xử lý dữ liệu lớn.
Các thành phần chính của Kafka bao gồm:
- Producer: Thành phần gửi dữ liệu (tin nhắn) tới các topic trong Kafka.
- Consumer: Thành phần nhận và xử lý dữ liệu từ các topic.
- Broker: Máy chủ Kafka, nơi lưu trữ và phục vụ tin nhắn.
- ZooKeeper: Dịch vụ quản lý và điều phối các broker trong Kafka (tuy nhiên, với các phiên bản mới hơn, Kafka đang dần loại bỏ sự phụ thuộc vào ZooKeeper).
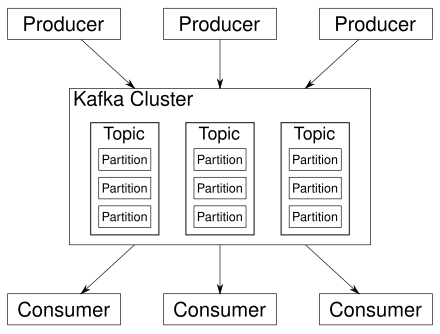
Các khái niệm cơ bản trong Kafka ⚙️
-
Topic: Là các chủ đề mà Kafka sử dụng để tổ chức các bản tin. Producer gửi dữ liệu đến các topic, còn Consumer nhận dữ liệu từ các topic.
- Ví dụ: Nếu bạn có một hệ thống theo dõi tình trạng đơn hàng, bạn có thể tạo các topic như
orders,payments,inventory.
- Ví dụ: Nếu bạn có một hệ thống theo dõi tình trạng đơn hàng, bạn có thể tạo các topic như
-
Partition: Mỗi topic có thể được chia thành nhiều partition, mỗi partition là một đoạn dữ liệu riêng biệt, cho phép xử lý song song và tăng khả năng mở rộng.
- Ví dụ: Topic
orderscó thể được chia thành các partition để các máy chủ có thể xử lý các đơn hàng đồng thời mà không làm chậm tốc độ.
- Ví dụ: Topic
-
Offset: Kafka đánh dấu vị trí của mỗi bản tin trong partition bằng một chỉ số gọi là offset. Consumer dùng offset để đọc dữ liệu theo đúng thứ tự.
- Ví dụ: Một consumer đọc bản tin ở offset 10, và khi consumer tiếp theo bắt đầu, nó sẽ tiếp tục từ offset 11, đảm bảo không bị lặp lại hoặc bỏ sót.
-
Replication: Kafka đảm bảo độ bền và khả năng chịu lỗi bằng cách sao chép dữ liệu của các partition lên nhiều broker. Nếu một broker gặp sự cố, broker khác có thể thay thế và tiếp tục hoạt động mà không mất dữ liệu.
- Ví dụ: Nếu bạn có một partition với ba bản sao, khi một broker gặp sự cố, các bản sao khác sẽ vẫn giữ dữ liệu an toàn và có thể phục hồi ngay lập tức.
Kafka hoạt động như thế nào? 🛠️
Kafka hoạt động theo cách cho phép producers gửi dữ liệu đến các broker Kafka, và các broker này sẽ lưu trữ dữ liệu trong các topic. Các consumers sau đó sẽ đọc dữ liệu từ các topic này.
- Producers gửi các bản tin vào topic.
- Kafka phân chia các topic thành nhiều partition và phân phối chúng trên các broker.
- Consumers lấy dữ liệu từ một hoặc nhiều partition.
- Kafka đảm bảo khả năng chịu lỗi và độ bền bằng cách sao chép dữ liệu trên nhiều broker.
Kafka hỗ trợ streaming dữ liệu real-time, giúp các ứng dụng có thể xử lý thông tin ngay lập tức khi nó xuất hiện. Nhờ vào khả năng scalability và fault tolerance tuyệt vời, Kafka có thể đáp ứng được những nhu cầu đòi hỏi tốc độ cao và tính liên tục trong các ứng dụng lớn.
Các trường hợp sử dụng Kafka 💡
Kafka có nhiều ứng dụng thực tế, chẳng hạn như:
-
Phân tích thời gian thực: Truyền tải dữ liệu đến các nền tảng phân tích thời gian thực như Apache Spark hay Apache Flink. Ví dụ: Phân tích dữ liệu truy cập web, hành vi người dùng trên ứng dụng di động.
-
Thu thập log: Tổng hợp log từ nhiều dịch vụ và chuyển chúng vào kho dữ liệu để phân tích, giúp phát hiện lỗi hoặc bảo mật.
-
Event Sourcing: Lưu trữ và phát lại mọi sự kiện hoặc thay đổi trạng thái của hệ thống để hỗ trợ việc kiểm tra và theo dõi, giúp tái tạo lại các trạng thái hệ thống.
-
Giao tiếp giữa các Microservices: Giảm sự phụ thuộc giữa các microservices bằng cách sử dụng Kafka để xử lý các giao tiếp bất đồng bộ. Kafka trở thành "bus" truyền thông giữa các microservices.
-
Xử lý dữ liệu IoT: Thu thập và xử lý dữ liệu từ các thiết bị Internet of Things (IoT), giúp giám sát và phân tích dữ liệu từ các cảm biến trong thời gian thực.
So sánh Kafka với các hệ thống nhắn tin khác 🔄
So sánh giữa Kafka và RabbitMQ 🔄
| Tiêu chí | Kafka | RabbitMQ |
|---|---|---|
| Kiểu kiến trúc | Distributed streaming platform | Message queueing system |
| Mô hình giao tiếp | Publish-Subscribe (xuất bản và đăng ký) | Queue-based (hàng đợi) |
| Throughput | Rất cao, xử lý hàng triệu tin nhắn mỗi giây | Thấp hơn so với Kafka, phù hợp cho các tác vụ có độ trễ thấp |
| Khả năng mở rộng | Rất tốt, dễ dàng mở rộng với nhiều broker | Khả năng mở rộng hạn chế khi so với Kafka |
| Độ trễ | Thấp, đặc biệt trong các trường hợp stream dữ liệu | Thấp, nhưng thường dùng cho các hàng đợi đơn giản |
| Độ tin cậy | Rất cao, với cơ chế sao chép dữ liệu giữa các broker | Khá cao, nhưng không mạnh mẽ như Kafka trong việc chịu lỗi phân tán |
| Ứng dụng | Event streaming, real-time analytics, log aggregation | Task queueing, RPC, Workload distribution |
| Xử lý tin nhắn | Tin nhắn có thể được lưu trữ lâu dài với khả năng phát lại | Tin nhắn thường được xóa sau khi tiêu thụ |
| Phát triển và triển khai | Phức tạp hơn, đòi hỏi cấu hình nhiều cho các cluster | Dễ dàng triển khai, hỗ trợ nhiều giao thức (AMQP, MQTT) |
| Các tính năng bổ sung | Kafka Streams, kết nối với các hệ thống Big Data | Routing, Exchanges, Dead-letter queues |
So sánh giữa Kafka và ActiveMQ 🔄
| Tiêu chí | Kafka | ActiveMQ |
|---|---|---|
| Kiểu kiến trúc | Distributed streaming platform | Message queueing system |
| Mô hình giao tiếp | Publish-Subscribe và Queue-based | Queue-based và Topic-based |
| Throughput | Rất cao, xử lý hàng triệu tin nhắn mỗi giây | Thấp hơn, thích hợp cho các ứng dụng có nhu cầu thấp về throughput |
| Khả năng mở rộng | Rất tốt, dễ dàng mở rộng với nhiều broker | Khả năng mở rộng kém hơn khi so với Kafka |
| Độ trễ | Thấp, tối ưu cho stream dữ liệu real-time | Có thể cao hơn khi số lượng tin nhắn tăng lên |
| Độ tin cậy | Rất cao, với cơ chế sao chép dữ liệu (Replication) | Khá cao, nhưng không mạnh mẽ như Kafka trong việc chịu lỗi phân tán |
| Ứng dụng | Event streaming, Real-time analytics, Log aggregation | Enterprise messaging, Queueing tasks, Routing |
| Xử lý tin nhắn | Tin nhắn có thể lưu trữ lâu dài, có thể được phát lại | Tin nhắn thường bị xóa sau khi tiêu thụ |
| Tính mở rộng | Mở rộng dễ dàng, không giới hạn số lượng broker | Phức tạp hơn, không dễ dàng mở rộng |
| Tính năng bổ sung | Kafka Streams, tích hợp với các hệ thống Big Data | JMS support, Virtual Destinations, Message selectors |
Tóm tắt so sánh:
- Kafka vượt trội hơn cả về throughput, scalability, và fault tolerance. Nó phù hợp cho các ứng dụng real-time streaming, big data, và event-driven architectures.
- RabbitMQ và ActiveMQ phù hợp hơn cho các task queuing và messaging-based hệ thống, nơi các yêu cầu về độ tin cậy và xử lý thấp hơn nhưng vẫn cần các tính năng như routing và message acknowledgement.
- Kafka có lợi thế vượt trội trong các ứng dụng xử lý luồng dữ liệu lớn và high-throughput, trong khi RabbitMQ và ActiveMQ sẽ tốt hơn khi bạn cần các tính năng message queuing phức tạp hoặc các hệ thống nhỏ hơn, ít cần mở rộng.
Bắt đầu với Kafka 🚀
Nếu bạn muốn làm quen với Kafka, đây là các bước cơ bản để bắt đầu:
-
Tải và cài đặt Kafka:
- Truy cập Kafka website và tải phiên bản mới nhất.
- Cài đặt trên máy tính của bạn hoặc sử dụng Docker để triển khai nhanh chóng.
-
Khởi động Kafka server và ZooKeeper:
- Kafka sử dụng ZooKeeper để điều phối các broker trong hệ thống. Bạn cần khởi động ZooKeeper trước khi Kafka hoạt động.
-
Tạo các topic:
- Các topic là nơi bạn sẽ gửi và nhận dữ liệu. Bạn có thể tạo topic bằng cách sử dụng lệnh Kafka CLI.
-
Viết các producer:
- Các producer gửi các bản tin vào các topic. Kafka hỗ trợ nhiều ngôn ngữ lập trình như Java, Python, Go để viết producer.
-
Viết các consumer:
- Consumer nhận và xử lý dữ liệu từ các topic. Bạn có thể cấu hình consumer để đọc dữ liệu từ nhiều partition và xử lý dữ liệu theo các hình thức khác nhau.
Khám phá thêm: Tìm hiểu về Kafka Streams, thư viện giúp xử lý và phân tích dữ liệu theo thời gian thực.
Kết luận 🎯
Kafka là công cụ lý tưởng cho việc xử lý dữ liệu thời gian thực trong các hệ thống phân tán quy mô lớn. Với khả năng mở rộng mạnh mẽ, độ tin cậy cao và khả năng xử lý luồng dữ liệu hiệu quả, Kafka đang trở thành nền tảng quan trọng trong việc xây dựng các ứng dụng hiện đại.
Nếu bạn đang xây dựng ứng dụng cần throughput cao, tính bền vững và real-time streaming, hãy cân nhắc sử dụng Apache Kafka!
All rights reserved
