ChatGPT Series 7.2: Prompt Engineering (2)
Tiếp nối bài viết trước ChatGPT Series 7.1: Prompt Engineering (1) về kỹ thuật Prompt Engineering, bài viết này mình sẽ giới thiệu một số phương pháp nâng cao hơn được nghiên cứu và áp dụng cho kỹ thuật Prompt Engineering.
Self-Consistency
-
Self-Consistency là một trong những hướng tiếp cận advanced hơn trong kỹ thuật Prompt Engineering được giới thiệu bởi Wang et al. (2022) nhằm cải thiện độ chính xác và hiệu suất của phương pháp CoT Prompting. Các phương pháp truyền thống thường sử dụng greedy decoding, tức là lựa chọn từ tiếp theo có khả năng xảy ra cao nhất tại mỗi bước mà không xem xét các con đường thay thế có thể dẫn đến kết quả tổng thể tốt hơn.
-
Self-consistency giải quyết các hạn chế này bằng cách xem xét nhiều reasoning paths và chọn câu trả lời nhất quán nhất (consistent answer). Cách thức hoạt động như sau:
- Tạo ra nhiều reasoning paths đa dạng: Thay vì chỉ tạo ra một reasoning paths duy nhất, kỹ thuật này tạo ra nhiều con đường lập luận khác nhau thông qua few-shot CoT.
- Chọn câu trả lời nhất quán nhất: Từ các reasoning paths này, kỹ thuật self-consistency chọn ra câu trả lời nhất quán nhất, nghĩa là câu trả lời xuất hiện nhiều nhất hoặc có sự đồng thuận cao nhất trong các reasoning paths.
-
Ví dụ minh họa cụ thể:
- Không sử dụng Self-Consistency (Greedy Decoding):
- Prompt:
When I was 6 my sister was half my age. Now I’m 70 how old is my sister?- Output:
35 - Kết quả trả lời trên là sai! Làm thế nào để chúng ta có thể cải thiện với phương pháp Self-Consistency. Chúng ta sẽ thử nó với few-shot examples như dưới thử xem:
- Prompt:
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today? A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted. So, they must have planted 21 - 15 = 6 trees. The answer is 6. Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot? A: There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5. Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total? A: Leah had 32 chocolates and Leah’s sister had 42. That means there were originally 32 + 42 = 74 chocolates. 35 have been eaten. So in total they still have 74 - 35 = 39 chocolates. The answer is 39. Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny? A: Jason had 20 lollipops. Since he only has 12 now, he must have given the rest to Denny. The number of lollipops he has given to Denny must have been 20 - 12 = 8 lollipops. The answer is 8. Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now? A: He has 5 toys. He got 2 from mom, so after that he has 5 + 2 = 7 toys. Then he got 2 more from dad, so in total he has 7 + 2 = 9 toys. The answer is 9. Q: There were nine computers in the server room. Five more computers were installed each day, from monday to thursday. How many computers are now in the server room? A: There are 4 days from monday to thursday. 5 computers were added each day. That means in total 4 * 5 = 20 computers were added. There were 9 computers in the beginning, so now there are 9 + 20 = 29 computers. The answer is 29. Q: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many golf balls did he have at the end of wednesday? A: Michael initially had 58 balls. He lost 23 on Tuesday, so after that he has 58 - 23 = 35 balls. On Wednesday he lost 2 more so now he has 35 - 2 = 33 balls. The answer is 33. Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left? A: She bought 5 bagels for $3 each. This means she spent 5 Q: When I was 6 my sister was half my age. Now I’m 70 how old is my sister? A: - Output 1:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70 - 3 = 67. The answer is 67. - Output 2:
When the narrator was 6, his sister was half his age, which is 3. Now that the narrator is 70, his sister would be 70 - 3 = 67 years old. The answer is 67.- Output 3:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70/2 = 35. The answer is 35. - Không sử dụng Self-Consistency (Greedy Decoding):
-
Hiểu 1 cách đơn giản, chúng ta có thể thấy rằng nếu trong quá trình self-consistency, đã có một câu trả lời xuất hiện nhiều nhất hoặc có sự đồng thuận cao nhất (câu trả lời đa số), thì câu trả lời đó sẽ được chọn làm câu trả lời cuối cùng (The answer is 67.)
Tree-of-Thoughts (ToT) Prompting
-
Hạn chế của kỹ thuật prompting truyền thống:
- Đối với các nhiệm vụ phức tạp đòi hỏi sự khám phá hoặc dự đoán chiến lược, các kỹ thuật prompting truyền thống hoặc đơn giản thường không hiệu quả.
- Yao et el. (2023) và Long (2023) đã đề xuất một khung làm việc mới gọi là Tree of Thoughts (ToT), khung này tổng quát hóa phương pháp chain-of-thought prompting và khuyến khích việc khám phá các suy nghĩ làm bước trung gian cho việc giải quyết vấn đề bằng mô hình ngôn ngữ.
-
Tree of Thoughts (ToT):
- ToT tổ chức các suy nghĩ của mô hình ngôn ngữ (LLM) thành các nút trong một cấu trúc cây, cho phép kết hợp suy nghĩ với thuật toán tìm kiếm mang tính biểu tượng. Điều này mở ra khả năng chọn "đường suy nghĩ" tối ưu, nâng cấp khả năng lập kế hoạch của LLM lên mức độ phức tạp cao hơn.
-
Cách thức hoạt động của ToT: -ToT duy trì một cây suy nghĩ, trong đó các suy nghĩ là các chuỗi ngôn ngữ mạch lạc đóng vai trò như các bước trung gian để giải quyết vấn đề.
- Phương pháp này cho phép mô hình ngôn ngữ tự đánh giá tiến trình của các suy nghĩ trung gian trong quá trình giải quyết vấn đề thông qua một quá trình lý luận có chủ đích.
- Khả năng của mô hình ngôn ngữ trong việc tạo ra và đánh giá các suy nghĩ sau đó được kết hợp với các thuật toán tìm kiếm (ví dụ: tìm kiếm theo chiều rộng và tìm kiếm theo chiều sâu) để khám phá hệ thống các suy nghĩ một cách có hệ thống, với khả năng dự đoán trước và quay lui.
Tree of Thoughts (ToT) là một khung làm việc mới trong lĩnh vực prompt engineering, giúp khắc phục những hạn chế của các kỹ thuật truyền thống trong việc giải quyết các nhiệm vụ phức tạp. Bằng cách tổ chức các suy nghĩ của mô hình ngôn ngữ thành cấu trúc cây và sử dụng các thuật toán tìm kiếm, ToT cho phép lựa chọn đường suy nghĩ tối ưu, nâng cao khả năng lập kế hoạch và lý luận của mô hình ngôn ngữ.
- Minh họa phương pháp tiếp cận ToT:

- Khi sử dụng ToT trong Các Nhiệm Vụ Khác Nhau:
- Khi sử dụng ToT, các nhiệm vụ khác nhau yêu cầu xác định số lượng ứng viên và số lượng suy nghĩ/bước.
- Ví dụ, trong bài toán Game of 24 được sử dụng như một nhiệm vụ lý luận toán học, cần phân chia suy nghĩ thành 3 bước, mỗi bước liên quan đến một phương trình trung gian. Ở mỗi bước, giữ lại b=5 ứng viên tốt nhất.
- Thực Hiện Tìm Kiếm Theo Chiều Rộng (BFS) trong ToT cho Nhiệm Vụ Game of 24:
- Đánh Giá Các Ứng Viên Suy Nghĩ:
- Mô hình ngôn ngữ (LM) được hướng dẫn đánh giá từng ứng viên suy nghĩ là "chắc chắn/có thể/không thể" với mục tiêu đạt được 24. -Theo các tác giả, "mục tiêu là thúc đẩy các giải pháp từng phần đúng đắn có thể được xác nhận trong vài lần thử nghiệm dự đoán, và loại bỏ các giải pháp từng phần không thể dựa trên cảm giác thông thường "quá lớn/nhỏ", và giữ lại các giải pháp "có thể".
- Lấy Mẫu Giá Trị:
- Giá trị được lấy mẫu 3 lần cho mỗi suy nghĩ.
- Đánh Giá Các Ứng Viên Suy Nghĩ:
- Dưới đây là quy trình thực hiện minh họa:

Tóm Lại, Khi sử dụng Tree of Thoughts (ToT), việc xác định số lượng ứng viên và số lượng suy nghĩ/bước là rất quan trọng. Trong ví dụ Game of 24, suy nghĩ được phân chia thành 3 bước với mỗi bước giữ lại 5 ứng viên tốt nhất. Quá trình này bao gồm việc đánh giá các ứng viên suy nghĩ qua nhiều bước và loại bỏ các giải pháp không khả thi, nhằm mục đích đạt được giải pháp đúng đắn một cách hiệu quả và có hệ thống.ông thể thực hiện được dựa trên lẽ thường “quá lớn/nhỏ” và giữ phần còn lại là “có thể””. Các giá trị được lấy mẫu 3 lần cho mỗi suy nghĩ. Quá trình này được minh họa dưới đây:
- Từ kết quả được báo cáo trong hình bên dưới, ToT vượt trội hơn đáng kể so với các phương pháp prompt khác:

- Bạn thể tham khảo code ở đây và ở đây
- So Sánh Giữa Yao et al. (2023) và Long (2023) về Tree of Thoughts (ToT):
- Ý Tưởng Chính của Yao et al. (2023) và Long (2023): Cả hai nghiên cứu của Yao et al. (2023) và Long (2023) đều nhắm tới việc nâng cao khả năng giải quyết các vấn đề phức tạp của mô hình ngôn ngữ lớn (LLM) thông qua việc tìm kiếm trên cấu trúc cây và sử dụng các cuộc trò chuyện nhiều vòng.
- Khác Biệt Chính
- Phương Pháp Tìm Kiếm Cây:
- Yao et al. (2023): Sử dụng các chiến lược tìm kiếm tổng quát như tìm kiếm theo chiều sâu (DFS), tìm kiếm theo chiều rộng (BFS), và tìm kiếm beam search.
- Long (2023): Sử dụng một chiến lược tìm kiếm cây được điều khiển bởi một "ToT Controller" được huấn luyện thông qua học tăng cường (reinforcement learning, RL).
- Chiến Lược Tìm Kiếm:
- DFS/BFS/Beam Search: Đây là các chiến lược tìm kiếm tổng quát không thích ứng với các vấn đề cụ thể. Chúng chỉ đơn thuần là các phương pháp duyệt qua không gian tìm kiếm mà không có khả năng học hỏi từ dữ liệu cụ thể.
- ToT Controller với Học Tăng Cường (RL): ToT Controller có thể học từ bộ dữ liệu mới hoặc thông qua việc tự chơi (như AlphaGo so với tìm kiếm brute force). Hệ thống ToT dựa trên RL có thể tiếp tục phát triển và học kiến thức mới ngay cả khi LLM cố định.
- Phương Pháp Tìm Kiếm Cây:
- Ưu Điểm của Mỗi Phương Pháp
- Phương Pháp của Yao et al. (2023):
- Đơn Giản và Hiệu Quả: Các chiến lược tìm kiếm như DFS, BFS, và beam search dễ triển khai và không cần huấn luyện thêm.
- Độ Tin Cậy: Đây là các phương pháp đã được chứng minh và sử dụng rộng rãi trong nhiều lĩnh vực.
- Phương Pháp của Long (2023):
- Khả Năng Thích Ứng Cao: ToT Controller được huấn luyện thông qua RL có thể thích nghi và học từ dữ liệu mới, giúp cải thiện hiệu suất giải quyết vấn đề theo thời gian.
- Tiến Hóa Liên Tục: Hệ thống này có thể tiếp tục học và nâng cao khả năng của mình thông qua việc tự chơi hoặc học từ các bộ dữ liệu mới.
- Phương Pháp của Yao et al. (2023):
Tóm Lại, Yao et al. (2023) và Long (2023) đều hướng tới việc cải thiện khả năng giải quyết các vấn đề phức tạp của LLM thông qua cấu trúc cây và các cuộc trò chuyện nhiều vòng. Tuy nhiên, điểm khác biệt chính nằm ở chiến lược tìm kiếm cây: Yao et al. sử dụng các phương pháp tìm kiếm tổng quát (DFS, BFS, beam search), trong khi Long sử dụng một ToT Controller được huấn luyện thông qua RL, cho phép hệ thống tự học và phát triển liên tục.
So Sánh Giữa "Chain of Thought" và "Tree of Thought" Prompting
-
Chain of Thought Prompting (CoT) và Tree of Thought Prompting (ToT) là hai phương pháp được sử dụng để nâng cao hiệu suất của các mô hình ngôn ngữ lớn (LLM) như GPT-3 hoặc GPT-4, đặc biệt trong các nhiệm vụ phức tạp đòi hỏi suy luận hoặc giải quyết vấn đề theo nhiều bước. Dưới đây là sự khác biệt giữa hai phương pháp này, cũng như khi nào nên sử dụng mỗi phương pháp.
-
Chain of Thought Prompting (CoT)
- Nguyên Lý:
- CoT giúp mô hình ngôn ngữ "suy nghĩ" bằng cách viết ra các bước trung gian hoặc quá trình lý luận dẫn đến câu trả lời.
- Phương pháp này khuyến khích mô hình tuân theo một chuỗi các bước logic để đi đến kết luận.
- Sử Dụng:
- Hữu ích cho các bài toán phức tạp như bài toán từ toán học, nơi mà chỉ đơn thuần đưa ra vấn đề không cung cấp đủ hướng dẫn cho mô hình.
- Bằng cách bao gồm chuỗi lý luận, mô hình được khuyến khích tuân theo một cách tiếp cận từng bước tương tự.
- Ví Dụ:
- Đối với một bài toán toán học, prompt sẽ bao gồm cả vấn đề và một giải thích chi tiết tuần tự về cách giải quyết, hướng dẫn mô hình qua quá trình suy luận.
- Nguyên Lý:
-
Tree of Thought Prompting (ToT)
- Nguyên Lý:
- ToT là một phương pháp tinh vi hơn, trong đó nhiều dòng lý luận được xem xét song song. Nó giống như tạo ra một cây quyết định, trong đó mỗi nhánh đại diện cho một con đường suy nghĩ hoặc một khía cạnh khác của vấn đề.
- Sử Dụng:
- Hữu ích cho các vấn đề có thể có nhiều cách tiếp cận hợp lệ hoặc khi lĩnh vực của vấn đề liên quan đến việc xử lý các khả năng và kết quả phân nhánh.
- Ví Dụ:
- Trong một kịch bản phức tạp với nhiều biến số hoặc kết quả khả thi, prompt sẽ bao gồm việc khám phá các con đường khác nhau, như xem xét các nguyên nhân khác nhau cho một hiện tượng trong một vấn đề khoa học.
- Nguyên Lý:
-
So Sánh và Hiệu Quả
- Độ Phức Tạp:
- ToT: Phức tạp hơn vì nó bao gồm việc xem xét nhiều dòng lý luận đồng thời. Nó toàn diện hơn nhưng cũng khó cấu trúc hiệu quả hơn.
- CoT: Đơn giản hơn và có thể áp dụng cho nhiều loại vấn đề, đặc biệt là nơi mà cách tiếp cận từng bước là có lợi.
- Tính Ứng Dụng:
- CoT: Thường dễ hiểu hơn và có thể áp dụng cho nhiều loại vấn đề, đặc biệt là nơi cần một cách tiếp cận tuyến tính, từng bước.
- ToT: Thích hợp hơn cho các kịch bản có khả năng phân nhánh, nơi cần xem xét nhiều yếu tố hoặc kết quả.
- Hiệu Quả:
- CoT: Thường hiệu quả hơn đối với các vấn đề đơn giản, vì nó trực tiếp hơn.
- ToT: Cung cấp sự khám phá toàn diện hơn về không gian vấn đề đối với các vấn đề phức tạp, đa chiều.
- Độ Phức Tạp:
-
Kết Luận: Phương Pháp Nào Tốt Hơn? Sự lựa chọn giữa CoT và ToT phụ thuộc vào bản chất của nhiệm vụ:
- Chain of Thought (CoT): Phù hợp cho hầu hết các nhiệm vụ giải quyết vấn đề đơn giản và dễ quản lý hơn.
- Tree of Thought (ToT): Thích hợp cho các vấn đề phức tạp, đa chiều, nơi cần đánh giá nhiều giả thuyết hoặc kịch bản khác nhau.
Tóm Lại, Cả hai phương pháp đều nhằm cải thiện khả năng suy luận của các mô hình ngôn ngữ bằng cách hướng dẫn chúng qua một quá trình suy nghĩ có cấu trúc. Sự lựa chọn phương pháp nào nên dựa trên yêu cầu cụ thể của vấn đề đang được giải quyết.
Chain-of-Verification (CoVe)
- Trong LLMs thường gặp vấn đề tạo ra những thông tin nghe thì hợp lý nhưng thực tế không chính xác, gọi là ảo giác (hallucination) vẫn luôn là vấn đề nhức nhối trong LLMs.
- Dhuliawala et al. đề xuất bài nghiên cứu "Chain-of-Verification Reduces Hallucination in Large Language Models" nghiên cứu khả năng của các mô hình ngôn ngữ lớn trong việc cân các phản hồi mà chúng đưa ra để sửa lỗi.
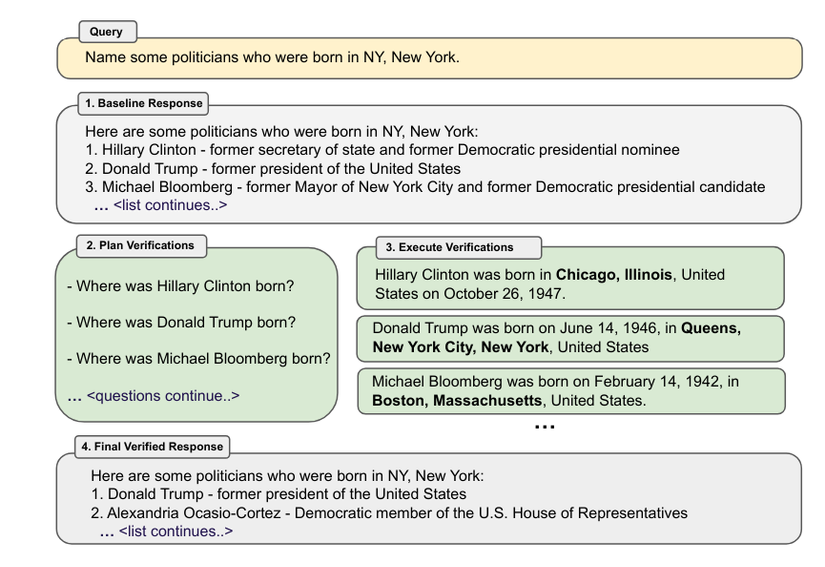
- Họ phát triển phương pháp Chain-of Verification (CoVe), theo đó (i) đầu tiên mô hình draft một response ban đầu; sau đó (ii) tạo ra các câu hỏi xác minh (plan verifications) để kiểm tra tính thực tế của bản draft ban đầu; (iii) trả lời các câu hỏi đó một cách độc lập để các câu trả lời không bị bias bởi những phản hồi của các câu hỏi khác; và cuối cùng (iv) tạo ra response cuối được verified.
- Ví dụ minh họa lấy từ paper đề cập trên về phương pháp CoVe bạn có thể tham khảo
Vô vàn kỹ thuật khác
Trong 2 bài viết về Prompt Engineering mình có list những kỹ thuật hay được áp dụng trong phát triển các dự án thực tế. Ngoài ra, còn rất nhiều kỹ thuật bạn có thể tham khảo thêm dựa trên keywords mình liệt kê bổ sung cho mọi người tự tìm hiểu nhé.
- Graph-of-Thought (GoT) Prompting
- Skeleton-of-Thought Prompting
- Least-to-Most Prompting
- ReAct Prompting
- Active-Prompt
- Instruction Prompting and Tuning
- Recursive Prompting
- Automatic Prompt Engineer (APE)
- Automatic Reasoning and Tool-use (ART)
- Chain-of-Note (CoN) Prompting
- Chain-of-Knowledge (CoK) Prompting
- Chain-of-Code (CoC) Prompting
- Chain-of-Symbol (CoS) Prompting
- Structured Chain-of-Thought (SCoT) Prompting
- Contrastive Chain-of-Thought (CCoT) Prompting
- Logical Chain-of-Thought (LogiCoT) Prompting
- System 2 Attention Prompting
- Emotion Prompting
- Thread of Thought (ThoT) Prompting
- Program of Thoughts (PoT) Prompting
- Optimization by Prompting (OPRO)
- Rephrase and Respond (RaR) Prompting
- Scratchpad Prompting
- Take a Step Back Prompting
- Ask Me Anything Prompting
- Promptbreeder
All rights reserved
