ChatGPT Series 6: Multimodal RAG và Những phương pháp được nghiên cứu để cải thiện chất lượng hệ thống RAG
Bài đăng này đã không được cập nhật trong 2 năm
Chúc mừng năm mới 2024 đến toàn thể cộng đồng ViBLO!
Tiếp tục serries về ChatGPT, ở ChatGPT Series 5 mình có đề cập tới một góc nhìn theo chiều rộng về RAG, bạn xem thêm ở đây nhé. Bài viết tiếp theo mình sẽ đề cập tới khía cạnh Multimodal RAG và những phương pháp được nghiên cứu để cải thiện hệ thống RAG.
Multimodal RAG
-
Trong thực tế thì nhiều tài liệu chứa hỗn hợp các loại nội dung trong đó, có thể bao gồm cả dạng văn bản và ảnh. Tuy nhiên, thông được nắm bắt trong hình ảnh sẽ bị mất (bỏ qua) trong hầu hết ứng dụng RAG. Với sự nổi lên của Multimodal LLM, chẳng hạn như GPT-4, chúng ta cũng cần xem xét sử dụng kết hợp thông tin hình ảnh trong hệ thống RAG.
-
Trong framework LangChain cũng hỗ trợ việc sử dụng kết hợp hình ảnh. Ba cách để sử dụng có thể thử:
- Option 1:
- Sử dụng multimodal embedding (chẳng hạn như CLIP) để embed ảnh và text.
- Retrieval sử dụng similarity search.
- Đưa ảnh và các đoạn text qua mô hình Multimodal LLM để tổng hợp câu trả lời.
- Option 2:
- Sử dụng Multimodal LLM (chẳng hạn như GPT-4, LLaVA, or FUYU-8b) để tạo text tóm tắt từ ảnh.
- Embed và retrieve text.
- Đưa các đoạn text vào mô hình LLM để tổng hợp câu trả lời.
- Option 3:
- Sử dụng Multimodal LLM (chẳng hạn như GPT-4, LLaVA, or FUYU-8b) để tạo text tóm tắt từ ảnh.
- Embed và retrieve các bản tóm tắt ảnh có reference tới raw image. Có thể sử dụng multi-vector retriever với Vector DB chẳng hạn như Chroma để lưu trữ raw text và images cùng với bản tóm tắt của chúng để retrieval.
- Đưa raw images và các đoạn text liên quan tới một mô hình Multimodal LLM để tổng hợp câu trả lời.
- Option 1:
-
Option 2 phù hợp khi không thể sử dụng Multimodal LLM để sinh ra câu trả lời do các vấn đề như chi phí, hạ tầng, ...
-
Tổng quan về cả 3 options nói trên được mô tả hình dưới đây. Nguồn
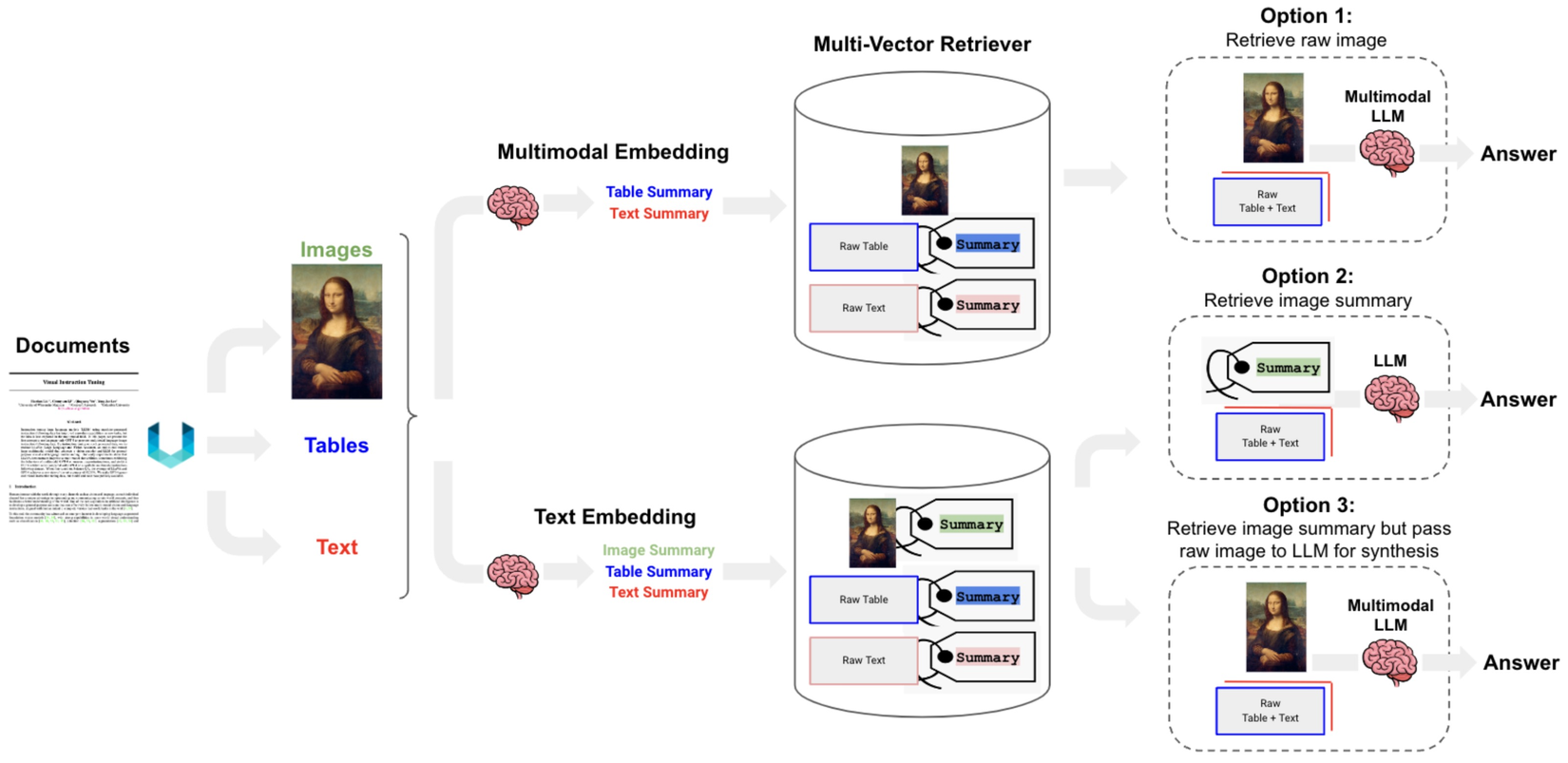
- Mọi người có thể thử nghiệm qua Langchain, họ có cung cấp 1 cookbooks cho Option 1 vs Option 3.
- Minh họa tổng quan Multimodal RAG:
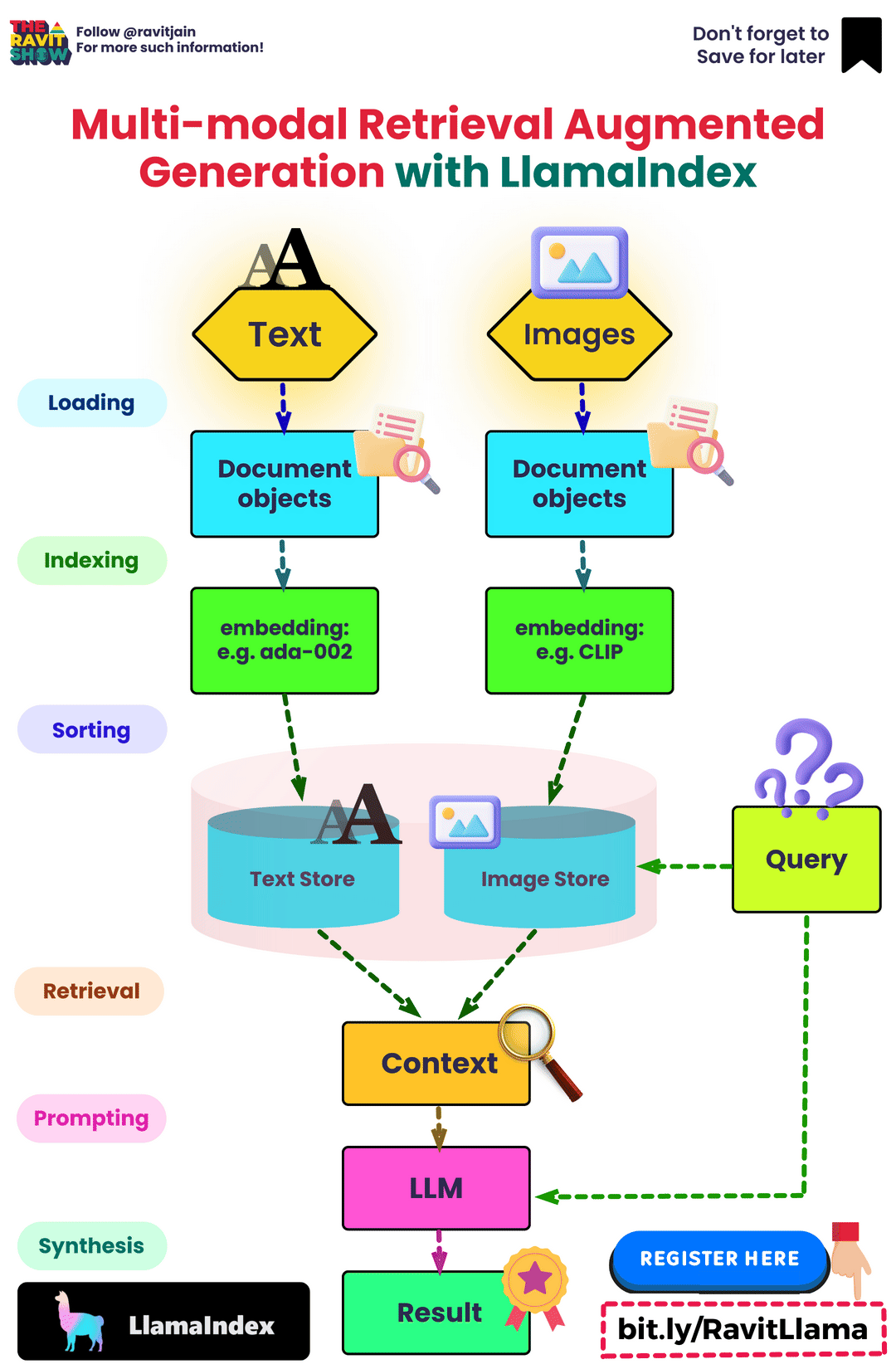
Một số phương pháp nghiên cứu để cải thiện hệ thống RAG
-
Để nâng cao và cải tiến hệ thống RAG, có một số phương pháp mình thấy được refer và sử dụng nhiều trong triển khai thực tế:
- Re-ranking Retrieved Results: Một phương pháp cơ bản và hiệu quả bao gồm việc sử dụng Mô hình xếp hạng lại để tinh chỉnh các kết quả thu được thông qua truy xuất ban đầu. Cách tiếp cận này ưu tiên các kết quả phù hợp hơn, từ đó cải thiện chất lượng tổng thể của nội dung được tạo ra. MonoT5, MonoBERT, DuoBERT, v.v. là những ví dụ về các mô hình DL có thể được sử dụng làm re-ranker. Để khám phá kỹ về kỹ thuật này, bạn tham khảo hướng dẫn và ví dụ ở đây
- FLARE Technique: Sau khi reranking, người ta đưa ra thêm phương pháp FLARE. Kỹ thuật này truy vấn động trên internet (cũng có thể là cơ sở tri thức cục bộ) bất cứ khi nào mức độ tin cậy của một phân đoạn nội dung được tạo giảm xuống dưới ngưỡng được chỉ định. Điều này khắc phục được hạn chế đáng kể của các hệ thống RAG thông thường, vốn thường chỉ truy vấn cơ sở tri thức ngay từ đầu và sau đó tạo ra kết quả cuối cùng. Bạn có thể xem thêm cách ứng dụng thực tế của kỹ thuật này ở đây.
- HyDE Approach: Kỹ thuật HyDE giới thiệu một khái niệm đổi mới về việc tạo ra một document giả định để đáp lại một truy vấn. Document này sau đó được chuyển đổi thành một embedding vector. Điểm độc đáo của phương pháp này nằm ở việc sử dụng vectơ để xác định vùng lân cận tương tự trong corpus không gian embedding, từ đó truy xuất các document thực tương tự dựa trên độ tương tự của vectơ. Để tìm hiểu kỹ hơn về phương pháp này, bạn tham khảo hướng dẫn và triển khai code ở đây.
- Chain-of-note: CHAIN-OF-NOTING, được thiết kế để nâng cao độ bền của RAG. Nền tảng của CON là tạo ra một loạt ghi chú đọc cho các tài liệu được truy xuất, cho phép đánh giá toàn diện mức độ liên quan của chúng với truy vấn đầu vào. Cách tiếp cận này không chỉ đánh giá mức độ phù hợp của từng tài liệu mà còn xác định chính xác thông tin quan trọng và đáng tin cậy nhất trong đó. Quá trình này lọc ra một cách hiệu quả những nội dung không liên quan hoặc kém tin cậy hơn, dẫn đến những phản hồi chính xác hơn và phù hợp với ngữ cảnh hơn. Ngoài ra, CON còn nâng cao khả năng của RAG để xử lý các truy vấn nằm ngoài phạm vi dữ liệu huấn luyện của chúng. Trong trường hợp tài liệu được truy xuất không cung cấp bất kỳ thông tin liên quan nào, CON có thể hướng dẫn mô hình thừa nhận các hạn chế của nó và phản hồi ở dạng "unknown" hoặc đưa ra lời giải thích tốt nhất có thể dựa trên dữ liệu có sẵn, nâng cao độ tin cậy của mô hình. Paper
- Self-RAG: Mô hình Self-RAG được đào tạo để tạo đầu ra văn bản có nhiều phân đoạn (đoạn là một câu). Các phân đoạn này bao gồm cả từ vựng gốc và mã thông báo phản ánh đặc biệt. Trong quá trình suy luận, mô hình sẽ quyết định có lấy thêm thông tin hay không. Nếu việc truy xuất là không cần thiết, nó sẽ tiến hành giống như một mô hình ngôn ngữ chuẩn. Nếu cần truy xuất, mô hình sẽ đánh giá mức độ liên quan của đoạn được truy xuất, độ chính xác của phân đoạn phản hồi và tiện ích tổng thể của phản hồi bằng cách sử dụng mã thông báo phê bình. Mô hình có thể xử lý đồng thời nhiều đoạn và sử dụng mã thông báo phản chiếu để được hướng dẫn. Paper
-
Mỗi phương pháp này cung cấp một cách tiếp cận riêng để tinh chỉnh hệ thống RAG, góp phần mang lại kết quả chính xác hơn và phù hợp với ngữ cảnh hơn. Để nói sâu về các kỹ thuật trên có thể sẽ cần nhiều hơn, chính vì thế trong nội dung bài viết này chủ yếu mình tập trung vào các keywords để các bạn có thể có 1 số hướng nghiên cứu cho những giải pháp cải thiện cho hệ thống RAG trong các ứng dụng thực tế.
All rights reserved
