
Chập chững tìm hiểu về Data Science
Bài đăng này đã không được cập nhật trong 3 năm
Data Science là cái tên có lẽ không còn quá xa lạ với mọi người. Một lĩnh vực lớn làm việc với Data mà chắc hẳn rất nhiều người tò mò. Đang đứng ở công việc với AI, thì cứ nghĩ là mình đang tìm hiểu một lĩnh vực mới, nhưng xem xét lại mới thấy mình cũng là 1 phần của Data Science. Với mong muốn cùng tìm hiểu, chia sẻ, trao đổi và trau dồi kiến thức trên nền tảng Viblo, mình xin phép chia sẻ bài viết đầu tiên của mình về Series Data Science. Do là kiến thức mới cũng như chưa có nhiều kinh nghiệm, bài viết này hay cả các bài viết sau này của mình sẽ có nhiều thiếu sót, rất mong được sự góp ý của bạn đọc.
Nào chúng ta bắt đầu thôi!

Data - biết nhưng không biết mô tả sao?
Chắc hẳn mọi người đều nghe nhiều về từ này, từ đủ mọi lĩnh vực, nhưng đôi khi được hỏi "Data là gì?" thì đa số (hay như mình) chỉ trả lời rằng "Data là dữ liệu" :>>
Mình có được đọc một khái niệm rất thú vị về Data như này, “Data is just collection of facts”. Cụ thể mọi người hiểu thế nào có thể chia sẻ dưới bình luận nhé.
Data trước đây thì tương đối nhỏ, hạn hẹp, và thường có cấu trúc rõ ràng. Còn hiện nay, data lại vô cùng lớn, hay nói nhẹ hơn là khổng lồ, dưới định dạng cả có cấu trúc (structured) và không cấu trúc (Unstructured ). Có câu "Kẻ nắm giữ nhiều dữ liệu nhất, kẻ đó mang quyền năng vô hạn" (Mình cũng không nhớ nghe ở đâu, và có chính xác vậy không, chỉ nhớ mang máng ý như vậy). Các bạn có thể không tin nhưng cứ nhìn con ChatGPT đang sốt gần đây xem, đọc về nó để biết nó đã học bao nhiêu dữ liệu. Vậy Data có ý nghĩa gì mà nó mạnh mẽ đến vậy, cùng điểm qua một chút nhé
- Dữ liệu mô tả trạng thái hiện tại của chúng ta
- Dữ liệu có thể giúp phát hiện các điều bất thường
- Dữ liệu có thể chẩn đoán nguyên nhân của các sự kiện hay hành vi được quan sát
- Dữ liệu có thể dự đoán các sự kiện trong tương lai
Chính vì phát hiện ra ý nghĩ nó như vậy nên việc thu thập dữ liệu đang ngày một gia tăng. Các ông lớn như Google sớm đã nhìn ra điều này nên luôn đi trước. Từ đó những ngành nghề mới (gọi là mới cũng không đúng vì bản chất thì là những công việc chuyên sâu hơn) làm việc với Data hình thành.
Vậy Data science là gì và tại sao nó quan trọng?
- Khoa học dữ liệu là lĩnh vực nghiên cứu dữ liệu nhằm khai thác những thông tin chuyên sâu có ý nghĩa. Đây là một phương thức tiếp cận đa ngành, kết hợp những nguyên tắc và phương pháp thực hành của các lĩnh vực toán học, thống kê, trí tuệ nhân tạo và kỹ thuật máy tính để phân tích khối lượng lớn dữ liệu. Nội dung phân tích này sẽ giúp các nhà khoa học dữ liệu đặt ra và trả lời những câu hỏi như sự kiện gì đã xảy ra, tại sao nó xảy ra, sự kiện gì sẽ xảy ra và có thể sử dụng kết quả thu được cho mục đích gì.
- Ngày nay, có thể nói mọi hoạt động của chúng ta đều được lưu trữ lại. Từ những cú click chuột, dừng lại xem 1 đoạn video tiktok hay thậm chí ngồi nói chuyện với bạn bè. Đã có khi mình mới chỉ nhắc đến trời hôm nay dễ mưa với bạn bè, mà mở FB lên toàn thấy quảng cáo bán áo mưa =))). Lúc ấy kiểu: quái lại, giờ nói chuyện cũng bị theo dõi, mà nó còn nghĩ luôn trước xem mình định mua gì ư? Những việc này không hoàn toàn được coi là đánh cắp thông tin hay vi phạm riêng tư, bởi mỗi khi bạn cài đặt 1 app như FB hay IG thì sẽ luôn có một cam kết, xong rồi yêu cầu mình đồng ý mới cho tiếp tục cài đặt sử dụng - Cái mà mọi người hầu như "Accept" luôn mà không cần đọc, trong đó sẽ chứa nội dung kiểu: Ông dùng của tôi, thì cho phép tôi quan sát hành vi của ông để cho ông những trải nghiệm tốt nhất nhé :v
Bốn bước trong Data science
Nhìn chung, sẽ có 4 bước lớn khi triển khai một bài toán trong Data Science. Các bước này có thể được phân nhỏ ra khiến số bước này tăng lên. Bốn bước mình đang muốn nhắc đến đó là:
-
Data collection & Storage:
- Thu thập dữ liệu có thể từ nhiều nguồn khác nhau
- Tổ chức lưu trữ theo cách an toàn và có thể truy cập được.
-
Data preparation: Bước làm sạch dữ liệu thô để tiến hành sử dụng. Một số bước làm sạch cơ bản có thể kế tới như
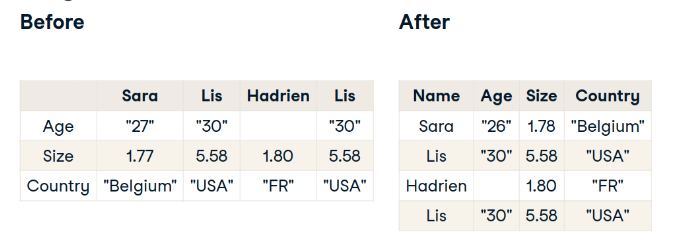
- Tiny data: trình bày 1 ma trận dữ liệu, với các quan sát trên các hàng và các biến dưới các cột
![image.png]()
- Loại bỏ các Duplicates
- Sử dụng ID để phân biệt
- Đồng bộ tiêu chuẩn (Homogeneity)
- Xử lý các giá trị bị thiếu (Missing)
- Tiny data: trình bày 1 ma trận dữ liệu, với các quan sát trên các hàng và các biến dưới các cột
-
Explore & Visualize:
-
Khai phá dữ liệu và trực quan hóa dữ liệu để rút ra những tri thức hay nhận xét cần thiết
-
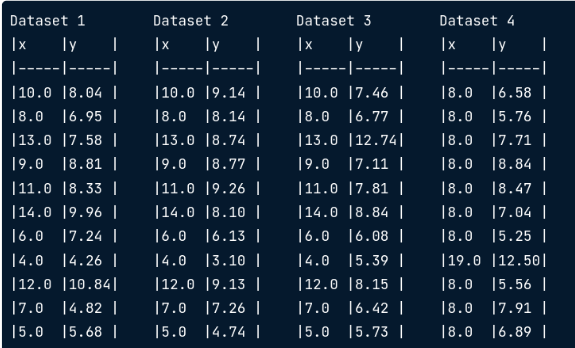
Dữ liệu ban đầu cung cấp ít thông tin; Thống kê mô tả làm tốt hơn nhưng có thể gây hiểu lầm; Trực quan hóa và phân tích chỉ cho chúng ta nhiều nhất. Có thể xem một ví dụ như sau
![image.png]()
-
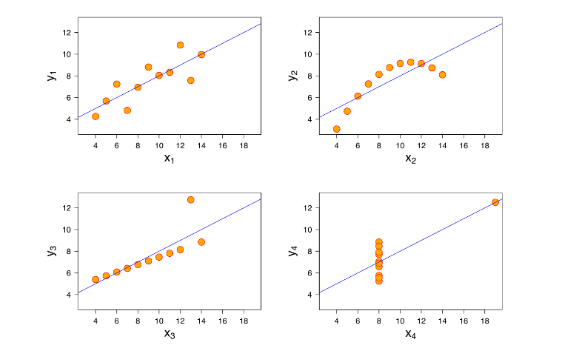
4 bảng có giá trị trung bình và phương sai giống hệt nhau đối với và , có hệ số tương quan giống nhau. Chúng có vẻ giống nhau vậy rồi có ý nghĩa gì?
-
Thử trực quan hóa nó lên nhé
![image.png]()
-
-
Experimentation & Prediction: Thử nghiệm phương pháp và tiến hành các dự đoán cho bài toán.
Data science roles
Cùng với 4 bước trong Data Science, có 4 công việc chính: Data Engineer, Data Analysis, Data Scientist và Machine Learning Scientist
Data Engineer
- Điều khiển luồng dữ liệu: xây dựng các data pipelines và hệ thống lưu trữ
- Thiết kế cơ sở hạ tầng để dữ liệu dễ dàng thu thập và xử lý
- Thường tập trung vào giai đoạn đầu tiên: Data collection & Storage
- Kỹ năng thông thạo SQL, sử dụng các ngôn ngữ lập trình như Java, Scala hoặc Python để xử lý dữ liệu
- Biết sử dụng Shell command cho các tác vụ tự động hóa
- Hiện nay nhóm này cần thông thạo với điện toán đám mây và lưu trữ dữ liệu lớn: AWS, Azure, Google Cloud Platform
Data Analysis:
- Mục tiêu khám phá dữ liệu và trực quan hóa dữ liệu
- Ít kinh nghiệm lập trình và thống kê hơn 3 nhóm còn lại
- Tập trung vào 2 giai đoạn Data Preparation và Ex&Viz
- Sử dụng SQL để truy vấn dữ liệu, tổng hợp để phân tích
- Sử dụng các công cụ BI (Business Intelligent) như Tableau, Power BI để thể hiện sự phân tích của họ
- Nhóm này cũng có thể sử dụng Python hoặc R để tiền xử lý cũng như phân tích dữ liệu
Data Scientist:
- Nhóm này có nền tảng vững chắc về thống kê nhất
- Thường sử dụng học máy truyền thống để dự đoán
- Tập trung vào 3 giai đoạn cuối
- Kỹ năng tốt về SQL, ít nhất 1 trong 2 ngôn ngữ Python hoặc R cần thông thạo
Machine Learning Scientist:
- Giống Data Scientist nhưng chuyên ngành học máy sâu hơn
- Ngoại suy những gì có thể đúng với những gì chúng ta đã biết
- Sử dụng Python hoặc R để đào tạo mô hình dự đoán
- Nhóm này thiết kế các mô hình học máy, học sâu cho phù hợp với bài toán về dữ liệu
Có thể thấy, khi bạn đang đứng một vai trò hay làm các dự án về AI, thông thường dữ liệu sẽ tương đối có sẵn, công việc của bạn sẽ có việc làm sạch dữ liệu, phân tích dữ liệu, thiết kế mô hình, đánh giá và deploy. Như vậy bạn cũng đã thực hiện phần nhỏ công việc của 1 Data Analysis hay Data Scientist

Không bắt buộc cả 4 roles
Ở mỗi công ty thì lại có những kiểu định nghĩa khác roles khác nhau, ví dụ như có công ty chỉ có 1 ông Data Scientist cân tất khi dữ liệu đã được tổ chức tương đối ổn định. Các roles mình nêu trên chỉ mang tính tương đối, ngoài ra còn 1 roles nữa đó là Business Analyst, roles này chủ yếu làm việc với khách hàng để hiểu nghiệp vụ kinh doanh
Bạn mình có tổng kết lại một chút về 4 roles trên qua hình vẽ dưới đây
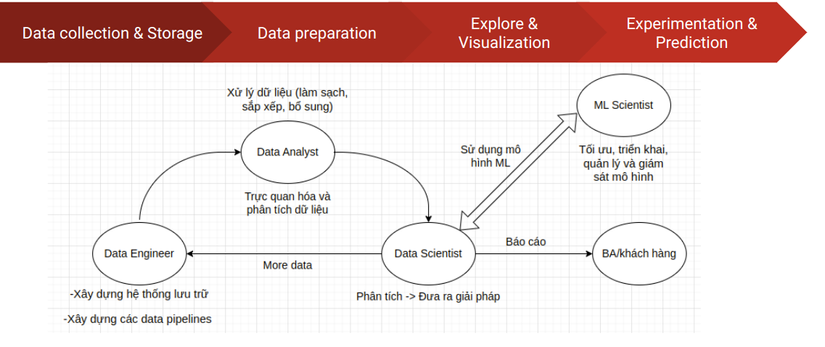
Data sources
- Nhiều nguồn từ các công ty, doanh nghiệp, free sources
- Một số nguồn data phổ biến:
- Web events: các thao tác trên web
- Survey data: hỏi mọi người bằng các bảng khảo sát, …
- Public data APIs: nhiều công ty có các API công khai cho phép bất kì ai truy cập vào dữ liệu của họ như Twitter, Wikipedia, …
- Public records: được thu thập và chia sẻ bởi các tổ chức quốc tế như Ngân hàng thế giới, Liên hợp quốc hoặc WTO, … các thông tin như thời tiết, môi trường, dân số, báo cáo tài chính, …
Tổng kết
Trong bài viết đầu tiên, mình đã chia sẽ những kiến thức tổng quan mình học được về Data Science. Cụ thể về các phần bên trong, mình sẽ học và chia sẻ thêm ở các bài viết sau. Mình rất mong nhận được những phản hồi và góp ý từ bạn đọc để việc học tập tốt hơn.
Tài liệu tham khảo
All rights reserved
