Cách tôi thay thế LLM API đắt đỏ bằng Rule-Based NLP Engine 100% Offline (Độ trễ 0ms)
Vì sao tự build một Domain-Specific Rule-Based Engine hoàn toàn bằng JavaScript lại là quyết định kiến trúc chuẩn xác nhất cho dự án Open Source của mình.
🔗 Live Demo: nodejs-quickstart-generator.netlify.app
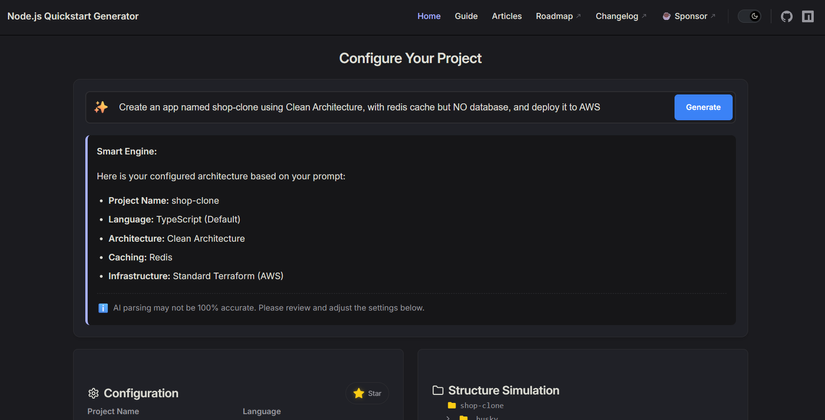
Nếu bạn đang làm một project Open Source trong năm 2024, có một áp lực vô hình là bằng mọi giá phải gắn cái OpenAI API key vào và gọi sản phẩm của mình là "AI-powered".
Với project mới nhất của mình — một công cụ tự động hóa cấu trúc (scaffolding) chuyên sâu cho Node.js — mình muốn người dùng có thể cấu hình các microservices bằng ngôn ngữ tự nhiên. Ví dụ: "Tạo cho tôi một project Clean Architecture dùng TypeScript, PostgreSQL và Kafka, nhưng không cần CI/CD."
Giải pháp tiêu chuẩn hiện nay của ngành? Gửi cái prompt đó tới một mô hình LLM, đợi 3-5 giây và parse cục JSON trả về.
Nhưng khi đối mặt với thực tế phải deploy hệ thống này cho hàng ngàn người dùng, mình đụng phải một bức tường lớn:
- Chi phí cho cái mác "Hype AI": Là một maintainer của dự án open-source, việc tự bỏ tiền túi gánh chi phí API cho từng prompt của người dùng chẳng khác nào "tự sát" về tài chính.
- Độ trễ mạng (Network Latency): Bắt người dùng đợi 3-5 giây cho một API call sẽ phá hỏng hoàn toàn trải nghiệm tức thời, mượt mà mà một web tool hiện đại cần có.
- Rủi ro "Ảo giác" (Hallucination): Khi bạn cấu hình kiến trúc phần mềm (như Terraform scripts hay database orchestrations), chỉ một config bịa ra (hallucinated) cũng có thể làm sập toàn bộ project. Mình cần output mang tính quyết định (100% deterministic), chứ không phải những suy đoán sáng tạo của AI.
Vì vậy, mình quyết định vứt bỏ cách tiếp cận bằng LLM. Thay vào đó, mình tự build một Domain-Specific Rule-Based AI Engine chạy hoàn toàn ở phía Client (Browser).
Dưới đây là cách mình đạt được độ trễ 0ms và $0 chi phí vận hành mà không làm mất đi khả năng hiểu ngôn ngữ tự nhiên của tool.
Cơ chế cốt lõi: Mang mọi thứ từ Cloud xuống Browser
Thay vì phụ thuộc vào các deep learning models, Engine của mình hoạt động dựa trên các nguyên tắc đã được xác minh toán học và tối ưu cao độ. Nó được viết hoàn toàn bằng JavaScript thuần và ship trực tiếp xuống trình duyệt.
1. Tối ưu Regex & Bài toán "Code-Switching"
Tập người dùng của mình là toàn cầu. Họ không chỉ nói tiếng Anh; họ mix tiếng Anh với tiếng Việt, tiếng Nhật, tiếng Trung, tiếng Hindi — thường là trong cùng một câu (hiện tượng này gọi là Code-switching).
Thay vì phải train một model hiểu 50 ngôn ngữ, mình map các "ý định kỹ thuật" (technical intents) và các "mẫu phủ định" (negative patterns) xuyên suốt các ngôn ngữ bằng các biểu thức Regular Expressions (Regex) được tinh chỉnh cực kỳ kỹ lưỡng.
Hãy xem cách Engine xử lý câu phủ định: Github
// Check từ khóa phủ định đứng TRƯỚC (Quét lùi tối đa 30 ký tự trước từ khóa chính)
const isNegativeBefore = /(?:no|without|không|khong|don't|dont|skip|remove|ko|đừng|khỏi|不要|不|无|没|bina)\s*$/i.test(beforeText.trim());
// Check từ khóa phủ định đứng SAU (Cần thiết cho cấu trúc tiếng Nhật 'なし' / tiếng Hindi 'nahi')
const isNegativeAfter = /^\s*(?:は|が|を)?\s*(?:nahi|なし|ない|いらない)/i.test(afterText);
Bất kể người dùng gõ "không dùng db" (tiếng Việt), "no database" (tiếng Anh), hay "不要 db" (tiếng Nhật), Engine đều parse nó y hệt nhau. Nó hoạt động như một cỗ máy tokenizer kỹ thuật không biết mệt mỏi, trích xuất chính xác những gì cần thiết đồng thời chủ động sanitize inputs để loại bỏ hoàn toàn rủi ro XSS.
2. Deterministic State Machine (Ánh xạ 1 triệu trạng thái)
Bảo một con AI sinh ra code từ con số 0 là rất rủi ro. Thay vào đó, NLP Engine của mình ánh xạ "ý định của người dùng" thẳng vào một Deterministic State Machine (Máy trạng thái quyết định).
Hệ thống scaffolding ẩn bên dưới có chính xác 1,064,448 trạng thái kiến trúc đã được verify (bao gồm các tổ hợp của Databases, Message Brokers, Cloud Providers, v.v.).
NLP Engine sẽ đánh giá các keyword kỹ thuật trích xuất được dựa trên một ma trận logic cấu hình sẵn này. Nó chọn ra chính xác một cấu hình an toàn, đã được verify. Không có "có lẽ", không có "ảo giác" — chỉ có sự chính xác tuyệt đối.
Kết quả: Nhanh, Miễn phí và Hoàn hảo
Bằng cách bước ra khỏi chuyến tàu hype của LLM và tự tay engineer một Local Heuristic NLP Engine, kết quả đạt được thực sự vượt ngoài mong đợi:
- Thời gian phản hồi 0ms: Toàn bộ quá trình parsing diễn ra ngay tại trình duyệt của người dùng trong nháy mắt.
- $0 Chi phí vận hành trọn đời: Không API keys, không tốn tiền thuê server xử lý, không bị rate limits.
- Bảo mật riêng tư tuyệt đối: Không có bất kỳ prompt hay lựa chọn kiến trúc nào của user bị gửi đến server của bên thứ ba.
- Khả năng chạy 100% Offline: Bạn theo nghĩa đen có thể rút dây mạng ra, load bản PWA đã lưu trong cache, và NLP Engine vẫn sẽ tiếp tục parse prompt mượt mà không trượt phát nào.
Bài học rút ra
Large Language Models (LLMs) là những công cụ tuyệt vời cho các tác vụ mang tính sáng tạo (generative). Nhưng đối với các bài toán điều hướng (routing) mang tính đặc thù và yêu cầu tính quyết định (deterministic), chúng ta thường hay "over-engineer" vấn đề. Đôi khi, một con "AI" thanh lịch nhất, dễ scale nhất và tiết kiệm chi phí nhất lại chính là thứ được tạo ra từ những bộ rules chặt chẽ, những đoạn regex thông minh và 0 dependencies từ server.
Tự mình trải nghiệm NLP engine offline 0ms này nhé: Thử ngay bản Web UI v2.6.0 mới nhất tại Node.js Quickstart Generator.
Nguồn từ: I Replaced a Costly LLM API with a 100% Offline NLP Engine (And Achieved 0ms Latency
All rights reserved
