Cách Pinterest đạt tới 11 triệu người dùng chỉ với 6 kỹ sư
Bài đăng này đã không được cập nhật trong 2 năm
Pinterest là một mạng xã hội tập trung vào hình ảnh, nơi người dùng có thể lưu hoặc "ghim" hình ảnh vào các bảng của họ.
Vào tháng Giêng năm 2012, Pinterest đạt được cột mốc 11,7 triệu người dùng hoạt động hàng tháng chỉ với 6 kỹ sư.
Ra mắt vào tháng 3 năm 2010, Pinterest là công ty nhanh nhất thời điểm đó đạt được 10 triệu người dùng hoạt động hàng tháng.
Bài học từ quá trình mở rộng quy mô của Pinterest
- Sử dụng công nghệ đã được kiểm chứng và tin cậy. Pinterest từng thử nghiệm những công nghệ mới mẻ hơn nhưng gặp phải nhiều vấn đề như lỗi dữ liệu.
- Giữ cho mọi thứ đơn giản. Đây là một nguyên tắc xuyên suốt!
- Đừng quá sáng tạo. Thay vào đó, nhóm Pinterest đã xây dựng kiến trúc có thể dễ dàng mở rộng bằng cách thêm các thành phần tương tự nhau.
- Hạn chế các lựa chọn. Nhiều lựa chọn quá có thể dẫn đến phức tạp và rối rắm.
- Chia tách theo chiều ngang (sharding) tốt hơn nhóm theo cụm (clustering) cho cơ sở dữ liệu. Cách này giúp giảm lưu lượng dữ liệu giữa các thành phần, mang lại hiệu quả tốt hơn.
- Tạo môi trường làm việc vui vẻ! Tại Pinterest, ngay cả những kỹ sư mới cũng có thể đóng góp mã code ngay trong tuần đầu tiên.
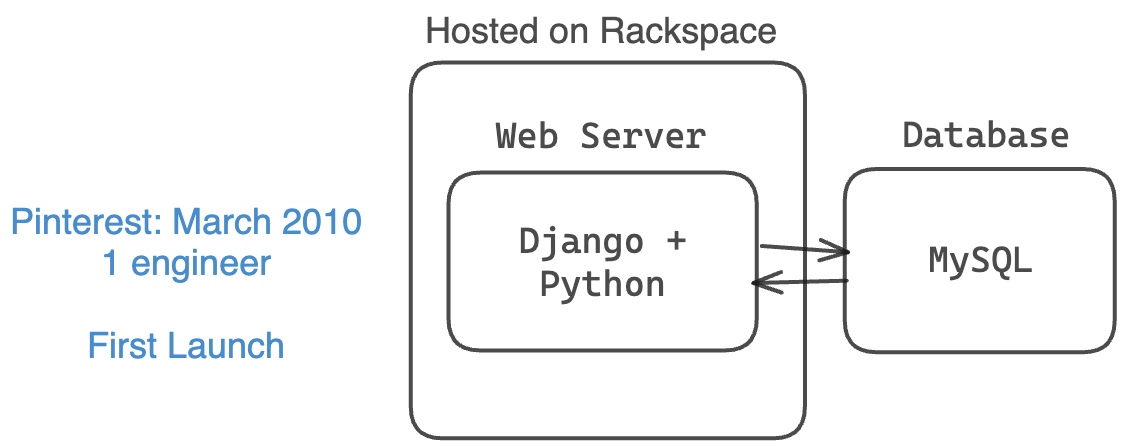
Tháng 3 năm 2010: Ra mắt phiên bản beta chỉ với 1 kỹ sư
Vào tháng 3 năm 2010, Pinterest bắt đầu hoạt động với chỉ 1 cơ sở dữ liệu MySQL nhỏ, 1 máy chủ web nhỏ và 1 kỹ sư (cùng với 2 nhà đồng sáng lập).
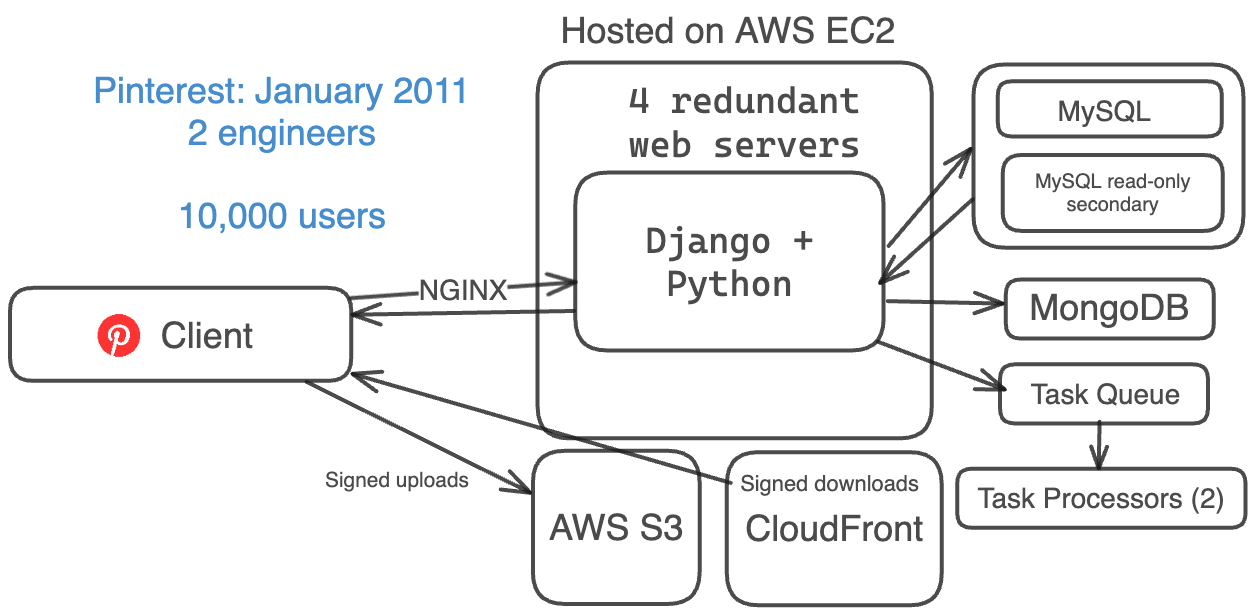
Tháng 1 năm 2011: 10.000 người dùng, 2 kỹ sư
Chín tháng sau, vào tháng Giêng năm 2011, kiến trúc của Pinterest đã phát triển để phục vụ nhiều người dùng hơn. Lúc này, họ vẫn đang giới hạn theo lời mời và chỉ có 2 kỹ sư.
Hệ thống của họ bao gồm:
- Một bộ web server cơ bản (Amazon EC2, S3 và CloudFront)
- Django (Python) cho phần backend
- 4 máy chủ web để dự phòng
- NGINX làm proxy và bộ cân bằng tải
- 1 cơ sở dữ liệu MySQL chính + 1 cơ sở dữ liệu phụ chỉ đọc
- MongoDB cho bộ đếm
- 1 hàng đợi tác vụ và 2 bộ xử lý tác vụ cho các tác vụ bất đồng bộ
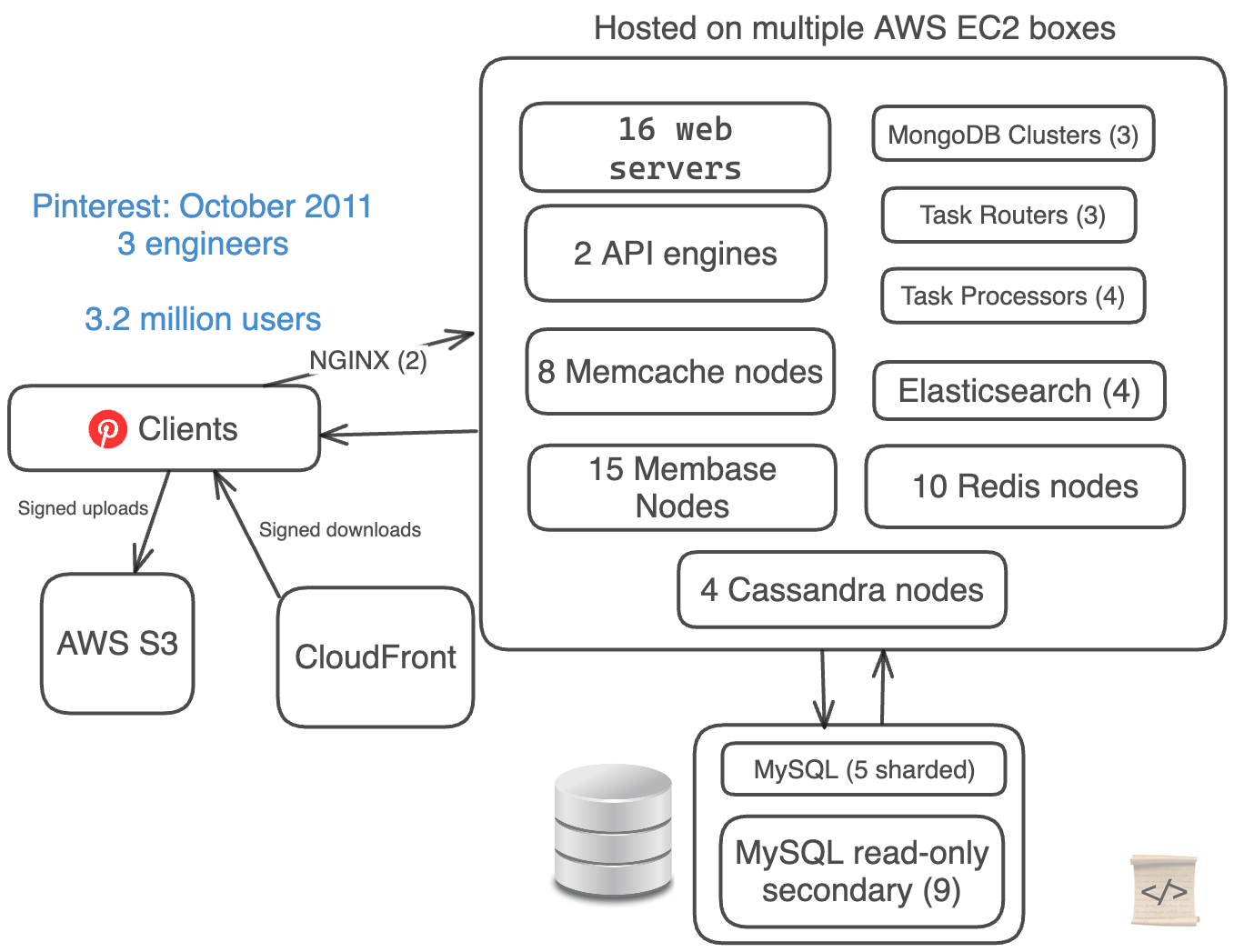
Tháng 10 năm 2011: 3,2 triệu người dùng, 3 kỹ sư
Từ tháng Giêng đến tháng 10 năm 2011, Pinterest đã trải qua một giai đoạn tăng trưởng bùng nổ, lượng người dùng tăng gấp đôi mỗi tháng rưỡi.
Tuy nhiên, tăng trưởng nhanh cũng khiến công nghệ dễ hỏng hóc hơn dự kiến.
Pinterest đã mắc một sai lầm nghiêm trọng: họ biến kiến trúc của mình trở nên quá phức tạp.
Với chỉ 3 kỹ sư, họ đã sử dụng tới 5 công nghệ cơ sở dữ liệu khác nhau.
Họ vừa tự phân shard cơ sở dữ liệu MySQL, vừa nhóm dữ liệu theo cụm bằng Cassandra và Membase (bây giờ là Couchbase).
Đây là "cỗ máy phức tạp" của họ:
- Web server stack (EC2 + S3 + CloudFront)
- Pinterest bắt đầu chuyển sang Flask (Python) cho phần backend của họ
- 16 web servers
- 2 API engines
- 2 NGINX proxies
- 5 cơ sở dữ liệu MySQL được phân chia thủ công + 9 cơ sở dữ liệu phụ chỉ đọc
- 4 Cassandra Nodes
- 15 Membase Nodes
- 8 Memcache Nodes
- 10 Redis Nodes
- 3 Task Routers + 4 Task Processors
- 4 Elastic Search Nodes
- 3 Mongo Clusters
⚠️ Phân cụm bị lỗi
Database clustering là quá trình kết nối nhiều máy chủ cơ sở dữ liệu thành một hệ thống hoạt động thống nhất.
Về mặt lý thuyết, nhóm theo cụm giúp tự động mở rộng lưu trữ dữ liệu (scaling), đảm bảo tính sẵn sàng cao (high availability), cân bằng tải tự động (free load balancing), loại bỏ điểm hỏng hóc đơn lẻ (single point of failure).
Tuy nhiên, trên thực tế, nhóm theo cụm lại quá phức tạp, khó khăn trong việc nâng cấp, thực tế vẫn có một điểm hỏng hóc đơn lẻ lớn.
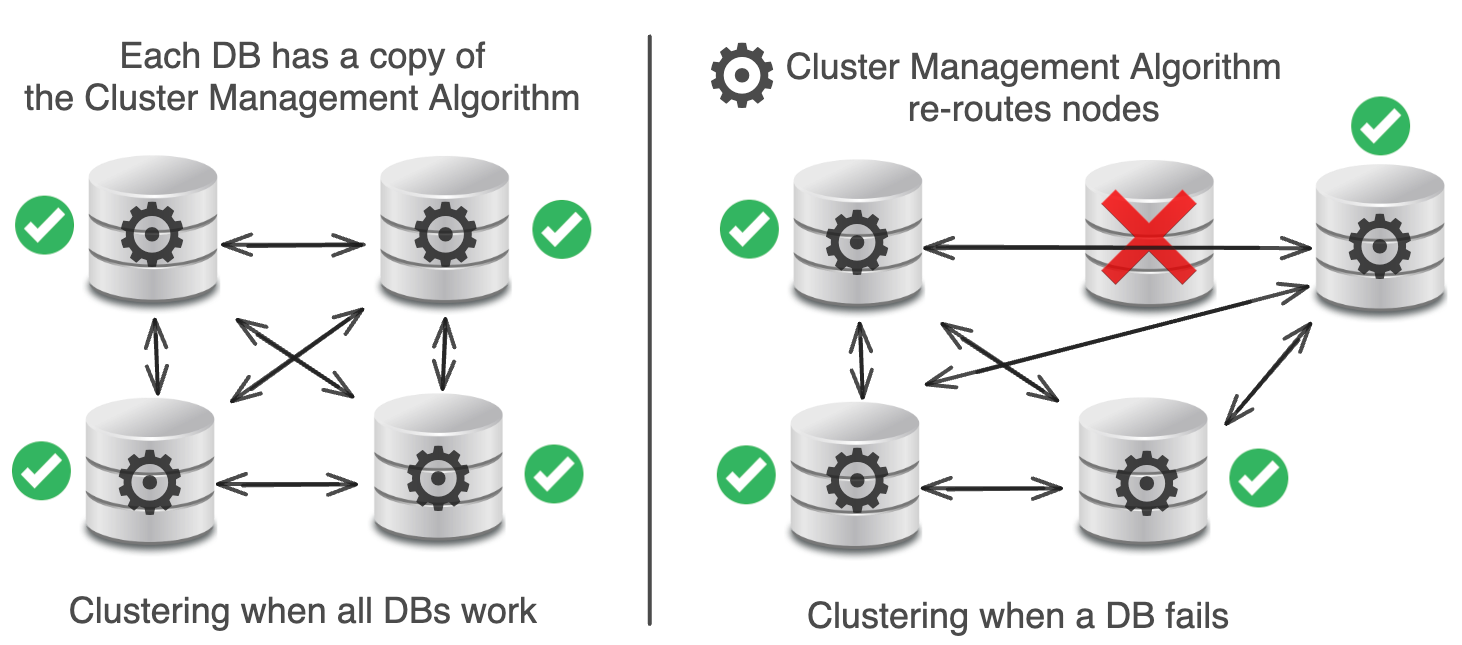
Mỗi cơ sở dữ liệu (DB) đều có một Thuật toán Quản lý Cụm (Cluster Management Algorithm) để điều hướng dữ liệu giữa các cơ sở dữ liệu.
Khi một cơ sở dữ liệu gặp sự cố, một cơ sở dữ liệu mới sẽ được thêm vào để thay thế.
Về mặt lý thuyết, Thuật toán Quản lý Cụm sẽ xử lý việc này một cách trơn tru.
Tuy nhiên, trong thực tế, Pinterest đã gặp phải một lỗi trong Thuật toán Quản lý Cụm, dẫn đến hư hỏng dữ liệu trên toàn bộ các nút (node) của họ, phá vỡ khả năng cân bằng lại dữ liệu, tạo ra một số vấn đề không thể khắc phục.
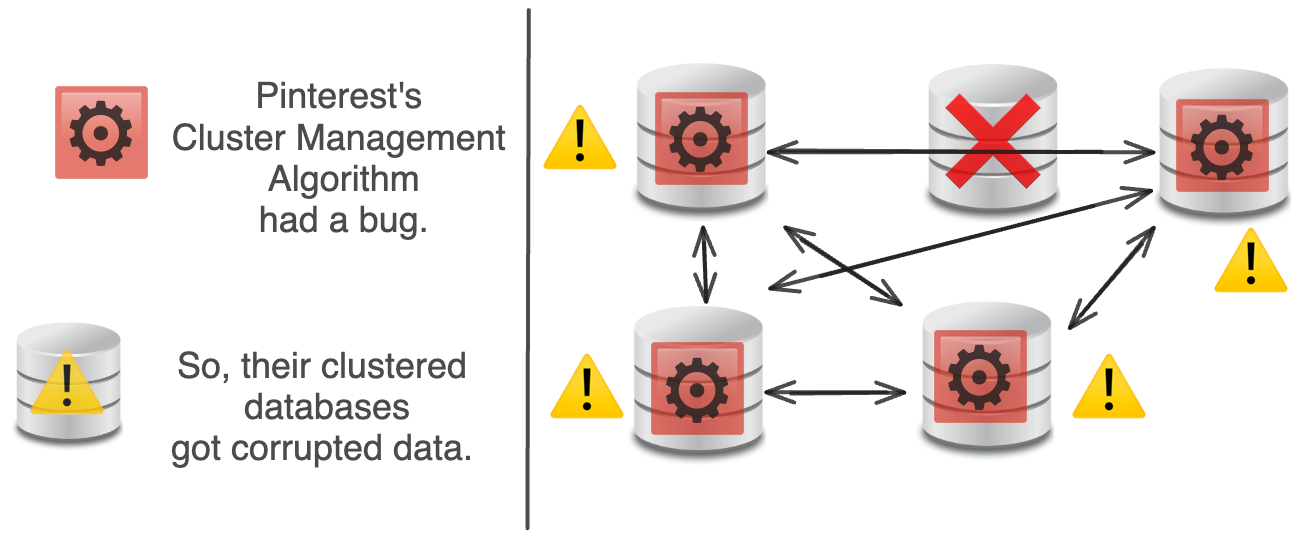
Giải pháp của Pinterest? Loại bỏ hoàn toàn công nghệ nhóm theo cụm (Cassandra, Membase) khỏi hệ thống. Thay vào đó, họ tập trung hoàn toàn vào MySQL + Memcached (đã được kiểm chứng nhiều hơn).
MySQL và Memcached là những công nghệ đã được kiểm chứng và tin cậy. Facebook đã sử dụng hai công nghệ này để tạo nên hệ thống Memcached lớn nhất thế giới, xử lý hàng tỷ yêu cầu mỗi giây một cách dễ dàng.
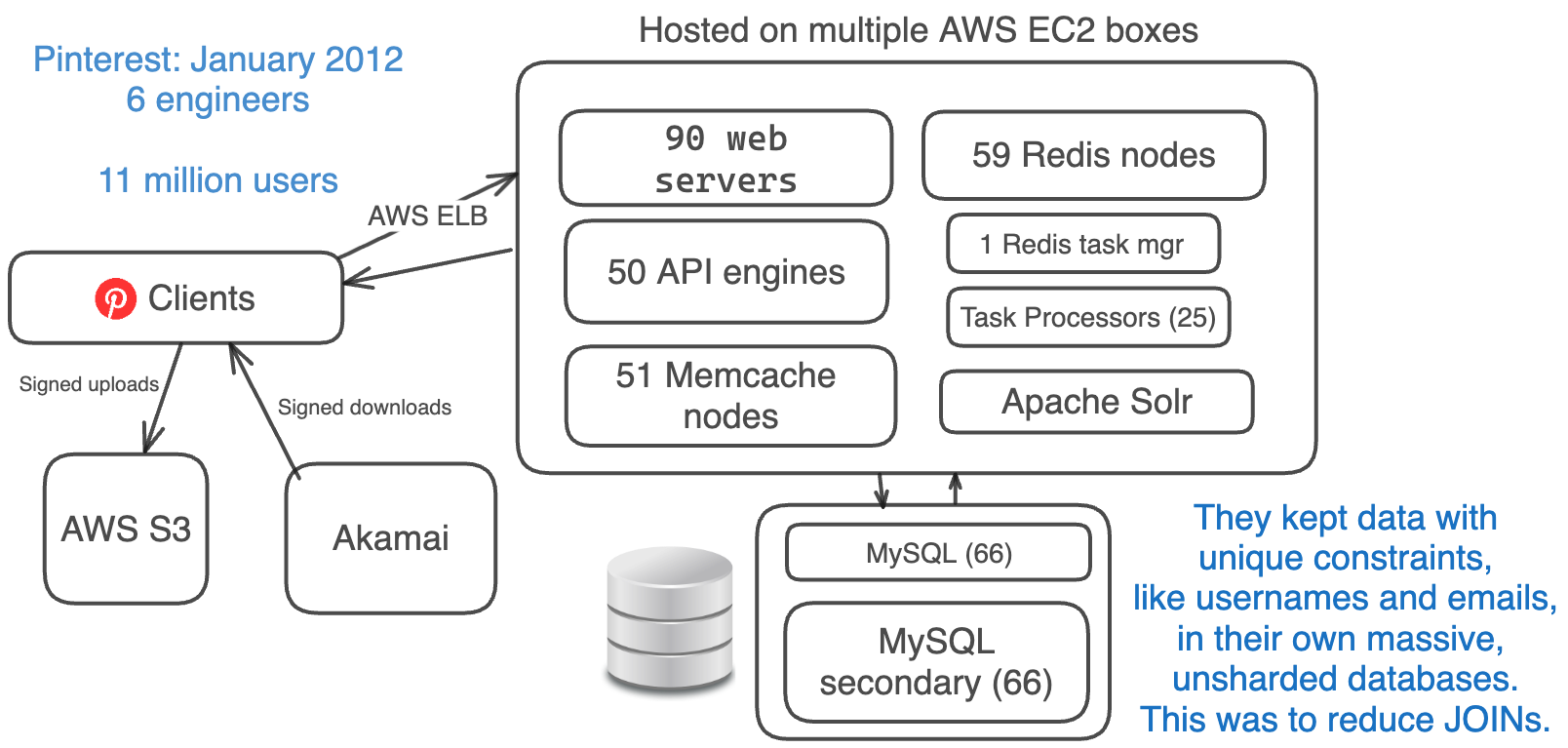
Tháng 1 năm 2012: 11 triệu người dùng, 6 kỹ sư
Vào tháng Giêng năm 2012, Pinterest đã vượt qua cột mốc ~11 triệu người dùng hoạt động hàng tháng, với lượng người dùng hoạt động hàng ngày dao động từ 12 triệu đến 21 triệu.
Đến thời điểm này, Pinterest đã dành thời gian để đơn giản hóa kiến trúc của mình.
Họ loại bỏ những công nghệ mới chưa được kiểm chứng, như nhóm theo cụm và Cassandra, và thay thế chúng bằng những công nghệ đã tin cậy, như MySQL, Memcache và Sharding.
Kiến trúc đã được đơn giản hóa của họ bao gồm:
- Amazon EC2 + S3 + Akamai (thay thế CloudFront)
- AWS ELB (Elastic Load Balancing - Cân bằng tải đàn hồi)
- 90 máy chủ Web + 50 máy chủ API (sử dụng Flask)
- 66 cơ sở dữ liệu MySQL chính + 66 cơ sở dữ liệu phụ
- 59 instances Redis
- 51 instances Memcache
- 1 Trình quản lý tác vụ Redis + 25 Bộ xử lý tác vụ
- Apache Solr Sharding (thay thế Elasticsearch)
- Đã loại bỏ Cassandra, Membase, Elasticsearch, MongoDB và NGINX
Cách Pinterest phân chia cơ sở dữ liệu của họ theo cách thủ công
Phân Shard cơ sở dữ liệu là một phương pháp chia tách một tập dữ liệu đơn lẻ thành nhiều cơ sở dữ liệu nhỏ hơn.
Lợi ích của phân Shard bao gồm:
- Tính sẵn sàng cao (high availability): Nếu một cơ sở dữ liệu gặp sự cố, các cơ sở dữ liệu khác vẫn có thể hoạt động bình thường, đảm bảo hệ thống không bị gián đoạn.
- Cân bằng tải (load balancing): Các truy vấn được phân bổ đều giữa các cơ sở dữ liệu, giúp giảm tải cho từng cơ sở dữ liệu và nâng cao hiệu suất tổng thể.
- Thuật toán đơn giản để định vị dữ liệu: Dễ dàng xác định dữ liệu cần thiết nằm ở cơ sở dữ liệu nào.
- Dễ dàng mở rộng dung lượng: Khi cần thêm dung lượng lưu trữ, chỉ cần thêm các cơ sở dữ liệu mới mà không cần thay đổi cấu trúc hiện có.
- Dễ dàng tìm kiếm dữ liệu: Việc định vị dữ liệu trong các cơ sở dữ liệu nhỏ hơn nhanh hơn và hiệu quả hơn so với một cơ sở dữ liệu lớn.
Khi Pinterest phân chia cơ sở dữ liệu lần đầu tiên, tính năng của họ bị đóng băng. Trong khoảng thời gian vài tháng, họ đã phân chia cơ sở dữ liệu của mình theo cách tăng dần và theo cách thủ công:

Đội ngũ phát triển đã loại bỏ việc nối bảng (table joins) và các truy vấn phức tạp khỏi tầng cơ sở dữ liệu. Thay vào đó, họ thêm nhiều lớp cache để tăng tốc độ truy cập dữ liệu.
Do việc duy trì tính duy nhất (unique constraints) cho dữ liệu như tên người dùng và email trên nhiều cơ sở dữ liệu khá phức tạp, họ đã giữ các dữ liệu này trong một cơ sở dữ liệu lớn, không phân Shard.
Mặt khác, tất cả các bảng khác đều được phân phát trên toàn bộ các Shard.
Ví dụ nhỏ về phân Shard thủ công:
- Do có hàng tỷ "pins" (hình ảnh), các index của cơ sở dữ liệu Pinterest gặp vấn đề hết bộ nhớ.
- Để giải quyết, họ đã tách bảng lớn nhất trong cơ sở dữ liệu sang một cơ sở dữ liệu riêng biệt.
- Sau đó, khi cơ sở dữ liệu riêng này cũng hết dung lượng, họ sẽ tiến hành phân Shard (chia tách bảng thành nhiều phần nhỏ hơn) trên bảng đó.
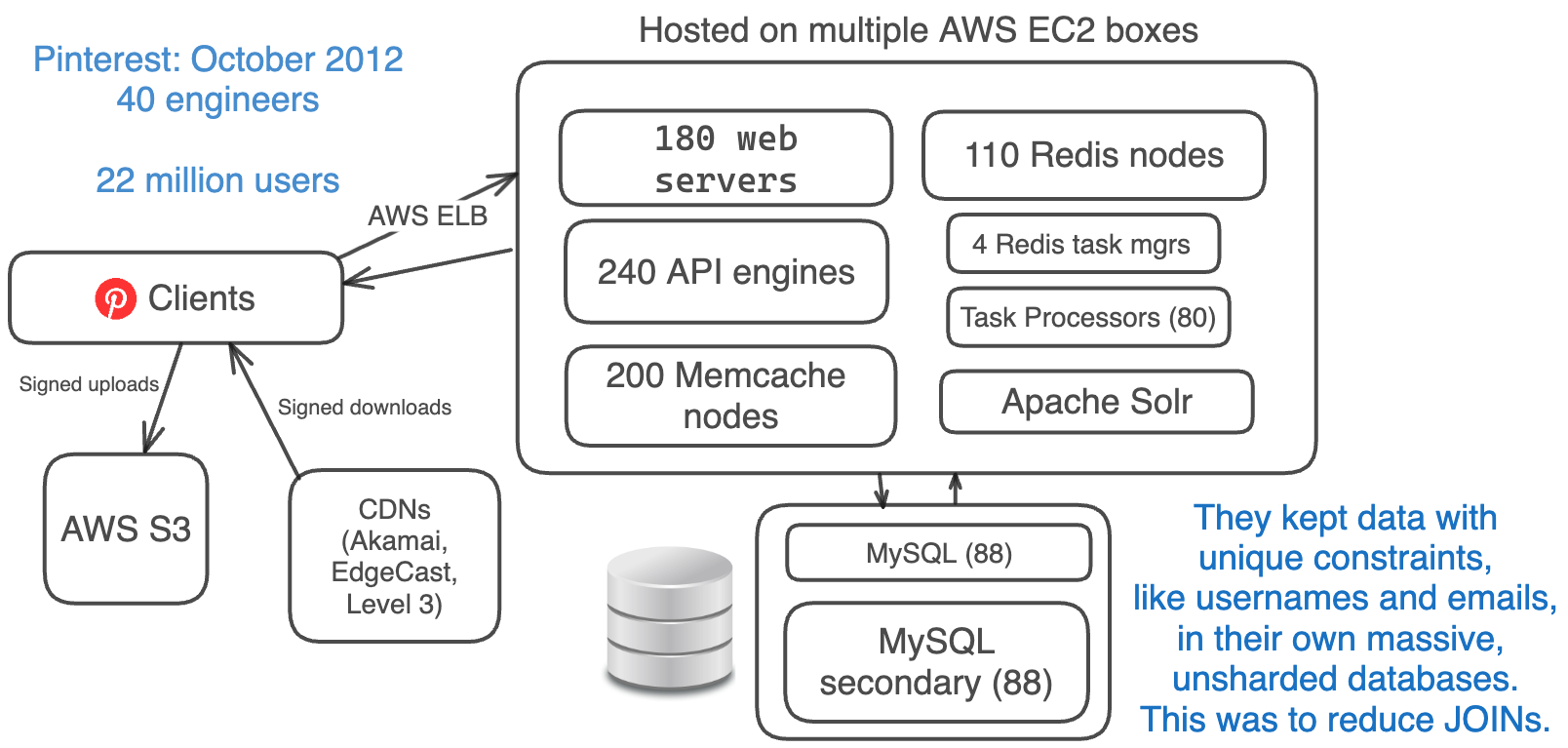
Tháng 10 năm 2012: 22 triệu người dùng, 40 kỹ sư
Vào tháng 10 năm 2012, Pinterest đã đạt khoảng 22 triệu người dùng hàng tháng, và đội ngũ kỹ sư của họ đã tăng gấp bốn lần lên 40 người.
Kiến trúc hệ thống vẫn giữ nguyên, họ chỉ đơn giản là thêm nhiều thành phần tương tự vào các hệ thống hiện có.
- Amazon EC2 + S3 + CDNs (EdgeCast, Akamai, Level 3): thêm mạng phân phối nội dung.
- 180 web servers + 240 API engines (using Flask): tăng số lượng máy chủ web và API.
- 88 MySQL DBs + 88 secondaries each: tăng số lượng cơ sở dữ liệu MySQL và bản sao phụ.
- 10 Redis instances: tăng số lượng instances Redis.
- 200 Memcache instances: tăng số lượng instances Memcache.
- 4 Redis Task Managers + 80 Task Processors: tăng cường khả năng xử lý tác vụ.
- Sharded Apache Solr: tiếp tục dùng Apache Solr phân Shard.
Họ bắt đầu chuyển đổi từ ổ cứng HDD sang ổ cứng SSD.
Việc gắn bó với EC2 và S3 có nghĩa là họ có ít lựa chọn cấu hình hơn, dẫn đến ít đau đầu và hệ thống đơn giản hơn.
Tuy nhiên, các instances mới có thể sẵn sàng trong vài giây. Điều này có nghĩa là họ có thể thêm 10 instances Memcache chỉ trong vài phút.
Cấu trúc cơ sở dữ liệu của Pinterest
IDs
Giống như Instagram, Pinterest có cấu trúc ID duy nhất vì họ đã phân chia cơ sở dữ liệu.
ID 64-bit của họ trông như sau:

ID Shard (16 bit): Xác định shard nào lưu trữ dữ liệu.
Type (10 bit): Xác định loại đối tượng, ví dụ như pins (hình ảnh).
ID Local (38 bit): Xác định vị trí của đối tượng trong bảng dữ liệu của shard đó.
Cấu trúc tra cứu các ID này là một Python dictionary đơn giản.
Tables
Họ sử dụng hai loại bảng: Bảng Đối tượng (Object tables) và Bảng Ánh xạ (Mapping tables).
Bảng Đối tượng:
- Dùng để lưu trữ các đối tượng như pins (hình ảnh), boards (bảng tin), comments (bình luận), users (người dùng), và nhiều loại đối tượng khác.
- Cấu trúc bảng gồm: ID cục bộ (Local ID) được ánh xạ tới một đoạn dữ liệu dạng blob (MySQL blob) như JSON.
Bảng Ánh xạ:
- Dùng để lưu trữ dữ liệu quan hệ giữa các đối tượng, ví dụ như ánh xạ bảng tin (boards) tới người dùng (users) hoặc lượt thích (likes) tới pins (hình ảnh).
- Cấu trúc bảng gồm: Full ID (ID đầy đủ) được ánh xạ tới một Full ID khác và một dấu thời gian (timestamp).
Để tối ưu hiệu suất, tất cả các truy vấn đều dựa trên khóa chính (primary key) hoặc index lookup (tra cứu chỉ mục). Họ đã loại bỏ hoàn toàn việc sử dụng JOINs (phép nối bảng).
Bài viết này dựa trên Scaling Pinterest, một bài nói chuyện của nhóm Pinterest vào năm 2012.
All rights reserved
