
Break Capcha bằng Deep learning
Bài đăng này đã không được cập nhật trong 5 năm
1. Giới thiệu bài toán
Vào một hôm trăng thanh gió mát cuối năm, lòng người rạo rực lương thưởng sắp về, anh Sếp mình có giao cho mình thử sức với một con capcha vô cùng mới mẻ. Mình quyết định sắn tay thử sức để có vài cái hay ho hôm nay đem chia sẻ với mọi người. Link trang ấy mình không tiện chia sẻ, các bạn tự tìm hiểu nhé  .
.
 '
'
Nói sơ qua một chút, CAPTCHA là hình ảnh chứ một đoạn mã có thể bao gồm 5 chữ hoặc số liền kề nhau. Các chữ số ấy sẽ được tác động để làm méo mó hoặc làm mờ, thêm nhiễu, sắp xếp không theo hàng lối nào cả để khó đọc hơn. Cơ hội trả lời đúng của chúng ta khi nhập CAPTCHA lên tới 80%, trong khi đó nếu là máy tính và không được lập trình đúng cách, cơ hội trả lời đúng chỉ là 0.1% mà thôi. Theo CAPTCHA là gì ? Tại sao bạn phải gõ chúng khi đăng nhập, đăng ký,...?
Lý do mà capcha khó đọc như thế là để hệ thống chống lại những cuộc tấn công có mục đích xấu. Bạn tưởng tượng một capcha đẹp sẽ bị đọc tự động dễ dàng bởi một vài phương pháp lập trình đơn giản. Vậy nên, chúng được được làm " xấu " đi để chỉ mắt người mới có thể đọc được thôi.
Giới thiệu thế là đủ rồi, mình cùng bắt tay đi "break" nó nào......À quên, các bạn có thể vào tham khảo cho repo của mình ở BreakCapcha Repo nhé.
2. Các bước xử lý
- Cài đặt môi trường
- Thu thập dữ liệu (bước này các bạn có thể dùng selenium để crawl dữ liệu, do không phải mục đích chính bài viết nên mình xin bỏ qua phần này)
- Tiền xử lý ảnh để loại bỏ nhiễu
- Nhận dạng đoạn mã bằng mô hình học sâu (Deep learning)
2.1. Cài đặt môi trường
Để có thể thực hiện được các bước xử lý phía dưới mình cần dùng những thư viện dưới đây.
numpy==1.18.5
torch==1.7.1
PyYAML==5.3.1
Pillow==8.0.1
opencv-python==4.4.0.44
Trong github, mình đã liệt kê trong file requirement.txt. Các bạn chỉ cần clone xuống và thực hiện câu lệnh sau:
pip install -r requirement.txt
2.2. Loại bỏ nhiễu
Trước hết ta đọc ảnh và quan sát dữ liệu.
from PIL import Image
from matplotlib import pyplot as plt
import cv2
import numpy as np
img = Image.open('./test.png')
plt.imshow(img)
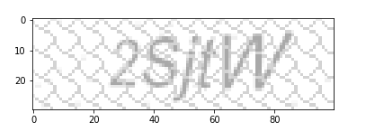 Image 1: Ví dụ
Image 1: Ví dụ
Quan sát ta có thể nhận ra những khó khăn khi xử lý ảnh như sau :
Kích thước ảnh bé: Ảnh đầu vào là ảnh transparent có kích thước 30 x 100 - tương đối nhỏ. Chính vì kích thước nhỏ như vậy sẽ gây khó khăn cho chúng ta khi sử dụng các bộ lọc nhiễu như Median, Gausian, ... Lý do là kích thước nhân (kernel) của một bộ lọc như Gausian tối thiểu là 3x3. Khi áp dụng kernel như vậy, kernel sẽ bao trọn một vùng tương đối lớn bao gồm cả nhiễu và ký tự nên ký tự sau đó sẽ bị biến dạng.
 Image 2: Ảnh sau khi sử dụng bộ lọc Gausian
Image 2: Ảnh sau khi sử dụng bộ lọc Gausian
Nhiễu: Sẽ gây khó khăn để có thể đọc được các ký tự có trong ảnh. Và một số nhiễu cũng chính là một phần pixel thể hiện màu ảnh của các ký tự. Tuy nhiên màu của nhiễu luôn nhạt hơn màu của ký tự hay nói cách khác giá trị pixel của nhiễu bé hơn giá trị pixel của các ký tự
Từ những nhận xét trên, trong bài này mình quyết định sử dụng sự chênh lệch giá trị pixel của nhiễu và ký tự để tách nhiễu khỏi ảnh. Nếu những giá trị pixel nào lớn hơn pass_factor thì đặt pixel đó bằng 0 hay nói cách khác là những giá pixel của phần ký tự mình đặt bằng 0. Ở đây, pass_factor là giá trị ngưỡng để lấy nhiễu. Code thực hiện như sau:
def remove_noise(img, pass_factor):
for column in range(img.size[0]):
for line in range(img.size[1]):
value = remove_noise_by_pixel(img, column, line, pass_factor)
img.putpixel((column, line), value)
return img
def remove_noise_by_pixel(img, column, line, pass_factor):
if img.getpixel((column, line)) < pass_factor:
return 0
return img.getpixel((column, line))
# convert to gray image
if 'L' != img.mode:
img_bg = img.convert('L')
img_bg = remove_noise(img_bg, pass_factor=170)
img_bg = np.asarray(img_bg)
plt.imshow(img_bg)
Sau khi thực hiện ta có kết quả như sau:
 Image 3: Nhiễu sau khi tách
Image 3: Nhiễu sau khi tách
Sau khi tách được ảnh nhiễu, ta lấy ảnh gốc trừ được phần nhiễu sẽ thu được phần chứa đoạn mã.
img_final = np.asarray(image.convert('L')) - np.asarray(img_bg)
img_final = cv2.cvtColor(img_final, cv2.COLOR_GRAY2BGR)
plt.imshow(img_final)
Trông cũng ngon ghẻ rất nhiều so với việc dùng bộ lọc Gausian đúng không nào 
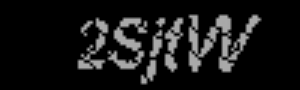 Image 4: Phần chứ đoạn mã
Image 4: Phần chứ đoạn mã
2.2. Nhận dạng đoạn mã bằng mô hình học sâu
Sau khi thu được ảnh đã được loại bỏ hoàn toàn nhiễu như bước trên, mình code một mô hình học sâu để đọc đoạn mã cụ thể mình dùng mô hình Attention OCR.Dành cho bạn nào chưa biết thì Attention OCR có kiến trúc bao gồm phần mạng CNN dùng để trích xuất đặc trưng từ ảnh đầu vào như MobileNet, ResNet, ....và phần sau là các lớp RNN và Attention để hỗ trợ việc học các đặc trưng có dạng tuần tự. Nếu các bạn chưa biết về Attention thì có thể tham khảo tại bài viết Machine Learning Attention, Attention, Attention, ...! của tác giả Phan Hoàng.
Ở bài này, mình không muốn tập trung quá nhiều về làm thế nào để xây dựng OCR này nhưng có một chú ý là do kích thước của ảnh tương đối bé (30 x 100) và số lượng ảnh dùng để huấn luyện bị hạn chế nên việc sử dụng nguyên một mô hình có kích thước lớn tương đối thôi như Resnet18 hay VGG-19, .... theo mình thực nghiệm đều không hiệu quả. Có thể do mô hình có nhiều tham số để tối ưu nhưng dữ liệu lại không đủ cho việc huấn luyện nên không thể đạt kết quả tốt nhất. Do đó ở đây mình đã dùng block của mô hình ResNet quen thuộc chỉnh sửa thành một mô hình mới phù hợp với bài toán hơn.
Mình có thu thập và tự gán nhãn 3500 ảnh trong đó chia 3000 ảnh cho tập train, 400 ảnh cho validate và 100 ảnh cho tập test. Kết quả mình đạt độ chính xác 84% cho tập validate và 80% cho tập test. Trong github của mình, mình cung cấp sẵn pretrained weight để các bạn có thể tự thử nghiệm nhé.

Cảm ơn các bạn đã theo dõi và đóng góp ý kiến cho những bài viết của mình trong một năm vừa qua. Chúc các bạn một năm mới may mắn và tiếp tục có nhiều động lực để theo đuổi con đường mình đã chọn. Happy New Year 
All rights reserved
