BigData Challegens - Part 2
Bài đăng này đã không được cập nhật trong 7 năm
I. Introduction
Phần I https://viblo.asia/p/big-data-challenges-part-1-63vKj07yl2R
Tiếp nối phần I, ở phần này mình sẽ trình bày nốt những thách thức còn lại của BigData, những giải pháp để có thể giải quyết được những thách thức này và những việc cần phải làm trong tương lai.
II. Challenges
3. Management challenges
Nhóm thách thức này giải quyết các vấn đề pháp luật và đạo đức liên quan đến dữ liệu truy cập:
a. Riêng tư: Bảo mật là một mối quan tâm lớn, đặc biệt là trong bối cảnh của Big Data. Ví dụ, trong lĩnh vực y tế, đã có luật điều chỉnh quyền riêng tư của bệnh nhân. Có sự lo sợ ngày càng tăng về việc sử dụng dữ liệu cá nhân không phù hợp, đặc biệt khi kết hợp dữ liệu này từ nhiều nguồn. Ví dụ: dữ liệu được trích xuất từ các dịch vụ dựa trên vị trí yêu cầu người đăng ký chia sẻ vị trí của họ dẫn đến mối quan tâm rõ ràng về quyền riêng tư. Một số người nghĩ rằng việc chỉ ẩn danh tính của họ mà không che giấu vị trí của họ sẽ không giải quyết đúng các mối quan tâm về quyền riêng tư. Nhà cung cấp dịch vụ dựa trên vị trí có thể kết luận danh tính của người đăng ký bằng cách truy tìm thông tin vị trí tiếp theo. Nó tương tự như người dùng để lại một vết bánh mì gói phía sau anh ta, chúng có thể được liên kết tới một vị trí văn phòng nhất định hoặc nơi cư trú và do đó được sử dụng để phát hiện danh tính của người dung. Ngoài ra, có thể tiết lộ các loại thông tin cá nhân khác như thông tin chi tiết về sức khỏe (ví dụ: thường xuyên đến trung tâm điều trị ung thư) hoặc tùy chọn tôn giáo (ví dụ: sự hiện diện trong nhà thờ) bằng cách theo dõi chuyển động của người dùng ẩn danh và phân tích các mẫu chuyển động theo thời gian. Sẽ khó khăn hơn khi ẩn vị trí người dùng hơn danh tính của anh/cô ta vì sử dụng các dịch vụ dựa trên vị trí mà anh/cô ấy cần để hiển thị vị trí. Ngày nay nhiều thông tin cá nhân được chia sẻ thông qua các dịch vụ trực tuyến như Facebook, Twitter, v.v. cho đến bây giờ nhiều người không hiểu ẩn ý của chia sẻ dữ liệu, cá dữ liệu này có thể liên kết với nhau để đưa ra nhiều chi tiết cá nhân hơn. (32)
Bảo mật: Nhiều công ty đang xây dựng môi trường tính toán lớn để lưu trữ, tổ hợp và phân tích lượng lớn Big Data đang lớn dần lên. Nó trở lên được biết rằng Bigdata giúp các công ty kinh doanh thích nghi sản phẩm và dịch vụ của họ với nhu cầu người dùng và nâng cao hiệu quả doanh nghiệp. Kết luận, lượng lớn kho Big data đã tăng cùng với sự tăng tương đối của các vấn đề bảo mật liên quan. Tác động của vi phạm an ninh lớn như đề xuất “Big data” và các nhóm tội phạm đang nhắm đến mục tiêu kho Big data để đạt được số tiền lớn, hãy tưởng tượng hàng terabyte dữ liệu trong các kho lưu trữ đó bao gồm thông tin của một công ty trang sức: dữ liệu khách hàng, dữ liệu nhân viên và bí mật doanh nghiệp.
Mặc dù giá trị mục tiêu cao của Big Data, việc bảo mật Big Data có những thách thức riêng mà về cơ bản nó không khác với những thách thức liên quan đến dữ liệu truyền thống. Trên thực tế, có sự khác biệt cơ bản giữa những thách thức bảo mật của Big Data và dữ liệu truyền thống bao gồm:
- Dữ liệu: các thuộc tính đa dạng, vận tốc và khối lượng đặc biệt của dữ liệu lớn khuếch đại các thách thức quản lý bảo mật so với vị trí của chúng trong môi trường truyền thống.
- Cơ sở hạ tầng: Bản chất phân tán của các môi trường dữ liệu lớn là một thách thức khác vì chúng phức tạp hơn và dễ bị tấn công hơn.
- Công nghệ: bảo mật không được lưu ý khi các công nghệ Big Data như Hadoop và NoSQL ban đầu được thiết kế đã tạo ra các lỗ hổng xác thực và bảo mật mạng.
Sự quản lý: Yêu cầu về Big data ngày càng lớn và sự quản lý Big data trở thành một vấn đề cấp bách. Bigdata là phong phú với thông tin cá nhân và dữ liệu doanh nghiệp bảo mật, và quản lý dữ liệu được yêu cầu để đảm bảo những thông tin này là an toàn cao. Sự quản lý Big data là cần thiết để đảm bảo chất lượng của Big data và kết luận chất lượng của tiến trình và phân tích được xây dựng dựa trên. Áp dụng sự quản lý Big data ở mức cao sẽ giúp tạo ra các quyết định cùng với sự tự tin, để lên kế hoạch đúng đắn cho tương lai, để tránh chi phí phát sinh từ dữ liệu chất lượng thấp và cần phải làm lại công việc và cung cấp báo cáo dữ liệu lớn tương thích với các tiêu chuẩn của chính phủ như Sarbanes. Việc quản lý Quản trị dữ liệu lớn đưa ra một số thách thức cho các tổ chức. Quản trị dữ liệu lớn sẽ yêu cầu tuân thủ nguyên gốc của giao thức bảo mật cho môi trường tính toán dữ liệu lớn, tuy nhiên, hầu hết các tổ chức đều vận hành các công cụ kế thừa của riêng họ và đều các kỹ thuật bảo mật độc quyền. (34)
III. Solution
Nhiệm vụ nhận thông tin chi tiết hữu ích từ Big Data không hề dễ dàng. Đó là vấn đề phát triển môi trường toàn diện bao gồm phần cứng, phần mềm cơ sở hạ tầng, phần mềm hoạt động, phần mềm quản lý và giao diện lập trình ứng dụng (API) để cung cấp mô hình đầy đủ chức năng quản lý Big data. Sự biểu diễn khái niệm của môi trường này được biểu diễn như là kiến trúc tham chiếu lớp được gọi là ngăn xếp công nghệ big data, như được hiển thị trong hình dưới đây: (35)
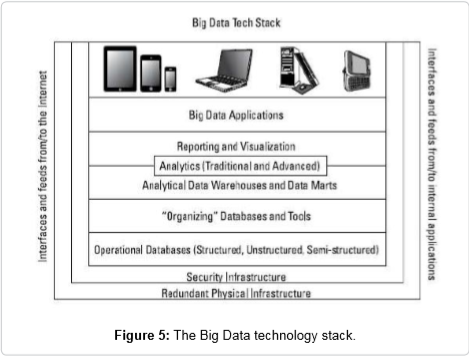
Ngăn xếp công nghệ này cung cấp mô hình chức năng từng lớp cho dữ liệu lớn, trong đó mỗi lớp sẽ trình bày công nghệ thích hợp được sử dụng để giải quyết các nhu cầu và thách thức đặc biệt của Big Data, bây giờ chúng ta sẽ bắt đầu mô tả những gì là đặc biệt cho mỗi lớp để thực hiện Big Data và cách nó tham gia để cung cấp một giải pháp tối ưu tổng thể (34).
1. Layer 1. Redundant physical infrastructure (Data challenges)
Đó là chủ yếu về cơ sở hạ tầng công nghệ mới để vượt qua những thách thức phát sinh từ các đặc tính dữ liệu như khối lượng lớn, dữ liệu cao, tốc độ cao. Cơ sở hạ tầng vật lý CNTT sẽ cung cấp các hệ thống phần cứng cần thiết với lưu trữ đầy đủ, sức mạnh xử lý và tốc độ truyền thông phù hợp với các yêu cầu của Big Data (36). Cơ sở hạ tầng IT tối ưu sẽ làm trọn vẹn việc triển khai Big data của bạn, chúng sẽ được xác định rõ ràng sau khi bạn đặt ra các yêu cầu của mình đối với từng tiêu chí sau:
Hiệu suất: Điều này đo lường mức độ đáp ứng của hệ thống, vì hiệu năng hệ thống làm tăng chi phí tăng cơ sở hạ tầng.
Tính sẵn sàng: Bạn có cần hệ thống của mình hoạt động 24/7 và không bị gián đoạn không? Nếu có, điều này có nghĩa là bạn cần cơ sở hạ tầng có tính sẵn sàng cao và cũng đắt tiền.
Khả năng mở rộng: Bạn cần phải thiết lập kích thước cơ sở hạ tầng, dung lượng lưu trữ và sức mạnh tính toán. Ngoài ra, bạn cần phải xem xét quy mô bổ sung cho những thách thức trong tương lai.
Tính linh hoạt: Điều này liên quan đến tốc độ bạn có thể thêm nhiều tài nguyên hơn vào cơ sở hạ tầng hoặc có thể khôi phục từ lỗi. Mức độ linh hoạt là tỷ lệ thực tế với chi phí. Do luồng dữ liệu không ngừng cho các dự án Big Data, cơ sở hạ tầng vật lý phải có cả sự dự phòng và khả năng phục hồi. (35)
2. Layer 2 - Security infrastructure (Management challenges)
Ngoài các biện pháp bảo mật truyền thống được áp dụng bởi hệ điều hành và ứng dụng để kiểm soát truy cập dữ liệu và bảo vệ dữ liệu trong khi giao tiếp, cần thực hiện các biện pháp đặc biệt để xem xét các thuộc tính đặc biệt của Big Data. Giải pháp chính để đảm bảo dữ liệu vẫn được bảo vệ là áp dụng mã hóa. Việc xóa bất kỳ chi tiết nhận dạng cá nhân nào là cần thiết để bảo vệ quyền riêng tư của người dùng, có thể đạt được bằng cách ẩn danh dữ liệu và xóa tất cả dữ liệu nhạy cảm cá nhân trước khi lưu các bản ghi đó. Ngoài ra, đáng lưu ý rằng nếu Big Data không được kiểm soát bởi khung quản trị rõ ràng, chúng ta sẽ kết thúc với các dữ liệu sai lệch dẫn đến mất mát không mong muốn, tuy nhiên Big Data vẫn là khái niệm mới và hiện tại vẫn chưa có tiêu chuẩn hoặc chính sách nào.
3. Layer 3 - Operational databases (Process challenges)
Kiến trúc dữ liệu lớn sẽ vẫn cần phải có cơ sở dữ liệu hoạt động để đáp ứng nhu cầu kinh doanh. Ví dụ, nhìn vào môi trường Facebook nếu bạn thay đổi trạng thái mối quan hệ của mình, thay đổi này sẽ bắt đầu lan truyền đến dòng thời gian của các thành viên gia đình, đối tác, bạn bè trực tiếp của bạn và tiếp tục cho đến bạn bè từ xa. Facebook sử dụng cơ sở dữ liệu MySQL để theo dõi những thay đổi đó và cũng để theo dõi tất cả các thay đổi được thực hiện trên trang chủ của nó. Công nghệ cơ sở dữ liệu cung cấp các công cụ và ngôn ngữ truy vấn khác nhau và theo yêu cầu của việc triển khai Big Data để thực hiện một hoặc nhiều động cơ và để chọn ngôn ngữ SQL hoặc bất kỳ ngôn ngữ nào khác (38). Chi tiết hơn về đặc điểm của SQL một cơ sở dữ liệu NoSQL được nhìn thấy trong Bảng 1: (34)

Điều quan trọng là phải hiểu các loại dữ liệu sẽ được cơ sở dữ liệu thao tác và nếu nó hỗ trợ hành vi giao dịch được gọi là "ACID" viết tắt của:
Nguyên vẹn: Nguyên vẹn có nghĩa là tất cả hoặc không có gì. Nếu bất kỳ phần giao dịch nào bị lỗi, toàn bộ giao dịch cũng không thành công.
Kiên định: Giao dịch với dữ liệu hợp lệ sẽ được thực hiện trong cơ sở dữ liệu kiên định với các quy tắc và ràng buộc được xác định.
Cách ly: Mỗi giao dịch sẽ chạy cho đến khi kết thúc theo thứ tự của nó và đồng thời nhiều giao dịch sẽ không can thiệp.
Bền vững: Khi dữ liệu giao dịch được ghi vào cơ sở dữ liệu, nó sẽ là mãi mãi bất kể mất điện, sự cố hoặc bất kỳ loại lỗi nào khác (39)
4. Layer 4 - Organizing data services and tools (Data & process challenges)
Trình điều khiển thực để chuyển đổi dữ liệu từ 0 và 1 thành thông tin chi tiết được thông báo vẫn còn thiếu; đây đơn giản là công nghệ phần mềm. Tổ chức các dịch vụ dữ liệu và các công cụ nắm bắt, xác thực và tổ chức các thành phần của Big Data. Một công nghệ phần mềm rất nổi tiếng trong lĩnh vực Dữ liệu lớn là Apache Hadoop (40). Apache Hadoop là một open source software framework targets để xử lý lượng lớn dữ liệu trong thời gian thực bằng cách phân phối việc xử lý các tập dữ liệu giữa các cụm máy. Nó mở rộng từ một máy chủ lên hàng nghìn máy tính, mỗi máy tính có dung lượng lưu trữ và tính toán riêng, xem hình 6 (41).
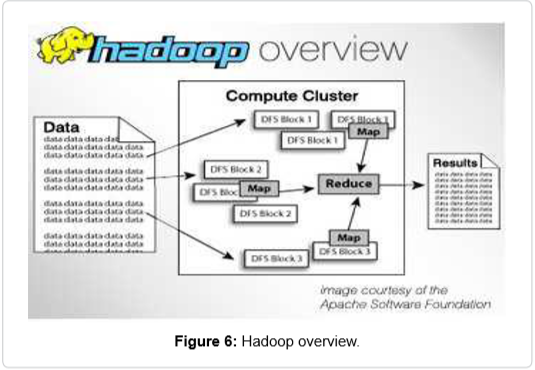
Nó cũng không phụ thuộc vào phần dư thừa của phần cứng để cung cấp tính khả dụng của hệ thống vì nó phát hiện ra sự thất bại ở lớp ứng dụng và thực hiện các hành động sửa chữa cần thiết (42).
Apache Hadoop bao gồm bốn modules chính:
Hệ thống tệp phân tán Hadoop (HDFS): Đây là hệ thống tệp phân tán chịu trách nhiệm lưu trữ dữ liệu trên nhiều máy chủ, chúng tổng hợp để cung cấp lượng băng thông cao qua cluster.
Sợi Hadoop: Module này quản lý tài nguyên máy tính trong cluster và kiểm soát việc gán tài nguyên cho các ứng dụng của khách hàng.
Bản đồ giảm Hadoop: Đây là công cụ chính để xử lý dữ liệu có quy mô lớn.
Hadoop common: Một hộp công cụ của các thư viện và các tiện ích được các module Hadoop khác yêu cầu (43).
5. Layer 5 – Analytical data warehouses (Process challenges)
Kho dữ liệu là cơ sở dữ liệu quan hệ được xây dựng bằng cách tích hợp dữ liệu từ cơ sở dữ liệu hoạt động, cơ sở dữ liệu lịch sử và các nguồn khác nhằm mục đích chạy truy vấn và phân tích mà không ảnh hưởng đến hiệu suất của cơ sở dữ liệu giao dịch trực tuyến. Kho dữ liệu là nguồn thông tin chính cho những người ra quyết định, đặc biệt là lập kế hoạch chiến lược. Trên thực tế, nó không chỉ là cơ sở dữ liệu hợp nhất tạo ra môi trường kho dữ liệu mà còn bao gồm khai thác, vận chuyển, chuyển đổi và tải các quy trình để biên dịch dữ liệu trong biểu mẫu sẵn sàng để phân tích (44). Kho dữ liệu là kho của dữ liệu có cấu trúc cao trong khi big data bao gồm các kiểu dữ liệu khác nhau: có cấu trúc, nửa có cấu trúc và không cấu trúc và không thể được hợp nhất với nhau do sự khác biệt về cấu trúc của dữ liệu và kho dữ liệu truyền thống không thể xử lý luồng dữ liệu lớn. Các tổ chức sẽ tiếp tục sử dụng kho dữ liệu truyền thống để phân tích các giá trị, xu hướng và mẫu quan trọng. Mối quan hệ giữa kho dữ liệu và Big Data là bổ sung để trở thành cấu trúc lai. Cấu trúc lai này sẽ bao gồm dữ liệu có cấu trúc cao được quản lý bởi kho dữ liệu truyền thống và phân tán cao và dễ bị thay đổi dữ liệu trong thời gian thực được quản lý bởi giải pháp Hadoop –controlled.
6. Layer 6 - Big Data analytics (Process challenges)
Phân tích dữ liệu lớn là quá trình kiểm tra lượng lớn dữ liệu tiềm năng thời gian thực và khác biệt để làm ví dụ: khám phá xu hướng ẩn, xu hướng thị trường và tùy chọn của khách hang. Mục tiêu cuối cùng của Phân tích dữ liệu lớn là hỗ trợ các tổ chức đưa ra quyết định kinh doanh sáng suốt hơn (46). Nói chung có ba loại công cụ phân tích chính có thể được sử dụng riêng lẻ hoặc cùng nhau bởi các tổ chức để đạt được giá trị kinh doanh thực tế và các lớp này là:
Báo cáo và trang tổng quan: Công cụ thân thiện với người dùng để trình bày thông tin được thu thập từ nhiều nguồn khác nhau. Khu vực này vẫn đang phát triển để hỗ trợ nhu cầu dữ liệu lớn và hiện tại chúng truy cập vào công nghệ cơ sở dữ liệu mới được gọi là "NoSQL". (34)
Trừu tượng hóa: Đây có thể được xem là công cụ báo cáo nâng cao cung cấp sự biểu diễn hình ảnh hoặc đồ họa cho dữ liệu và giúp người dùng dễ dàng hiểu dữ liệu và mối quan hệ của nhiều biến cùng một lúc. Đầu ra của những công cụ này là rất tương tác và năng động. Những công cụ này đã sử dụng các kỹ thuật mới để cho phép người dùng xem dữ liệu khi đang thay đổi trong thời gian thực (47).
Phân tích và phân tích nâng cao: Đây là nhóm kỹ thuật phân tích dựa trên các nguyên tắc toán học được sử dụng để tổng hợp và đếm các sự kiện lịch sử trong kho dữ liệu của tổ chức nhằm xác định xu hướng và phát hiện mẫu. Những kỹ thuật này giúp dự đoán kết quả trong tương lai và đưa ra các quyết định cần thiết để hỗ trợ hoặc có biện pháp khắc phục để tránh các ảnh hưởng được dự kiến từ trước. Phân tích dự đoán, phân tích mô phỏng và phân tích tối ưu hóa là những ví dụ phổ biến về những kỹ thuật đó. (48)
7. Layer 7 - Big Data applications (Process challenges)
Người dùng quan tâm nhất đến các sản phẩm công nghệ có liên quan đến lớp này vì chúng là sản phẩm cuối cùng mà họ tương tác. Các sản phẩm này có thể là ứng dụng của bên thứ ba hoặc các ứng dụng nội bộ có thể đáp ứng các yêu cầu chung của nhiều ngành hoặc yêu cầu của ngành cụ thể. Một số ví dụ về các nhóm nổi tiếng là ứng dụng dữ liệu nhật ký (Splunk, Loggly), các ứng dụng tiếp thị (Bloomreach, Myrrix) và các ứng dụng truyền thông tiên tiến (Bluefin, DataXu). Việc xây dựng các sản phẩm tùy chỉnh cho Big Data phải tuân thủ các tiêu chuẩn phát triển phần mềm phù hợp, ví dụ bao gồm giao diện API được xác định rõ, điều này sẽ giúp các nhà phát triển truy cập vào các funtions bởi mỗi lớp thông qua các interfaces.
IV. Discussion and Future Work
Bây giờ rõ ràng là Big Data quá lớn, quá nhanh và quá chênh lệch dữ liệu mà không thể được xử lý bởi các kiến trúc cơ sở dữ liệu truyền thống và cần các hệ thống tinh vi đặc biệt. "Big data" vẫn được coi là khái niệm và thị trường của công nghệ này vẫn đang phát triển nhưng sẽ phát triển trong năm năm tới. Các nghiên cứu cho thấy trong điều kiện trạng thái bình thường, thị trường Big Data sẽ tăng gần gấp đôi trong giai đoạn 2015-2020, tăng từ khoảng 38 tỷ USD năm 2015 lên hơn 76 tỷ USD vào năm 2020 (50).
Rõ ràng là việc phát triển các công nghệ Big Data để xử lý dữ liệu lớn hơn và dữ liệu thời gian thực, và từ nhiều thiết bị hơn đã từng sẽ là kế hoạch chuẩn cho tương lai, trong khi các nhà nghiên cứu xem xét nó như là phần mở rộng cho phương pháp hiện tại. Trên thực tế các nhà nghiên cứu đang mong muốn tận dụng dữ liệu ở mức độ sâu hơn để có được thông tin chi tiết hơn so với các điểm dữ liệu thông thường đang được trích xuất hiện nay. Dữ liệu hiện đang được phân tích để tìm ra câu trả lời cho các câu hỏi truyền thống: “khi nào? Lá Gì? Bao nhiêu? Bao lâu?”, chúng được trả lời bởi các điểm dữ liệu số và được gọi là “Big data 1.0". Trong tương lai, các nhà nghiên cứu lên kế hoạch để phân tích Big data sâu hơn để tìm câu trả lời cho câu hỏi “tại sao?”, họ nghiên cứu lớp cảm xúc nằm phía sau các con số được tính toán; các nhà nghiên cứu gọi đây là "Big data 2.0". Big data mới sẽ đạt được sau khi phát triển phân tích văn bản, cho phép xử lý dữ liệu tìm kiếm theo cụm từ và các mẫu để giải thích các motivations đằng sau kết quả đã kết luận. (51)
Chúng ta vẫn đang ở giai đoạn đầu của kỷ nguyên Big data và vẫn còn nhiều điều để khám phá. Big data là từ khóa hay nhưng nhiều người không biết nhiều về nó. Cho đến nay các tập đoàn phần mềm lớn không sở hữu hoặc không thị trường hóa các giải pháp cho Big Data, ví dụ các công ty như Google không sử dụng giải pháp Big Data của họ theo cách thương mại. Nếu các công ty muốn sử dụng Big Data, họ nên xây dựng chiến lược đã được xác định rõ để thực hiện. Có nhiều cách tiếp cận khác nhau để triển khai các giải pháp Big Data. Cách thứ nhất là cách tiếp cận mang tính cách mạng, nghĩa là công ty thiết lập một môi trường tính toán Big Data mới và chuyển tất cả dữ liệu sang nền tảng mới, vì vậy tất cả các quá trình xử lý, phân tích, báo cáo và lập mô hình được thực hiện thông qua tình báo và phân tích kinh doanh mới. Rất nhiều công ty phân tích theo định hướng đã triển khai phương pháp này và chuyển dữ liệu của họ sang môi trường Hadoop và trên hết là họ xây dựng các giải pháp kinh doanh thông minh. Ngoài ra còn có cách tiếp cận tiến hóa trong đó Big Data được xử lý bằng nền tảng BI truyền thống hiện tại. Dữ liệu được thu thập và phân tích thông qua các công cụ có cấu trúc và không có cấu trúc và sau đó đầu ra được chuyển tiếp đến kho dữ liệu. Các tiện ích báo cáo và lập mô hình truyền thống giờ đây có thể truy cập suy nghĩ và bản ghi trực tuyến từ các nguồn truyền thông xã hội. Tuy nhiên, ngay cả khi cách tiếp cận tiến hóa đáp ứng được nhiều yêu cầu của môi trường Big Data, nó vẫn có hầu hết các vấn đề của BI cổ điển, nó có thể trở thành một nút cổ chai giữa thông tin trực tuyến từ các nguồn Big Data và phân tích sức mạnh của biến đổi BI hoặc kho dữ liệu. Cách tiếp cận thứ ba là phương pháp lai mà cả công nghệ Dữ liệu lớn truyền thống và mới được sử dụng và dữ liệu được phân phối giữa hai, một ví dụ về cách tiếp cận như vậy là giải pháp Hana từ SAP. (52)
V. References
https://www.sas.com/en_us/insights/big-data/hadoop.html https://www.researchgate.net/publication/282281171_Big_Data_Challenges https://searchbusinessanalytics.techtarget.com/definition/ad-hoc-analysis https://www.guru99.com/online-analytical-processing.html https://opensource.com/life/14/8/intro-apache-hadoop-big-data https://www.information-management.com/slideshow/20-top-platforms-for-analytics-and-business-intelligence https://www.sap.com/products/hana.html
All rights reserved
