Big Data challenges - Part 1
Bài đăng này đã không được cập nhật trong 7 năm
Mình mới tìm hiểu về lĩnh vực này và tìm được một bài khá hay muốn chia sẻ với mọi người. Hi vọng những ai cũng có hứng thú với Big Data sẽ tìm được kiến thức gì đó bổ ích với bản thân mình từ bài dịch này, hơn nữa bài này đa phần là chữ và nội dung khá dài nên mình sẽ chia nó thành 2 phần để đỡ gây nhàm chán với người đọc 
I. Abstract
Dữ liệu khổng lồ, đa dạng và bền vững đã lan tràn nhanh chóng ra khắp nơi gọi là kỷ nguyên Big Data. Loại dữ liệu này trở thành nguồn tài nguyên vô cùng quan trọng cho những thông tin có giá trị và giúp tạo ra những thông tin sang suốt hơn. Tuy nhiên, nó cùng với những thuộc tính rất đặc biệt không thể được quản lý và xử lý bởi những hệ thống phần mềm truyền thống hiện nay, đó đã trở thành 1 vấn đề thực tế. Nghiên cứu này sẽ thảo luận về tất cả các thách thức khác nhau của Big Data được phân loại thành ba nhóm chính: các thách thức về dữ liệu, quy trình và quản lý. Thách thức dữ liệu là nhóm những thách thức liên quan đến các đặc điểm của chính dữ liệu. Nhóm xử lý bao gồm tất cả những thách thức gặp phải trong khi xử lý Dữ liệu lớn; bắt đầu với bước lấy dữ liệu và kết thúc bằng cách trình bày đầu ra cho clients.
Nhóm quản lý bao gồm các vấn đề pháp lý và đạo đức liên quan đến việc truy cập dữ liệu. Tham chiếu kiến trúc phân lớp được gọi là ngăn xếp công nghệ dữ liệu lớn sẽ được trình bày như khung giải pháp lý thuyết cho những thách thức của Big Data. Mỗi lớp sẽ cung cấp các công nghệ cần thiết để vượt qua thử thách khác nhau nhưng tất cả các lớp này cần cung cấp giải pháp hoàn chỉnh. Phát triển công nghệ liên tục đòi hỏi phải cải tiến phân tích Big Data mới để tìm hiểu kỹ hơn về dữ liệu tìm kiếm, có giá trị hơn và phát hành phiên bản Big Data 2.0 mới.
II.Introduction
Vấn đề đề cập trong bài nghiên cứu này là những thách thức của BigData và để nhận ra được những thách thức này, 2 câu hỏi quan trọng cần được trả lời đó là Thế nào là Big Data? và Những đặc tính của Big Data là gì?. Thuật ngữ Big Data là một chỉ định nhỏ không chính xác bởi vì nó có nghĩa là dữ liệu từ trước là nhỏ, trong khi nó thực sự không phải vậy và nó cũng chỉ ra rằng kích thước dữ liệu là một thách thức mà chúng ta đang phải đối mặt (1). Đơn giản, Big Data đề cập đến dữ liệu và thông tin mà chúng không thể được xử lý hoặc xử lý thông qua các hệ thống phần mềm truyền thống hiện tại. Big Data là bộ dữ liệu có cấu trúc và phi cấu trúc lớn cần được xử lý bằng các kỹ thuật phân tích nâng cao và các kỹ thuật trừu tượng để khám phá các mẫu ẩn và tìm các mối tương quan chưa biết giúp cải thiện tiến trình đưa ra quyết định. Nhiều tổ chức có dung lượng dữ liệu khổng lồ, nhưng họ không thể sử dụng nó vì nó vẫn ở dạng thô, nửa cấu trúc hoặc không cấu trúc nên rất khó để nhận ra. Doanh nghiệp phải đối mặt với một thách thức thực sự khi dữ liệu chồng chất lên nhau, vì vậy phần trăm dữ liệu có thể được xử lý đang giảm xuống (2). Con người hiện đang sống trong kỷ nguyên Big Data do sự phát triển nhanh chóng của công nghệ. Nhạc cụ đã giúp chúng ta cảm nhận mọi thứ xung quanh và với khả năng lưu dữ liệu đo được đầy đủ hoặc một phần. Ngoài ra những tiến bộ trong viễn thông và công nghệ mạng tạo ra dễ dàng hơn sự kết nối của con người và sự vật, ví dụ như người dân có thể giám sát từ xa từ văn phòng vẫn biết được tiến độ dự án đang diễn ra hàng ngàn dặm. Hơn nữa, sự phát triển liên tục của các bảng mạch điện giúp tăng thêm sự thông minh trên các thiết bị khắp mọi nơi (3). Ví dụ, các công ty đường sắt bắt đầu cài đặt cảm biến trong xe của họ để theo dõi tình trạng của tất cả các bộ phận và tất cả các tình huống phải đối mặt và để giảm khả năng xảy ra tai nạn xe lửa. Các bài đọc được lưu trữ và phân tích để sử dụng sau này để xác định ví dụ các bộ phận cần được sửa chữa hoặc thay thế trước khi gây ra nhiều thiệt hại hơn (4). Ngoài ra, trí thông minh cũng được thêm vào đường ray, các cảm biến được cài đặt trên khoảng cách vài bước chân để cung cấp giám sát trực tuyến cho tất cả các sự kiện bên ngoài.
Các con đường được trang bị cảm biến để đọc tất cả các sự kiện liên quan đến thời tiết nhằm tránh mọi thảm họa xảy ra. Hệ thống tự động bao phủ mạng lưới giao thông sẽ tạo ra khối lượng dữ liệu khổng lồ, đa dạng và thô mà các hệ thống truyền thống không thể xử lý được hoàn toàn (5); ở đây một vấn đề Big Data được tạo ra. Ban đầu dữ liệu lớn được đặc trưng bởi 3Vs: dung lượng, đa dạng và vận tốc, như thể hiện trong hình sau: (6)

Công nghệ Big Data rất thuận lợi vì nó cung cấp cho doanh nghiệp ba giá trị chính: giảm chi phí, cải thiện việc ra quyết định và cải thiện sản phẩm và dịch vụ (7). Việc giảm chi phí thu được từ Big Data có thể trực tiếp hoặc gián tiếp. Trực tiếp một số công ty theo ý tưởng rằng sức mạnh xử lý (MIPs: triệu lệnh mỗi giây) và dung lượng lưu trữ (terabyte) rẻ hơn nếu được cung cấp bởi công nghệ Big Data như hệ thống Hadoop. Ví dụ một công ty đã so sánh giữa chi phí hàng năm của một terabyte trên các hệ thống khác nhau và thấy rằng chi phí 37k$ cho hệ thống cơ sở dữ liệu truyền thống, 5K$ cho một ứng dụng cơ sở dữ liệu và chỉ 2K$ cho cụm Hadoop. Một cách gián tiếp, việc phân tích dữ liệu lớn đã giúp đưa ra quyết định cắt giảm chi phí. Ví dụ: United Parcel Service (UPS), công ty cung cấp gói hàng lớn nhất toàn cầu, đã sử dụng.
Big Data được thu thập để theo dõi chuyển động của các gói từ những năm 1980 và nó duy trì trên 16 petabyte được thu thập bởi cảm biến được cài đặt trên khoảng 46.000 xe. Dữ liệu này không chỉ được sử dụng để theo dõi hiệu suất của các trình điều khiển UPS mà chủ yếu là thiết kế lại đường dẫn của các trình điều khiển và cấu hình lại hoạt động pick-up và drop-off trong thời gian thực. Dự án này được gọi là On Road Integrated Optimization và Navigation (ORION) đã lưu UPS trong năm 2011 hơn 8,4 triệu gallon nhiên liệu, khoảng 30 triệu USD. (8)
Một nghiên cứu gần đây cho thấy 90% các giám đốc điều hành tin rằng dữ liệu trở thành yếu tố thứ tư của sản xuất cho doanh nghiệp cần thiết như đất đai, lao động và vốn. Do đó thuật ngữ data-driven decision making ra đời để mô tả quá trình thu thập và phân tích dữ liệu để hướng dẫn hoặc cải thiện các quyết định (9). Điều này liên quan đến việc phân tích dữ liệu phi giao dịch và phi cấu trúc như ý tưởng sản phẩm hoặc đánh giá do người tiêu dùng tạo ra. Trong thực tế, các chuyên gia dữ liệu khám phá dữ liệu lớn được thu thập từ các phương tiện truyền thông xã hội để nghiên cứu thực địa để kiểm tra giả thuyết cụ thể và kết quả là họ có thể xác định giá trị, tính hợp lệ và tính khả thi của những ý tưởng này và chuẩn bị kế hoạch thực hiện chúng. Các quyết định của các nhà khoa học đang sử dụng một số công cụ nghe để tiến hành phân tích văn bản và tình cảm và thông qua các công cụ này các công ty có thể đo lường một số khía cạnh nhất định về sự quan tâm các sản phẩm của họ và thực hiện các biện pháp cải thiện. Ví dụ trước khi một sản phẩm đưa vào thị trường, những người tiếp thị muốn biết người tiêu dùng sẽ cảm thấy thế nào về giá cả, cảm giác này sẽ thay đổi như thế nào từ khu vực này sang khu vực khác và thay đổi như thế nào theo thời gian. Dựa trên phân tích kết quả của các thử nghiệm này, các nhà tiếp thị có thể điều chỉnh giá để đảm bảo tỷ lệ tạo ra cao của sản phẩm (10). Một ví dụ khác, Caesars một công ty game hàng đầu đã siết chặt Big Data Technology để cải thiện quy trình ra quyết định của mình. Công ty này đang thu thập dữ liệu về khách hàng của mình thông qua các nguồn như chương trình khách hàng thân thiết của Total Rewards, luồng nhấp chuột trên web và chơi trong thời gian thực trên các máy xèng. Nó đang sử dụng dữ liệu này để hiểu khách hàng, nhưng vấn đề là làm thế nào để giải thích dữ liệu này và hành động phù hợp trong thời gian thực trong khi khách hàng vẫn đang đứng ở máy và chơi. Caesars đã nhận ra rằng nếu một khách hàng mới không may mắn ở các máy xèng; có khả năng anh ấy sẽ không bao giờ quay lại.
Tuy nhiên, nếu công ty này tặng quà anh ta, ví dụ như một phiếu giảm giá bữa ăn miễn phí trước khi anh ấy rời khỏi máy đánh xèng, anh ấy có nhiều khả năng sẽ truy cập lại vào sòng bạc một lần nữa. Khái niệm ở đây là yêu cầu phân tích thời gian thực về tình hình và cung cấp phiếu giảm giá trước khi khách hàng biến mất một cách không thoải mái. Caesars đã triển khai các cụm Hadoop và phân tích các phần mềm cần thiết, tất nhiên cần thuê một số chuyên gia dữ liệu để vận hành hệ thống phân tích (11). Ngoài ra, việc tạo ra các sản phẩm và dịch vụ hấp dẫn từ Big Data là một cơ hội lớn khác và có rất nhiều ví dụ về các sản phẩm và dịch vụ thành công xuất phát từ Big Data. Ví dụ, tại LinkedIn có một tính năng cụ thể mà chắc chắn đã thêm giá trị cao cho công ty này là những người bạn có thể biết (PYMK). Hầu hết người dùng LinkedIn đã sử dụng tính năng PYMK để gợi ý cho các thành viên LinkedIn một số thành viên khác mà họ muốn kết nối. Các tính năng của PYMK thu thập chi tiết các kết nối này bằng cách chạy phương pháp đa nhân tố để tìm ra các thành viên được đề xuất dựa trên các tiêu chí như trường học, sự kết nối, các trường đại học và khoảng cách địa lý. Số lượng khách hàng cho LinkedIn đã tăng lên rất nhiều bởi tính năng PYMK. LinkedIn nhận thấy rằng các hòm thư PYMK đã đạt được tỷ lệ nhấp chuột cao hơn 30% so với các lệnh khác được gửi đi để khuyến khích mọi người truy cập lại trang web một lần nữa. (12)
Quá trình phân tích Big Data gồm nhiều giai đoạn bao gồm thu thập và bắt lấy dữ liệu, trích xuất thông tin và làm sạch, tích hợp dữ liệu, tổng hợp và trình bày, xử lý truy vấn và phân tích và mô hình hóa dữ liệu cũng như cách diễn giải và thuyết trình. Mỗi giai đoạn có những trở ngại riêng của nó (13). Dữ liệu ngày càng tăng và chảy rất nhanh được tạo ra bởi các thiết bị di động, cảm biến, phương tiện truyền thông xã hội, email, trang web ... vv đang góp phần vào vụ nổ dữ liệu lớn. Tuy nhiên, các tổ chức cần thu thập, lưu trữ và thúc đẩy giá trị ra khỏi luồng dữ liệu này. (14)
Mục đích của nghiên cứu này là thảo luận tất cả các loại thách thức khác nhau của Big Data và từ đó để ngoại suy và xây dựng kiến trúc tham chiếu lớp được sử dụng như một giải pháp khái niệm để quản lý hiệu quả Big Data bất kể mọi khó khăn gặp phải.
Sau khi hiểu Big data có ý nghĩa gì và tại sao nó quan trọng, giờ là lúc chúng ta phải biết những thách thức của Big Data. Phần nghiên cứu 2 sẽ thảo luận chi tiết từng thử thách. Sau đó, trong phần 3 nó sẽ trình bày tất cả các khả năng có thể để vượt qua từng thách thức khác nhau. Sau đó trong phần 4, sẽ thảo luận về tương lai của Big Data trước khi đi đến kết luận cùng với các đề nghị và gợi ý.
III.Challenges
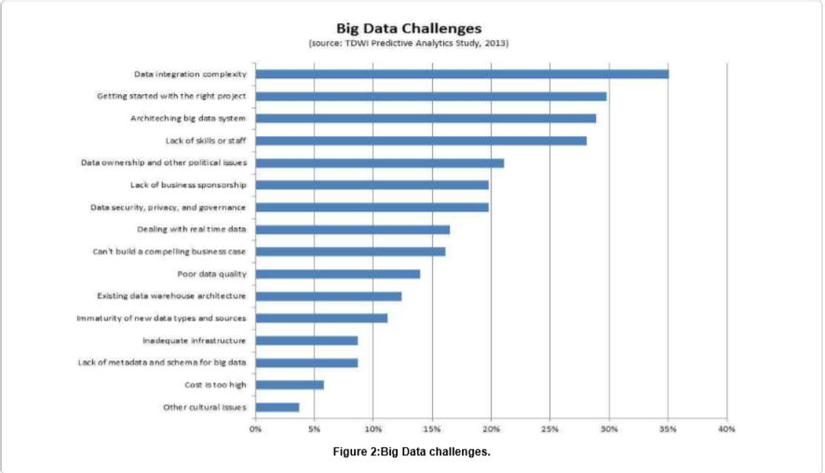
Big data cung cấp cho tổ chức với thông tin chi tiết khổng lồ; tuy nhiên, terabyte hoặc petabyte dữ liệu chảy mỗi ngày đến một tổ chức đã tiết lộ ra rằng cơ sở hạ tầng và kiến trúc hiện tại không đủ để đáp ứng thách thức. Các nhà khoa học CNTT có trách nhiệm cung cấp công nghệ có khả năng quản lý tất cả các yêu cầu kỹ thuật của các luồng dữ liệu khổng lồ. Các chuyên gia CNTT đang nhận được nhiều cuộc gọi hơn khi dữ liệu lớn lên; các yêu cầu dành cho phân tích Ad-Hoc và báo cáo tóm tắt hơn. Người ra quyết định không thể đợi hàng giờ hoặc hàng ngày để tìm câu trả lời cho các truy. Người dùng cuối cũng sẽ cần có phương tiện để truy cập, hiểu và phân tích dữ liệu này mà không cần phải trả lại IT cho mọi yêu cầu (15). Đây là những ví dụ về những thách thức của Big Data có thể được nhóm lại thành ba loại chính dựa trên vòng đời dữ liệu: các thách thức về dữ liệu, quy trình và quản lý. Thách thức dữ liệu là những thách thức liên quan đến đặc điểm của chính dữ liệu, ví dụ khối lượng dữ liệu, sự đa dạng, vận tốc, tính xác thực, biến động, chất lượng, khám phá và thuyết pháp. Đây là những ví dụ về những thách thức của Big Data có thể được nhóm lại thành ba loại chính dựa trên vòng đời dữ liệu: các thách thức về dữ liệu, quy trình và quản lý. Thách thức dữ liệu là những thách thức liên quan đến đặc điểm của chính dữ liệu, ví dụ khối lượng dữ liệu, sự đa dạng, vận tốc, tính xác thực, biến động, chất lượng, khám phá và thuyết pháp. Nhóm thứ hai là những thách thức về quy trình liên quan đến chuỗi các kỹ thuật: cách thu thập dữ liệu, cách tích hợp dữ liệu, cách chuyển đổi dữ liệu, cách chọn mô hình phù hợp để phân tích và cách cung cấp kết quả. Loại thứ ba là những thách thức quản lý bao gồm tất cả các khía cạnh riêng tư, bảo mật, quản trị và đạo đức. (16)
1.Data challenges
Thách thức dữ liệu là nhóm các thách thức liên quan đến các đặc điểm của chính dữ liệu và các đặc điểm này như sau:
Dung lượng: Số lượng dữ liệu được lưu trữ tăng đáng kể mỗi phút, khoảng 800.000 PB dữ liệu được lưu trữ trên toàn thế giới vào năm 2000, dự kiến sẽ tăng lên 35 ZB vào năm 2020. Facebook tạo ra khoảng 10 TB mỗi ngày, Twitter tạo ra khoảng 7 TB và một số doanh nghiệp tạo ra terabyte mỗi giờ. (17)
Vì vậy, nó trở nên bình thường để có sức chứa dữ liệu trong giới hạn petabyte (PB).
Ngày nay chúng ta đang theo dõi và ghi lại mọi dữ liệu môi trường, dữ liệu kinh doanh, dữ liệu y tế, dữ liệu giám sát, (18) v.v. Do thiết bị đo đạc, máy tự động ghi lại mọi sự kiện, ví dụ máy ATM lưu trữ mọi giao dịch sao lưu, cửa truy cập lưu trữ mọi sự kiện truy cập và hệ thống hãng hàng không lưu trữ tất cả yêu cầu check-in, Giám sát máy ảnh lưu trữ vi phạm tốc độ cao. Do đó, chúng ta có một lượng lớn dữ liệu không thể được quản lý bởi hệ thống truyền thống hiện tại. Thách thức trở nên rõ ràng ở đây khi các luồng dữ liệu trong doanh nghiệp đang gia tăng và tỷ lệ dữ liệu có thể được xử lý đang giảm dần, từ đó tạo ra cái được gọi là khu vực mù (19). Vùng này chỉ ra dữ liệu "bạn không biết", chúng có thể có tầm quan trọng lớn hoặc không có gì cả, như được hiển thị trong hình dưới đây

Đa dạng: Khối lượng dữ liệu khổng lồ do hiện tượng Big Data đưa ra đã đưa ra thách thức mới, đó là sự đa dạng của các kiểu dữ liệu và định dạng. Sự lan truyền to lớn của các cảm biến, thiết bị thông minh và công nghệ cộng tác xã hội đã làm cho dữ liệu trong doanh nghiệp phức tạp vì nó không chỉ bao gồm kiểu dữ liệu truyền thống mà còn cả dữ liệu thô, bán cấu trúc và phi cấu trúc được thu thập từ các trang web, email, diễn đàn truyền thông xã hội, chỉ mục tìm kiếm, âm thanh và video… (20). Chỉ có khoảng 20% dữ liệu có thể được xử lý bởi các hệ thống truyền thống hiện tại và 80% còn lại không được phân tích và do đó không được sử dụng cho quá trình ra quyết định và hiểu biết. Một thách thức khác của Big Data xuất hiện ở đây do đặc tính đa dạng (1).
Vận tốc: Đặc tính vận tốc có thể được xác định bởi dung lượng của ứng dụng phần mềm hiện tại để xử lý và xử lý luồng dữ liệu được tạo liên tục và liên tục với tốc độ, vì vậy chúng trở nên quan trọng do thời hạn sử dụng ngắn của dữ liệu cần được phân tích gần như thời gian thực nếu chúng ta dự định tìm thông tin chi tiết về dữ liệu đó. Điều này bổ sung thêm thách thức mới cho Big dâta cần được phân tích khi nó đang chuyển động (21).
Tính xác thực: Điều này đề cập đến các thành kiến, sự không chắc chắn, không trung thực và giá trị bị thiếu trong dữ liệu. Tính năng này đo lường độ chính xác của dữ liệu và khả năng sử dụng nó để phân tích. Mức độ chính xác của các tập dữ liệu tích lũy vào hệ thống của chúng ta sẽ xác định mức độ quan trọng của dữ liệu này cho vấn đề đang được nghiên cứu và một số nhà nghiên cứu tin rằng đây là thách thức lớn nhất của Big Data. (22)
Biến động: Biến động dữ liệu biểu thị thời gian dữ liệu hợp lệ, trong bao lâu chúng ta nên giữ nó trong cơ sở dữ liệu. Thế giới hiện nay dựa nhiều hơn vào dữ liệu thời gian thực và điều quan trọng là phải biết tại thời điểm nào dữ liệu không còn được áp dụng cho phân tích. (23)
Chất lượng: Đặc tính chất lượng đo lường thế nào là dữ liệu đáng tin cậy để được sử dụng cho việc đưa ra quyết định. Nói rằng chất lượng dữ liệu cao hay thấp về cơ bản phụ thuộc vào bốn thông số:
- Trọn vẹn: tất cả dữ liệu có liên quan đều có sẵn, ví dụ như tất cả chi tiết của nhà cung cấp như tên, địa chỉ, tài khoản ngân hàng, v.v ...
- Chính xác: dữ liệu không bị lỗi chính tả, lỗi đánh máy, sai cụm từ và chữ viết tắt
- Sẵn sàng: dữ liệu có sẵn khi được yêu cầu và dễ tìm
- Kịp thời: dữ liệu được cập nhật và sẵn sàng hỗ trợ đưa ra quyết định (24)
Khám phá: Điều này đề cập đến cách lọc ra dữ liệu chất lượng cao liên quan đến các vấn đề đang lo lắng từ luồng dữ liệu không ngừng lớn lên. (5)
Giáo lý: Sự sáng suốt có giá trị được trích xuất từ việc phân tích dữ liệu lớn, nhưng chúng ta không cần bắt buộc lúc nào cũng phải có các con số. Chúng ta nên tham khảo ý kiến các chuyên gia, áp dụng ý thức chung và phản ứng với các sự kiện xung quanh. Ví dụ: sẽ là không đúng, nếu chỉ thực hiện các biện pháp phòng ngừa dịch cúm khi Google Flu Trends cho chúng ta biết. (25)
2. Process challenges
Nhóm này bao gồm tất cả các thách thức gặp phải trong khi xử lý Big data; bắt đầu với bước bắt dữ liệu và kết thúc bằng cách trình bày đầu ra cho khách hàng, để hiểu bức tranh tổng thể, như được hiển thị trên hình dưới đây (26)
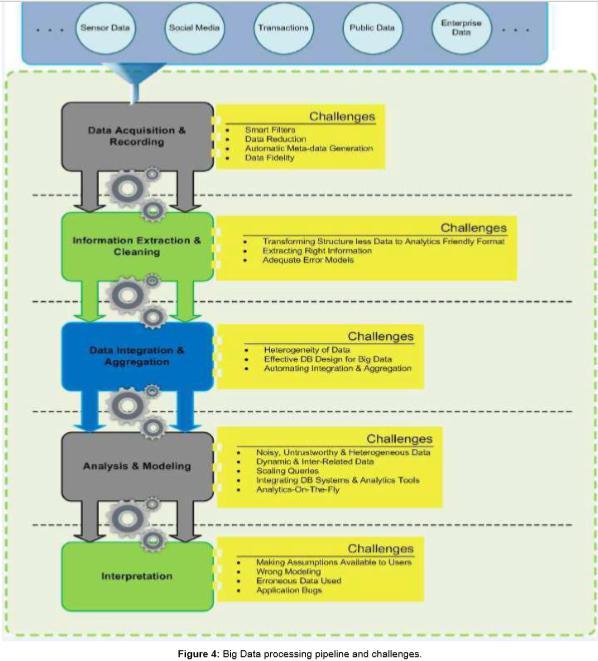
Nhìn chung, các thử thách khi xử lý dữ liệu là:
Thu thập và ghi dữ liệu: Big data không đến từ không gian, nên có một nguồn sản xuất dữ liệu này. Chúng ta có thể cảm nhận được bất cứ thứ gì xung quanh chúng ta, bắt đầu bằng cách hình thành nhịp tim của công dân già, đến kiểm tra sự tồn tại của các độc tố trong không khí và cuộc công kích kính thiên văn thế hệ mới toàn cầu được gọi là kính thiên văn mảng km vuông được ước tính tạo ra một triệu terabyte mỗi ngày. Tương tự như vậy ngày nay các thí nghiệm khoa học có thể tạo ra petabyte dữ liệu. Liệu ta có quan tâm đến tất cả dữ liệu này không? Câu trả lời là không, chúng ta có thể lọc ra và nén nó theo thứ tự độ lớn của dữ liệu. Cách xác định các bộ lọc này là thách thức thực sự vì chúng phải thông minh để phân biệt giữa những gì hữu ích để nắm bắt và những gì vô dụng để loại bỏ. Ví dụ giả sử một cảm biến đang đưa ra các bài đọc khác với phần còn lại, điều này có thể sảy ra bởi cảm biến bị lỗi, tuy nhiên làm thế nào chúng ta có thể chắc chắn rằng đó không phải là một hiện vật cần một sự xem xét chi tiết hơn.
Ngoài ra, dữ liệu này được thu thập từ các cảm biến thường liên quan đến không gian và thời gian, ví dụ, các cảm biến giao thông được cài đặt trên cùng một con đường. Hầu hết các nghiên cứu nên tiến hành về khoa học giảm kích thước dữ liệu, chúng có thể xử lý dữ liệu thành dung lượng có thể quản lý và đồng thời bảo vệ người dùng khỏi bị mất. Ngoài ra, thuật toán phân tích trực tuyến cũng được yêu cầu để xử lý dữ liệu phát trực tuyến và giảm kích thước dữ liệu trước khi lưu trữ.
Thách thức lớn thứ hai trong lĩnh vực này là sự tự động tạo siêu dữ liệu, mô tả dữ liệu được ghi lại, cách dữ liệu được ghi lại và đo lường. Ví dụ, trong các thí nghiệm khoa học, cần phải có nhiều chi tiết về điều kiện và thủ tục được yêu cầu để ngắt kết quả đúng cách và là cần thiết để lưu siêu dữ liệu này với kiểu dữ liệu quan sát, hệ thống thu thập siêu dữ liệu đặc biệt cần thiết để giảm thiểu tải trọng từ con người. Xuất xứ dữ liệu trở thành một vấn đề lớn bởi vì ghi lại nguồn gốc của dữ liệu và sự chuyển động của nó trong đường ống xử lý sẽ giúp xác định các bước xử lý tiếp theo phụ thuộc rõ ràng vào bước hiện tại. Ví dụ, nếu lỗi xử lý xảy ra ở một giai đoạn, tất cả các phân tích tiếp theo sẽ là vô ích. Vì vậy nghiên cứu cũng nên được tiến hành ở đây để phát triển hệ thống giúp tạo ra siêu dữ liệu phù hợp và để đưa ra xuất xứ của dữ liệu thông qua các giai đoạn khác nhau của đường ống phân tích dữ liệu. (27)
Lấy dữ liệu và làm sạch: Các dữ liệu thu thập được chủ yếu là không ở định dạng yêu cầu để xử lý. Ví dụ, hồ sơ y tế của bệnh viện bao gồm các báo cáo y tế, đơn thuốc, các bài đọc được thu thập từ các cảm biến và máy theo dõi và dữ liệu hình ảnh như tia X. Chúng ta có thể sử dụng dữ liệu này một cách hiệu quả trong khi chúng ở các dạng khác nhau không? Câu trả lời là không. Chúng ta cần xây dựng một quy trình trích xuất để lấy ra các thông tin cần thiết từ nguồn dữ liệu lớn và xây dựng nó theo một dạng chuẩn và có cấu trúc sẵn sàng để phân tích. Tạo và duy trì quy trình này một cách chính xác là một thử thách kéo dài. Thiết kế của quá trình rút ra là phụ thuộc lớn vào loại ứng dụng, ví dụ như dữ liệu bạn rút ra từ MRI là khác của việc kéo ra từ hình ảnh của các ngôi sao. Hơn nữa do tính phổ biến của camera giám sát và thiết bị hỗ trợ GPS như máy ảnh, điện thoại di động, thiết bị điều hướng và các thiết bị cổng thông tin khác, dữ liệu phụ thuộc vào vị trí và phong phú có thể được trích xuất.
Dữ liệu lớn không phải lúc nào cũng nói sự thật, nó có thể mang theo một số thông tin giả mạo. Ví dụ bệnh nhân có thể cố tình che giấu một số hành vi nguy hiểm hoặc các triệu chứng có thể dẫn bác sĩ chẩn đoán sai bệnh; hoặc đôi khi bệnh nhân có thể cung cấp sai tên của các loại thuốc mà họ đã dùng trước đó dẫn đến hồ sơ y tế không chính xác. Điều này sẽ đòi hỏi phải sử dụng các kỹ thuật làm sạch dữ liệu bao gồm các ràng buộc được kiểm soát tốt đối với dữ liệu hợp lệ và các mô hình lỗi được xác minh tốt để đảm bảo chất lượng của dữ liệu. Tuy nhiên, các mô hình kiểm soát chất lượng cho hầu hết các Mô hình dữ liệu lớn vẫn không có sẵn, đại diện cho một thách thức lớn khác. (28)
Tích hợp và tổng hợp dữ liệu: Luồng dữ liệu lớn là dị thể, phức tạp và không đồng nhất, do đó nó là không đủ để bắt và lưu trữ trong kho lưu trữ của chúng ta. Ví dụ, nếu chúng ta lấy dữ liệu của một số thí nghiệm khoa học, nó sẽ là vô dụng để lưu chúng như là một loạt các tập dữ liệu. Không có khả năng ai đó sẽ tìm thấy dữ liệu này hoặc đưa dữ liệu vào bất kỳ phân tích nào. Tuy nhiên, nếu dữ liệu có siêu dữ liệu chất lượng và đầy đủ, nó có thể được sử dụng nhưng thách thức vẫn phát sinh từ sự khác biệt về chi tiết thử nghiệm và cấu trúc bản ghi dữ liệu lưu trữ. Phân tích dữ liệu là một quá trình tinh vi và đơn giản hơn là tìm kiếm, định danh, hiểu và trích dẫn dữ liệu. Thực hiện phân tích dữ liệu ở quy mô lớn yêu cầu tự động hóa tất cả các bước này. Điều này cần thể hiện các cấu trúc dữ liệu và ngữ nghĩa khác nhau dưới dạng mà máy tính có thể hiểu và sau đó tự động giải quyết. Rất nhiều công việc đã được tiến hành trong lĩnh vực tích hợp dữ liệu, tuy nhiên vẫn còn nhiều cần nỗ lực bổ sung cần thiết để đạt được giải pháp khác nhau mà không có lỗi tự động.
Hiệu quả của việc phân tích dữ liệu chủ yếu phụ thuộc vào thiết kế cơ sở dữ liệu. Cùng một tập dữ liệu có thể được lưu trữ theo các ý nghĩa khác nhau, một số thiết kế sẽ có ưu điểm hơn và có thể bất lợi cho các lĩnh vực khác, ví dụ như sự khác biệt trong cấu trúc của cơ sở dữ liệu tin sinh học lưu trữ thông tin về các thực thể tương tự như gen. Thiết kế cơ sở dữ liệu trở thành một nghệ thuật và những người chịu trách nhiệm về vai trò đó trong các tổ chức lớn nên được trả một mức lương hậu hĩnh. Mặt khác, các chuyên gia trong lĩnh vực này có thể tự mình tạo ra các thiết kế cơ sở dữ liệu hiệu quả để cung cấp cho họ các công cụ thông minh để giúp họ trong quá trình thiết kế hoặc hoàn toàn bỏ qua quá trình thiết kế và phát triển các kỹ thuật để sử dụng hiệu quả cơ sở dữ liệu. (29)
Xử lý truy vấn, mô hình hóa dữ liệu và phân tích: Các kỹ thuật truy vấn và khai thác dữ liệu lớn khác nhau đáng kể so với các dữ liệu được sử dụng để phân tích các tập dữ liệu truyền thống. Dữ liệu lớn thường là dữ liệu nhiễu, không đáng tin cậy, không đồng nhất, động và được kết nối với nhau. Tuy nhiên, dữ liệu lớn nhiễu có thể hữu ích hơn các mẫu dữ liệu nhỏ vì các số liệu thống kê chung có thể được trích xuất từ các mẫu lặp lại và phân tích tương quan thường áp đảo các biến thể riêng lẻ và tiết lộ nhiều kiến thức ẩn. Ngoài ra Big Data tạo thành một mạng kết nối lớn thông tin không đồng nhất, thông tin dư thừa có thể được phân tích để bù đắp dữ liệu còn thiếu, kiểm tra các mối quan hệ không đáng tin cậy, để xác minh các điều kiện mâu thuẫn và tiết lộ các mô hình ẩn.
Có một số yêu cầu để khai thác dữ liệu như dữ liệu được làm sạch, tích hợp, đáng tin cậy và dễ truy cập, giao diện truy vấn khai báo, thuật toán khai thác có thể mở rộng và môi trường tính toán mạnh mẽ. Đồng thời, việc khai thác dữ liệu có thể giúp cải thiện chất lượng và độ tin cậy của dữ liệu, giải thích ngữ nghĩa của nó và đề xuất các hàm truy vấn thông minh. Như đã thấy hồ sơ y tế có tính chất không đồng nhất được phân phối trên nhiều hệ thống và có lỗi. Ở đây tầm quan trọng của phân tích Big data được thực hiện khi áp dụng trong chăm sóc sức khỏe, ví dụ xem xét mạnh mẽ tất cả các điều kiện khó khăn trước đó. Mặt khác, kiến thức được trích xuất trong phân tích và khai thác có thể giúp sửa lỗi và loại bỏ sự mơ hồ. Ví dụ, một bác sĩ có thể chẩn đoán một trường hợp bệnh nhân là "DVT" được sử dụng để đề cập đến cả hai "Viêm màng phổi" và "Chứng huyết khối tĩnh mạch sâu", chúng ở hai điều kiện y tế không giống nhau. Đào sâu vào các dữ liệu liên quan như các triệu chứng hoặc thuốc sẽ giúp xác định những gì bác sĩ chuẩn đoán là có ý nghĩa.
Big Data là công cụ chính cho thế hệ tiếp theo của phân tích dữ liệu tương tác, cung cấp câu trả lời trong thời gian thực. Thế hệ mới này sẽ cho phép truy vấn luồng dữ liệu lớn ví dụ nội dung của các trang web để phổ biến danh sách hot, cung cấp đề xuất tức thì và cung cấp phân tích quảng cáo để quyết định xem nó có đáng để lưu trữ hoặc loại bỏ tập dữ liệu hay không. Các kỹ thuật quy trình truy vấn cần được phát triển để đáp ứng độ phức tạp của các terabyte dữ liệu lớn và để cho phép thời gian phản hồi tương tác, cần thêm nhiều nghiên cứu được tiến hành.
Các nhà phân tích của Big Data phàn nàn việc thiếu sự phối hợp giữa hệ thống cơ sở dữ liệu lưu trữ dữ liệu và có truy vấn SQL với các gói phân tích thực hiện các loại xử lý phi SQL khác nhau như khai thác dữ liệu và phân tích thống kê. Ngày nay các nhà phân tích bị trì hoãn bởi quá trình xuất dữ liệu chậm lần đầu từ cơ sở dữ liệu, thực hiện xử lý Non-SQL và cuối cùng nhập dữ liệu trở lại cơ sở dữ liệu. Điều này đại diện cho một trở ngại thực sự cho việc chạy tùy chọn tương tác của thế hệ đầu tiên của các hệ thống OLAP SQL-driven. Các gói phân tích trong tương lai sẽ có các ngôn ngữ khai báo truy vấn để nâng cao hiệu suất phân tích và lần lượt đưa ra quyết định đúng đắn về thời gian. (30)
Có lẽ mĩnh sẽ kết thúc phần I ở đây vì cũng đã quá dài rồi, phần còn lại mình sẽ viết ở part 2. Cảm ơn mọi người đã đọc bài
Reference
All rights reserved
