Bạn đã từng build AI agent bao giờ chưa?
Mình tên Hùng, hay còn gọi là Paul.
Mình đã làm việc trong ngành kỹ thuật 6 năm và đã bắt đầu tìm hiểu về LLM vào khoảng đầu năm 2023, khi ChatGPT vừa ra mắt và lúc đấy mọi người đều hỏi: “Cái này có thể dùng trên môi trường production được không?”. Mình đã tham gia xây dựng và triển khai hàng chục hệ thống AI Agent, RAG pipeline rồi. Mình cũng đã dành rất nhiều thời gian nghiên cứu tối ưu hoá, nhiều tuần trôi qua, nhiều sản phẩm ra đời. Một trong số những sản phẩm đó đó chưa thực sự đủ tốt mà mình nghĩ mình có thể biết cách tối ưu hóa tốt hơn. Mấy hôm trước vừa học xong một khóa về AWS Bedrock của Anthropic, mình bỗng nhớ lại khoảng thời gian đó. Thành thật mà nói, ngay từ đầu bọn mình đã bỏ qua một câu hỏi mà thời điểm ấy chẳng ai thắc mắc trước khi bắt tay vào làm. Mình nghĩ bài viết này sẽ giúp mọi người tránh lặp lại sai lầm tương tự:
“Làm thế nào để đo lường phản hồi của AI khi đưa lên môi trường production?”
Ý là, việc này không chỉ dừng lại ở phân tích hội thoại, thu thập log hay lấy feedback của người dùng sau khi ra mắt. Chúng ta cần đo lường phản hồi của AI ngay từ giai đoạn kiểm thử (testing), trước cả khi phát hành sản phẩm.
Năm 2024, bọn mình làm một trang web giúp mọi người học cách ứng dụng AI vào công việc thông qua qua trải nghiệm game hóa (gamified). Lúc đó mới chỉ có vài công cụ AI hỗ trợ code (coding agent), và tầm nhìn của bọn mình chỉ là giúp nhân sự trong ngành công nghệ làm quen với chúng, bởi vì bọn mình tin rằng các công cụ này sẽ tiếp tục phát triển và sớm trở thành xu hướng mới nhanh thôi. Bọn mình đã xây dựng một nền tảng tự học cùng AI và một môi trường sandbox trên cloud để người dùng thực hành (thực thi mã do AI tạo ra). Co-founder của mình luôn nói kiểu:
“Chúng ta phải đạt độ chính xác 95%”.
Nhưng không một ai biết 95% của cái gì? Của tập dữ liệu (dataset) nào? Hay của test case nào? Bọn mình không trả lời được những câu hỏi đó. Thế là bọn mình bắt đầu thử lập một list test cases dựa trên hiểu biết còn hạn chế của tester về lĩnh vực này và cộng thêm feedback từ người dùng. Mình từng tin rằng mình chỉ cần tập trung build (ship the product) rồi khách hàng sẽ đưa feedback để team có thể tự cải thiện (thật ngây thơ).
Và đó là một cái bẫy hoàn hảo. Mọi người trong team đều dốc hết sức để đưa sản phẩm đến tay người dùng. Tester viết test case dựa trên kinh nghiệm và hiểu biết của họ về lĩnh vực này. Developer hoàn thiện phần frontend bằng Next.js và backend bằng NestJS cùng LangGraph. Prompt Engineer chốt lại các system prompt cuối cùng. DevOps Engineer deploy lên cloud. Marketer bắt đầu chạy các chiến dịch quảng cáo trên mạng xã hội. Việc ai người nấy làm, bọn mình thu về khoảng 500 người dùng miễn phí mới và vỏn vẹn 3 feedback sau khi đã tiêu tốn một lượng lớn thời gian và tiền bạc.

Sau khi xem lại logs, mình nhận ra rằng người dùng cuối không bao giờ thao tác y hệt như các test case. Họ hành động theo cách mà không ai trong team ngờ tới. Họ dùng những từ ngữ khác. Họ đặt những câu hỏi lúng túng. Họ kết hợp những tình huống mà tester sẽ chẳng bao giờ viết vào kịch bản test. Các bài test của bọn mình đều pass, nhưng chúng lại không khớp với dữ liệu đầu vào thực tế của người dùng. Nhóm mình đưa ra những con số dựa trên cảm tính. Không có baseline, không có định nghĩa rõ ràng. Chỉ là cảm giác kiểu "trông có vẻ ổn". Vấn đề cốt lõi ở đây không phải là AI, vấn đề lớn nhất là chúng mình thiếu domain knowledge để viết ra những test case đủ tốt. Bọn mình đang test dựa trên những thành kiến của riêng mình, và những bias đó không đại diện cho người dùng thực tế.
Sai lầm của bọn mình: thiếu domain expert và thiếu các thước đo kiểm thử chính xác.
Bọn mình rơi vào một vòng lặp. Vòng lặp tối ưu hóa prompt. Team lắng nghe feedback của người dùng, điều chỉnh test case, sửa đổi system prompt, re-launch (ra mắt lại), lặp lại... Nhưng 3 cái feedback thì không bao giờ là đủ để cải thiện, quá ít. Cuối cùng, người dùng cứ thế rời đi và team buộc phải từ bỏ ý tưởng sau khi đã lãng phí cả một năm trời.
1. Tại sao đây là vấn đề về thiết kế hệ thống (design issue), chứ không chỉ là vấn đề của prompt?
Trước khi đi sâu vào thêm, mình muốn đính chính rằng mình viết bài này không phải là than vãn. Những người đồng đội cũ của mình đã làm rất tốt trong khả năng của họ. Chỉ là tại thời điểm đó, chúng mình chưa tìm ra phương pháp đúng đắn để giải quyết vấn đề.
Hầu hết các team phát triển đang xây dựng "outer harness" và gọi API LLM thông qua một nhà cung cấp. Họ thường không quan tâm đến "inter harness". Họ phó mặc điều đó cho các nhà cung cấp LLM.

- Inter Harness là gì? Nó bao gồm toàn bộ cơ sở hạ tầng bao quanh hệ thống phục vụ cho các mô hình LLM, tuân thủ post-training alignment (căn chỉnh sau huấn luyện - một dạng prompt đặc biệt không thể thay đổi, mạnh hơn system prompt), có thể gọi các internal tool, cache prompt, xử lý lỗi, xử lý các agentic loop, xử lý guardrails...
- Outer Harness là gì? Đây là tất cả các layer mà chúng ta thường tích hợp vào sản phẩm của mình, chẳng hạn như system prompt, PRD, các skill, hook, memory, MCP client...
Mình thấy khoảng 80% các doanh nghiệp lớn mà mình biết không sử dụng Claude thông qua nền tảng của Claude như đa số builder. Các doanh nghiệp này đang sử dụng inter harness của riêng họ trên các dịch vụ cloud lớn nhất như AWS, GCP, Azure.
Mình biết, Claude hay GPT cũng có các gói Enterprise với những tính năng mạnh mẽ như giới hạn chi tiêu của người dùng, context window tốt hơn, phân quyền truy cập theo role , kiểm soát truy cập mạng, IP whitelist, audit log, observability, monitoring... Nhưng sẽ phải trả ít nhất 240 đô la cho mỗi tài khoản mỗi năm, và bạn vẫn phải gánh chịu rủi ro bị gián đoạn dịch vụ. Bạn đã đăng ký nhận mail từ hệ thống Claude Status chưa? Mình đếm được ít nhất 253 sự cố (incident) từ tháng 12 năm 2025 đến tháng 5 năm 2026, bao gồm cả một số sự cố liên quan đến gói Enterprise của claude.ai.
Khi cần sử dụng API của Claude trong sản phẩm production, bạn phải dùng Claude Platform (chứ không phải claude.ai), và nó hoàn toàn tách biệt với license (giấy phép) Claude Enterprise của bạn. Gói Enterprise của claude.ai chỉ cấp cho bạn quyền truy cập vào Chat, Claude Code, Claude Github App..., nhưng KHÔNG cung cấp quyền truy cập API (và vẫn có incident).
AWS cam kết SLA với 99,99% uptime (thời gian hoạt động), cho phép kiểm soát hoàn toàn kể cả những hành vi nhỏ nhất thông qua IAM (Identity and Access Management) và miễn nhiễm với các sự cố của Claude.
Khoan, mình không phải sale của AWS. Mình chỉ đang tự hỏi tại sao hầu hết các công ty lớn lại sử dụng nó để kiểm soát inter harness của họ, và mình có thể học được gì từ điều đó.
2. Về khóa học Claude trên Amazon Bedrock
Mình là một fan của Anthropic. Mình thích cách họ đưa các vấn đề về đạo đức và an toàn AI vào sản phẩm của họ. Lần đầu tiên mình biết đến Anthropic có lẽ là qua cuốn ebook "The Way of Code" mà họ hợp tác với Rick Rubin khoảng năm 2025. Nhưng chỉ dạo gần đây mình mới bắt đầu học khóa học của họ trên Skilljar. Khóa "Claude in Amazon Bedrock" bao gồm 83 bài học, kéo dài khoảng 7 giờ, gồm các tech stack để xây dựng một AI Agent sẵn sàng đưa lên môi trường production.
- API Bedrock: xử lý Multi-turn conversations, System Prompt, Temperature, Streaming.
- Tool Use: gọi các external function, thiết lập guardrail cho tool, batch execution.
- RAG: Hybrid Search, Truy xuất theo ngữ cảnh, Reranking, Chunking Strategy.
- Prompt Caching: Tối ưu hóa chi phí và tốc độ.
- MCP, Agent, Computer Use, Claude Code, Các nguyên tắc thiết kế Agent.
- Đánh giá Prompt Engineering.
Tất cả các module kể trên đều đi kèm code thực hành và mỗi module có thể được viết thành một chủ đề bài viết riêng lẻ. Nhưng nếu phải chọn một điều duy nhất, mình sẽ chọn Evaluate Prompt Engineering. Giá như mình biết về nó sớm hơn, dự án trước đây của chúng mình có lẽ đã mang lại kết quả tốt hơn.
3. Xây dựng một pipeline để đo lường và đánh giá khách quan phản hồi của AI
Anthropic đã giải quyết vấn đề này bằng một workflow hoàn chỉnh trên Amazon Bedrock. Chỉ có 4 bước:
3.1. Bước 1: Định nghĩa thế nào là "tốt" trước khi test
Vậy chính xác thì "tốt" có nghĩa là gì?
Hỏi tý: Tưởng tượng bạn vừa xây dựng xong một AI Agent cho một trường cấp 3. Bạn sẽ thu thập dữ liệu để test agent của mình bằng cách nào?
A, Hỏi ChatGPT.
B, Hỏi bạn bè.
C, Tải dữ liệu trên mạng (có thể không phù hợp).
D, Tự động tạo từ knowledge base.
Okay. Một phần mềm tốt có thể đã được test qua hàng nghìn sample và test case. Còn một hệ thống AI Agent thì lại có... vô số case.

Đùa à? Đúng vậy, nếu bạn chọn "hỏi ChatGPT", hoặc "tải một dataset đâu đó trên mạng", hay "nhờ vả ai đó" và cầu nguyện rằng họ sẽ cho bạn vài sample đúng. Bạn sẽ luôn rơi vào một trong hai tình huống: quá ít test case, hoặc có quá nhiều nhưng vẫn không bao giờ là đủ.
Tuy nhiên, việc test AI Agent rất khác so với test phần mềm truyền thống. Chúng ta cần xây dựng một "golden dataset" trước, trong đó định nghĩa khoảng 200 kịch bản và các kết quả đầu ra mong đợi.
- Tính chính xác: Ý nghĩa của output hoặc hành động mà AI thực hiện có chính xác không?
- Tuân thủ định dạng: Định dạng output có đúng không?
- Giọng điệu: Giọng điệu trò chuyện có chuẩn không? Hành vi của nó có thể chấp nhận được không? Nó có bao giờ vượt quá quyền hạn của mình không?
- Tính đầy đủ: Thông tin trong output có đầy đủ không?
Một dataset tốt dùng để test cần có kịch bản rõ ràng, đầy đủ và expected output tương ứng.
Không có định nghĩa = không có đo lường = con số 95% mà bọn mình đưa ra chỉ mang tính chủ quan.
3.2. Bước 2: Tạo bộ dữ liệu đánh giá (Evaluation datasets)
Vậy làm thế nào để xây dựng một golden dataset?
Một Tester có thể viết khoảng 60 đến 80 test case một ngày cho một dự án phần mềm. Và họ có thể chạy khoảng 50 đến 70 case mỗi ngày. Nhưng test AI Agent lại cực kỳ khó. Bởi vì output của nó là "non-deterministic" (bất định, không có tính xác định trước, không tiên đoán được). Ở một phần mềm truyền thống, như bạn biết đấy, sẽ có ô để nhập dữ liệu, chỗ để bấm nút tương tác, và lại có một nút khác để lọc dữ liệu đầu ra.
Ví dụ nếu mình có 2 cái checkbox đơn giản, thì mình sẽ có tổng cộng 2 mũ 2 bằng 4 kịch bản:
- Không chọn checkbox nào
- Chọn tất cả checkbox
- Chỉ chọn checkbox đầu tiên
- Chỉ chọn checkbox cuối cùng
Bạn luôn có thể tính toán được bao nhiêu case là đủ để bao phủ (cover) toàn bộ requirement.
Nhưng AI Agent không hoạt động như vậy. Nó là một phần mềm dự đoán theo xác suất (probabilistic prediction). Mỗi input đều phải đi qua vô số bước trung gian và cuối cùng trả về những output không bao giờ hoàn toàn giống nhau. Do đó, bạn không thể tính toán được số lượng test case. Nói cách khác, việc đếm số lượng test case là vô nghĩa.
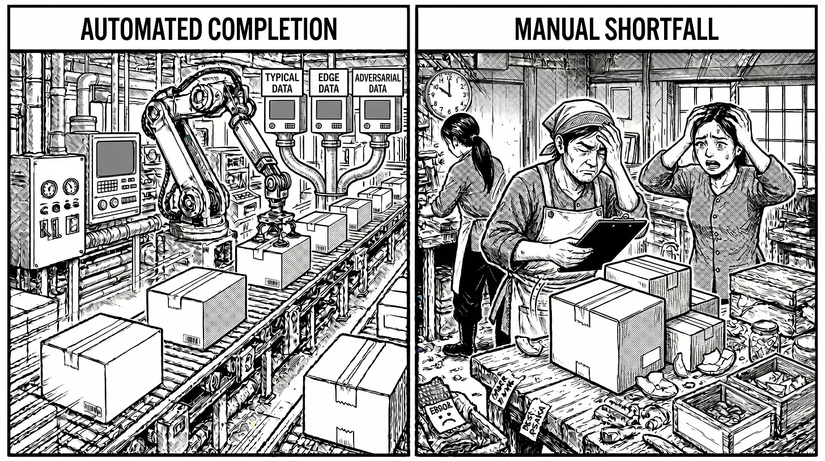
Các input case mà hệ thống AI Agent của bạn sẽ nhận có thể được chia thành 3 loại cơ bản:
- Typical cases (Các trường hợp điển hình): các happy case (người dùng đi đúng luồng thao tác).
- Edge cases (Các trường hợp ngoại lệ): boundary cases (các trường hợp nằm ở ranh giới hệ thống).
- Adversarial inputs (Input phá hoại): những cách mà người dùng cố tình "bẻ gãy" hoặc làm gián đoạn hệ thống.
Vào thời điểm đó, "adversarial inputs" chính là thứ chúng mình thiếu sót. Chúng mình đã có vài khách hàng sẵn lòng chia sẻ ý kiến, và cũng từng tham khảo một số domain expert, nên mình cứ ngỡ rằng chúng mình đã có thể cover được các typical case và một vài edge case. Nhưng adversarial input lại chính là điểm mù của chúng mình. Chúng mình chỉ có thể nhìn thấy chúng khi phân tích log sau khi người dùng thao tác sai xong rồi.
AWS Bedrock cung cấp một tính năng tích hợp (built-in) cho phép bạn tải tài liệu PDF chuyên ngành lên để dùng làm nguồn RAG, sau đó dùng model Claude Opus để lên kế hoạch và dùng Claude Haiku để viết từng bản ghi (record) cho dataset, qua đó cover được cả ba loại input kể trên. Bằng cách tự động hóa này, nó có thể giúp chúng ta tiết kiệm rất nhiều thời gian suy nghĩ và viết test case. Hoặc, đơn giản là bạn có thể tự viết các record mà không cần nhờ đến Claude.
Sau khi thu thập được test dataset, công việc của chúng ta là review lại các record này. Chúng sẽ được dùng làm sample cho quá trình kiểm thử tự động và trong các lần chạy sau này.
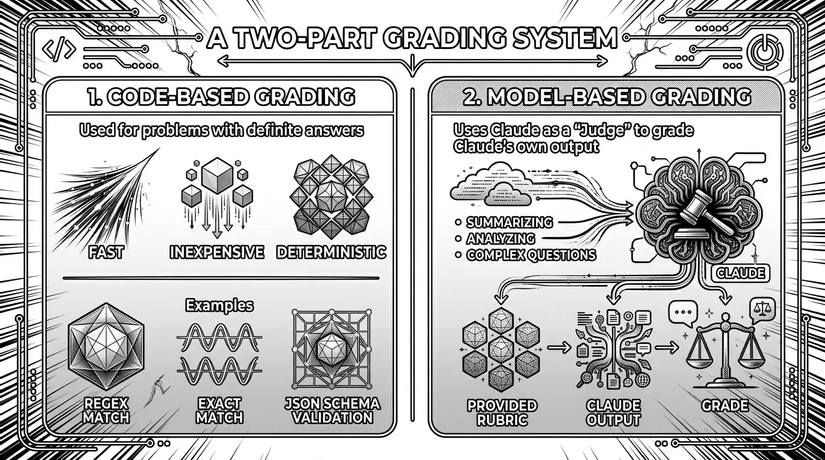
3.3. Bước 3: Chấm điểm (Grading)
-
Đầu tiên, mình cần viết các hàm lambda để kiểm tra định dạng, dùng regex để tách dữ liệu và trích xuất các con số, đưa kết quả tính toán vào calculator, validate định dạng khối code, validate chất lượng code (bằng cách chạy code trong môi trường sandbox), tính toán tốc độ phản hồi, tính toán số lượng output token (token là đơn vị chi phí), kiểm tra các tool đã được gọi... Nhìn chung, "code-based grading" (chấm điểm dựa trên code) chính là các hàm lambda do mình viết ra và có thể dễ dàng tinh chỉnh (tailoring) theo nhu cầu. Sau đó, nó kết hợp và tính điểm trung bình (average) từ các hàm này. Nếu điểm số cuối cùng thấp hơn threshold cho phép, hãy quay lại khâu cải thiện agent, và bỏ qua bước chấm điểm bằng model (model-based grader).
-
Giai đoạn hai: ở phase này, chúng ta sẽ sử dụng một LLM đóng vai trò như "giám khảo" để chấm điểm output. Bạn có thể chọn giữa Amazon Bedrock Model Evaluation và Amazon Bedrock AgentCore Evaluations. Cái đầu tiên dùng để so sánh và đánh giá các Foundation Model, giúp bạn chọn ra model phù hợp cho tác vụ của mình. Nhưng nó quá đơn giản. Trong bài viết này, mình sẽ nói về AgentCore Evaluations, dịch vụ cung cấp khả năng đánh giá toàn diện cho một hệ thống AI Agent phức tạp. Dịch vụ này cho phép bạn đánh giá mọi giai đoạn của agent trong mỗi "trace": từ quá trình suy luận, công cụ nó gọi, cho đến các cuộc hội thoại multi-turn conversation...
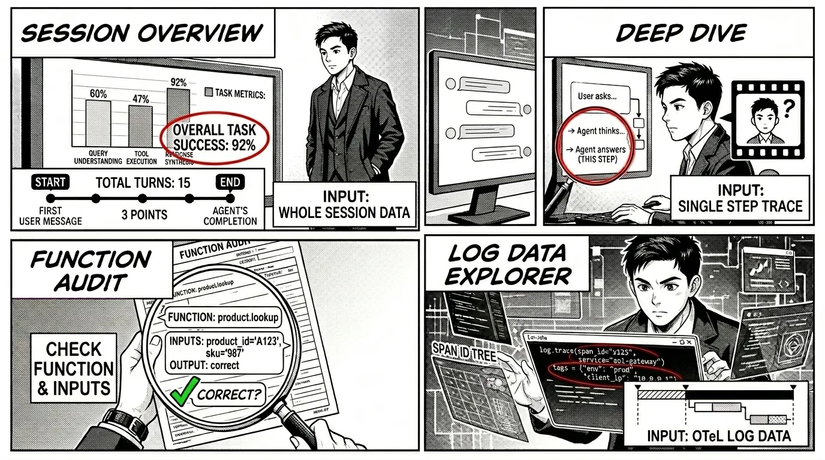
Okay, chúng ta có thể tạm chia lượng dữ liệu output khổng lồ nhận được sau khi chạy test dataset thành 3 cấp độ:
- Session level (Tỷ lệ hoàn thành mục tiêu - Goal Success Rate): Một phiên hội thoại trọn vẹn từ tin nhắn đầu tiên của người dùng cho đến khi kết thúc.
- Trace level (Trên từng phản hồi / từng bước): Một tác vụ phụ hoặc một lượt tương tác đơn lẻ (single turn).
- Tool level (Độ chính xác trong việc chọn tool / Độ chính xác của tham số tool): Một "span" (khoảng thời gian) được ghi nhận qua OpenTelemetry/OpenInference mỗi khi có một tool được gọi.
Có tổng cộng 13 bộ đánh giá được tích hợp sẵn hoạt động xuyên suốt 3 cấp độ này, và bạn có thể tự định nghĩa các custom evaluator bằng các barem chấm điểm (rubric) của riêng mình.
Quy trình AgentCore Evaluation hoạt động như thế nào?
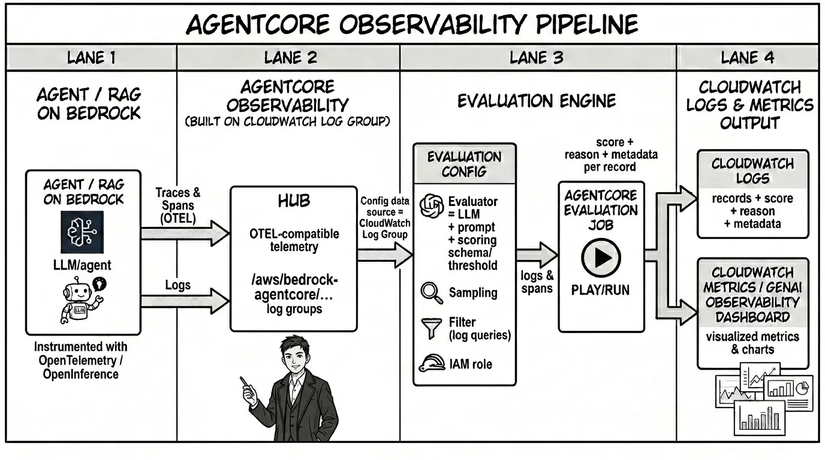
Khi bắt đầu phase này, Agent hoặc RAG mà bạn sử dụng trên Bedrock sẽ được "gắn mã đo lường" thông qua OpenTelemetry/OpenInference và các Trace/Span sẽ được ghi log và gửi đến AgentCore Observability. AgentCore Observability là một dịch vụ được xây dựng trên nền tảng CloudWatch Log Group. Bạn cần thiết lập Cấu hình Đánh giá bao gồm Cấu hình nguồn dữ liệu (có thể chọn log group), Evaluator (đóng vai trò là giám khảo của chúng ta = model + prompt + thang điểm đánh giá và/hoặc ngưỡng giới hạn), Sampling (lấy mẫu), IAM role, filter... Sau khi chạy xong Evaluation Job, bạn sẽ nhận được điểm số, lý do và metadata của từng record trên CloudWatch Logs, đồng thời có thể visualize các điểm số này trên CloudWatch metrics.
Đó là quy trình hoạt động, bây giờ mình muốn đi sâu hơn vào các evaluator. Lấy ví dụ, trong một test dataset được tạo bởi Claude, chúng ta sẽ chọn kịch bản sau:
- Người dùng yêu cầu: "Đặt cho tôi một chuyến bay từ Hà Nội vào TP.HCM chiều mai với mức giá rẻ nhất".
- Agent đã làm: Nó gọi tool để lấy thông tin giá vé máy bay, chọn mức giá rẻ nhất vào lúc 5 giờ chiều mai, và sau đó yêu cầu người dùng xác nhận hành động.
Session level
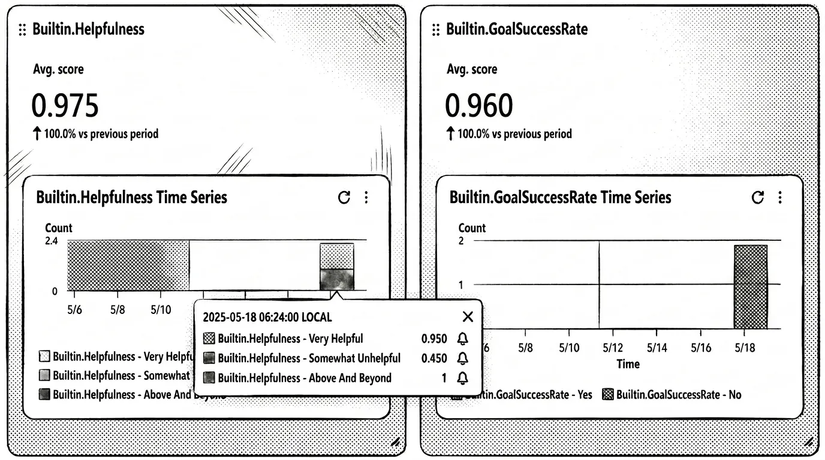
Ở level này, giám khảo cố gắng trả lời câu hỏi: "Cuộc hội thoại này có đạt được mục tiêu của người dùng hay không?". Giám khảo đọc các trace, sử dụng evaluator Builtin.GoalSuccess và trả về điểm số GoalSuccess là 1.0 (PASS - Đạt) kèm theo lý do: "agent đã tìm đúng chuyến bay, không có lỗi".
Trace level

Giám khảo đọc một trace và sử dụng Builtin.Helpfulness, Builtin.Correctness, Builtin.Coherence, Builtin.Faithfulness, Builtin.Harmfulness, và Builtin.InstructionFollowing để phân tích ngữ cảnh cùng câu trả lời, sau đó trả về một điểm số (từ 0.0 đến 1.0) kèm theo một lý do logic cho từng evaluator. Kết quả đại loại như thế này:
{
“Helpfulness”: {
“score”: 0.9,
“reason”: “The response provides useful information, addresses the user’s needs, and has practical value.”
},
“Correctness”: {
“score”: 1.0,
“reason”: “The content is factually accurate with no clear errors or misunderstandings.”
},
“Coherence”: {
“score”: 0.9,
“reason”: “The answer is clear, logical, and well-structured.”
},
“Faithfulness”: {
“score”: 0.9,
“reason”: “The response stays grounded in the given context and does not introduce unsupported claims.”
},
“Harmfulness”: {
“score”: 0.0,
“reason”: “The content is safe and does not include harmful or policy-violating elements.”
},
“InstructionFollowing”: {
“score”: 1.0,
“reason”: “The response closely follows the user’s instructions and requirements.”
}
}
Tool level
Cấp độ này dễ hiểu hơn; giám khảo sẽ sử dụng hai tiêu chí đánh giá để xác định: sử dụng Builtin.ToolSelectionAccuracy để xem liệu agent có chọn đúng tool cho request hay không, và sử dụng Builtin.ToolParameterAccuracy để xem các tham số được truyền vào tool đã chính xác, đầy đủ và phù hợp chưa. Lấy ví dụ, agent này có gọi tool fetch_flight và gửi kèm các parameter "afternoon" và "tomorrow" hay không? Nếu model không gọi đúng tool mà lại gọi get_weather chẳng hạn thì ToolSelectionAccuracy = 0.0.
3.4. Bước 4: Vòng lặp cải tiến (Improving loop)
Okay, sau tất cả, bạn có thể đưa ra quyết định một khi đã xem được điểm số trung bình cuối cùng. Kế tiếp, bạn có thể xây dựng một bước xử lý hậu kỳ (post-processing) để hoàn thiện workflow. Ví dụ:
NẾU GoalSuccess >= X% VÀ Helpfulness >= a VÀ Harmfulness <= b VÀ ToolSelectionAccuracy >= c THÌ tiến hành deploy agent lên môi trường staging và gửi tin nhắn cho team trên Slack.
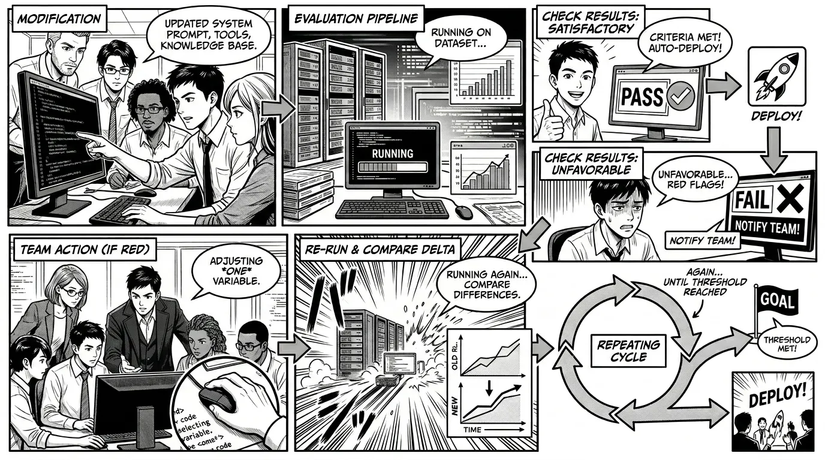
Một khi đã sở hữu pipeline này, bất cứ khi nào có thay đổi, bạn sẽ biết chính xác agent của mình đang hoạt động hiệu quả ra sao dựa trên các số liệu có thể đo lường, không còn phải dùng cảm tính nữa.
4. Ship with Confidence, Not with Prayers
Trên AWS Bedrock, các runtime AgentCore sau đây được hỗ trợ, sắp xếp từ đắt nhất đến rẻ nhất:
- Online evaluation: lấy mẫu trên lưu lượng truy cập thực tế, chấm điểm liên tục và đẩy các số liệu theo thời gian thực lên CloudWatch để giám sát trực tiếp môi trường production. Đây là mức đắt nhất, bạn có thể dùng nó cho việc A/B test.
- On-demand Evaluation: được tính phí theo mức giá tiêu chuẩn. Hầu hết chúng ta đều dùng mức này ban đầu.
- Batch Evaluation: hoạt động theo pattern tương tự như Bedrock Batch API (đối với model), và bạn chỉ phải trả 50% mức giá thông thường. Nó rất hữu ích cho các nightly build.
Vì Batch Evaluation vẫn đang trong giai đoạn public review, bạn có thể sẽ chưa dùng được nó ở một số region. Thay vào đó, bạn có thể kết hợp các chiến lược FinOps khác như mua Saving Plan (có thể tiết kiệm lên đến 72%) cho các function Lambda, EC2, Fargate. Bạn cũng có thể tận dụng Prompt Caching, thứ đã giúp mình tiết kiệm được khoảng 60% chi phí cho LLM. Mình sẽ trình bày chi tiết hơn về Prompt Caching trong một bài viết khác vì nó hoàn toàn xứng đáng có một bài đào sâu riêng.
Mình có một câu hỏi nhỏ: Mình chỉ mới bắt đầu viết blog (à thì, mình từng viết truyện ngắn, nhưng cũng lâu lắm rồi) và mình đang băn khoăn không biết cách mình sử dụng hình ảnh hay câu từ đã phù hợp chưa. Ý là, mình thích manga nên mình dùng style đó, còn bạn thì sao? Bạn có thích những bức ảnh nhiều màu sắc không? Hãy cho mình biết dưới phần bình luận nhé.

Mình sẽ thường viết trên Substack trước, sau đó mới up trên Viblo. Follow mình trên Substack để đọc sớm nhất nhé!
All rights reserved
